 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVTG: A Large-Scale Dataset and Training Paradigm for Open-World Video Temporal Grounding
Apr 28, 2026Video Temporal Grounding (VTG), the task of localizing video segments from text queries, struggles in open-world settings due to limited dataset scale and semantic diversity, causing performance gaps between common and rare concepts. To overcome these limitations, we introduce OmniVTG, a new large-scale dataset for open-world VTG, coupled with a Self-Correction Chain-of-Thought (CoT) training paradigm designed to enhance the grounding capabilities of Multimodal Large Language Models (MLLMs). Our OmniVTG is constructed via a novel Semantic Coverage Iterative Expansion pipeline, which first identifies gaps in the vocabulary of existing datasets and collects videos that are highly likely to contain these target concepts. For high-quality annotation, we leverage the insight that modern MLLMs excel at dense captioning more than direct grounding and design a caption-centric data engine to prompt MLLMs to generate dense, timestamped descriptions. Beyond the dataset, we observe that simple supervised finetuning (SFT) is insufficient, as a performance gap between rare and common concepts still persists. We find that MLLMs' video understanding ability significantly surpasses their direct grounding ability. Based on this, we propose a Self-Correction Chain-of-Thought (CoT) training paradigm. We train the MLLM to first predict, then use its understanding capabilities to reflect on and refine its own predictions. This capability is instilled via a three-stage pipeline of SFT, CoT finetuning, and reinforcement learning. Extensive experiments show our approach not only excels at open-world grounding in our OmniVTG dataset but also achieves state-of-the-art zero-shot performance on four existing VTG benchmarks. Code is available at https://github.com/oceanflowlab/OmniVTG.
UniTalking: A Unified Audio-Video Framework for Talking Portrait Generation
Mar 02, 2026While state-of-the-art audio-video generation models like Veo3 and Sora2 demonstrate remarkable capabilities, their closed-source nature makes their architectures and training paradigms inaccessible. To bridge this gap in accessibility and performance, we introduce UniTalking, a unified, end-to-end diffusion framework for generating high-fidelity speech and lip-synchronized video. At its core, our framework employs Multi-Modal Transformer Blocks to explicitly model the fine-grained temporal correspondence between audio and video latent tokens via a shared self-attention mechanism. By leveraging powerful priors from a pre-trained video generation model, our framework ensures state-of-the-art visual fidelity while enabling efficient training. Furthermore, UniTalking incorporates a personalized voice cloning capability, allowing the generation of speech in a target style from a brief audio reference. Qualitative and quantitative results demonstrate that our method produces highly realistic talking portraits, achieving superior performance over existing open-source approaches in lip-sync accuracy, audio naturalness, and overall perceptual quality.
