 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Low-Light Image Enhancement via Histogram Equalization Prior
Dec 03, 2021


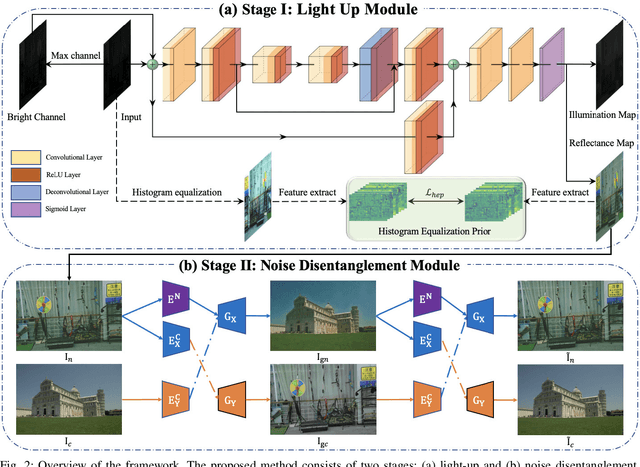

Deep learning-based methods for low-light image enhancement typically require enormous paired training data, which are impractical to capture in real-world scenarios. Recently, unsupervised approaches have been explored to eliminate the reliance on paired training data. However, they perform erratically in diverse real-world scenarios due to the absence of priors. To address this issue, we propose an unsupervised low-light image enhancement method based on an effective prior termed histogram equalization prior (HEP). Our work is inspired by the interesting observation that the feature maps of histogram equalization enhanced image and the ground truth are similar. Specifically, we formulate the HEP to provide abundant texture and luminance information. Embedded into a Light Up Module (LUM), it helps to decompose the low-light images into illumination and reflectance maps, and the reflectance maps can be regarded as restored images. However, the derivation based on Retinex theory reveals that the reflectance maps are contaminated by noise. We introduce a Noise Disentanglement Module (NDM) to disentangle the noise and content in the reflectance maps with the reliable aid of unpaired clean images. Guided by the histogram equalization prior and noise disentanglement, our method can recover finer details and is more capable to suppress noise in real-world low-light scenarios. Extensive experiments demonstrate that our method performs favorably against the state-of-the-art unsupervised low-light enhancement algorithms and even matches the state-of-the-art supervised algorithms.
Transformer based Models for Unsupervised Anomaly Segmentation in Brain MR Images
Jul 05, 2022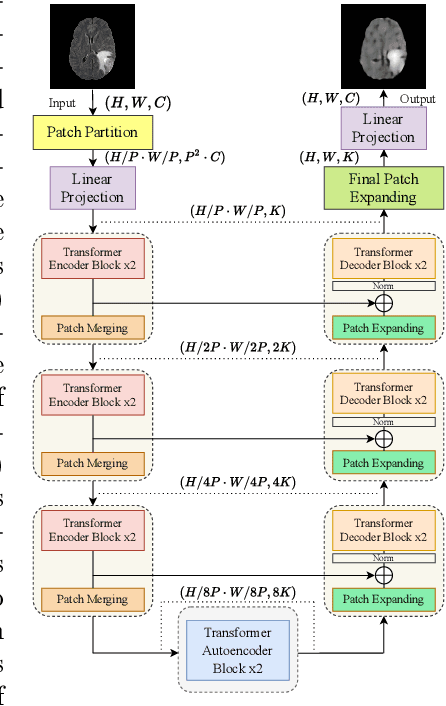
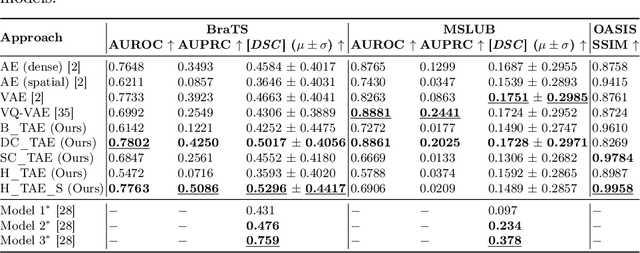
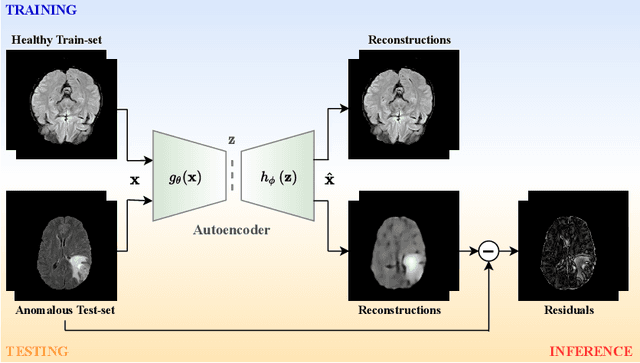
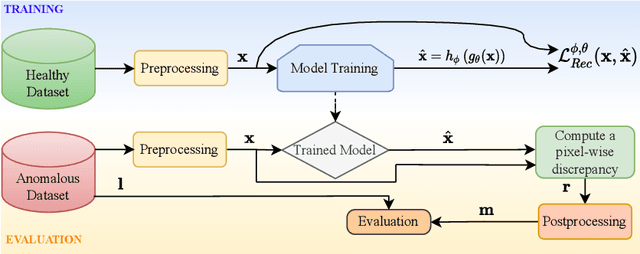
