 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Collaborative Control for Geometry-Conditioned PBR Image Generation
Feb 20, 2024
Current 3D content generation approaches build on diffusion models that output RGB images. Modern graphics pipelines, however, require physically-based rendering (PBR) material properties. We propose to model the PBR image distribution directly, avoiding photometric inaccuracies in RGB generation and the inherent ambiguity in extracting PBR from RGB. Existing paradigms for cross-modal fine-tuning are not suited for PBR generation due to both a lack of data and the high dimensionality of the output modalities: we overcome both challenges by retaining a frozen RGB model and tightly linking a newly trained PBR model using a novel cross-network communication paradigm. As the base RGB model is fully frozen, the proposed method does not risk catastrophic forgetting during fine-tuning and remains compatible with techniques such as IPAdapter pretrained for the base RGB model. We validate our design choices, robustness to data sparsity, and compare against existing paradigms with an extensive experimental section.
Hitchhiker's guide to cancer-associated lymphoid aggregates in histology images: manual and deep learning-based quantification approaches
Mar 06, 2024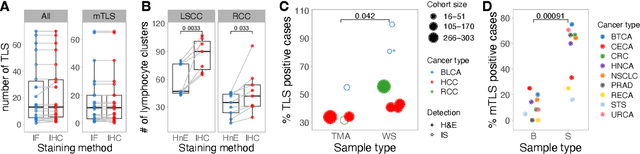
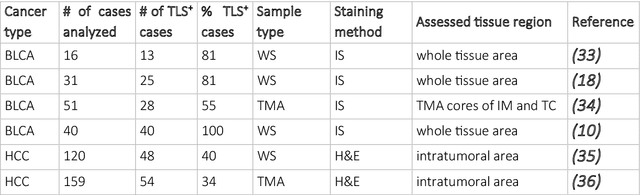
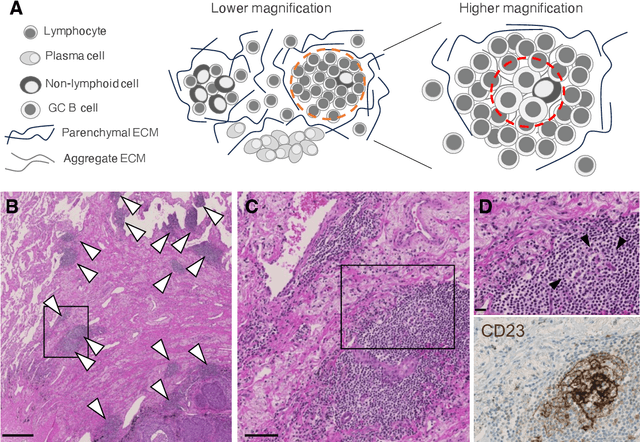
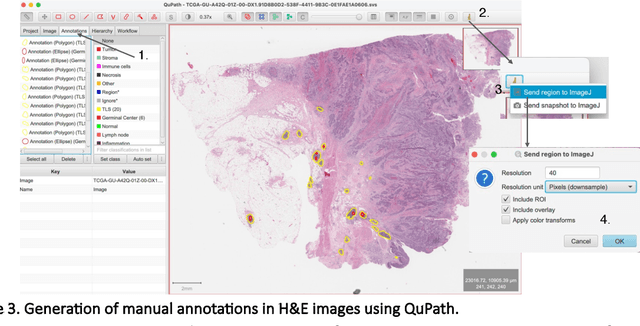
Quantification of lymphoid aggregates including tertiary lymphoid structures with germinal centers in histology images of cancer is a promising approach for developing prognostic and predictive tissue biomarkers. In this article, we provide recommendations for identifying lymphoid aggregates in tissue sections from routine pathology workflows such as hematoxylin and eosin staining. To overcome the intrinsic variability associated with manual image analysis (such as subjective decision making, attention span), we recently developed a deep learning-based algorithm called HookNet-TLS to detect lymphoid aggregates and germinal centers in various tissues. Here, we additionally provide a guideline for using manually annotated images for training and implementing HookNet-TLS for automated and objective quantification of lymphoid aggregates in various cancer types.
Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
Mar 05, 2024
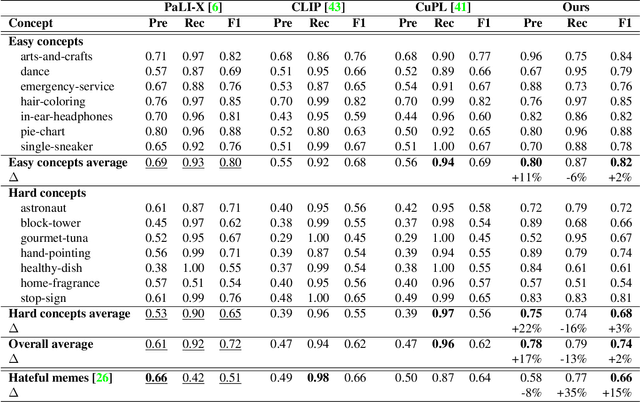
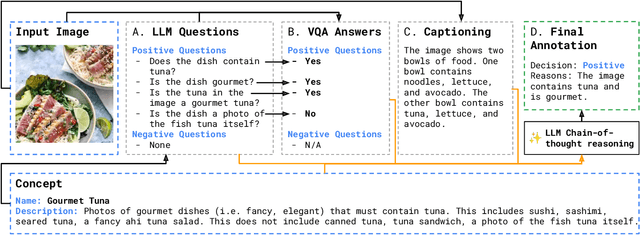
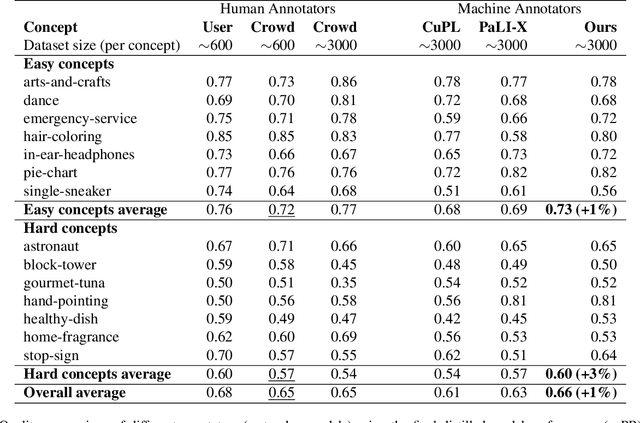
From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Improving Android Malware Detection Through Data Augmentation Using Wasserstein Generative Adversarial Networks
Mar 05, 2024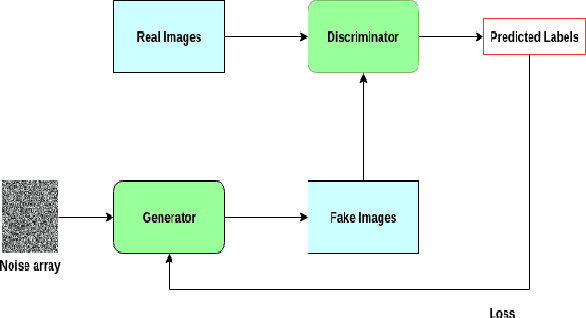
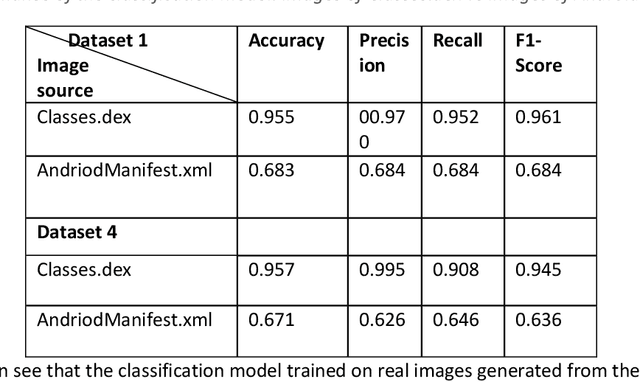
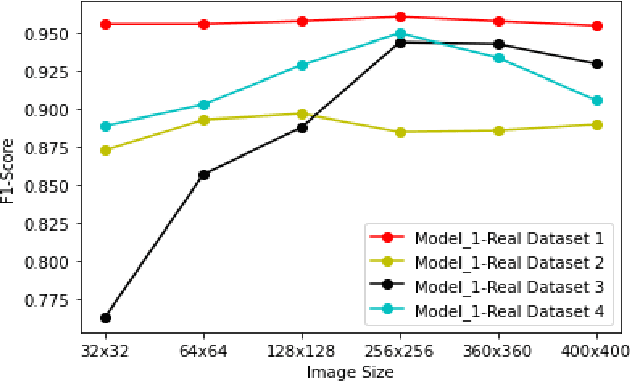
Generative Adversarial Networks (GANs) have demonstrated their versatility across various applications, including data augmentation and malware detection. This research explores the effectiveness of utilizing GAN-generated data to train a model for the detection of Android malware. Given the considerable storage requirements of Android applications, the study proposes a method to synthetically represent data using GANs, thereby reducing storage demands. The proposed methodology involves creating image representations of features extracted from an existing dataset. A GAN model is then employed to generate a more extensive dataset consisting of realistic synthetic grayscale images. Subsequently, this synthetic dataset is utilized to train a Convolutional Neural Network (CNN) designed to identify previously unseen Android malware applications. The study includes a comparative analysis of the CNN's performance when trained on real images versus synthetic images generated by the GAN. Furthermore, the research explores variations in performance between the Wasserstein Generative Adversarial Network (WGAN) and the Deep Convolutional Generative Adversarial Network (DCGAN). The investigation extends to studying the impact of image size and malware obfuscation on the classification model's effectiveness. The data augmentation approach implemented in this study resulted in a notable performance enhancement of the classification model, ranging from 1.5% to 7%, depending on the dataset. The highest achieved F1 score reached 0.975. Keywords--Generative Adversarial Networks, Android Malware, Data Augmentation, Wasserstein Generative Adversarial Network
