 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evolving Image Compositions for Feature Representation Learning
Jun 16, 2021
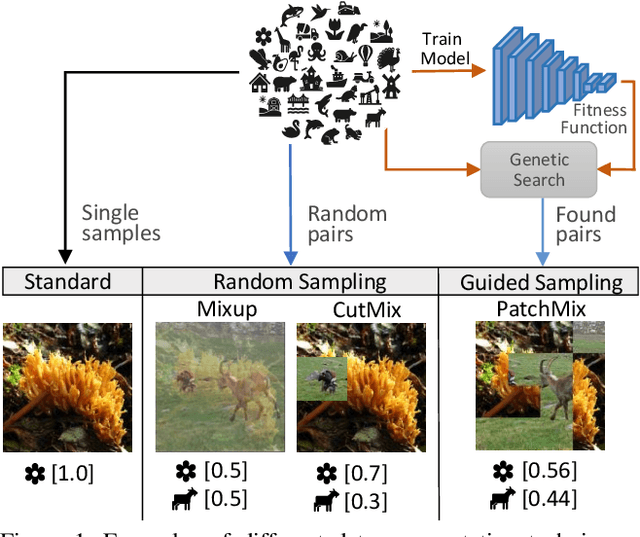
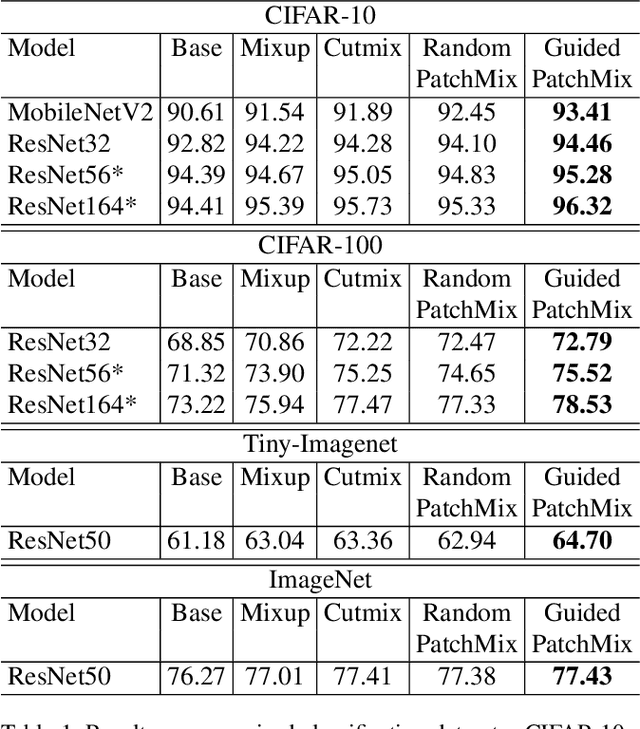
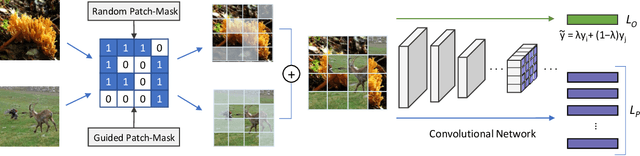
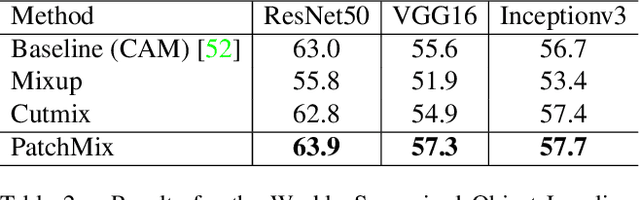
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples' ground truth labels are set as proportional to the number of patches from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to discover optimal grid-like patterns and image pairing jointly. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16) by significant margins, also outperforming previous state-of-the-art pairwise augmentation strategies.
