 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Harnessing the Conditioning Sensorium for Improved Image Translation
Oct 13, 2021
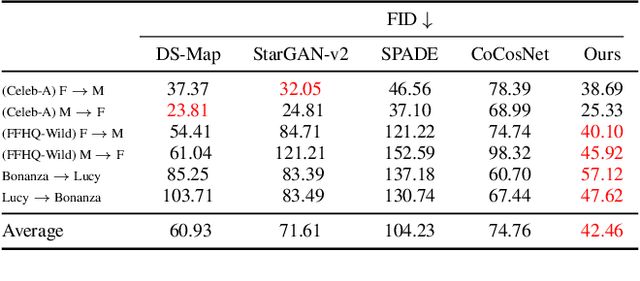
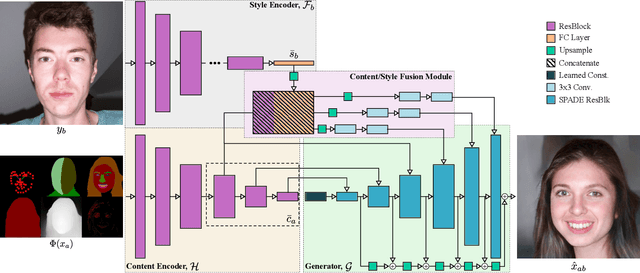


Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry), and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approach to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach straightforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.
VL-Taboo: An Analysis of Attribute-based Zero-shot Capabilities of Vision-Language Models
Sep 12, 2022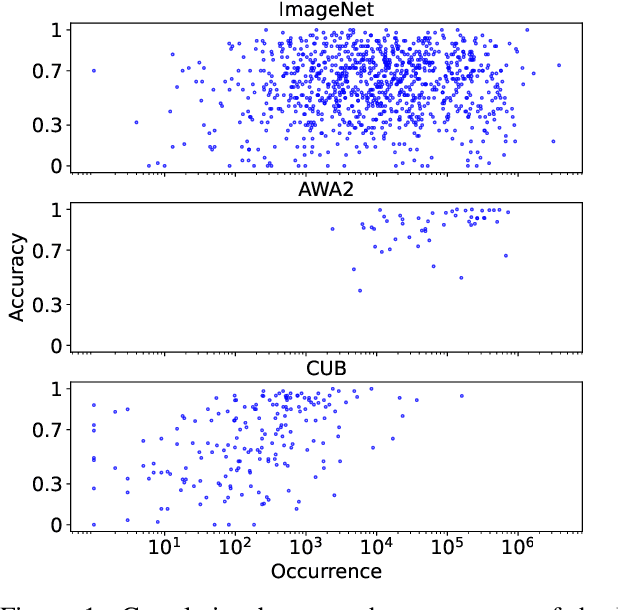
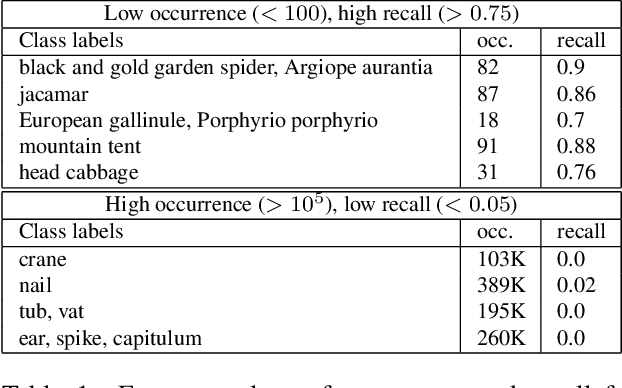
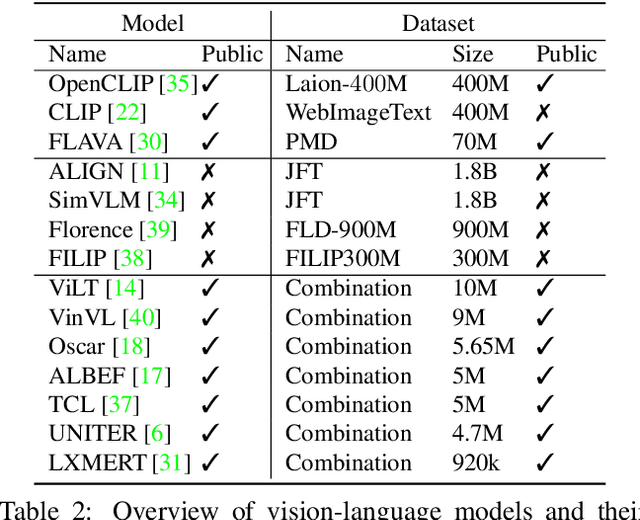
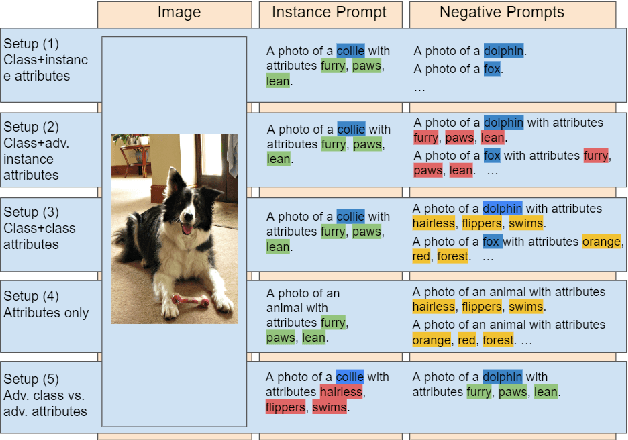
Vision-language models trained on large, randomly collected data had significant impact in many areas since they appeared. But as they show great performance in various fields, such as image-text-retrieval, their inner workings are still not fully understood. The current work analyses the true zero-shot capabilities of those models. We start from the analysis of the training corpus assessing to what extent (and which of) the test classes are really zero-shot and how this correlates with individual classes performance. We follow up with the analysis of the attribute-based zero-shot learning capabilities of these models, evaluating how well this classical zero-shot notion emerges from large-scale webly supervision. We leverage the recently released LAION400M data corpus as well as the publicly available pretrained models of CLIP, OpenCLIP, and FLAVA, evaluating the attribute-based zero-shot capabilities on CUB and AWA2 benchmarks. Our analysis shows that: (i) most of the classes in popular zero-shot benchmarks are observed (a lot) during pre-training; (ii) zero-shot