PalmProbNet: A Probabilistic Approach to Understanding Palm Distributions in Ecuadorian Tropical Forest via Transfer Learning
Mar 05, 2024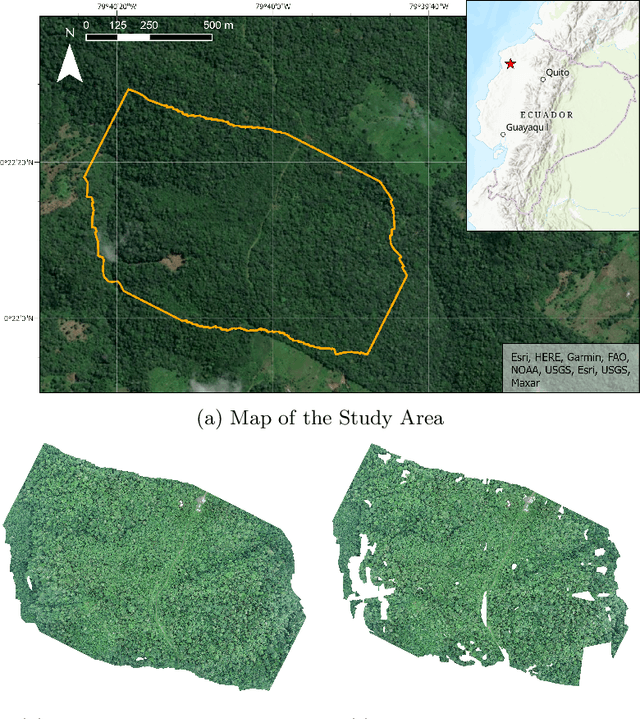
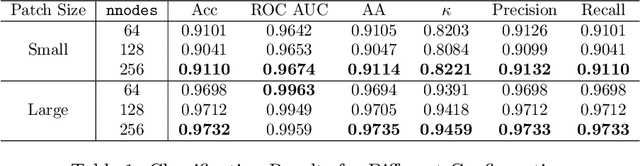


Palms play an outsized role in tropical forests and are important resources for humans and wildlife. A central question in tropical ecosystems is understanding palm distribution and abundance. However, accurately identifying and localizing palms in geospatial imagery presents significant challenges due to dense vegetation, overlapping canopies, and variable lighting conditions in mixed-forest landscapes. Addressing this, we introduce PalmProbNet, a probabilistic approach utilizing transfer learning to analyze high-resolution UAV-derived orthomosaic imagery, enabling the detection of palm trees within the dense canopy of the Ecuadorian Rainforest. This approach represents a substantial advancement in automated palm detection, effectively pinpointing palm presence and locality in mixed tropical rainforests. Our process begins by generating an orthomosaic image from UAV images, from which we extract and label palm and non-palm image patches in two distinct sizes. These patches are then used to train models with an identical architecture, consisting of an unaltered pre-trained ResNet-18 and a Multilayer Perceptron (MLP) with specifically trained parameters. Subsequently, PalmProbNet employs a sliding window technique on the landscape orthomosaic, using both small and large window sizes to generate a probability heatmap. This heatmap effectively visualizes the distribution of palms, showcasing the scalability and adaptability of our approach in various forest densities. Despite the challenging terrain, our method demonstrated remarkable performance, achieving an accuracy of 97.32% and a Cohen's kappa of 94.59% in testing.
