 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Style Transfer and Content-Style Disentanglement
Nov 25, 2021
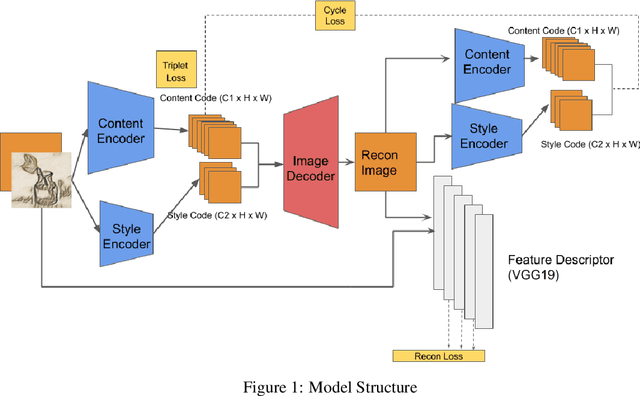
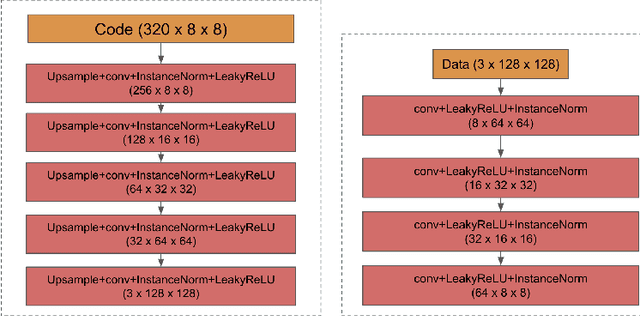

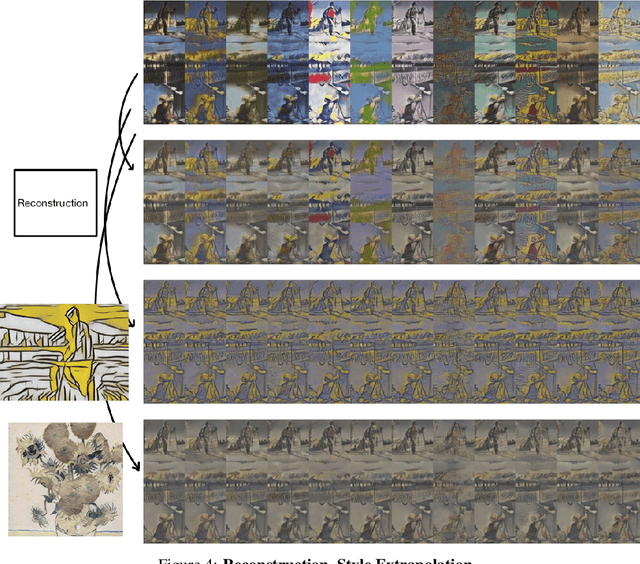
We propose a way of learning disentangled content-style representation of image, allowing us to extrapolate images to any style as well as interpolate between any pair of styles. By augmenting data set in a supervised setting and imposing triplet loss, we ensure the separation of information encoded by content and style representation. We also make use of cycle-consistency loss to guarantee that images could be reconstructed faithfully by their representation.
