 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scalable Kernel-Based Minimum Mean Square Error Estimator for Accelerated Image Error Concealment
May 23, 2022
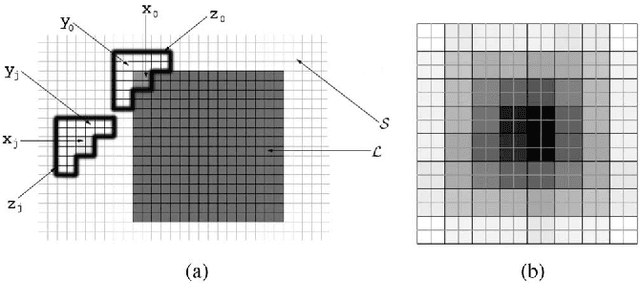

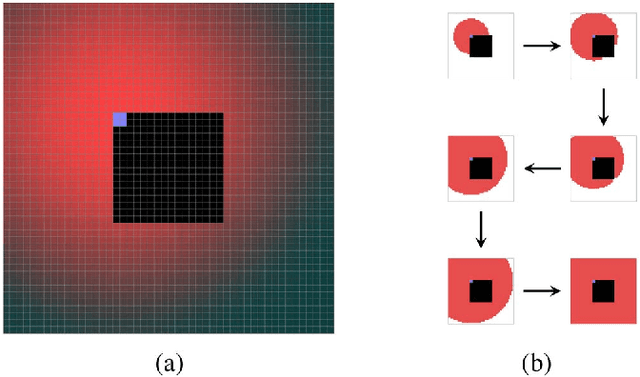
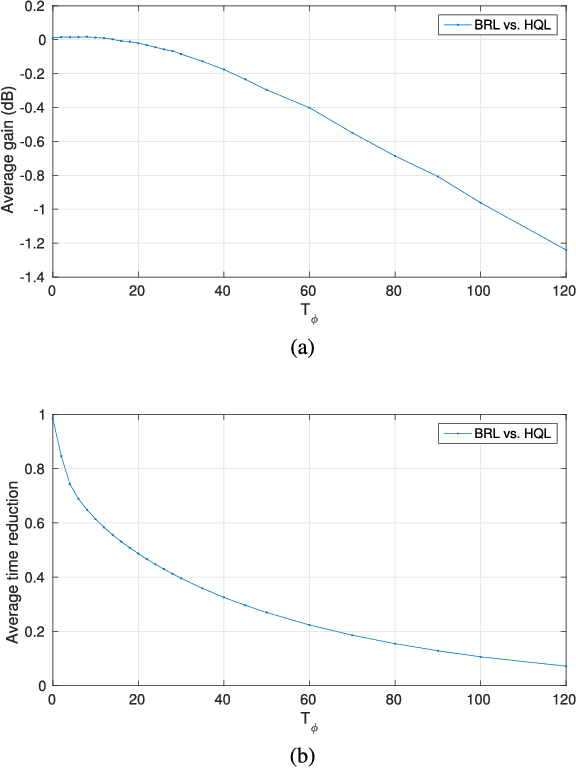
Error concealment is of great importance for block-based video systems, such as DVB or video streaming services. In this paper, we propose a novel scalable spatial error concealment algorithm that aims at obtaining high quality reconstructions with reduced computational burden. The proposed technique exploits the excellent reconstructing abilities of the kernel-based minimum mean square error K-MMSE estimator. We propose to decompose this approach into a set of hierarchically stacked layers. The first layer performs the basic reconstruction that the subsequent layers can eventually refine. In addition, we design a layer management mechanism, based on profiles, that dynamically adapts the use of higher layers to the visual complexity of the area being reconstructed. The proposed technique outperforms other state-of-the-art algorithms and produces high quality reconstructions, equivalent to K-MMSE, while requiring around one tenth of its computational time.