Time Weaver: A Conditional Time Series Generation Model
Mar 05, 2024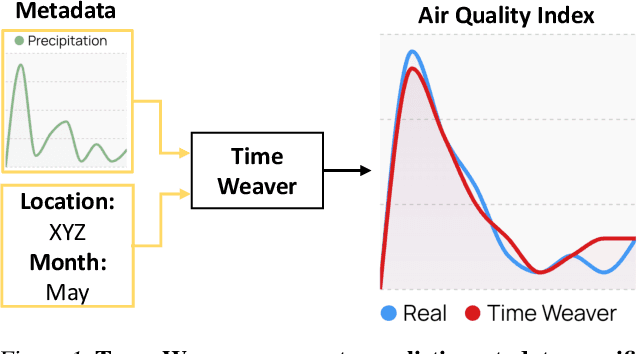
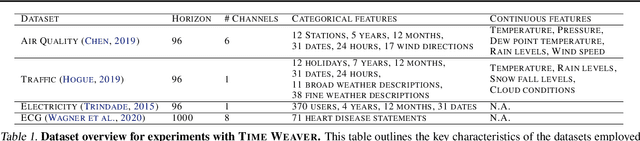
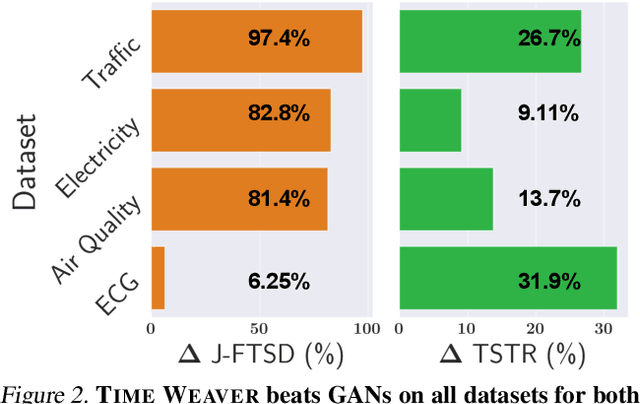
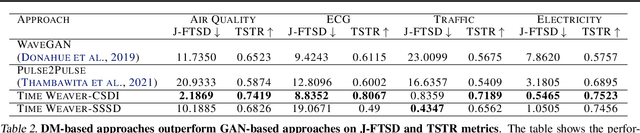
Imagine generating a city's electricity demand pattern based on weather, the presence of an electric vehicle, and location, which could be used for capacity planning during a winter freeze. Such real-world time series are often enriched with paired heterogeneous contextual metadata (weather, location, etc.). Current approaches to time series generation often ignore this paired metadata, and its heterogeneity poses several practical challenges in adapting existing conditional generation approaches from the image, audio, and video domains to the time series domain. To address this gap, we introduce Time Weaver, a novel diffusion-based model that leverages the heterogeneous metadata in the form of categorical, continuous, and even time-variant variables to significantly improve time series generation. Additionally, we show that naive extensions of standard evaluation metrics from the image to the time series domain are insufficient. These metrics do not penalize conditional generation approaches for their poor specificity in reproducing the metadata-specific features in the generated time series. Thus, we innovate a novel evaluation metric that accurately captures the specificity of conditional generation and the realism of the generated time series. We show that Time Weaver outperforms state-of-the-art benchmarks, such as Generative Adversarial Networks (GANs), by up to 27% in downstream classification tasks on real-world energy, medical, air quality, and traffic data sets.
