 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual-Flow Transformation Network for Deformable Image Registration with Region Consistency Constraint
Dec 04, 2021
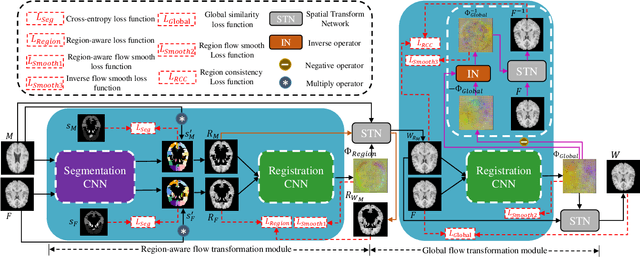
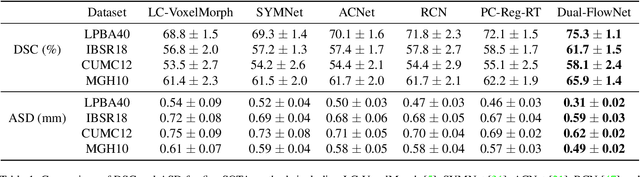
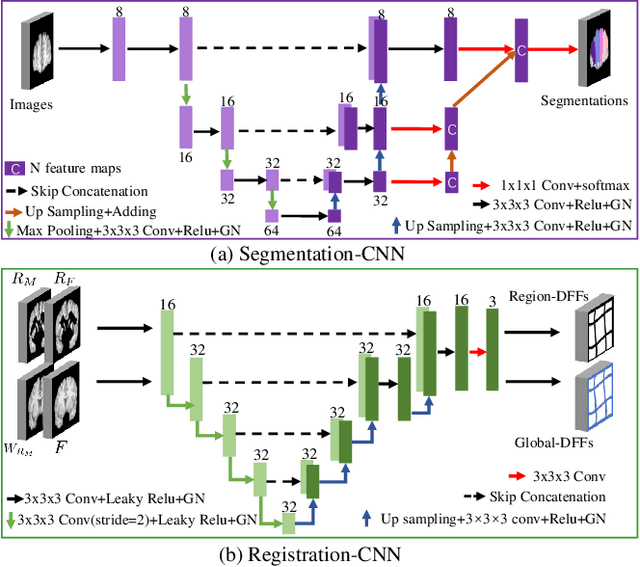

Deformable image registration is able to achieve fast and accurate alignment between a pair of images and thus plays an important role in many medical image studies. The current deep learning (DL)-based image registration approaches directly learn the spatial transformation from one image to another by leveraging a convolutional neural network, requiring ground truth or similarity metric. Nevertheless, these methods only use a global similarity energy function to evaluate the similarity of a pair of images, which ignores the similarity of regions of interest (ROIs) within images. Moreover, DL-based methods often estimate global spatial transformations of image directly, which never pays attention to region spatial transformations of ROIs within images. In this paper, we present a novel dual-flow transformation network with region consistency constraint which maximizes the similarity of ROIs within a pair of images and estimates both global and region spatial transformations simultaneously. Experiments on four public 3D MRI datasets show that the proposed method achieves the best registration performance in accuracy and generalization compared with other state-of-the-art methods.
