 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Supervision Learning for Whole Slide Image Classification
Paper and Code
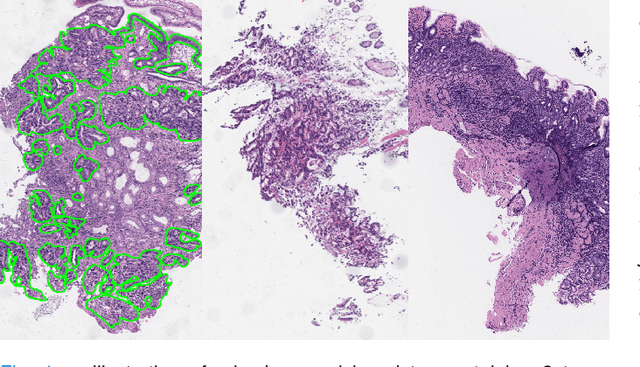
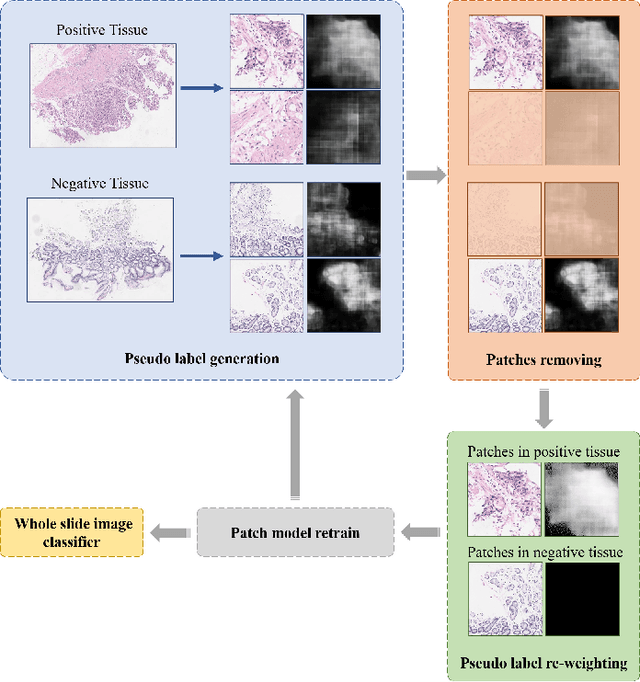
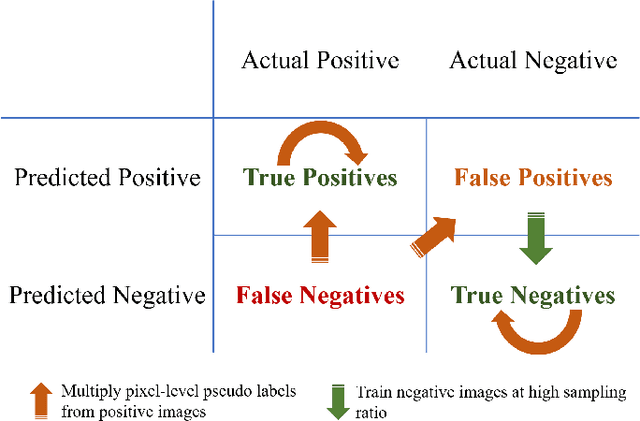
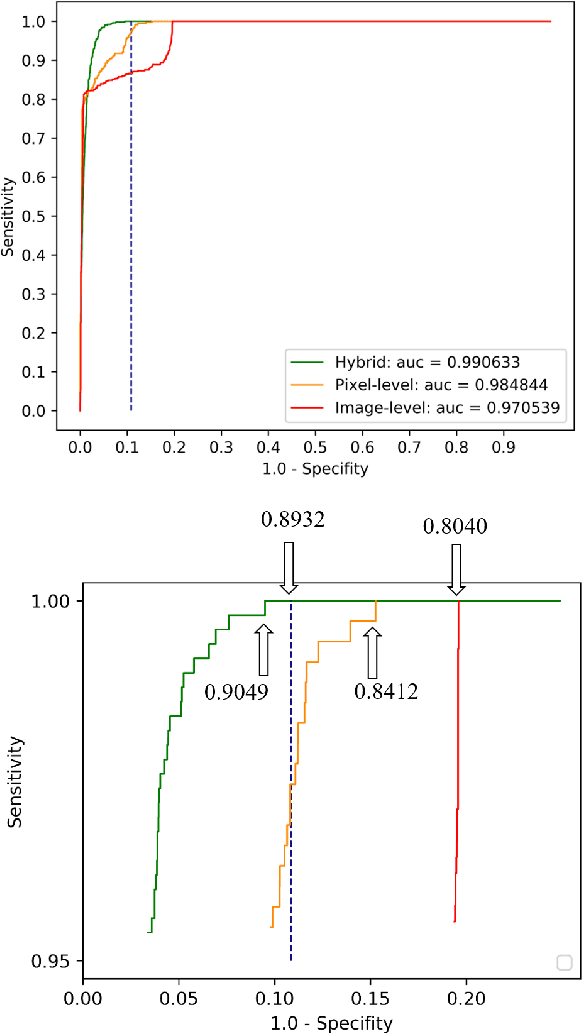
Weak supervision learning on classification labels has demonstrated high performance in various tasks. When a few pixel-level fine annotations are also affordable, it is natural to leverage both of the pixel-level (e.g., segmentation) and image level (e.g., classification) annotation to further improve the performance. In computational pathology, however, such weak or mixed supervision learning is still a challenging task, since the high resolution of whole slide images makes it unattainable to perform end-to-end training of classification models. An alternative approach is to analyze such data by patch-base model training, i.e., using self-supervised learning to generate pixel-level pseudo labels for patches. However, such methods usually have model drifting issues, i.e., hard to converge, because the noise accumulates during the self-training process. To handle those problems, we propose a mixed supervision learning framework for super high-resolution images to effectively utilize their various labels (e.g., sufficient image-level coarse annotations and a few pixel-level fine labels). During the patch training stage, this framework can make use of coarse image-level labels to refine self-supervised learning and generate high-quality pixel-level pseudo labels. A comprehensive strategy is proposed to suppress pixel-level false positives and false negatives. Three real-world datasets with very large number of images (i.e., more than 10,000 whole slide images) and various types of labels are used to evaluate the effectiveness of mixed supervision learning. We reduced the false positive rate by around one third compared to state of the art while retaining 100% sensitivity, in the task of image-level classification.