Evolution of Activation Functions for Deep Learning-Based Image Classification
Jun 24, 2022
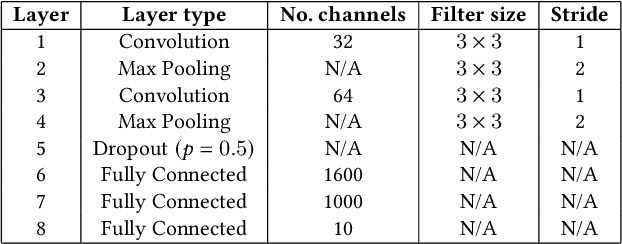
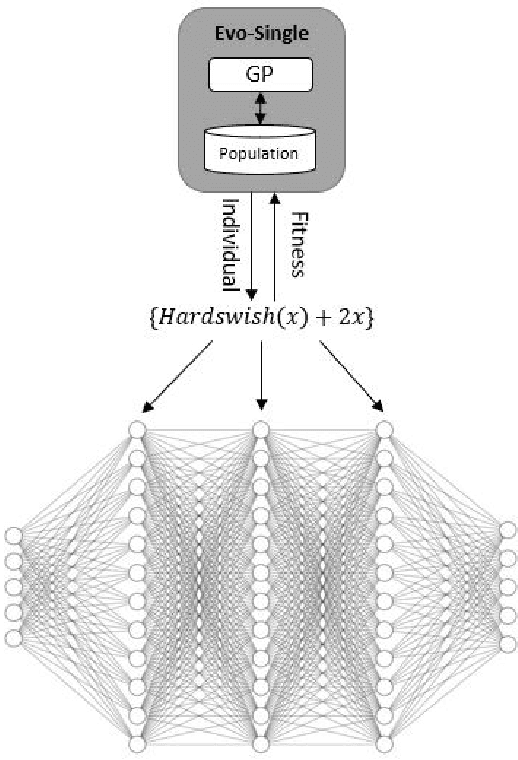
Activation functions (AFs) play a pivotal role in the performance of neural networks. The Rectified Linear Unit (ReLU) is currently the most commonly used AF. Several replacements to ReLU have been suggested but improvements have proven inconsistent. Some AFs exhibit better performance for specific tasks, but it is hard to know a priori how to select the appropriate one(s). Studying both standard fully connected neural networks (FCNs) and convolutional neural networks (CNNs), we propose a novel, three-population, coevolutionary algorithm to evolve AFs, and compare it to four other methods, both evolutionary and non-evolutionary. Tested on four datasets -- MNIST, FashionMNIST, KMNIST, and USPS -- coevolution proves to be a performant algorithm for finding good AFs and AF architectures.
Hypernet-Ensemble Learning of Segmentation Probability for Medical Image Segmentation with Ambiguous Labels
Dec 13, 2021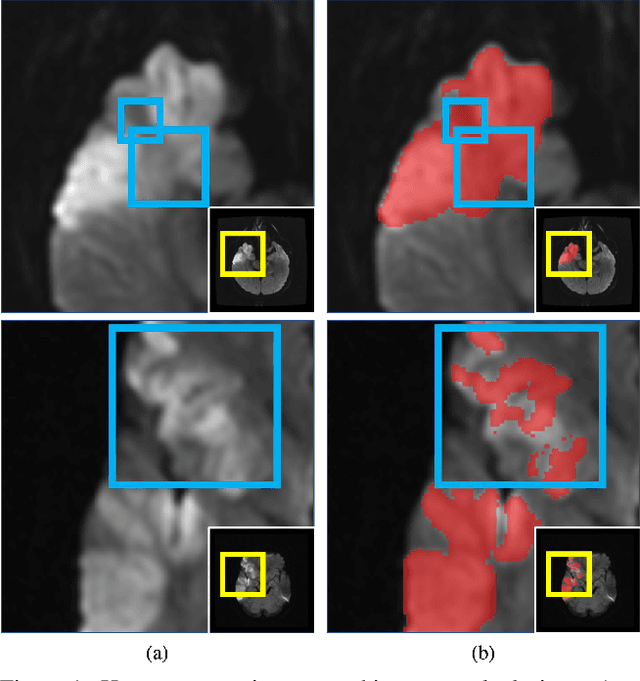
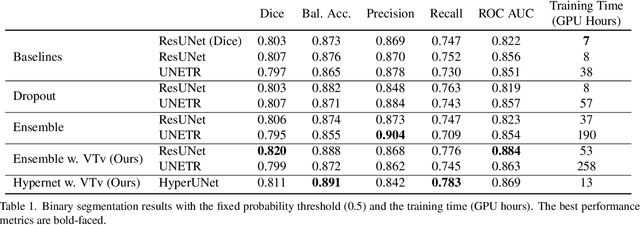
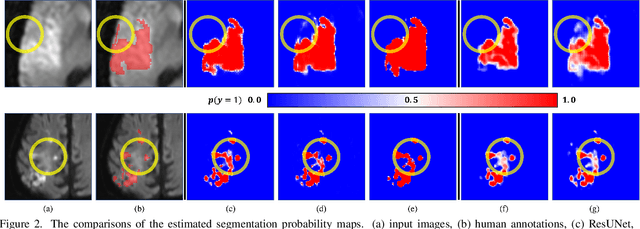
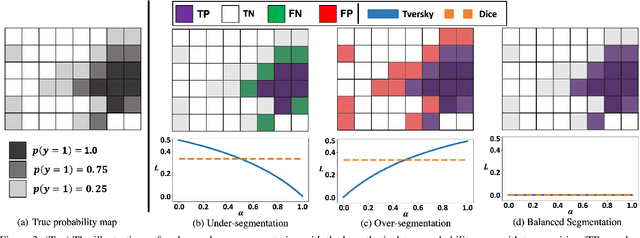
Despite the superior performance of Deep Learning (DL) on numerous segmentation tasks, the DL-based approaches are notoriously overconfident about their prediction with highly polarized label probability. This is often not desirable for many applications with the inherent label ambiguity even in human annotations. This challenge has been addressed by leveraging multiple annotations per image and the segmentation uncertainty. However, multiple per-image annotations are often not available in a real-world application and the uncertainty does not provide full control on segmentation results to users. In this paper, we propose novel methods to improve the segmentation probability estimation without sacrificing performance in a real-world scenario that we have only one ambiguous annotation per image. We marginalize the estimated segmentation probability maps of networks that are encouraged to under-/over-segment with the varying Tversky loss without