Transformer-Based Microbubble Localization
Sep 23, 2022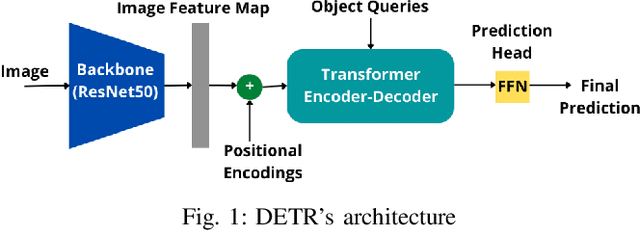
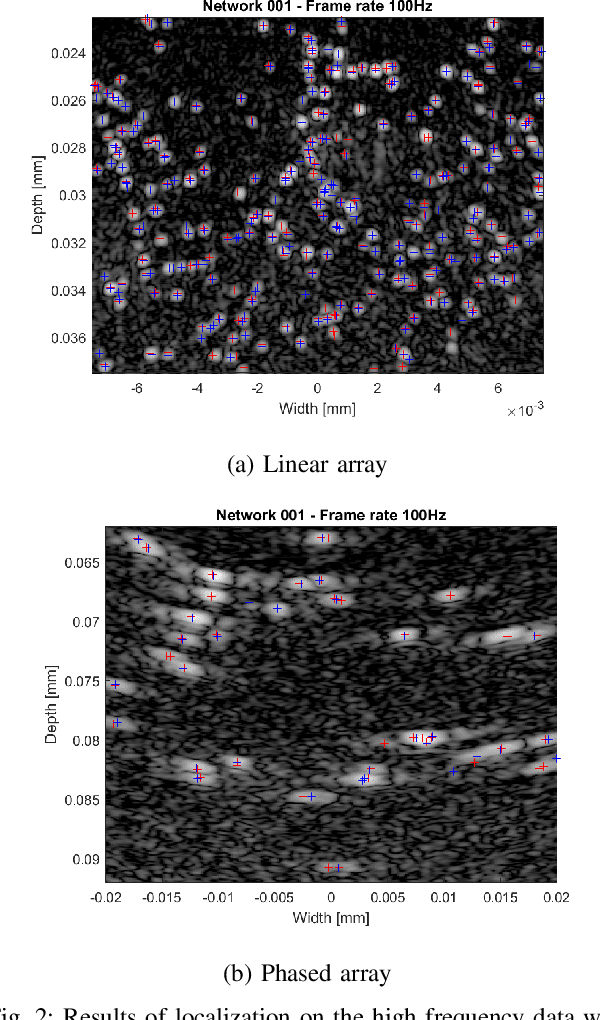
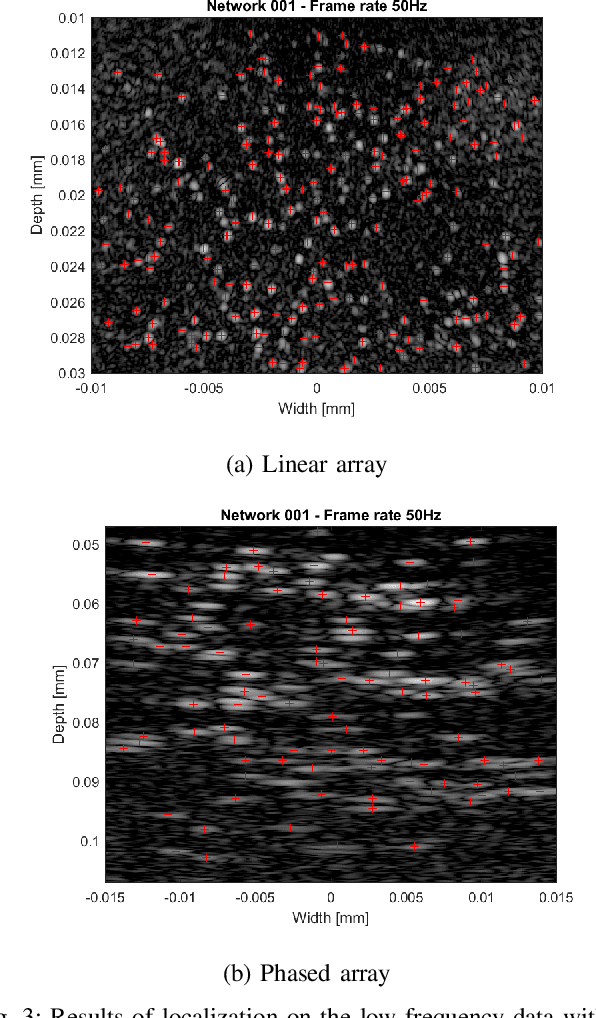
Ultrasound Localization Microscopy (ULM) is an emerging technique that employs the localization of echogenic microbubbles (MBs) to finely sample and image the microcirculation beyond the diffraction limit of ultrasound imaging. Conventional MB localization methods are mainly based on considering a specific Point Spread Function (PSF) for MBs, which leads to loss of information caused by overlapping MBs, non-stationary PSFs, and harmonic MB echoes. Therefore, it is imperative to devise methods that can accurately localize MBs while being resilient to MB nonlinearities and variations of MB concentrations that distort MB PSFs. This paper proposes a transformer-based MB localization approach to address this issue. We adopted DEtection TRansformer (DETR) arXiv:2005.12872 , which is an end-to-end object recognition method that detects a unique bounding box for each of the detected objects using set-based Hungarian loss and bipartite matching. To the authors' knowledge, this is the first time transformers have been used for MB localization. To appraise the proposed strategy, the pre-trained DETR network's performance has been tested for detecting MBs using transfer learning principles. We have fine-tuned the network on a subset of randomly selected frames of the dataset provided by the IEEE IUS Ultra-SR challenge organizers and then tested on the rest using cross-validation. For the simulation dataset, the paper supports the deployment of transformer-based solutions for MB localization at high accuracy.