The quality of patient care associated with diagnostic radiology is proportionate to a physician workload. Segmentation is a fundamental limiting precursor to diagnostic and therapeutic procedures. Advances in Machine Learning (ML) aim to increase diagnostic efficiency to replace single application with generalized algorithms. In Unsupervised Anomaly Detection (UAD), Convolutional Neural Network (CNN) based Autoencoders (AEs) and Variational Autoencoders (VAEs) are considered as a de facto approach for reconstruction based anomaly segmentation. Looking for anomalous regions in medical images is one of the main applications that use anomaly segmentation. The restricted receptive field in CNNs limit the CNN to model the global context and hence if the anomalous regions cover parts of the image, the CNN-based AEs are not capable to bring semantic understanding of the image. On the other hand, Vision Transformers (ViTs) have emerged as a competitive alternative to CNNs. It relies on the self-attention mechanism that is capable to relate image patches to each other. To reconstruct a coherent and more realistic image, in this work, we investigate Transformer capabilities in building AEs for reconstruction based UAD task. We focus on anomaly segmentation for Brain Magnetic Resonance Imaging (MRI) and present five Transformer-based models while enabling segmentation performance comparable or superior to State-of-The-Art (SOTA) models. The source code is available on Github https://github.com/ahmedgh970/Transformers_Unsupervised_Anomaly_Segmentation.git
Temporal Flow Mask Attention for Open-Set Long-Tailed Recognition of Wild Animals in Camera-Trap Images
Aug 31, 2022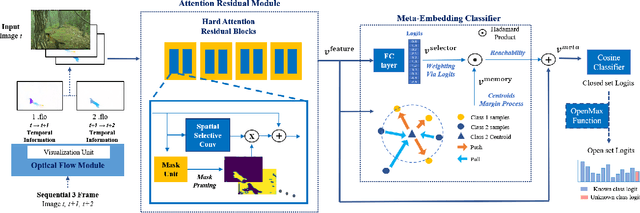
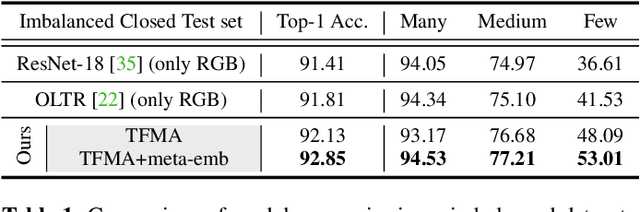
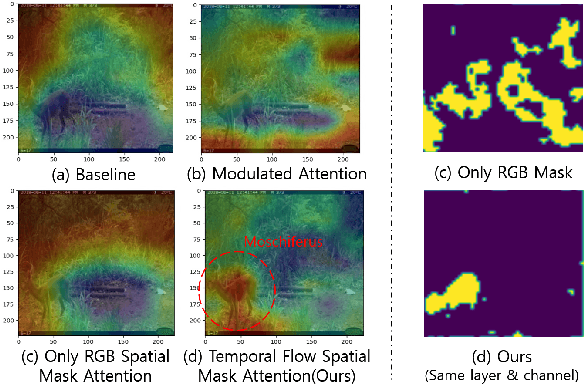
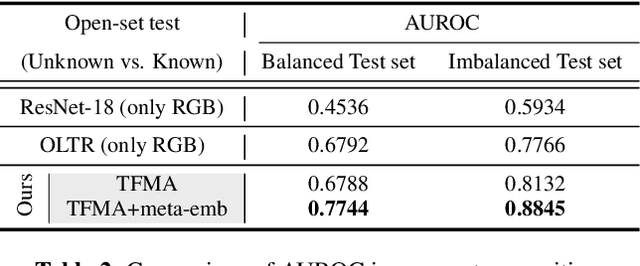
Camera traps, unmanned observation devices, and deep learning-based image recognition systems have greatly reduced human effort in collecting and analyzing wildlife images. However, data collected via above apparatus exhibits 1) long-tailed and 2) open-ended distribution problems. To tackle the open-set long-tailed recognition problem, we propose the Temporal Flow Mask Attention Network that comprises three key building blocks: 1) an optical flow module, 2) an attention residual module, and 3) a