penalizing balanced segmentation. Moreover, we propose a unified hypernetwork ensemble method to alleviate the computational burden of training multiple networks. Our approaches successfully estimated the segmentation probability maps that reflected the underlying structures and provided the intuitive control on segmentation for the challenging 3D medical image segmentation. Although the main focus of our proposed methods is not to improve the binary segmentation performance, our approaches marginally outperformed the state-of-the-arts. The codes are available at \url{https://github.com/sh4174/HypernetEnsemble}.
Deep-Learning-Based Single-Image Height Reconstruction from Very-High-Resolution SAR Intensity Data
Nov 19, 2021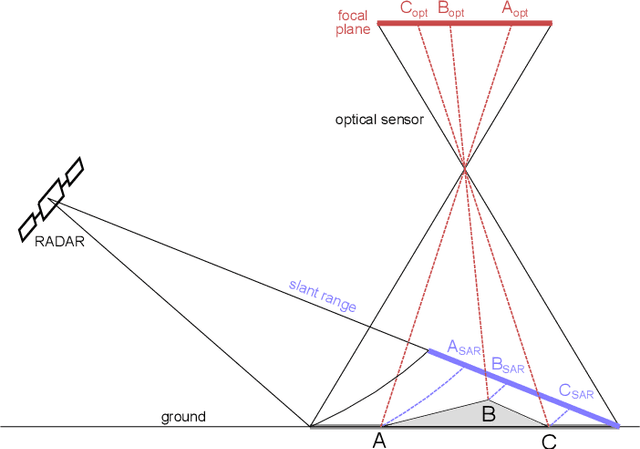
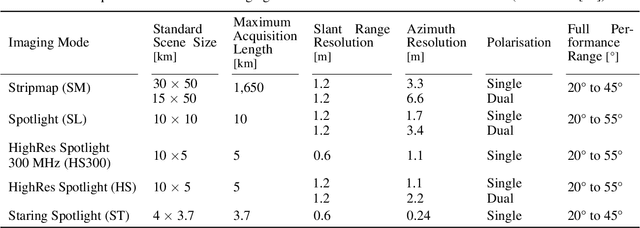
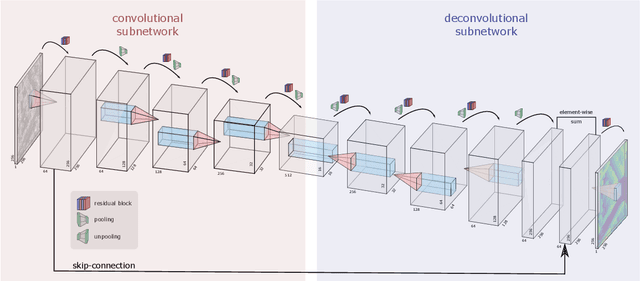
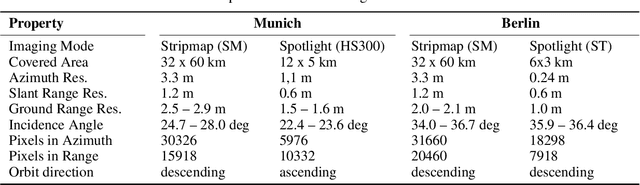
Originally developed in fields such as robotics and autonomous driving with image-based navigation in mind, deep learning-based single-image depth estimation (SIDE) has found great interest in the wider image analysis community. Remote sensing is no exception, as the possibility to estimate height maps from single aerial or satellite imagery bears great potential in the context of topographic reconstruction. A few pioneering investigations have demonstrated the general feasibility of single image height prediction from optical remote sensing images and motivate further studies in that direction. With this paper, we present the first-ever demonstration of deep learning-based single image height prediction for the other important sensor modality in remote sensing: synthetic aperture radar (SAR) data. Besides the adaptation of a convolutional neural network (CNN) architecture for SAR intensity images, we present a workflow for the generation of training data, and extensive experimental results for different SAR imaging modes and test sites. Since we put a particular emphasis on transferability, we are able to confirm that deep learning-based single-image height estimation is not only possible, but also transfers quite well to unseen data, even if acquired by different imaging modes and imaging parameters.