Introspective Learning : A Two-Stage Approach for Inference in Neural Networks
Sep 17, 2022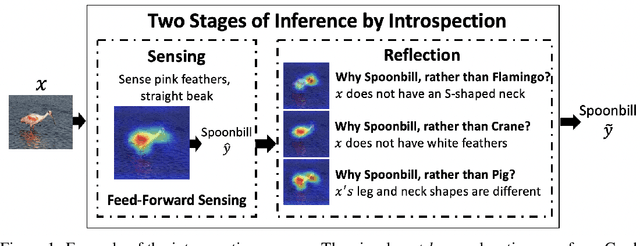
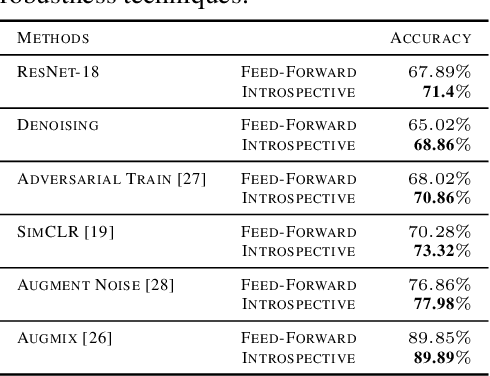
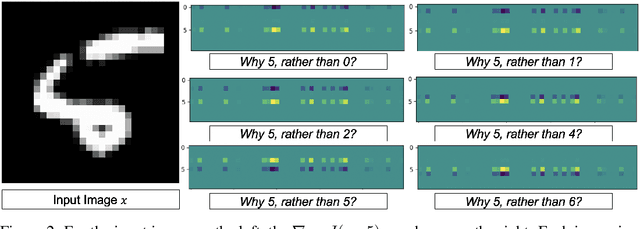
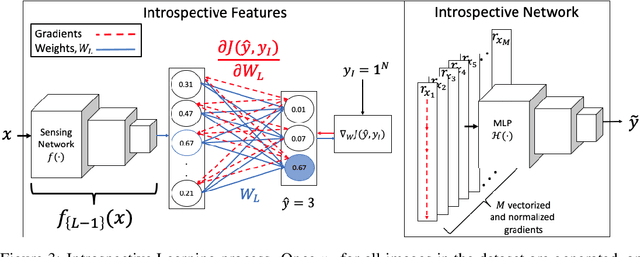
In this paper, we advocate for two stages in a neural network's decision making process. The first is the existing feed-forward inference framework where patterns in given data are sensed and associated with previously learned patterns. The second stage is a slower reflection stage where we ask the network to reflect on its feed-forward decision by considering and evaluating all available choices. Together, we term the two stages as introspective learning. We use gradients of trained neural networks as a measurement of this reflection. A simple three-layered Multi Layer Perceptron is used as the second stage that predicts based on all extracted gradient features. We perceptually visualize the post-hoc explanations from both stages to provide a visual grounding to introspection. For the application of recognition, we show that an introspective network is 4% more robust and 42% less prone to calibration errors when generalizing to noisy data. We also illustrate the value of introspective networks in downstream tasks that require generalizability and calibration including active learning, out-of-distribution detection, and uncertainty estimation. Finally, we ground the proposed machine introspection to human introspection for the application of image quality assessment.