meta-embedding classifier. We extract temporal features of sequential frames using the optical flow module and learn informative representation using attention residual blocks. Moreover, we show that applying the meta-embedding technique boosts the performance of the method in open-set long-tailed recognition. We apply this method on a Korean Demilitarized Zone (DMZ) dataset. We conduct extensive experiments, and quantitative and qualitative analyses to prove that our method effectively tackles the open-set long-tailed recognition problem while being robust to unknown classes.
Memory-guided Image De-raining Using Time-Lapse Data
Jan 06, 2022


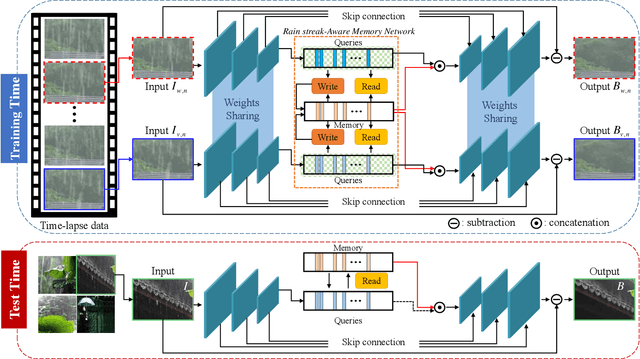
This paper addresses the problem of single image de-raining, that is, the task of recovering clean and rain-free background scenes from a single image obscured by a rainy artifact. Although recent advances adopt real-world time-lapse data to overcome the need for paired rain-clean images, they are limited to fully exploit the time-lapse data. The main cause is that, in terms of network architectures, they could not capture long-term rain streak information in the time-lapse data during training owing to the lack of memory components. To address this problem, we propose a novel network architecture based on a memory network that explicitly helps to capture long-term rain streak information in the time-lapse data. Our network comprises the encoder-decoder networks and a memory network. The features extracted from the encoder are read and updated in the memory network that contains several memory items to store rain streak-aware feature representations. With the read/update operation, the memory network retrieves relevant memory items in terms of the queries, enabling the memory items to represent the various rain streaks included in the time-lapse data. To boost the discriminative power of memory features, we also present a novel background selective whitening (BSW) loss for capturing only rain streak information in the memory network by erasing the background information. Experimental results on standard benchmarks demonstrate the effectiveness and superiority of our approach.