DSRGAN: Detail Prior-Assisted Perceptual Single Image Super-Resolution via Generative Adversarial Networks
Dec 25, 2021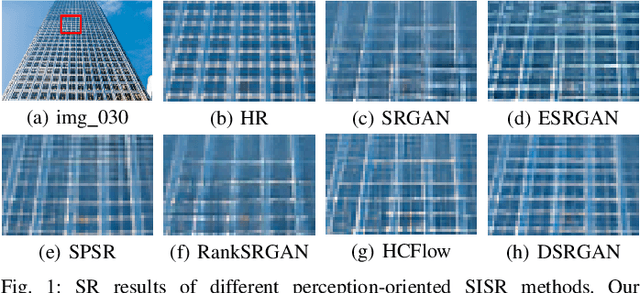
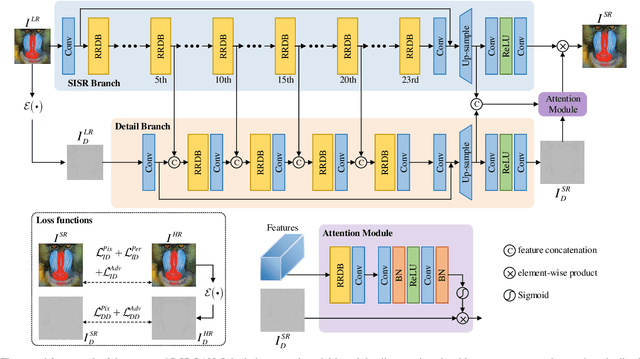


The generative adversarial network (GAN) is successfully applied to study the perceptual single image superresolution (SISR). However, the GAN often tends to generate images with high frequency details being inconsistent with the real ones. Inspired by conventional detail enhancement algorithms, we propose a novel prior knowledge, the detail prior, to assist the GAN in alleviating this problem and restoring more realistic details. The proposed method, named DSRGAN, includes a well designed detail extraction algorithm to capture the most important high frequency information from images. Then, two discriminators are utilized for supervision on image-domain and detail-domain restorations, respectively. The DSRGAN merges the restored detail into the final output via a detail enhancement manner. The special design of DSRGAN takes advantages from both the model-based conventional algorithm and the data-driven deep learning network. Experimental results demonstrate that the DSRGAN outperforms the state-of-the-art SISR methods on perceptual metrics and achieves comparable results in terms of fidelity metrics simultaneously. Following the DSRGAN, it is feasible to incorporate other conventional image processing algorithms into a deep learning network to form a model-based deep SISR.