Collaborative Filtering-Based Method for Low-Resolution and Details Preserving Image Denoising
Jul 10, 2021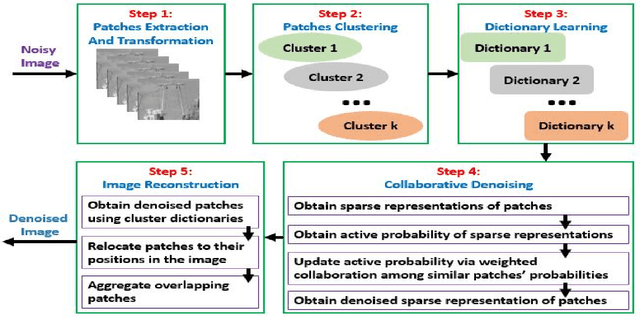
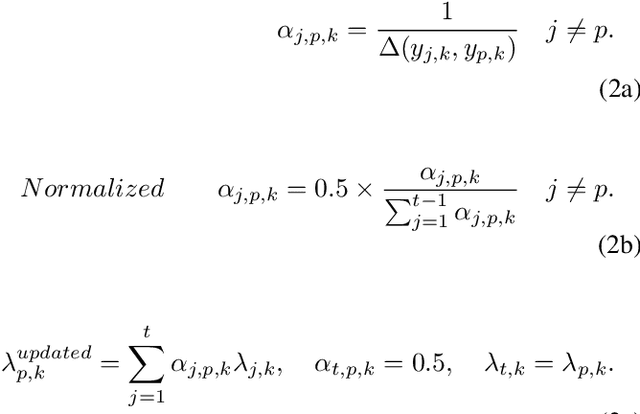
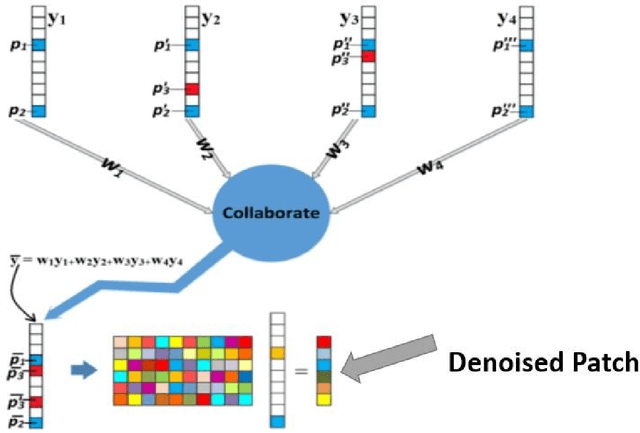
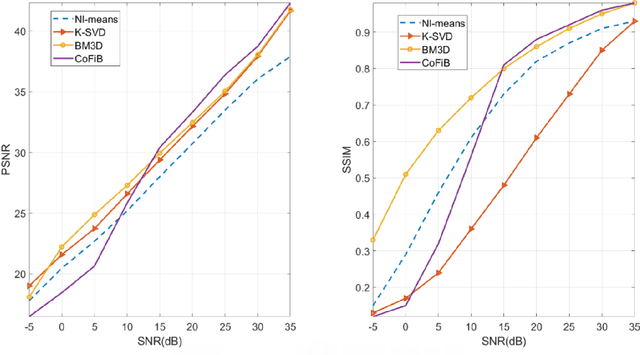
Over the years, progressive improvements in denoising performance have been achieved by several image denoising algorithms that have been proposed. Despite this, many of these state-of-the-art algorithms tend to smooth out the denoised image resulting in the loss of some image details after denoising. Many also distort images of lower resolution resulting in a partial or complete structural loss. In this paper, we address these shortcomings by proposing a collaborative filtering-based (CoFiB) denoising algorithm. Our proposed algorithm performs weighted sparse domain collaborative denoising by taking advantage of the fact that similar patches tend to have similar sparse representations in the sparse domain. This gives our algorithm the intelligence to strike a balance between image detail preservation and noise removal. Our extensive experiments showed that our proposed CoFiB algorithm does not only preserve the image details but also perform excellently for images of any given resolution where many denoising algorithms tend to struggle, specifically at low resolutions.
NeRF, meet differential geometry!