performance mainly comes out of models' capability of recognizing class labels, whenever they are present in the text, and a significantly lower performing capability of attribute-based zeroshot learning is only observed when class labels are not used; (iii) the number of the attributes used can have a significant effect on performance, and can easily cause a significant performance decrease.
Deep Reinforced Attention Regression for Partial Sketch Based Image Retrieval
Nov 21, 2021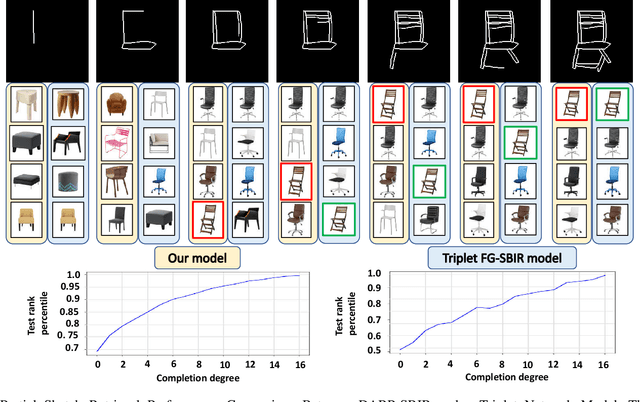
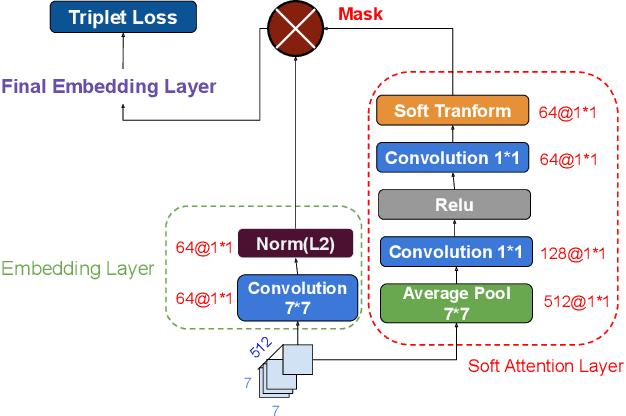
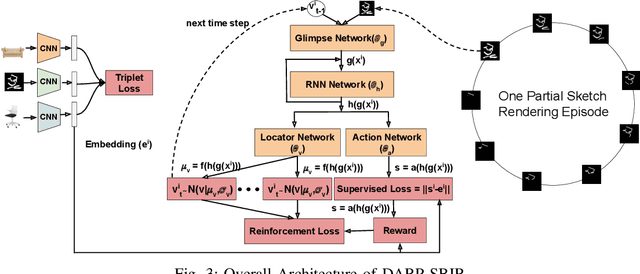
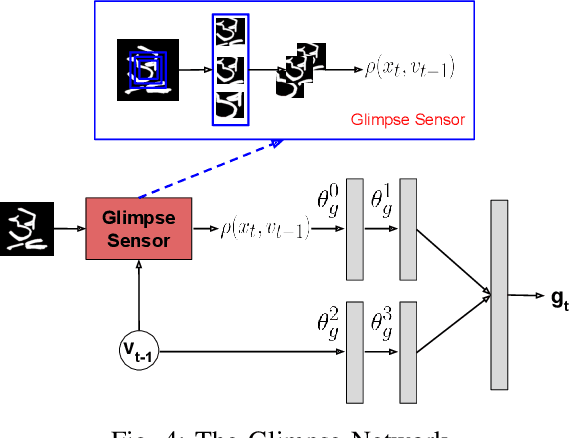
Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) aims at finding a specific image from a large gallery given a query sketch. Despite the widespread applicability of FG-SBIR in many critical domains (e.g., crime activity tracking), existing approaches still suffer from a low accuracy while being sensitive to external noises such as unnecessary strokes in the sketch. The retrieval performance will further deteriorate under a more practical on-the-fly setting, where only a partially complete sketch with only a few (noisy) strokes are available to retrieve corresponding images. We propose a novel framework that leverages a uniquely designed deep reinforcement learning model that performs a dual-level exploration to deal with partial sketch training and attention region selection. By enforcing the model's attention on the important regions of the original sketches, it remains robust to unnecessary stroke noises and improve the retrieval accuracy by a large margin. To sufficiently explore partial sketches and locate the important regions to attend, the model performs bootstrapped policy gradient for global exploration while adjusting a standard