Efficient Textured Mesh Recovery from Multiple Views with Differentiable Rendering
May 25, 2022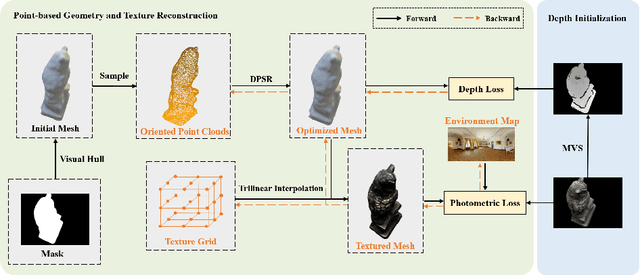
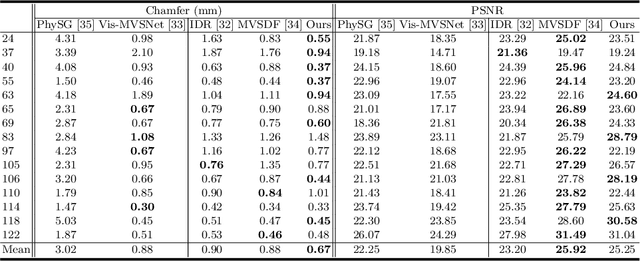


Despite of the promising results on shape and color recovery using self-supervision, the multi-layer perceptrons-based methods usually costs hours to train the deep neural network due to the implicit surface representation. Moreover, it is quite computational intensive to render a single image, since a forward network inference is required for each pixel. To tackle these challenges, in this paper, we propose an efficient coarse-to-fine approach to recover the textured mesh from multi-view images. Specifically, we take advantage of a differentiable Poisson Solver to represent the shape, which is able to produce topology-agnostic and watertight surfaces. To account for the depth information, we optimize the shape geometry by minimizing the difference between the rendered mesh with the depth predicted by the learning-based multi-view stereo algorithm. In contrast to the implicit neural representation on shape and color, we introduce a physically based inverse rendering scheme to jointly estimate the lighting and reflectance of the objects, which is able to render the high resolution image at real-time. Additionally, we fine-tune the extracted mesh by inverse rendering to obtain the mesh with fine details and high fidelity image. We have conducted the extensive experiments on several multi-view stereo datasets, whose promising results demonstrate the efficacy of our proposed approach. We will make our full implementation publicly available.
NTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021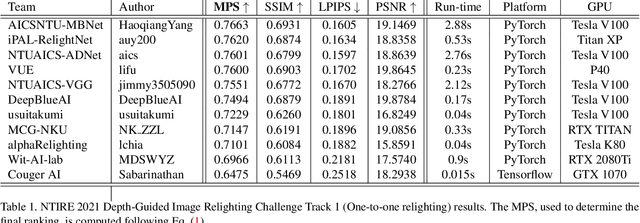

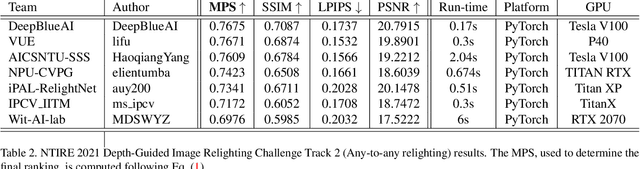

Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
A Joint Graph and Image Convolution Network for Automatic Brain Tumor Segmentation
Sep 12, 2021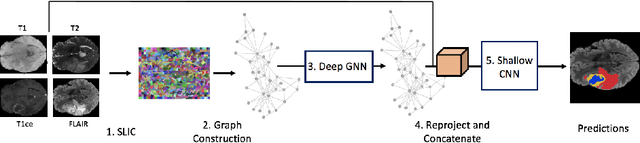
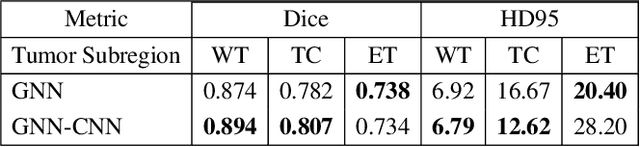
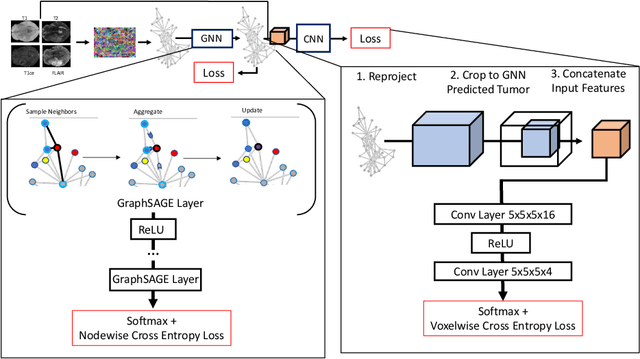
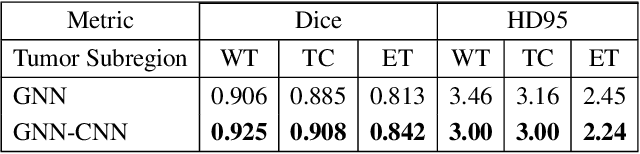