Using Multi-modal Data for Improving Generalizability and Explainability of Disease Classification in Radiology
Jul 29, 2022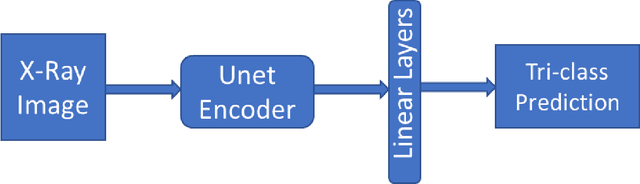
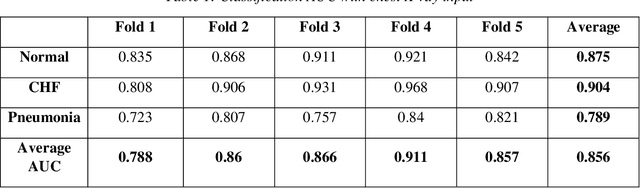
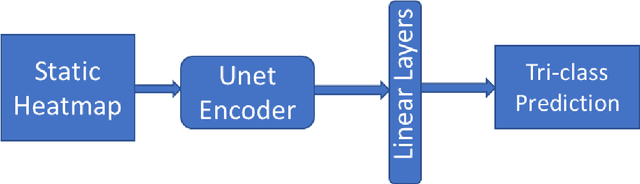

Traditional datasets for the radiological diagnosis tend to only provide the radiology image alongside the radiology report. However, radiology reading as performed by radiologists is a complex process, and information such as the radiologist's eye-fixations over the course of the reading has the potential to be an invaluable data source to learn from. Nonetheless, the collection of such data is expensive and time-consuming. This leads to the question of whether such data is worth the investment to collect. This paper utilizes the recently published Eye-Gaze dataset to perform an exhaustive study on the impact on performance and explainability of deep learning (DL) classification in the face of varying levels of input features, namely: radiology images, radiology report text, and radiologist eye-gaze data. We find that the best classification performance of X-ray images is achieved with a combination of radiology report free-text and radiology image, with the eye-gaze data providing no performance boost. Nonetheless, eye-gaze data serving as secondary ground truth alongside the class label results in highly explainable models that generate better attention maps compared to models trained to do classification and attention map generation without eye-gaze data.
M^4I: Multi-modal Models Membership Inference
Sep 15, 2022
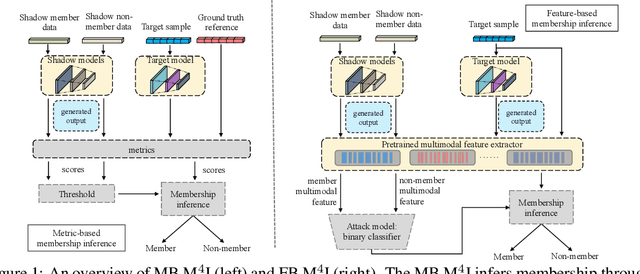
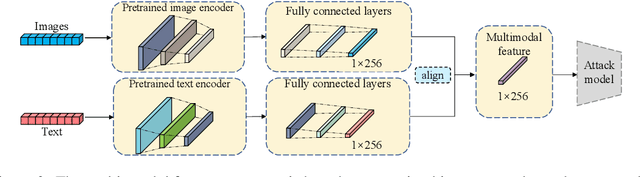
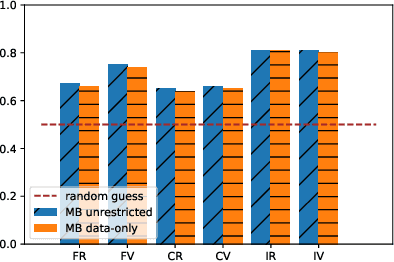
With the development of machine learning techniques, the attention of research has been moved from single-modal learning to multi-modal learning, as real-world data exist in the form of different modalities. However, multi-modal models often carry more information than single-modal models and they are usually applied in sensitive scenarios, such as medical report generation or disease identification. Compared with the existing membership inference against machine learning classifiers, we focus on the problem that the input and output of the multi-modal models are in different modalities, such as image captioning. This work studies the privacy leakage of multi-modal models through the lens of membership inference attack, a process of determining whether a data record involves in the model training process or not. To achieve this, we propose Multi-modal Models Membership Inference (M^4I) with two attack methods to infer the membership status, named metric-based (MB) M^4I and feature-based (FB) M^4I, respectively. More specifically, MB M^4I adopts similarity metrics while attacking to infer target data membership. FB M^4I uses a pre-trained shadow multi-modal feature extractor to achieve the purpose of data inference attack by comparing the similarities from extracted input and output features. Extensive experimental results show that both attack methods can achieve strong performances. Respectively, 72.5% and 94.83% of attack success rates on average can be obtained under unrestricted scenarios. Moreover, we evaluate multiple defense mechanisms against our attacks. The source code of M^4I attacks is publicly available at https://github.com/MultimodalMI/Multimodal-membership-inference.git.