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Nov 26, 2021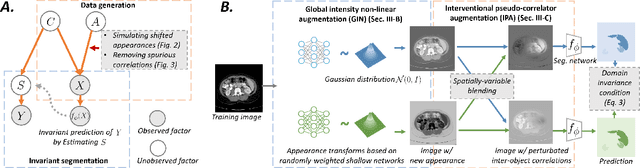
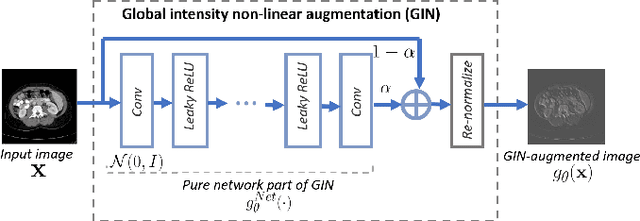
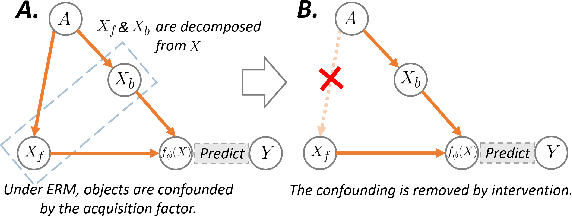
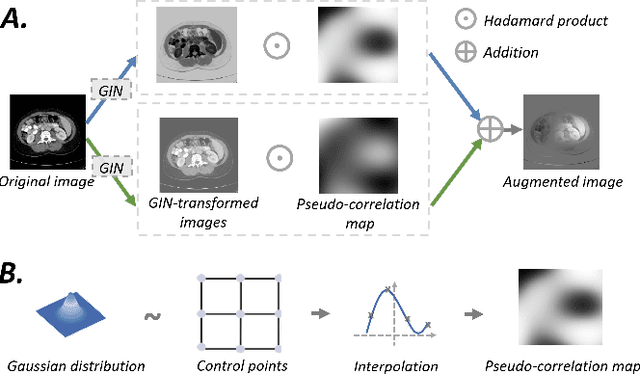
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
Seamless Iterative Semi-Supervised Correction of Imperfect Labels in Microscopy Images
Aug 05, 2022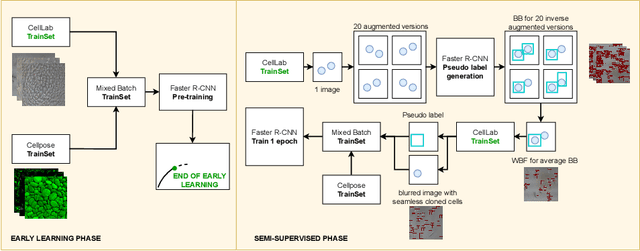
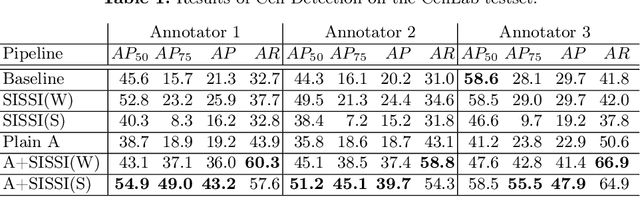
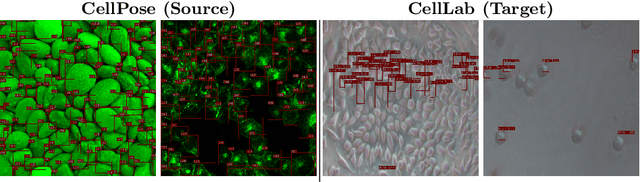

In-vitro tests are an alternative to animal testing for the toxicity of medical devices. Detecting cells as a first step, a cell expert evaluates the growth of cells according to cytotoxicity grade under the microscope. Thus, human fatigue plays a role in error making, making the use of deep learning appealing. Due to the high cost of training data annotation, an approach without manual annotation is needed. We propose Seamless Iterative Semi-Supervised correction of Imperfect labels (SISSI), a new method for training object detection models with noisy and missing annotations in a semi-supervised fashion. Our network learns from noisy labels generated with simple image processing algorithms, which are iteratively corrected during self-training. Due to the nature of missing bounding boxes in the pseudo labels, which would negatively affect the training, we propose to train on dynamically generated synthetic-like images using seamless cloning. Our method successfully provides an adaptive early learning correction technique for object detection. The combination of early learning correction that has been applied in classification and semantic segmentation before and synthetic-like image generation proves to be more effective than the usual semi-supervised approach by > 15% AP and > 20% AR across three different readers. Our code is available at https://github.com/marwankefah/SISSI.