We present a joint graph convolution-image convolution neural network as our submission to the Brain Tumor Segmentation (BraTS) 2021 challenge. We model each brain as a graph composed of distinct image regions, which is initially segmented by a graph neural network (GNN). Subsequently, the tumorous volume identified by the GNN is further refined by a simple (voxel) convolutional neural network (CNN), which produces the final segmentation. This approach captures both global brain feature interactions via the graphical representation and local image details through the use of convolutional filters. We find that the GNN component by itself can effectively identify and segment the brain tumors. The addition of the CNN further improves the median performance of the model by 2 percent across all metrics evaluated. On the validation set, our joint GNN-CNN model achieves mean Dice scores of 0.89, 0.81, 0.73 and mean Hausdorff distances (95th percentile) of 6.8, 12.6, 28.2mm on the whole tumor, core tumor, and enhancing tumor, respectively.
Semantic-Guided Zero-Shot Learning for Low-Light Image/Video Enhancement
Oct 03, 2021
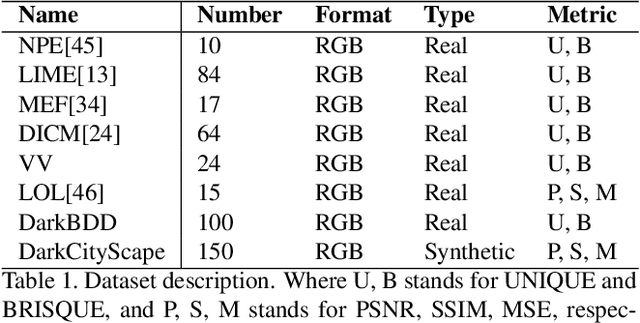
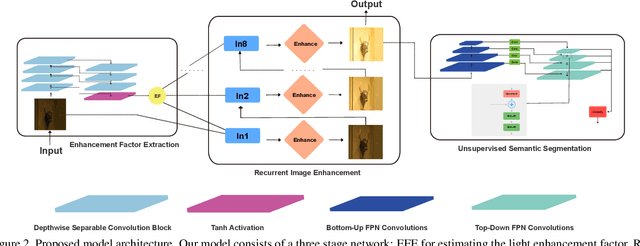
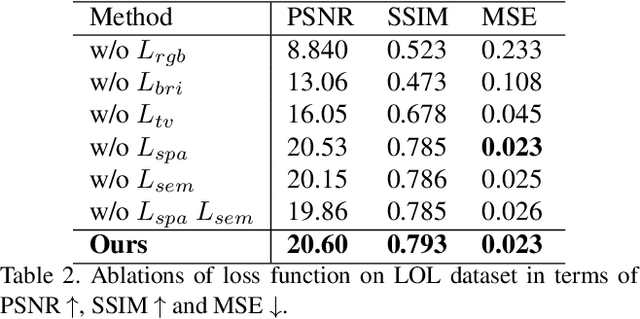
Low-light images challenge both human perceptions and computer vision algorithms. It is crucial to make algorithms robust to enlighten low-light images for computational photography and computer vision applications such as real-time detection and segmentation tasks. This paper proposes a semantic-guided zero-shot low-light enhancement network which is trained in the absence of paired images, unpaired datasets, and segmentation annotation. Firstly, we design an efficient enhancement factor extraction network using depthwise separable convolution. Secondly, we propose a recurrent image enhancement network for progressively enhancing the low-light image. Finally, we introduce an unsupervised semantic segmentation network for preserving the semantic information. Extensive experiments on various benchmark datasets and a low-light video demonstrate that our model outperforms the previous state-of-the-art qualitatively and quantitatively. We further discuss the benefits of the proposed method for low-light detection and segmentation.