Jun 29, 2022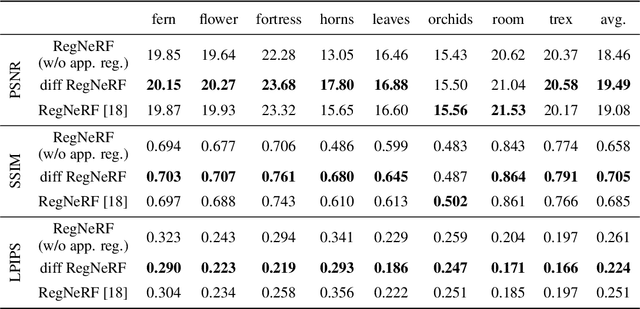
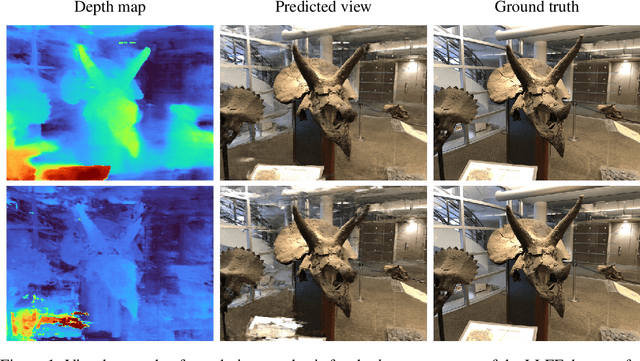
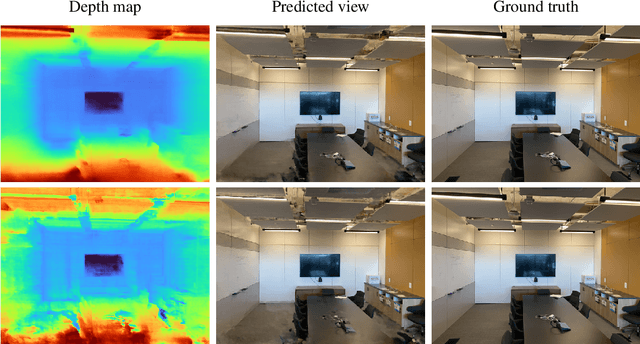

Neural radiance fields, or NeRF, represent a breakthrough in the field of novel view synthesis and 3D modeling of complex scenes from multi-view image collections. Numerous recent works have been focusing on making the models more robust, by means of regularization, so as to be able to train with possibly inconsistent and/or very sparse data. In this work, we scratch the surface of how differential geometry can provide regularization tools for robustly training NeRF-like models, which are modified so as to represent continuous and infinitely differentiable functions. In particular, we show how these tools yield a direct mathematical formalism of previously proposed NeRF variants aimed at improving the performance in challenging conditions (i.e. RegNeRF). Based on this, we show how the same formalism can be used to natively encourage the regularity of surfaces (by means of Gaussian and Mean Curvatures) making it possible, for example, to learn surfaces from a very limited number of views.
GIRAFFE HD: A High-Resolution 3D-aware Generative Model
Mar 28, 2022
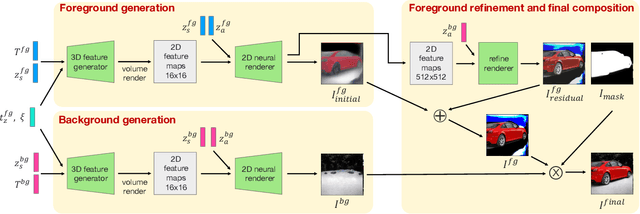

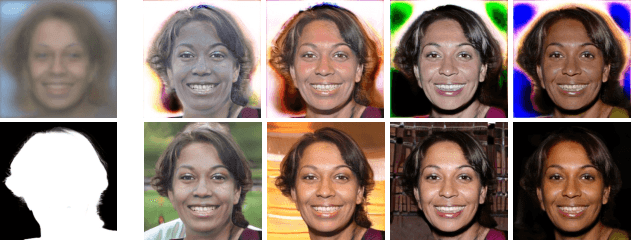
3D-aware generative models have shown that the introduction of 3D information can lead to more controllable image generation. In particular, the current state-of-the-art model GIRAFFE can control each object's rotation, translation, scale, and scene camera pose without corresponding supervision. However, GIRAFFE only operates well when the image resolution is low. We propose GIRAFFE HD, a high-resolution 3D-aware generative model that inherits all of GIRAFFE's controllable features while generating high-quality, high-resolution images ($512^2$ resolution and above). The key idea is to leverage a style-based neural renderer, and to independently generate the foreground and background to force their disentanglement while imposing consistency constraints to stitch them together to composite a coherent final image. We demonstrate state-of-the-art 3D controllable high-resolution image generation on multiple natural image datasets.