Spectral image clustering on dual-energy CT scans using functional regression mixtures
Jan 31, 2022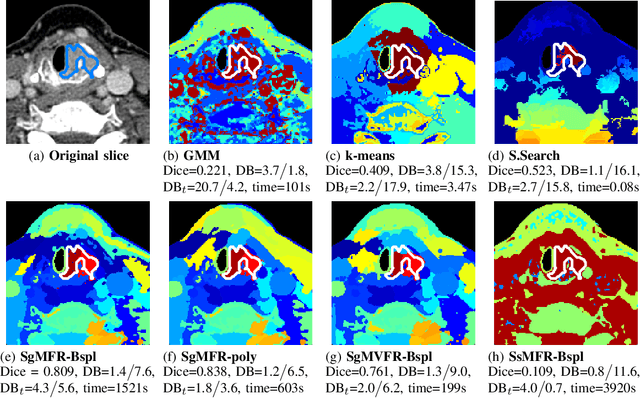
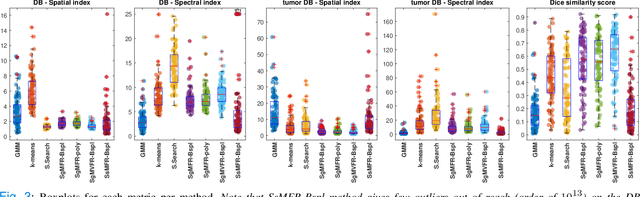
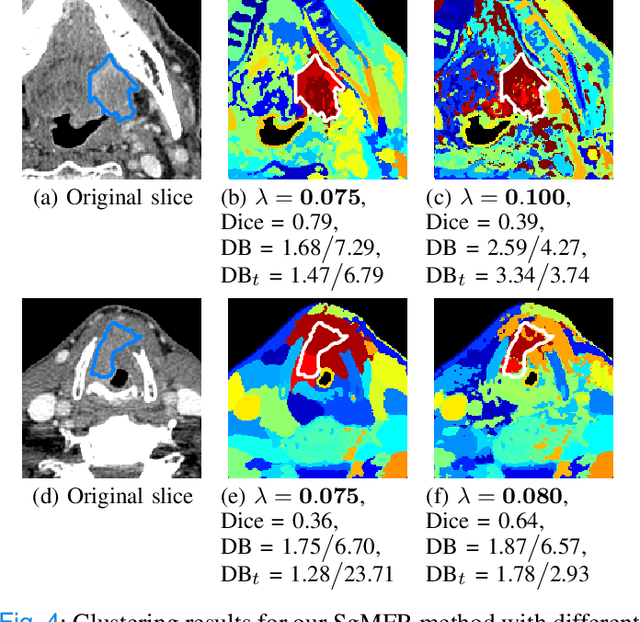
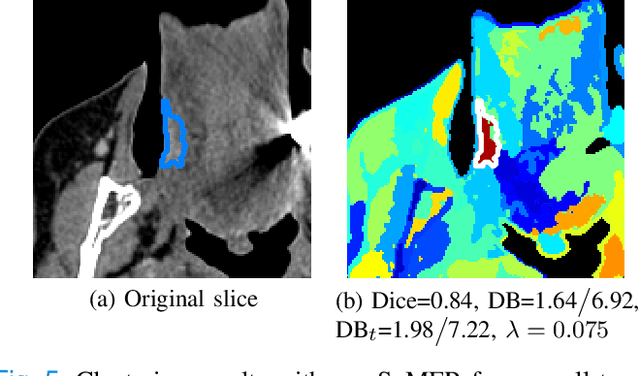
Dual-energy computed tomography (DECT) is an advanced CT scanning technique enabling material characterization not possible with conventional CT scans. It allows the reconstruction of energy decay curves at each 3D image voxel, representing varying image attenuation at different effective scanning energy levels. In this paper, we develop novel functional data analysis (FDA) techniques and adapt them to the analysis of DECT decay curves. More specifically, we construct functional mixture models that integrate spatial context in mixture weights, with mixture component densities being constructed upon the energy decay curves as functional observations. We design unsupervised clustering algorithms by developing dedicated expectation maximization (EM) algorithms for the maximum likelihood estimation of the model parameters. To our knowledge, this is the first article to adapt statistical FDA tools and model-based clustering to take advantage of the full spectral information provided by DECT. We evaluate our methods on 91 head and neck cancer DECT scans. We compare our unsupervised clustering results to tumor contours traced manually by radiologists, as well as to several baseline algorithms. Given the inter-rater variability even among experts at delineating head and neck tumors, and given the potential importance of tissue reactions surrounding the tumor itself, our proposed methodology has the potential to add value in downstream machine learning applications for clinical outcome prediction based on DECT data in head and neck cancer.