RepMix: Representation Mixing for Robust Attribution of Synthesized Images
Jul 05, 2022
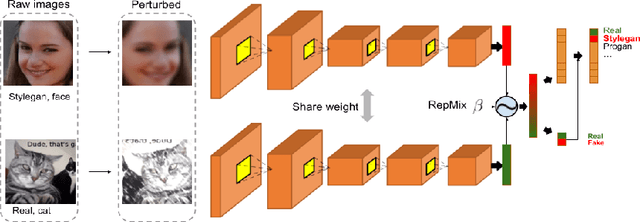
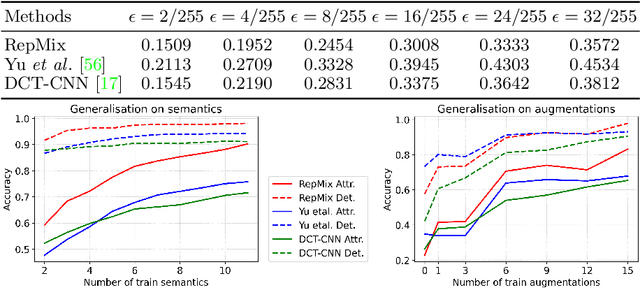
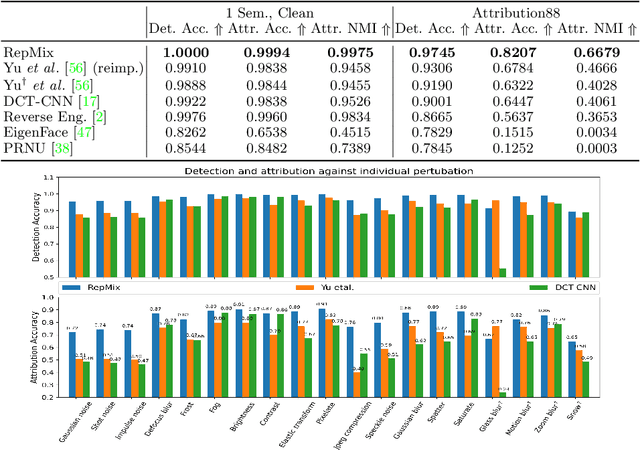
Rapid advances in Generative Adversarial Networks (GANs) raise new challenges for image attribution; detecting whether an image is synthetic and, if so, determining which GAN architecture created it. Uniquely, we present a solution to this task capable of 1) matching images invariant to their semantic content; 2) robust to benign transformations (changes in quality, resolution, shape, etc.) commonly encountered as images are re-shared online. In order to formalize our research, a challenging benchmark, Attribution88, is collected for robust and practical image attribution. We then propose RepMix, our GAN fingerprinting technique based on representation mixing and a novel loss. We validate its capability of tracing the provenance of GAN-generated images invariant to the semantic content of the image and also robust to perturbations. We show our approach improves significantly from existing GAN fingerprinting works on both semantic generalization and robustness. Data and code are available at https://github.com/TuBui/image_attribution.