Multi-Task Learning with Multi-query Transformer for Dense Prediction
May 31, 2022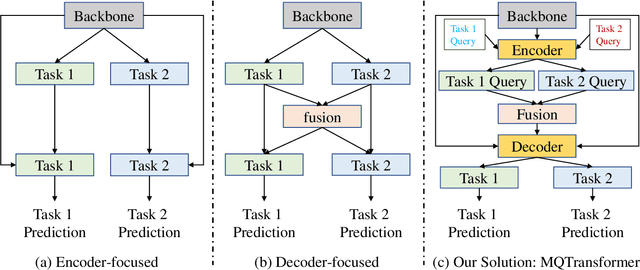
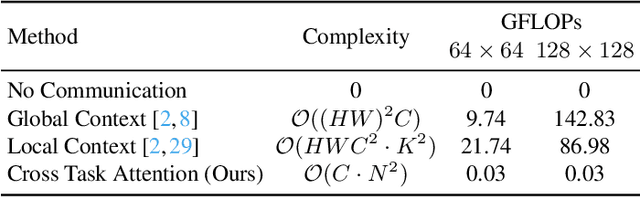
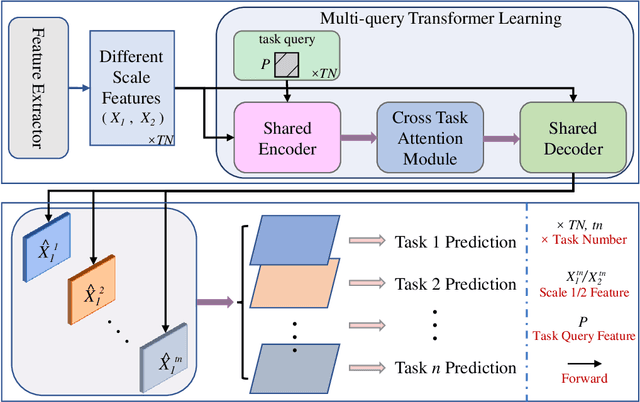
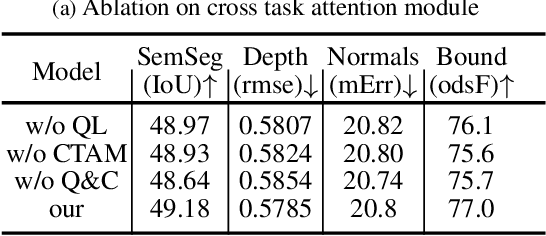
Previous multi-task dense prediction studies developed complex pipelines such as multi-modal distillations in multiple stages or searching for task relational contexts for each task. The core insight beyond these methods is to maximize the mutual effects between each task. Inspired by the recent query-based Transformers, we propose a simpler pipeline named Multi-Query Transformer (MQTransformer) that is equipped with multiple queries from different tasks to facilitate the reasoning among multiple tasks and simplify the cross task pipeline. Instead of modeling the dense per-pixel context among different tasks, we seek a task-specific proxy to perform cross-task reasoning via multiple queries where each query encodes the task-related context. The MQTransformer is composed of three key components: shared encoder, cross task