Real-Time Neural Character Rendering with Pose-Guided Multiplane Images
Apr 25, 2022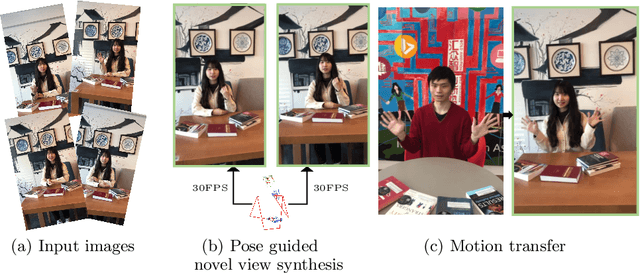
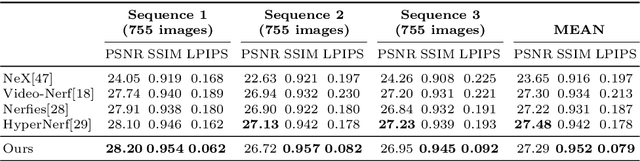
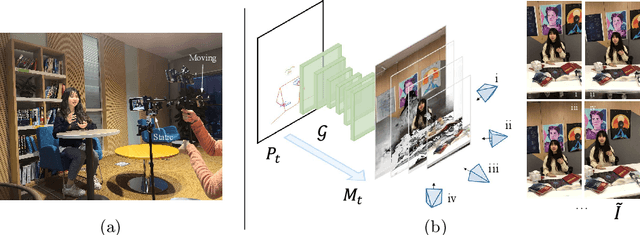
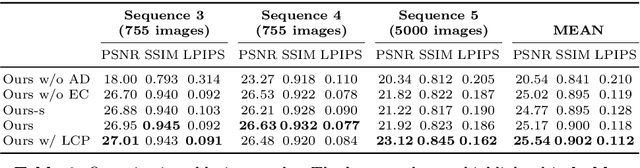
We propose pose-guided multiplane image (MPI) synthesis which can render an animatable character in real scenes with photorealistic quality. We use a portable camera rig to capture the multi-view images along with the driving signal for the moving subject. Our method generalizes the image-to-image translation paradigm, which translates the human pose to a 3D scene representation -- MPIs that can be rendered in free viewpoints, using the multi-views captures as supervision. To fully cultivate the potential of MPI, we propose depth-adaptive MPI which can be learned using variable exposure images while being robust to inaccurate camera registration. Our method demonstrates advantageous novel-view synthesis quality over the state-of-the-art approaches for characters with challenging motions. Moreover, the proposed method is generalizable to novel combinations of training poses and can be explicitly controlled. Our method achieves such expressive and animatable character rendering all in real time, serving as a promising solution for practical applications.