deviation term that governs a locator network for local exploration. The training process is guided by a hybrid loss that integrates a reinforcement loss and a supervised loss. A dynamic ranking reward is developed to fit the on-the-fly image retrieval process using partial sketches. The extensive experimentation performed on three public datasets shows that our proposed approach achieves the state-of-the-art performance on partial sketch based image retrieval.
Continual Learning for Steganalysis
Sep 03, 2022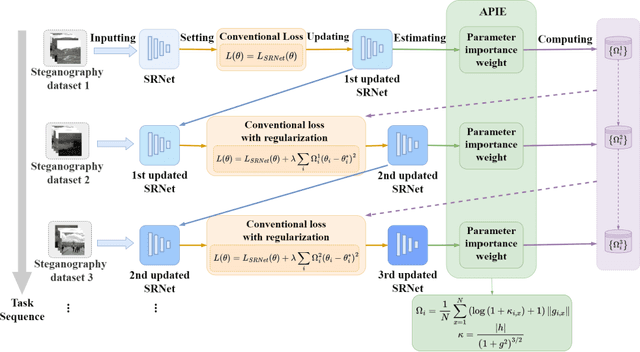
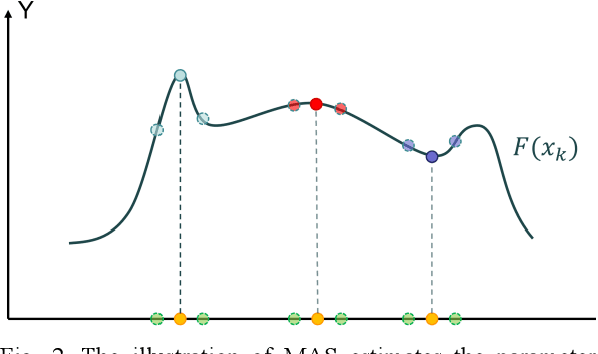
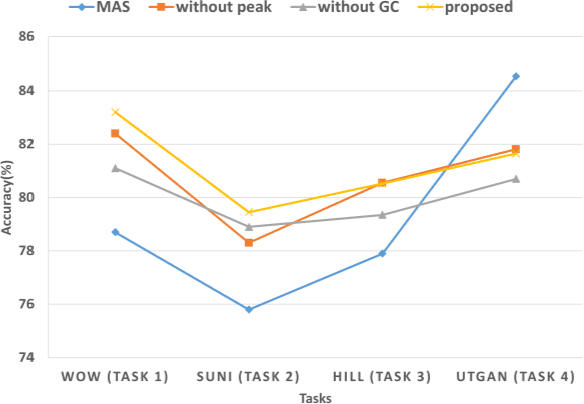
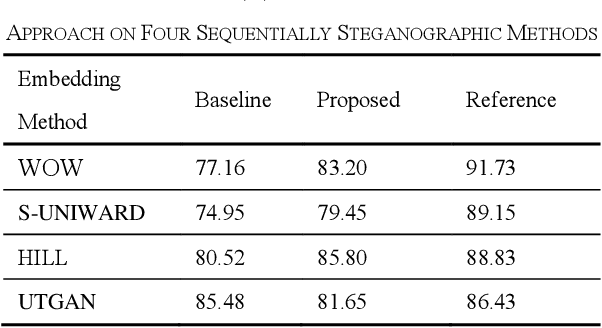
To detect the existing steganographic algorithms, recent steganalysis methods usually train a Convolutional Neural Network (CNN) model on the dataset consisting of corresponding paired cover/stego-images. However, it is inefficient and impractical for those steganalysis tools to completely retrain the CNN model to make it effective against both the existing steganographic algorithms and a new emerging steganographic algorithm. Thus, existing steganalysis models usually lack dynamic extensibility for new steganographic algorithms, which limits their application in real-world scenarios. To address this issue, we propose an accurate parameter importance estimation (APIE) based-continual learning scheme for steganalysis. In this scheme, when a steganalysis model is trained on the new image dataset generated by the new steganographic algorithm, its network parameters are effectively and efficiently updated with sufficient consideration of their importance evaluated in the previous training process. This approach can guide the steganalysis model to learn the patterns of the new steganographic algorithm without significantly degrading the detectability against the previous steganographic algorithms. Experimental results demonstrate the proposed scheme has promising extensibility for new emerging steganographic algorithms.