Automated SSIM Regression for Detection and Quantification of Motion Artefacts in Brain MR Images
Jun 14, 2022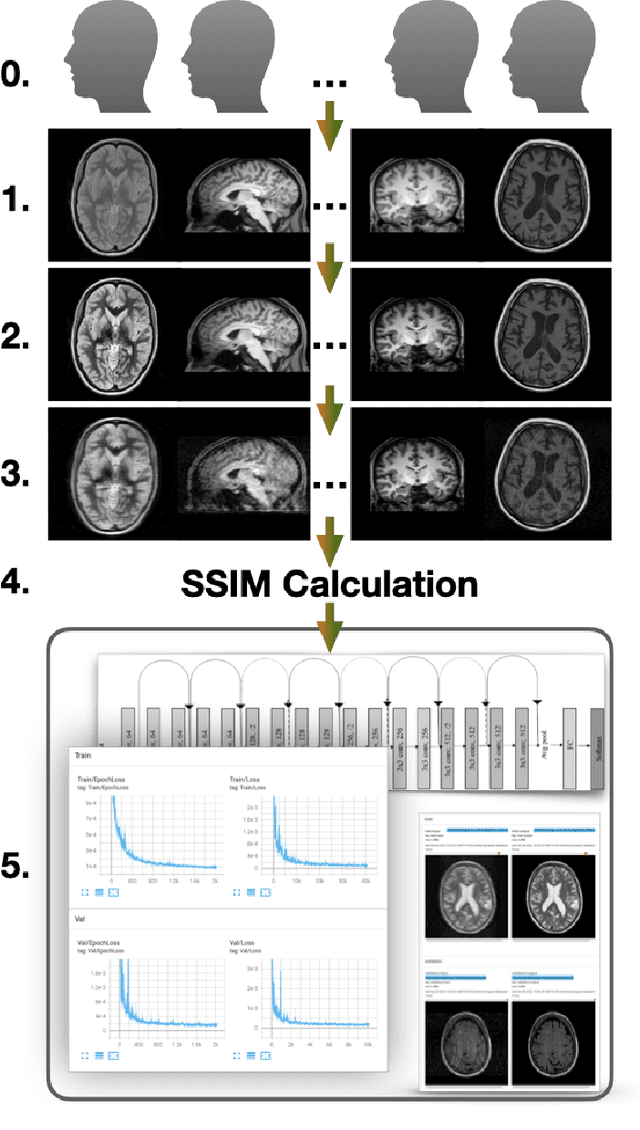
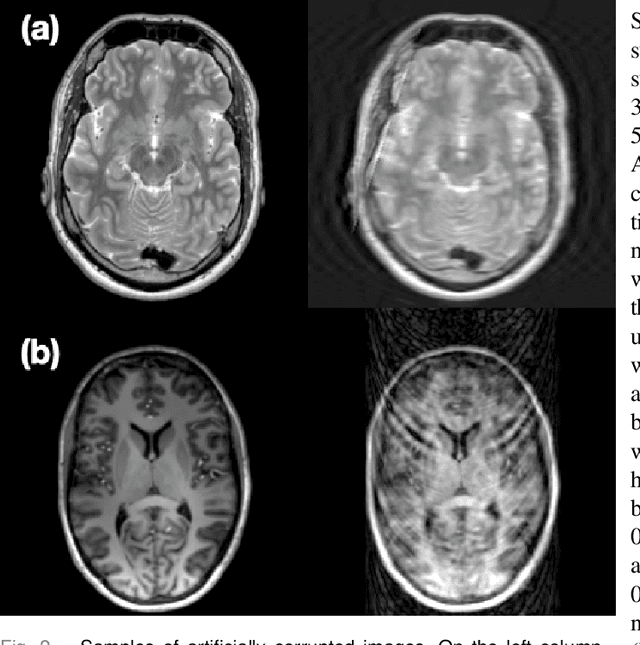
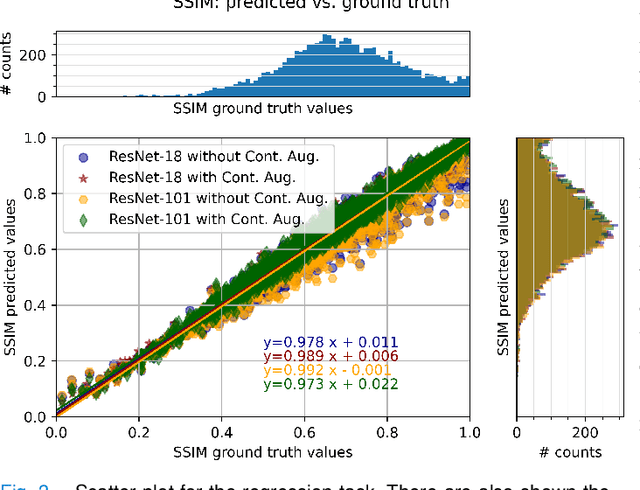
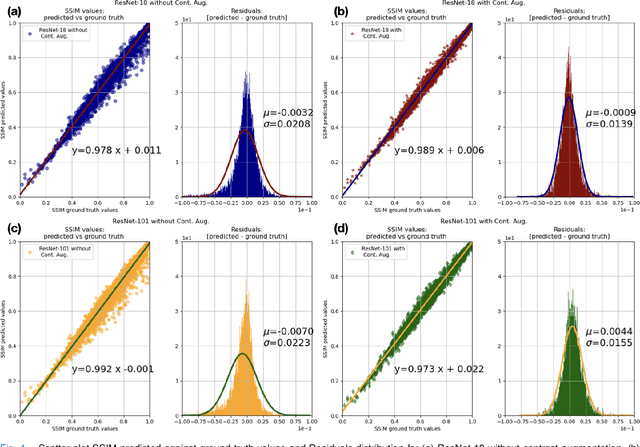
Motion artefacts in magnetic resonance brain images are a crucial issue. The assessment of MR image quality is fundamental before proceeding with the clinical diagnosis. If the motion artefacts alter a correct delineation of structure and substructures of the brain, lesions, tumours and so on, the patients need to be re-scanned. Otherwise, neuro-radiologists could report an inaccurate or incorrect diagnosis. The first step right after scanning a patient is the "\textit{image quality assessment}" in order to decide if the acquired images are diagnostically acceptable. An automated image quality assessment based on the structural similarity index (SSIM) regression through a residual neural network has been proposed here, with the possibility to perform also the classification in different groups - by subdividing with SSIM ranges. This method predicts SSIM values of an input image in the absence of a reference ground truth image. The networks were able to detect motion artefacts, and the best performance for the regression and classification task has always been achieved with ResNet-18 with contrast augmentation. Mean and standard