Learning Deep Latent Subspaces for Image Denoising
Apr 01, 2021
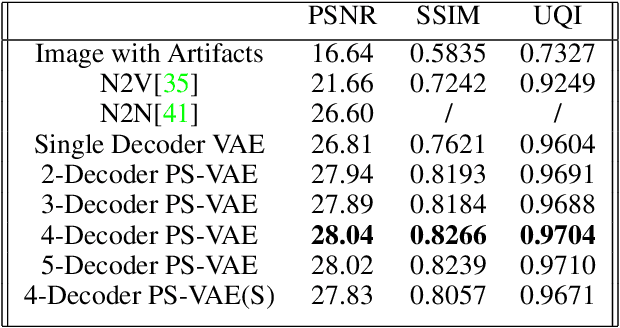
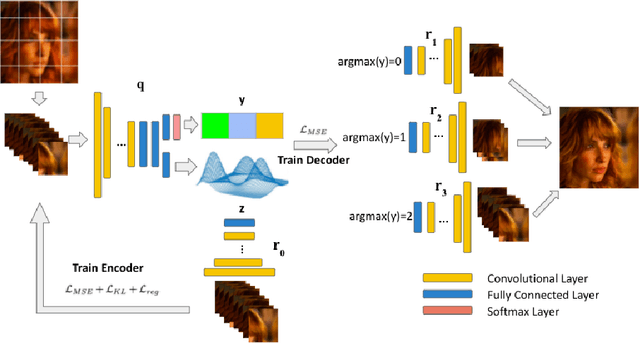

Heterogeneity exists in most camera images. This heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Current camera image processing pipelines, including deep trained versions, tend to rectify the issue applying a single filter that is homogeneously applied to the entire image. This is also particularly true when an encoder-decoder type deep architecture is trained for the task. In this paper, we present a structured deep learning model that solves the heterogeneous image artifact filtering problem. We call our deep trained model the Patch Subspace Variational Autoencoder (PS-VAE) for Camera ISP. PS-VAE does not necessarily assume uniform image distortion levels nor similar artifact types within the image. Rather, our model attempts to learn to cluster different patches extracted from images into artifact type and distortion levels, within multiple latent subspaces (e.g. Moire ringing artifacts are often a higher dimensional latent distortion than a Gaussian motion blur artifact). Each image's patches are encoded into soft-clusters in their appropriate latent sub-space, using a prior mixture model. The decoders of the PS-VAE are also trained in an unsupervised manner for each of the image patches in each soft-cluster. Our experimental results demonstrates the flexibility and performance that one can achieve through improved heterogeneous filtering. We compare our results to a conventional one-encoder-one-decoder architecture.
Segmentation of kidney stones in endoscopic video feeds
Apr 29, 2022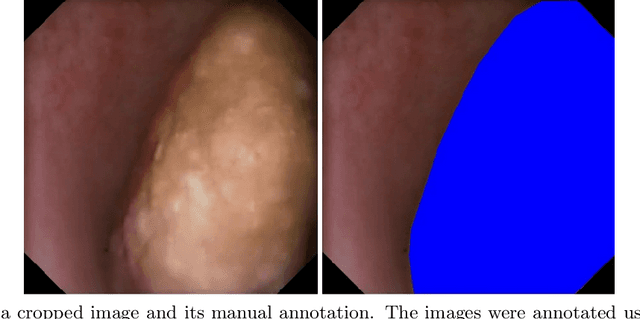
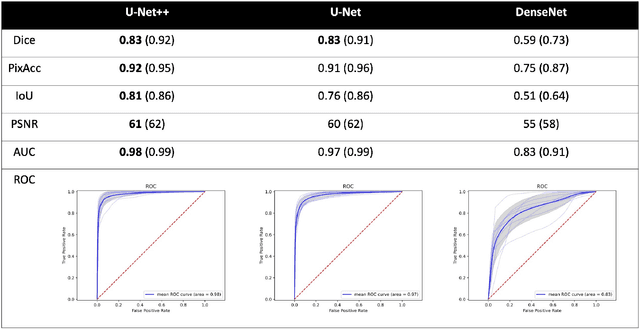
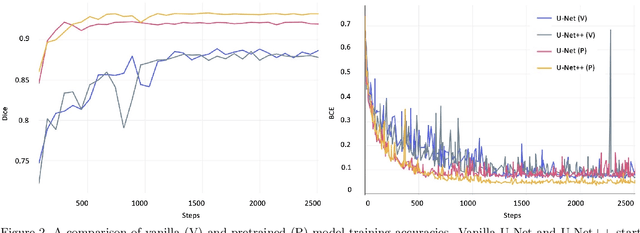
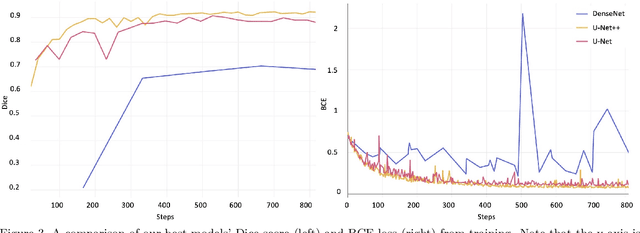
Image segmentation has been increasingly applied in medical settings as recent developments have skyrocketed the potential applications of deep learning. Urology, specifically, is one field of medicine that is primed for the adoption of a real-time image segmentation system with the long-term aim of automating endoscopic stone treatment. In this project, we explored supervised deep learning models to annotate kidney stones in surgical endoscopic video feeds. In this paper, we describe how we built a dataset from the raw videos and how we developed a pipeline to automate as much of the process as possible. For the segmentation task, we adapted and analyzed three baseline deep learning models -- U-Net, U-Net++, and DenseNet -- to predict annotations on the frames of the endoscopic videos with the highest accuracy above 90\%. To show clinical potential for real-time use, we also confirmed that our best trained model can accurately annotate new videos at 30 frames per second. Our results demonstrate that the proposed method justifies continued development and study of image segmentation to annotate ureteroscopic video feeds.