Moment Transform-Based Compressive Sensing in Image Processing
Nov 14, 2021
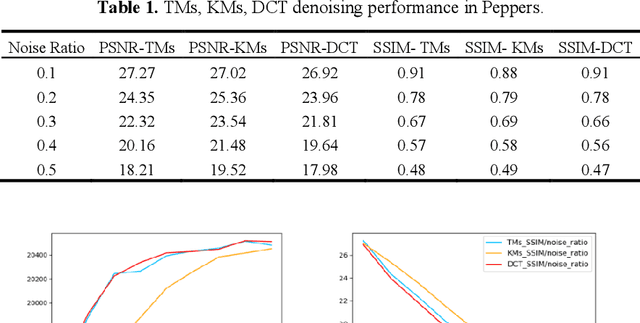
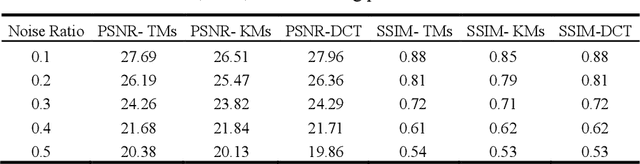
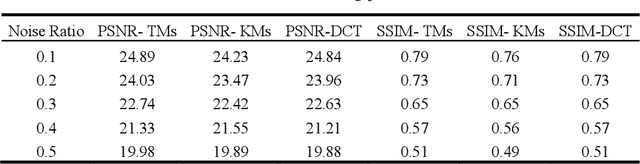
Over the last decades, images have become an important source of information in many domains, thus their high quality has become necessary to acquire better information. One of the important issues that arise is image denoising, which means recovering a signal from inaccurately and/or partially measured samples. This interpretation is highly correlated to the compressive sensing theory, which is a revolutionary technology and implies that if a signal is sparse then the original signal can be obtained from a few measured values, which are much less, than the ones suggested by other used theories like Shannon's sampling theories. A strong factor in Compressive Sensing (CS) theory to achieve the sparsest solution and the noise removal from the corrupted image is the selection of the basis dictionary. In this paper, Discrete Cosine Transform (DCT) and moment transform (Tchebichef, Krawtchouk) are compared in order to achieve image denoising of Gaussian additive white noise based on compressive sensing and sparse approximation theory. The experimental results revealed that the basis dictionaries constructed by the moment transform perform competitively to the traditional DCT. The latter transform shows a higher PSNR of 30.82 dB and the same 0.91 SSIM value as the Tchebichef transform. Moreover, from the sparsity point of view, Krawtchouk moments provide approximately 20-30% more sparse results than DCT.