Integrating kNN with Foundation Models for Adaptable and Privacy-Aware Image Classification
Feb 19, 2024Traditional deep learning models implicity encode knowledge limiting their transparency and ability to adapt to data changes. Yet, this adaptability is vital for addressing user data privacy concerns. We address this limitation by storing embeddings of the underlying training data independently of the model weights, enabling dynamic data modifications without retraining. Specifically, our approach integrates the $k$-Nearest Neighbor ($k$-NN) classifier with a vision-based foundation model, pre-trained self-supervised on natural images, enhancing interpretability and adaptability. We share open-source implementations of a previously unpublished baseline method as well as our performance-improving contributions. Quantitative experiments confirm improved classification across established benchmark datasets and the method's applicability to distinct medical image classification tasks. Additionally, we assess the method's robustness in continual learning and data removal scenarios. The approach exhibits great promise for bridging the gap between foundation models' performance and challenges tied to data privacy. The source code is available at https://github.com/TobArc/privacy-aware-image-classification-with-kNN.
Cas-DiffCom: Cascaded diffusion model for infant longitudinal super-resolution 3D medical image completion
Feb 21, 2024Early infancy is a rapid and dynamic neurodevelopmental period for behavior and neurocognition. Longitudinal magnetic resonance imaging (MRI) is an effective tool to investigate such a crucial stage by capturing the developmental trajectories of the brain structures. However, longitudinal MRI acquisition always meets a serious data-missing problem due to participant dropout and failed scans, making longitudinal infant brain atlas construction and developmental trajectory delineation quite challenging. Thanks to the development of an AI-based generative model, neuroimage completion has become a powerful technique to retain as much available data as possible. However, current image completion methods usually suffer from inconsistency within each individual subject in the time dimension, compromising the overall quality. To solve this problem, our paper proposed a two-stage cascaded diffusion model, Cas-DiffCom, for dense and longitudinal 3D infant brain MRI completion and super-resolution. We applied our proposed method to the Baby Connectome Project (BCP) dataset. The experiment results validate that Cas-DiffCom achieves both individual consistency and high fidelity in longitudinal infant brain image completion. We further applied the generated infant brain images to two downstream tasks, brain tissue segmentation and developmental trajectory delineation, to declare its task-oriented potential in the neuroscience field.
Critical windows: non-asymptotic theory for feature emergence in diffusion models
Mar 03, 2024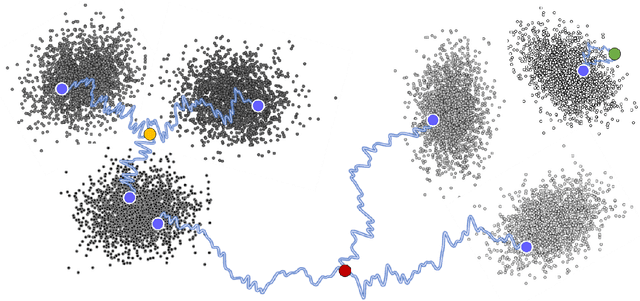
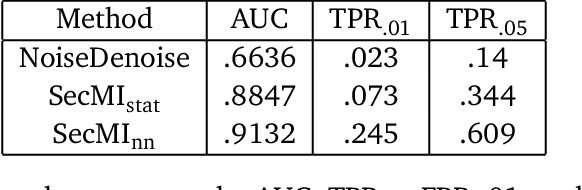
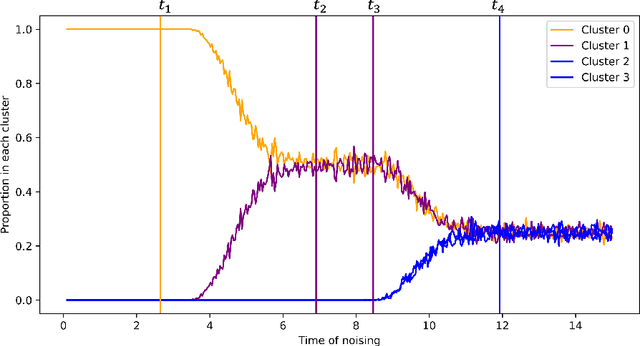

We develop theory to understand an intriguing property of diffusion models for image generation that we term critical windows. Empirically, it has been observed that there are narrow time intervals in sampling during which particular features of the final image emerge, e.g. the image class or background color (Ho et al., 2020b; Georgiev et al., 2023; Raya & Ambrogioni, 2023; Sclocchi et al., 2024; Biroli et al., 2024). While this is advantageous for interpretability as it implies one can localize properties of the generation to a small segment of the trajectory, it seems at odds with the continuous nature of the diffusion. We propose a formal framework for studying these windows and show that for data coming from a mixture of strongly log-concave densities, these windows can be provably bounded in terms of certain measures of inter- and intra-group separation. We also instantiate these bounds for concrete examples like well-conditioned Gaussian mixtures. Finally, we use our bounds to give a rigorous interpretation of diffusion models as hierarchical samplers that progressively "decide" output features over a discrete sequence of times. We validate our bounds with synthetic experiments. Additionally, preliminary experiments on Stable Diffusion suggest critical windows may serve as a useful tool for diagnosing fairness and privacy violations in real-world diffusion models.