* Published in SPIE Medical Imaging: Image Processing 2022 (9 pages, 5 figures, 1 table)
Super-resolution of multiphase materials by combining complementary 2D and 3D image data using generative adversarial networks
Oct 22, 2021
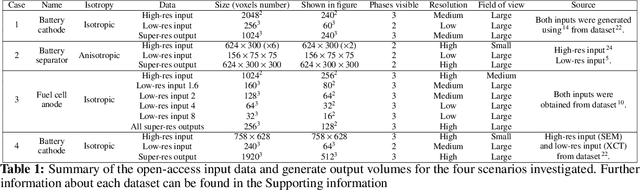
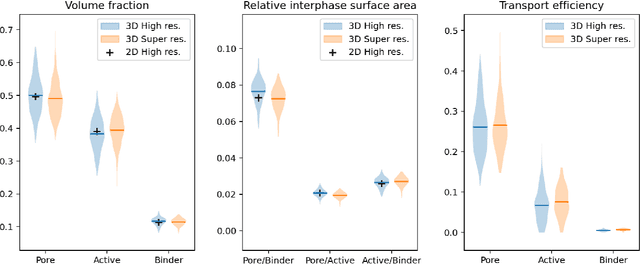

Modelling the impact of a material's mesostructure on device level performance typically requires access to 3D image data containing all the relevant information to define the geometry of the simulation domain. This image data must include sufficient contrast between phases to distinguish each material, be of high enough resolution to capture the key details, but also have a large enough field-of-view to be representative of the material in general. It is rarely possible to obtain data with all of these properties from a single imaging technique. In this paper, we present a method for combining information from pairs of distinct but complementary imaging techniques in order to accurately reconstruct the desired multi-phase, high resolution, representative, 3D images. Specifically, we use deep convolutional generative adversarial networks to implement super-resolution, style transfer and dimensionality expansion. To demonstrate the widespread applicability of this tool, two pairs of datasets are used to validate the quality of the volumes generated by fusing the information from paired imaging techniques. Three key mesostructural metrics are calculated in each case to show the accuracy of this method. Having confidence in the accuracy of our method, we then demonstrate its power by applying to a real data pair from a lithium ion battery electrode, where the required 3D high resolution image data is not available anywhere in the literature. We believe this approach is superior to previously reported statistical material reconstruction methods both in terms of its fidelity and ease of use. Furthermore, much of the data required to train this algorithm already exists in the literature, waiting to be combined. As such, our open-access code could precipitate a step change by generating the hard to obtain high quality image volumes necessary to simulate behaviour at the mesoscale.