deviation of residuals' distribution were $\mu=-0.0009$ and $\sigma=0.0139$, respectively. Whilst for the classification task in 3, 5 and 10 classes, the best accuracies were 97, 95 and 89\%, respectively. The obtained results show that the proposed method could be a tool in supporting neuro-radiologists and radiographers in evaluating the image quality before the diagnosis.
Active learning for interactive satellite image change detection
Oct 08, 2021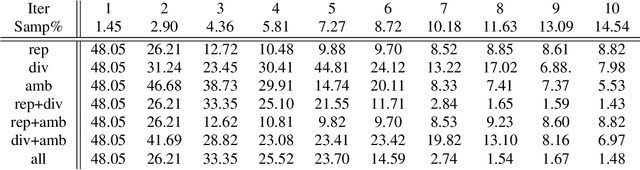
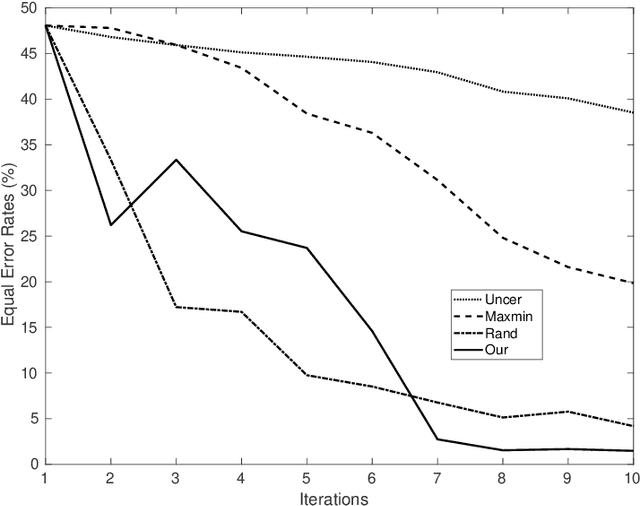
We introduce in this paper a novel active learning algorithm for satellite image change detection. The proposed solution is interactive and based on a question and answer model, which asks an oracle (annotator) the most informative questions about the relevance of sampled satellite image pairs, and according to the oracle's responses, updates a decision function iteratively. We investigate a novel framework which models the probability that samples are relevant; this probability is obtained by minimizing an objective function capturing representativity, diversity and ambiguity. Only data with a high probability according to these criteria are selected and displayed to the oracle for further annotation. Extensive experiments on the task of satellite image change detection after natural hazards (namely tornadoes) show the relevance of the proposed method against the related work.