attention and shared decoder. We first model each task with a task-relevant and scale-aware query, and then both the image feature output by the feature extractor and the task-relevant query feature are fed into the shared encoder, thus encoding the query feature from the image feature. Secondly, we design a cross task attention module to reason the dependencies among multiple tasks and feature scales from two perspectives including different tasks of the same scale and different scales of the same task. Then we use a shared decoder to gradually refine the image features with the reasoned query features from different tasks. Extensive experiment results on two dense prediction datasets (NYUD-v2 and PASCAL-Context) show that the proposed method is an effective approach and achieves the state-of-the-art result. Code will be available.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022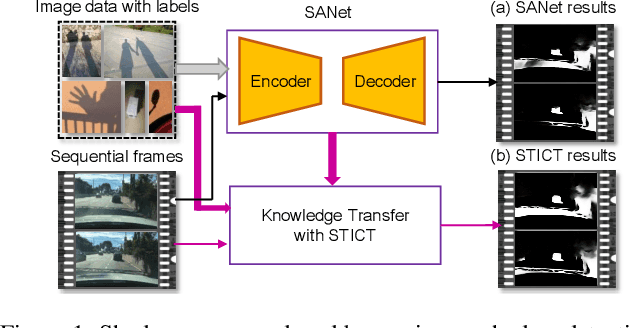

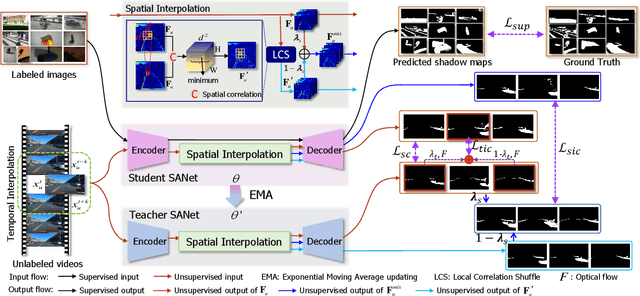
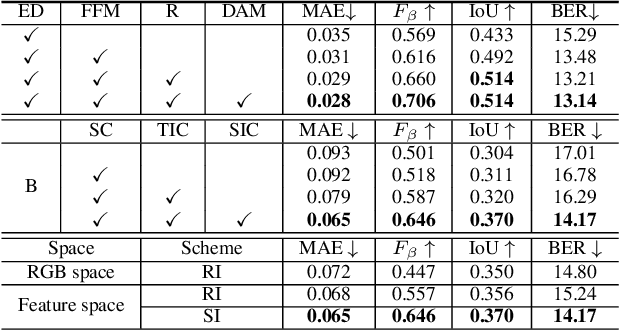
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.