Learning Incrementally to Segment Multiple Organs in a CT Image
Mar 04, 2022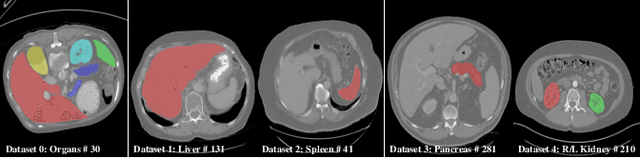
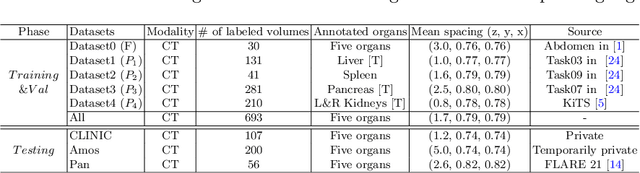
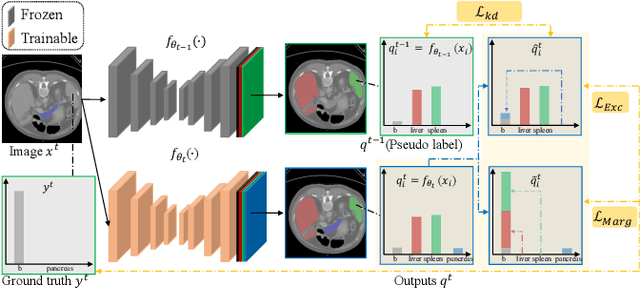
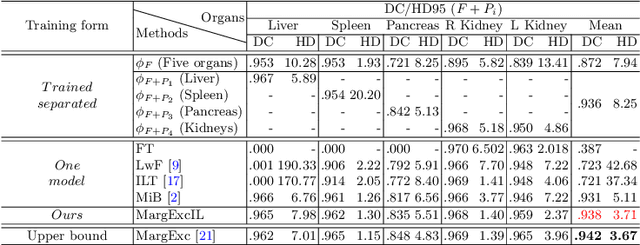
There exists a large number of datasets for organ segmentation, which are partially annotated and sequentially constructed. A typical dataset is constructed at a certain time by curating medical images and annotating the organs of interest. In other words, new datasets with annotations of new organ categories are built over time. To unleash the potential behind these partially labeled, sequentially-constructed datasets, we propose to incrementally learn a multi-organ segmentation model. In each incremental learning (IL) stage, we lose the access to previous data and annotations, whose knowledge is assumingly captured by the current model, and gain the access to a new dataset with annotations of new organ categories, from which we learn to update the organ segmentation model to include the new organs. While IL is notorious for its `catastrophic forgetting' weakness in the context of natural image analysis, we experimentally discover that such a weakness mostly disappears for CT multi-organ segmentation. To further stabilize the model performance across the IL stages, we introduce a light memory module and some loss functions to restrain the representation of different categories in feature space, aggregating feature representation of the same class and separating feature representation of different classes. Extensive experiments on five open-sourced datasets are conducted to illustrate the effectiveness of our method.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
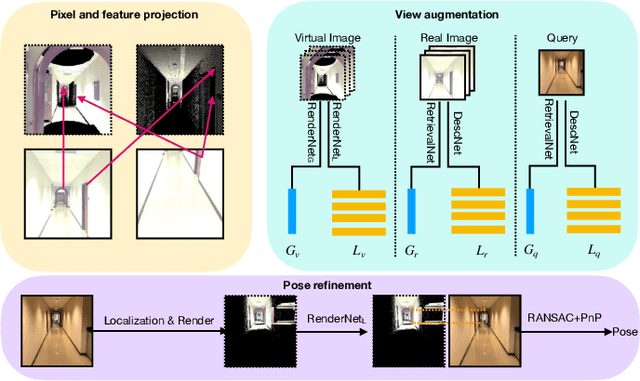
