 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORGI: Consistency-Aware 3D Dog Reconstruction from a Single Image in the Wild
Jul 01, 2026Reconstructing high-fidelity 3D models of highly articulated animals, such as dogs, from a single in-the-wild image remains a formidable challenge. In this paper, we introduce CORGI, a novel framework for consistency-aware 3D dog reconstruction from a single unconstrained image that completely eliminates the need for 3D supervision. To overcome generative inconsistencies and the lack of multi-view capture, our pipeline introduces three core components. First, we propose a Canonical-Driven Orbital Generation (CDOG) strategy, utilizing specialized Canonical and Orbit LoRAs to normalize arbitrary input poses and synthesize reliable 360-degree video observations. Second, we design a Consistency-aware Deformable 3DGS (CA-3DGS) module that anchors on a D-SMAL prior, explicitly modeling per-view generative errors through dedicated neural deformation fields to learn accurate vertex-level displacements. Finally, to eliminate structural distortions and recover high-frequency details, we introduce a self-supervised Deformation-Conditioned Generative Repair (DCGR) module. Extensive experiments demonstrate that CORGI achieves state-of-the-art performance, generalizing seamlessly across diverse dog breeds to produce geometrically accurate, visually coherent, and fully animatable 3D assets ready for downstream applications.
ModRWKV: Transformer Multimodality in Linear Time
May 20, 2025



Currently, most multimodal studies are based on large language models (LLMs) with quadratic-complexity Transformer architectures. While linear models like RNNs enjoy low inference costs, their application has been largely limited to the text-only modality. This work explores the capabilities of modern RNN architectures in multimodal contexts. We propose ModRWKV-a decoupled multimodal framework built upon the RWKV7 architecture as its LLM backbone-which achieves multi-source information fusion through dynamically adaptable heterogeneous modality encoders. We designed the multimodal modules in ModRWKV with an extremely lightweight architecture and, through extensive experiments, identified a configuration that achieves an optimal balance between performance and computational efficiency. ModRWKV leverages the pretrained weights of the RWKV7 LLM for initialization, which significantly accelerates multimodal training. Comparative experiments with different pretrained checkpoints further demonstrate that such initialization plays a crucial role in enhancing the model's ability to understand multimodal signals. Supported by extensive experiments, we conclude that modern RNN architectures present a viable alternative to Transformers in the domain of multimodal large language models (MLLMs). Furthermore, we identify the optimal configuration of the ModRWKV architecture through systematic exploration.
SCAResNet: A ResNet Variant Optimized for Tiny Object Detection in Transmission and Distribution Towers
Apr 05, 2024



Traditional deep learning-based object detection networks often resize images during the data preprocessing stage to achieve a uniform size and scale in the feature map. Resizing is done to facilitate model propagation and fully connected classification. However, resizing inevitably leads to object deformation and loss of valuable information in the images. This drawback becomes particularly pronounced for tiny objects like distribution towers with linear shapes and few pixels. To address this issue, we propose abandoning the resizing operation. Instead, we introduce Positional-Encoding Multi-head Criss-Cross Attention. This allows the model to capture contextual information and learn from multiple representation subspaces, effectively enriching the semantics of distribution towers. Additionally, we enhance Spatial Pyramid Pooling by reshaping three pooled feature maps into a new unified one while also reducing the computational burden. This approach allows images of different sizes and scales to generate feature maps with uniform dimensions and can be employed in feature map propagation. Our SCAResNet incorporates these aforementioned improvements into the backbone network ResNet. We evaluated our SCAResNet using the Electric Transmission and Distribution Infrastructure Imagery dataset from Duke University. Without any additional tricks, we employed various object detection models with Gaussian Receptive Field based Label Assignment as the baseline. When incorporating the SCAResNet into the baseline model, we achieved a 2.1% improvement in mAPs. This demonstrates the advantages of our SCAResNet in detecting transmission and distribution towers and its value in tiny object detection. The source code is available at https://github.com/LisavilaLee/SCAResNet_mmdet.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
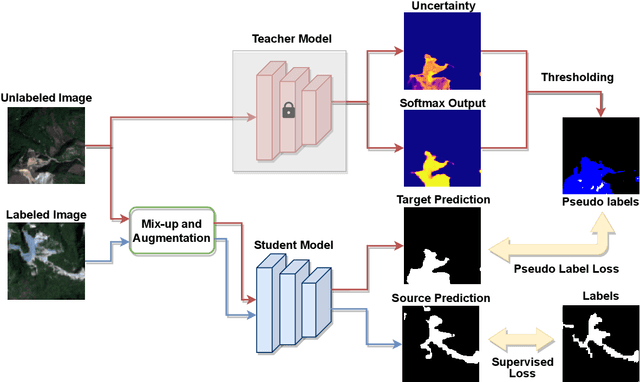
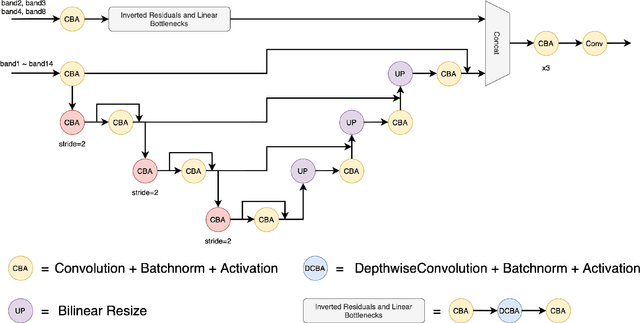
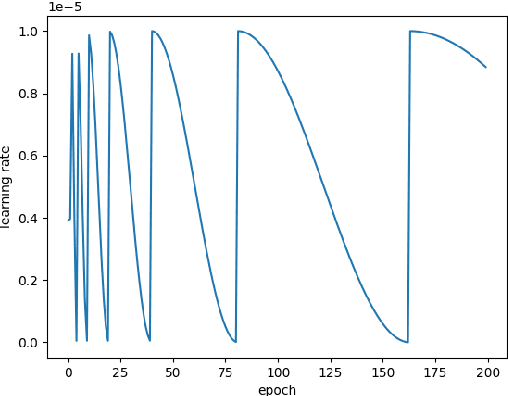
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.