Discover and Mitigate Unknown Biases with Debiasing Alternate Networks
Jul 20, 2022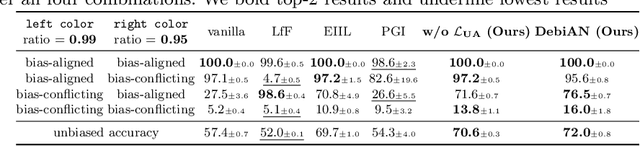
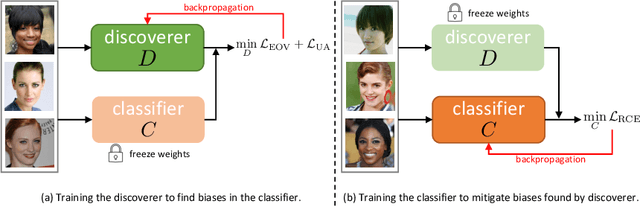
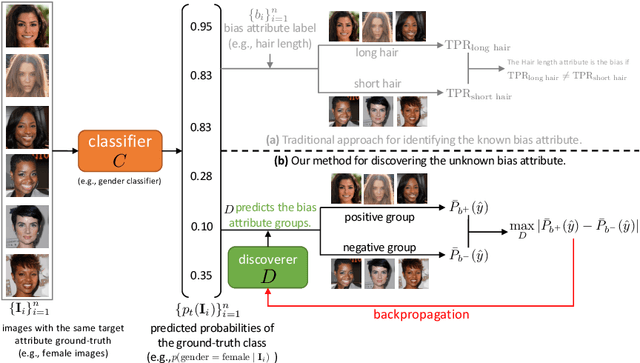

Deep image classifiers have been found to learn biases from datasets. To mitigate the biases, most previous methods require labels of protected attributes (e.g., age, skin tone) as full-supervision, which has two limitations: 1) it is infeasible when the labels are unavailable; 2) they are incapable of mitigating unknown biases -- biases that humans do not preconceive. To resolve those problems, we propose Debiasing Alternate Networks (DebiAN), which comprises two networks -- a Discoverer and a Classifier. By training in an alternate manner, the discoverer tries to find multiple unknown biases of the classifier without any annotations of biases, and the classifier aims at unlearning the biases identified by the discoverer. While previous works evaluate debiasing results in terms of a single bias, we create Multi-Color MNIST dataset to better benchmark mitigation of multiple biases in a multi-bias setting, which not only reveals the problems in previous methods but also demonstrates the advantage of DebiAN in identifying and mitigating multiple biases simultaneously. We further conduct extensive experiments on real-world datasets, showing that the discoverer in DebiAN can identify unknown biases that may be hard to be found by humans. Regarding debiasing, DebiAN achieves strong bias mitigation performance.
SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
Dec 07, 2021
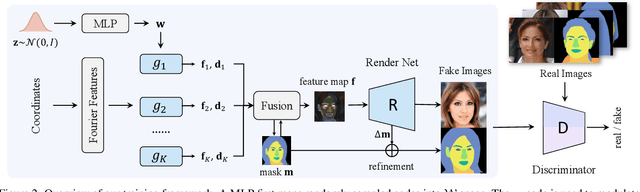
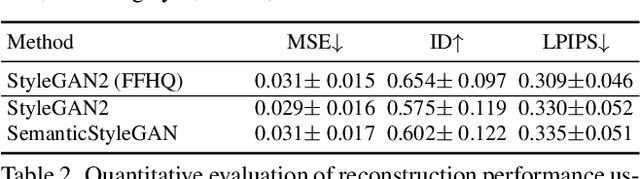
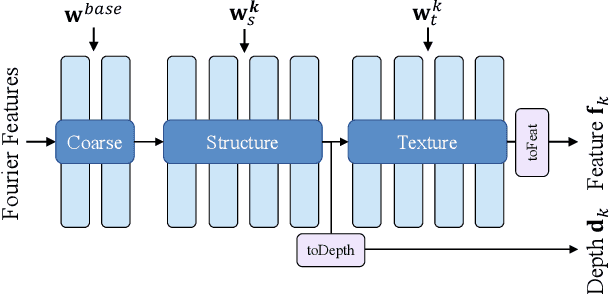
Recent studies have shown that StyleGANs provide promising prior models for downstream tasks on image synthesis and editing. However, since the latent codes of StyleGANs are designed to control global styles, it is hard to achieve a fine-grained control over synthesized images. We present SemanticStyleGAN, where a generator is trained to model local semantic parts separately and synthesizes images in a compositional way. The structure and texture of different local parts are controlled by corresponding latent codes. Experimental results demonstrate that our model provides a strong disentanglement between different spatial areas. When combined with editing methods designed for StyleGANs, it can achieve a more fine-grained control to edit synthesized or real images. The model can also be extended to other domains via transfer learning. Thus, as a generic prior model with built-in disentanglement, it could facilitate the development of GAN-based applications and enable more potential downstream tasks.