Compiler-Aware Neural Architecture Search for On-Mobile Real-time Super-Resolution
Jul 25, 2022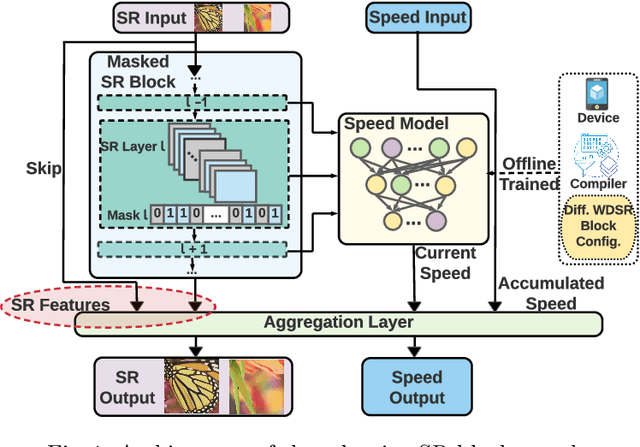
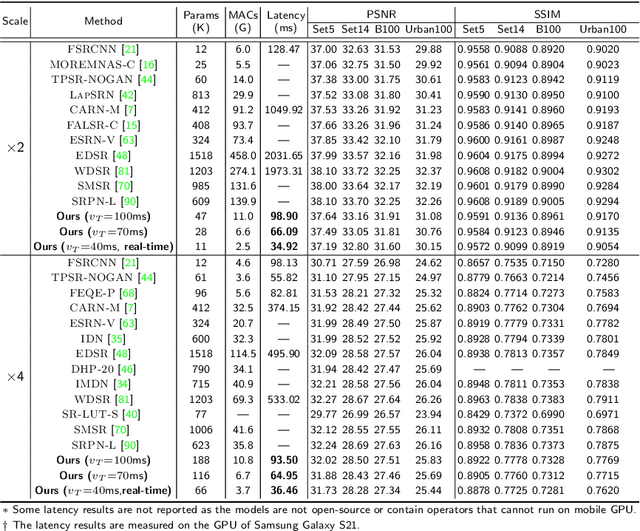
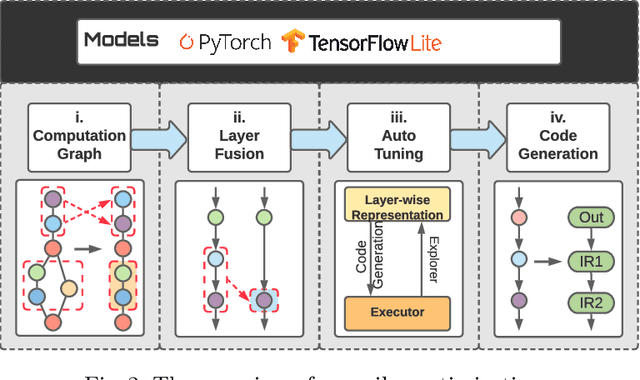
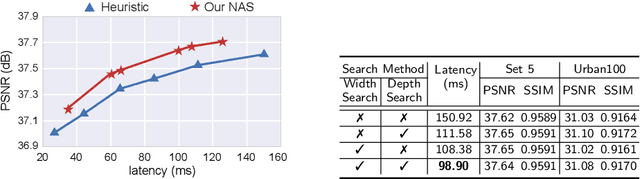
Deep learning-based super-resolution (SR) has gained tremendous popularity in recent years because of its high image quality performance and wide application scenarios. However, prior methods typically suffer from large amounts of computations and huge power consumption, causing difficulties for real-time inference, especially on resource-limited platforms such as mobile devices. To mitigate this, we propose a compiler-aware SR neural architecture search (NAS) framework that conducts depth search and per-layer width search with adaptive SR blocks. The inference speed is directly taken into the optimization along with the SR loss to derive SR models with high image quality while satisfying the real-time inference requirement. Instead of measuring the speed on mobile devices at each iteration during the search process, a speed model incorporated with compiler optimizations is leveraged to predict the inference latency of the SR block with various width configurations for faster convergence. With the proposed framework, we achieve real-time SR inference for implementing 720p resolution with competitive SR performance (in terms of PSNR and SSIM) on GPU/DSP of mobile platforms (Samsung Galaxy S21).