Continual Learning for Steganalysis
Sep 03, 2022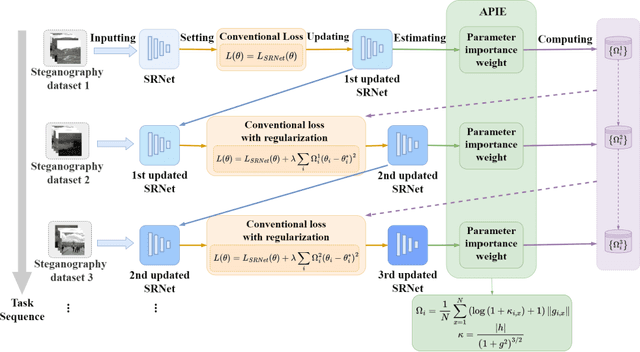
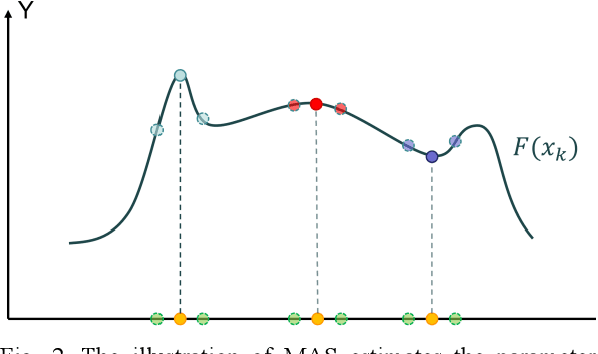
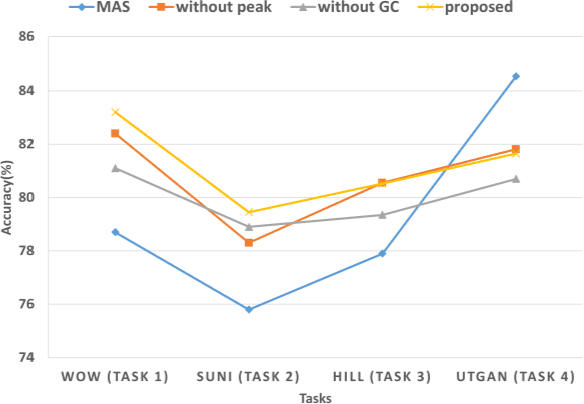
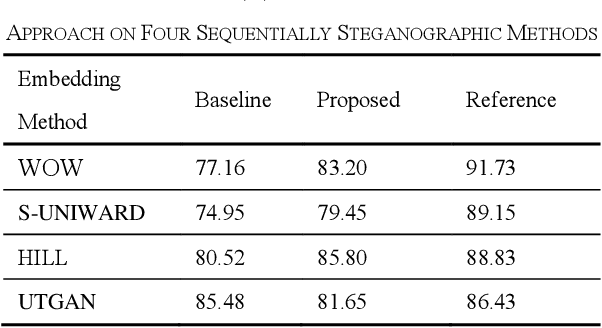
To detect the existing steganographic algorithms, recent steganalysis methods usually train a Convolutional Neural Network (CNN) model on the dataset consisting of corresponding paired cover/stego-images. However, it is inefficient and impractical for those steganalysis tools to completely retrain the CNN model to make it effective against both the existing steganographic algorithms and a new emerging steganographic algorithm. Thus, existing steganalysis models usually lack dynamic extensibility for new steganographic algorithms, which limits their application in real-world scenarios. To address this issue, we propose an accurate parameter importance estimation (APIE) based-continual learning scheme for steganalysis. In this scheme, when a steganalysis model is trained on the new image dataset generated by the new steganographic algorithm, its network parameters are effectively and efficiently updated with sufficient consideration of their importance evaluated in the previous training process. This approach can guide the steganalysis model to learn the patterns of the new steganographic algorithm without significantly degrading the detectability against the previous steganographic algorithms. Experimental results demonstrate the proposed scheme has promising extensibility for new emerging steganographic algorithms.
One-Shot Medical Landmark Localization by Edge-Guided Transform and Noisy Landmark Refinement
Jul 31, 2022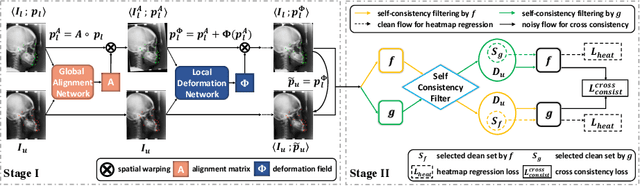
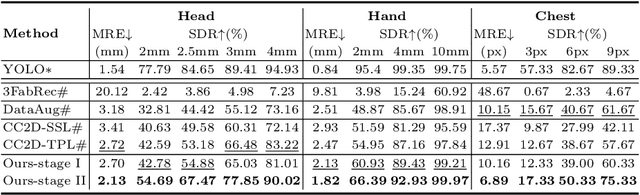
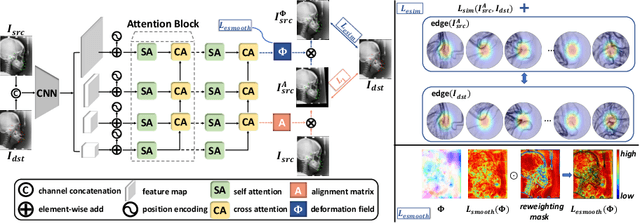
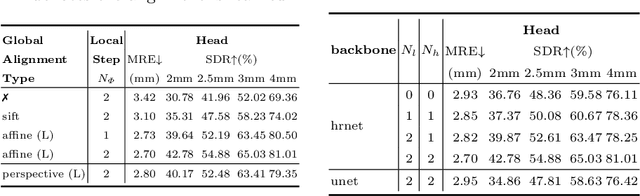
As an important upstream task for many medical applications, supervised landmark localization still requires non-negligible annotation costs to achieve desirable performance. Besides, due to cumbersome collection procedures, the limited size of medical landmark datasets impacts the effectiveness of large-scale self-supervised pre-training methods. To address these challenges, we propose a two-stage framework for one-shot medical landmark localization, which first infers landmarks by unsupervised registration from the labeled exemplar to unlabeled targets, and then utilizes these noisy pseudo labels to train robust detectors. To handle the significant structure variations, we learn an end-to-end cascade of global alignment and local deformations, under the guidance of novel loss functions which incorporate edge information. In stage II, we explore self-consistency for selecting reliable pseudo labels and cross-consistency for semi-supervised learning. Our method achieves state-of-the-art performances on public datasets of different body parts, which demonstrates its general applicability.