Generative Domain Adaptation for Face Anti-Spoofing
Jul 20, 2022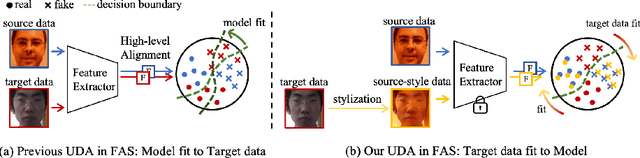
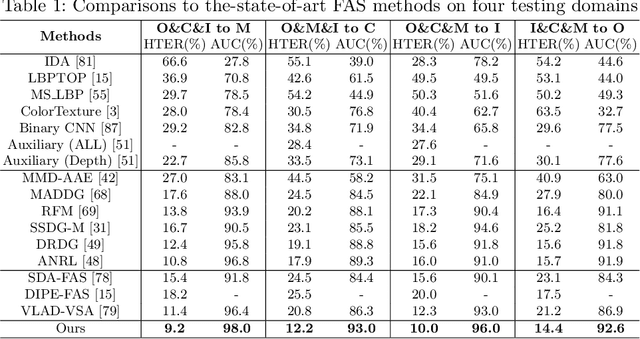
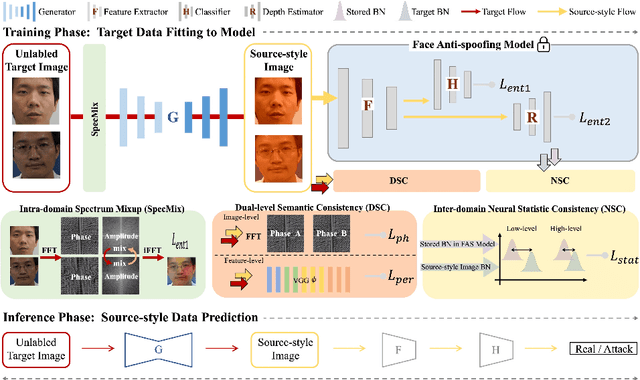
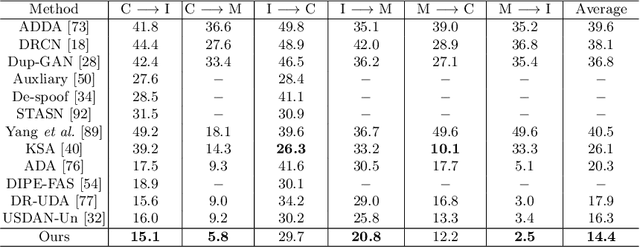
Face anti-spoofing (FAS) approaches based on unsupervised domain adaption (UDA) have drawn growing attention due to promising performances for target scenarios. Most existing UDA FAS methods typically fit the trained models to the target domain via aligning the distribution of semantic high-level features. However, insufficient supervision of unlabeled target domains and neglect of low-level feature alignment degrade the performances of existing methods. To address these issues, we propose a novel perspective of UDA FAS that directly fits the target data to the models, i.e., stylizes the target data to the source-domain style via image translation, and further feeds the stylized data into the well-trained source model for classification. The proposed Generative Domain Adaptation (GDA) framework combines two carefully designed consistency constraints: 1) Inter-domain neural statistic consistency guides the generator in narrowing the inter-domain gap. 2) Dual-level semantic consistency ensures the semantic quality of stylized images. Besides, we propose intra-domain spectrum mixup to further expand target data distributions to ensure generalization and reduce the intra-domain gap. Extensive experiments and visualizations demonstrate the effectiveness of our method against the state-of-the-art methods.