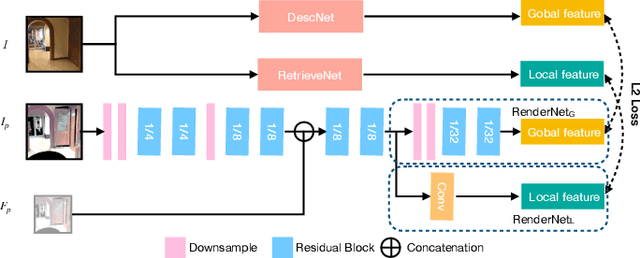

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
GAF-NAU: Gramian Angular Field encoded Neighborhood Attention U-Net for Pixel-Wise Hyperspectral Image Classification
Apr 21, 2022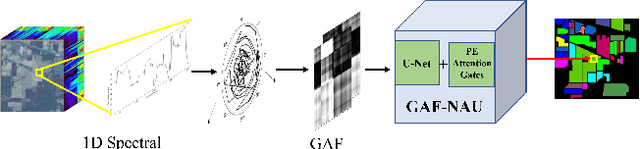

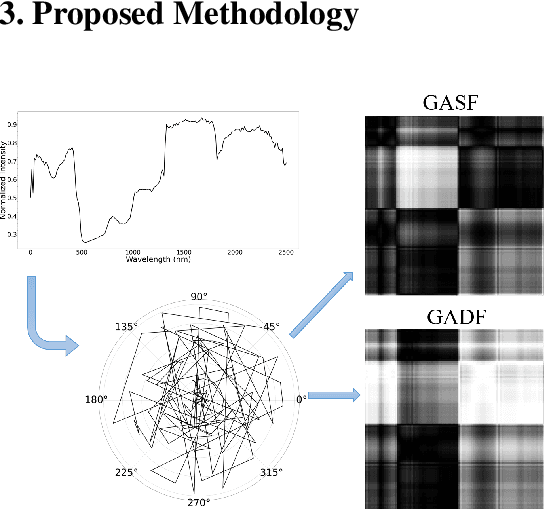

Hyperspectral image (HSI) classification is the most vibrant area of research in the hyperspectral community due to the rich spectral information contained in HSI can greatly aid in identifying objects of interest. However, inherent non-linearity between materials and the corresponding spectral profiles brings two major challenges in HSI classification: interclass similarity and intraclass variability. Many advanced deep learning methods have attempted to address these issues from the perspective of a region/patch-based approach, instead of a pixel-based alternate. However, the patch-based approaches hypothesize that neighborhood pixels of a target pixel in a fixed spatial window belong to the same class. And this assumption is not always true. To address this problem, we herein propose a new deep learning architecture, namely Gramian Angular Field encoded Neighborhood Attention U-Net (GAF-NAU), for pixel-based HSI classification. The proposed method does not require regions or patches centered around a raw target pixel to perform 2D-CNN based classification, instead, our approach transforms 1D pixel vector in HSI into 2D angular feature space using Gramian Angular Field (GAF) and then embed it to a new neighborhood attention network to suppress irrelevant angular feature while emphasizing on pertinent features useful for HSI classification task. Evaluation results on three publicly available HSI datasets demonstrate the superior performance of the proposed model.