APISR: Anime Production Inspired Real-World Anime Super-Resolution
Mar 03, 2024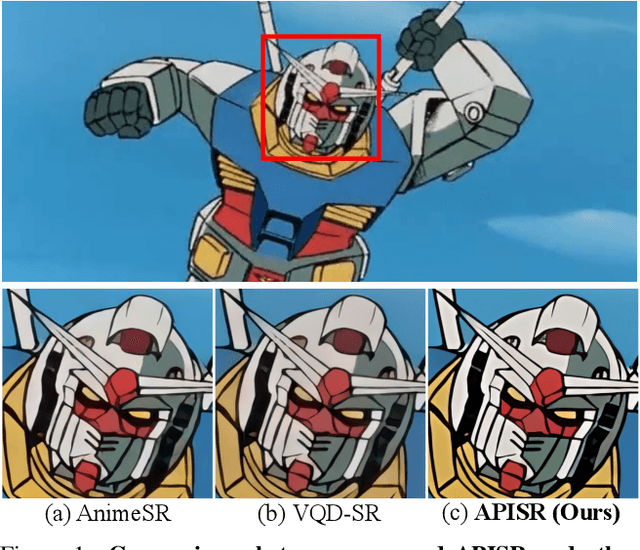
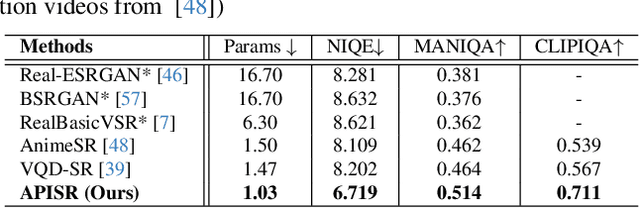
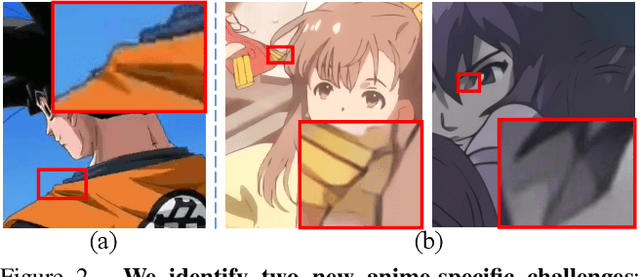
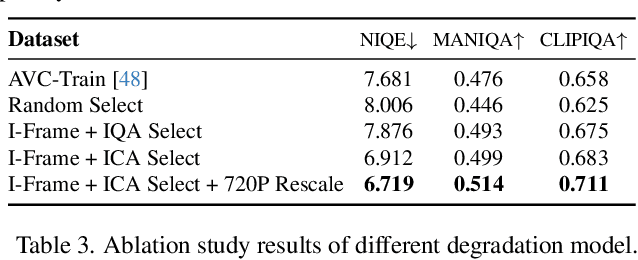
While real-world anime super-resolution (SR) has gained increasing attention in the SR community, existing methods still adopt techniques from the photorealistic domain. In this paper, we analyze the anime production workflow and rethink how to use characteristics of it for the sake of the real-world anime SR. First, we argue that video networks and datasets are not necessary for anime SR due to the repetition use of hand-drawing frames. Instead, we propose an anime image collection pipeline by choosing the least compressed and the most informative frames from the video sources. Based on this pipeline, we introduce the Anime Production-oriented Image (API) dataset. In addition, we identify two anime-specific challenges of distorted and faint hand-drawn lines and unwanted color artifacts. We address the first issue by introducing a prediction-oriented compression module in the image degradation model and a pseudo-ground truth preparation with enhanced hand-drawn lines. In addition, we introduce the balanced twin perceptual loss combining both anime and photorealistic high-level features to mitigate unwanted color artifacts and increase visual clarity. We evaluate our method through extensive experiments on the public benchmark, showing our method outperforms state-of-the-art approaches by a large margin.