Mixed Supervision Learning for Whole Slide Image Classification
Jul 05, 2021
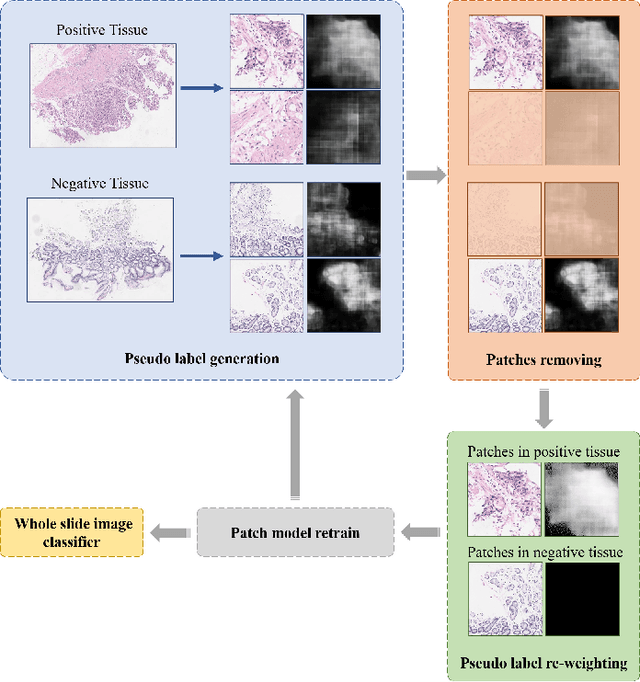
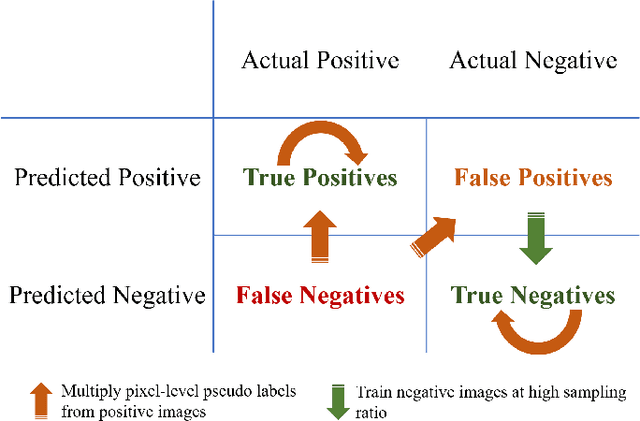
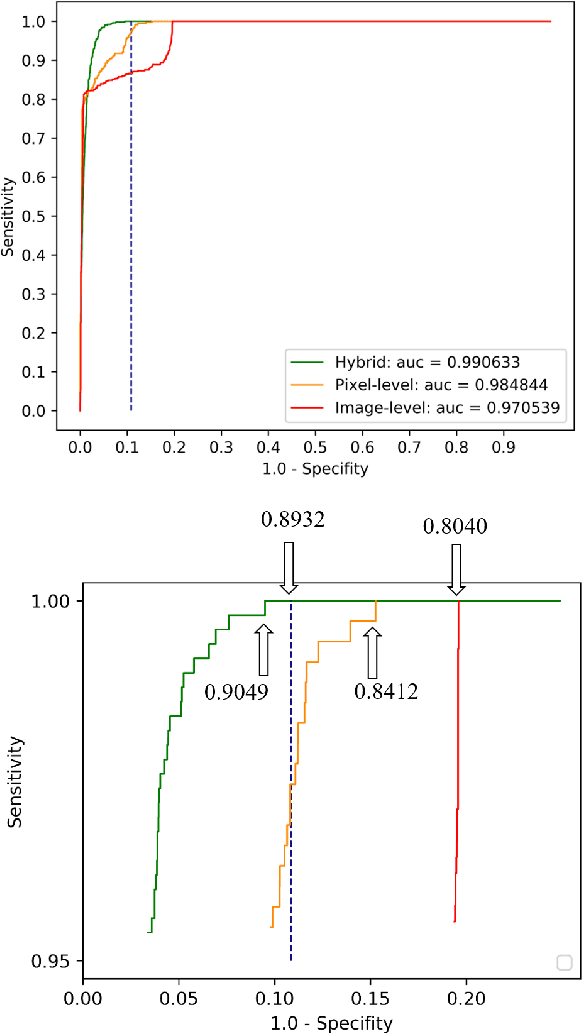
Weak supervision learning on classification labels has demonstrated high performance in various tasks. When a few pixel-level fine annotations are also affordable, it is natural to leverage both of the pixel-level (e.g., segmentation) and image level (e.g., classification) annotation to further improve the performance. In computational pathology, however, such weak or mixed supervision learning is still a challenging task, since the high resolution of whole slide images makes it unattainable to perform end-to-end training of classification models. An alternative approach is to analyze such data by patch-base model training, i.e., using self-supervised learning to generate pixel-level pseudo labels for patches. However, such methods usually have model drifting issues, i.e., hard to converge, because the noise accumulates during the self-training process. To handle those problems, we propose a mixed supervision learning framework for super high-resolution images to effectively utilize their various labels (e.g., sufficient image-level coarse annotations and a few pixel-level fine labels). During the patch training stage, this framework can make use of coarse image-level labels to refine self-supervised learning and generate high-quality pixel-level pseudo labels. A comprehensive strategy is proposed to suppress pixel-level false positives and false negatives. Three real-world datasets with very large number of images (i.e., more than 10,000 whole slide images) and various types of labels are used to evaluate the effectiveness of mixed supervision learning. We reduced the false positive rate by around one third compared to state of the art while retaining 100% sensitivity, in the task of image-level classification.