Multi-Modal Masked Autoencoders for Medical Vision-and-Language Pre-Training
Sep 15, 2022Medical vision-and-language pre-training provides a feasible solution to extract effective vision-and-language representations from medical images and texts. However, few studies have been dedicated to this field to facilitate medical vision-and-language understanding. In this paper, we propose a self-supervised learning paradigm with multi-modal masked autoencoders (M$^3$AE), which learn cross-modal domain knowledge by reconstructing missing pixels and tokens from randomly masked images and texts. There are three key designs to make this simple approach work. First, considering the different information densities of vision and language, we adopt different masking ratios for the input image and text, where a considerably larger masking ratio is used for images. Second, we use visual and textual features from different layers to perform the reconstruction to deal with different levels of abstraction in visual and language. Third, we develop different designs for vision and language decoders (i.e., a Transformer for vision and a multi-layer perceptron for language). To perform a comprehensive evaluation and facilitate further research, we construct a medical vision-and-language benchmark including three tasks. Experimental results demonstrate the effectiveness of our approach, where state-of-the-art results are achieved on all downstream tasks. Besides, we conduct further analysis to better verify the effectiveness of different components of our approach and various settings of pre-training. The source code is available at~\url{https://github.com/zhjohnchan/M3AE}.
A Study on Self-Supervised Object Detection Pretraining
Jul 09, 2022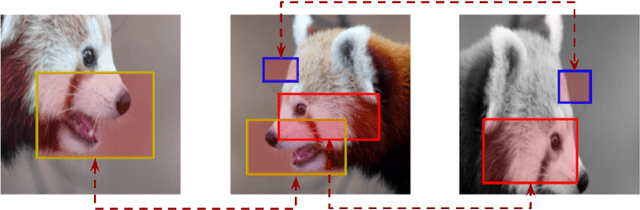
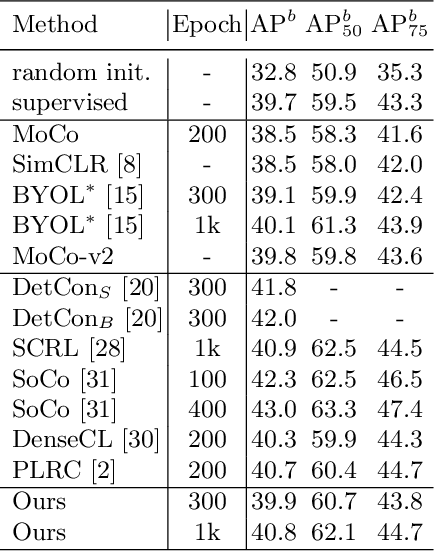
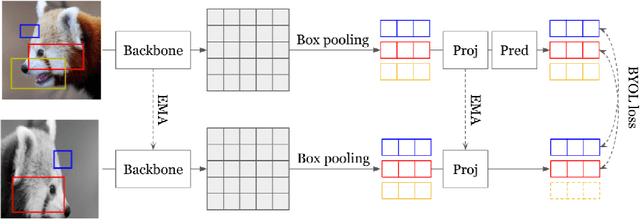
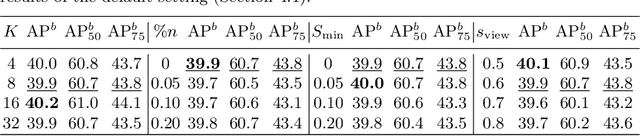
In this work, we study different approaches to self-supervised pretraining of object detection models. We first design a general framework to learn a spatially consistent dense representation from an image, by randomly sampling and projecting boxes to each augmented view and maximizing the similarity between corresponding box features. We study existing design choices in the literature, such as box generation, feature extraction strategies, and using multiple views inspired by its success on instance-level image representation learning techniques. Our results suggest that the method is robust to different choices of hyperparameters, and using multiple views is not as effective as shown for instance-level image representation learning. We also design two auxiliary tasks to predict boxes in one view from their features in the other view, by (1) predicting boxes from the sampled set by using a contrastive loss, and (2) predicting box coordinates using a transformer, which potentially benefits downstream object detection tasks. We found that these tasks do not lead to better object detection performance when finetuning the pretrained model on labeled data.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
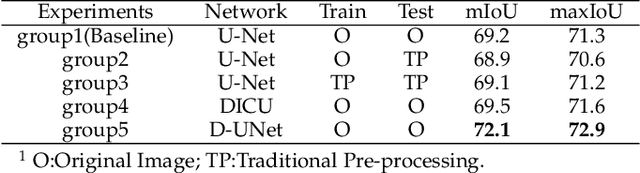
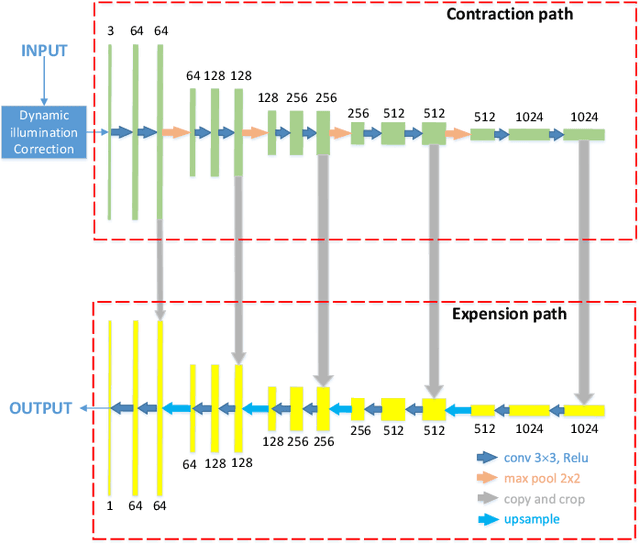

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
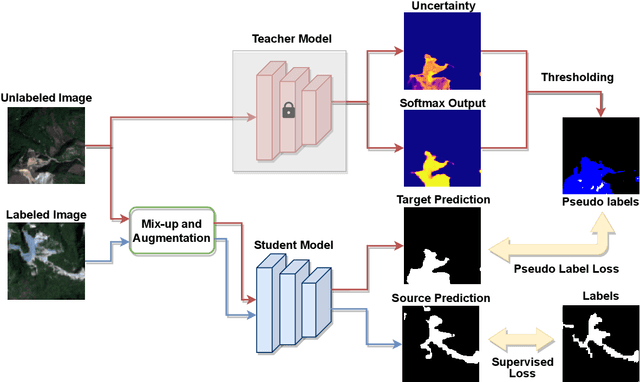
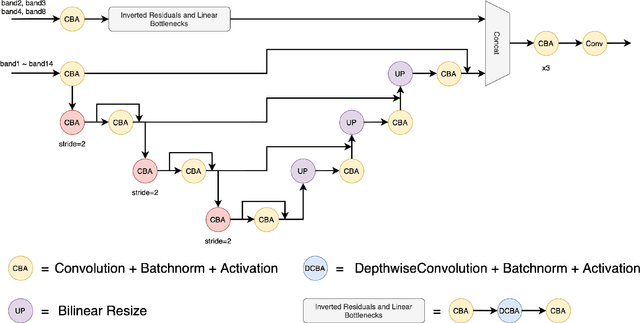