Transformers in Medical Image Analysis: A Review
Feb 24, 2022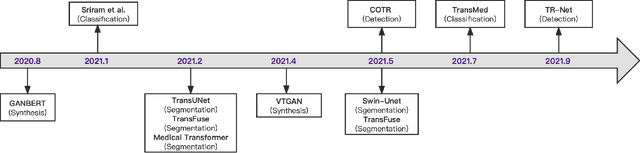
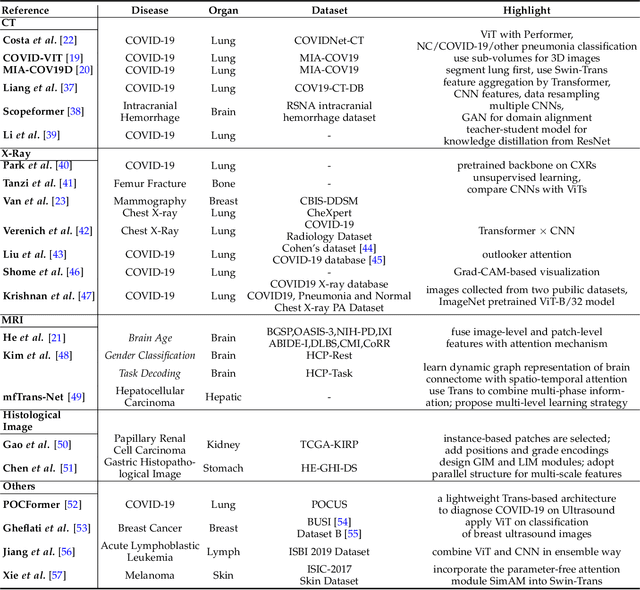
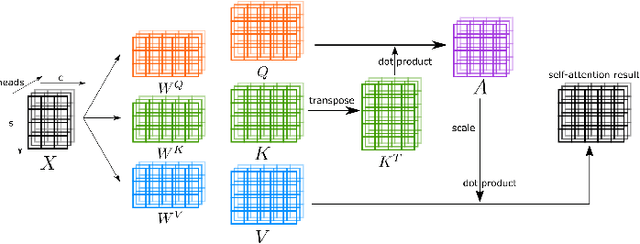
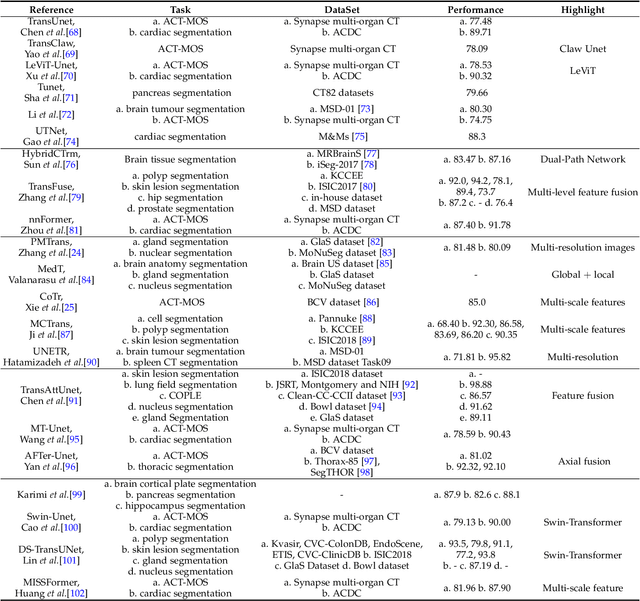
Transformers have dominated the field of natural language processing, and recently impacted the computer vision area. In the field of medical image analysis, Transformers have also been successfully applied to full-stack clinical applications, including image synthesis/reconstruction, registration, segmentation, detection, and diagnosis. Our paper presents both a position paper and a primer, promoting awareness and application of Transformers in the field of medical image analysis. Specifically, we first overview the core concepts of the attention mechanism built into Transformers and other basic components. Second, we give a new taxonomy of various Transformer architectures tailored for medical image applications and discuss their limitations. Within this review, we investigate key challenges revolving around the use of Transformers in different learning paradigms, improving the model efficiency, and their coupling with other techniques. We hope this review can give a comprehensive picture of Transformers to the readers in the field of medical image analysis.