LEAF + AIO: Edge-Assisted Energy-Aware Object Detection for Mobile Augmented Reality
May 27, 2022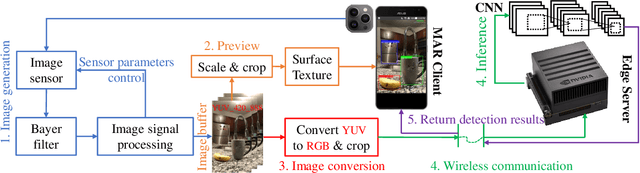
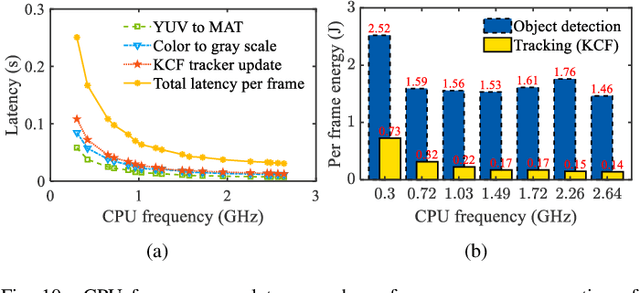
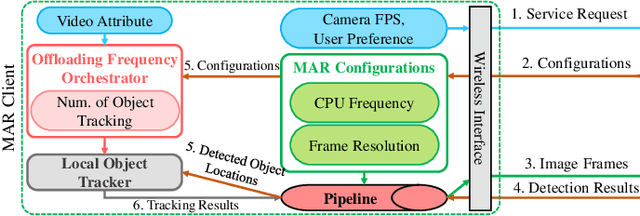

Today very few deep learning-based mobile augmented reality (MAR) applications are applied in mobile devices because they are significantly energy-guzzling. In this paper, we design an edge-based energy-aware MAR system that enables MAR devices to dynamically change their configurations, such as CPU frequency, computation model size, and image offloading frequency based on user preferences, camera sampling rates, and available radio resources. Our proposed dynamic MAR configuration adaptations can minimize the per frame energy consumption of multiple MAR clients without degrading their preferred MAR performance metrics, such as latency and detection accuracy. To thoroughly analyze the interactions among MAR configurations, user preferences, camera sampling rate, and energy consumption, we propose, to the best of our knowledge, the first comprehensive analytical energy model for MAR devices. Based on the proposed analytical model, we design a LEAF optimization algorithm to guide the MAR configuration adaptation and server radio resource allocation. An image offloading frequency orchestrator, coordinating with the LEAF, is developed to adaptively regulate the edge-based object detection invocations and to further improve the energy efficiency of MAR devices. Extensive evaluations are conducted to validate the performance of the proposed analytical model and algorithms.