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
SimMIM: A Simple Framework for Masked Image Modeling
Nov 18, 2021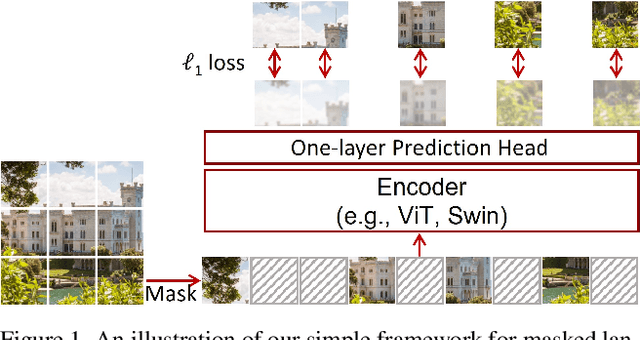
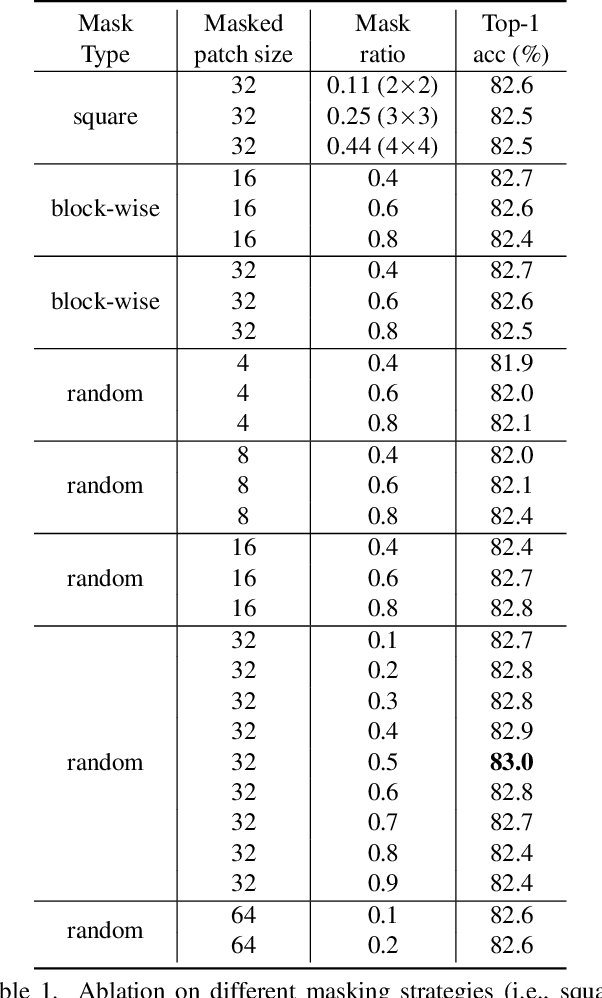

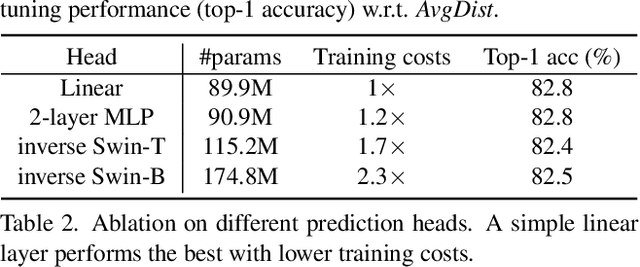
This paper presents SimMIM, a simple framework for masked image modeling. We simplify recently proposed related approaches without special designs such as block-wise masking and tokenization via discrete VAE or clustering. To study what let the masked image modeling task learn good representations, we systematically study the major components in our framework, and find that simple designs of each component have revealed very strong representation learning performance: 1) random masking of the input image with a moderately large masked patch size (e.g., 32) makes a strong pre-text task; 2) predicting raw pixels of RGB values by direct regression performs no worse than the patch classification approaches with complex designs; 3) the prediction head can be as light as a linear layer, with no worse performance than heavier ones. Using ViT-B, our approach achieves 83.8% top-1 fine-tuning accuracy on ImageNet-1K by pre-training also on this dataset, surpassing previous best approach by +0.6%. When applied on a larger model of about 650 million parameters, SwinV2-H, it achieves 87.1% top-1 accuracy on ImageNet-1K using only ImageNet-1K data. We also leverage this approach to facilitate the training of a 3B model (SwinV2-G), that by $40\times$ less data than that in previous practice, we achieve the state-of-the-art on four representative vision benchmarks. The code and models will be publicly available at https://github.com/microsoft/SimMIM.