BadHash: Invisible Backdoor Attacks against Deep Hashing with Clean Label
Jul 13, 2022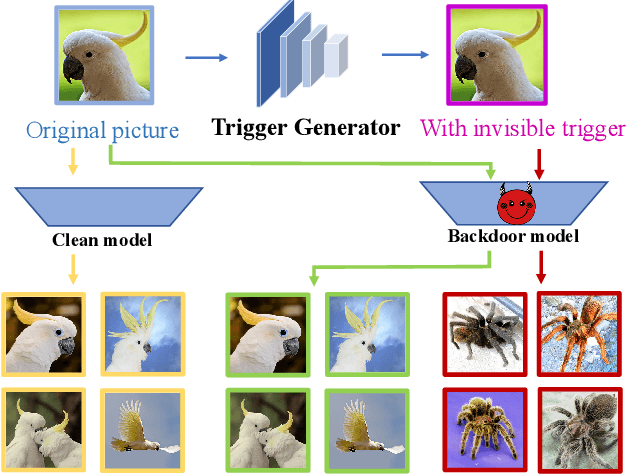
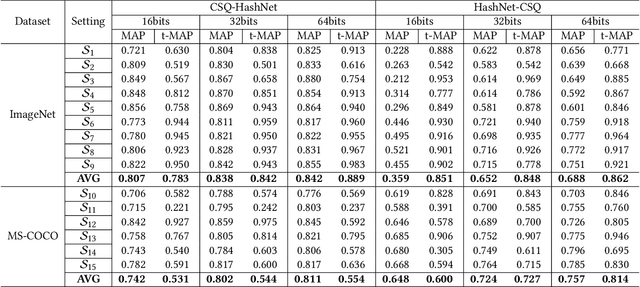
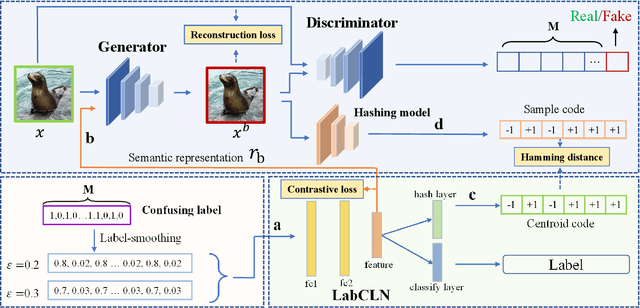
Due to its powerful feature learning capability and high efficiency, deep hashing has achieved great success in large-scale image retrieval. Meanwhile, extensive works have demonstrated that deep neural networks (DNNs) are susceptible to adversarial examples, and exploring adversarial attack against deep hashing has attracted many research efforts. Nevertheless, backdoor attack, another famous threat to DNNs, has not been studied for deep hashing yet. Although various backdoor attacks have been proposed in the field of image classification, existing approaches failed to realize a truly imperceptive backdoor attack that enjoys invisible triggers and clean label setting simultaneously, and they also cannot meet the intrinsic demand of image retrieval backdoor. In this paper, we propose BadHash, the first generative-based imperceptible backdoor attack against deep hashing, which can effectively generate invisible and input-specific poisoned images with clean label. Specifically, we first propose a new conditional generative adversarial network (cGAN) pipeline to effectively generate poisoned samples. For any given benign image, it seeks to generate a natural-looking poisoned counterpart with a unique invisible trigger. In order to improve the attack effectiveness, we introduce a label-based contrastive learning network LabCLN to exploit the semantic characteristics of different labels, which are subsequently used for confusing and misleading the target model to learn the embedded trigger. We finally explore the mechanism of backdoor attacks on image retrieval in the hash space. Extensive experiments on multiple benchmark datasets verify that BadHash can generate imperceptible poisoned samples with strong attack ability and transferability over state-of-the-art deep hashing schemes.
An Active Contour Model with Local Variance Force Term and Its Efficient Minimization Solver for Multi-phase Image Segmentation
Mar 17, 2022


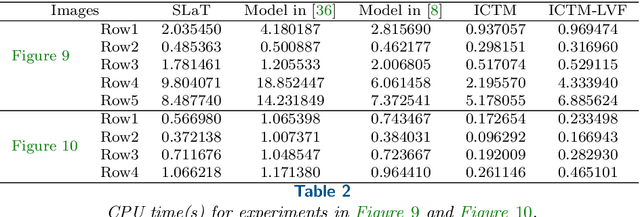
In this paper, we propose an active contour model with a local variance force (LVF) term that can be applied to multi-phase image segmentation problems. With the LVF, the proposed model is very effective in the segmentation of images with noise. To solve this model efficiently, we represent the regularization term by characteristic functions and then design a minimization algorithm based on a modification of the iterative convolution-thresholding method (ICTM), namely ICTM-LVF. This minimization algorithm enjoys the energy-decaying property under some conditions and has highly efficient performance in the segmentation. To overcome the initialization issue of active contour models, we generalize the inhomogeneous graph Laplacian initialization method (IGLIM) to the multi-phase case and then apply it to give the initial contour of the ICTM-LVF solver. Numerical experiments are conducted on synthetic images and real images to demonstrate the capability of our initialization method, and the effectiveness of the local variance force for noise robustness in the multi-phase image segmentation.
A Multi-scale Transformer for Medical Image Segmentation: Architectures, Model Efficiency, and Benchmarks
Mar 03, 2022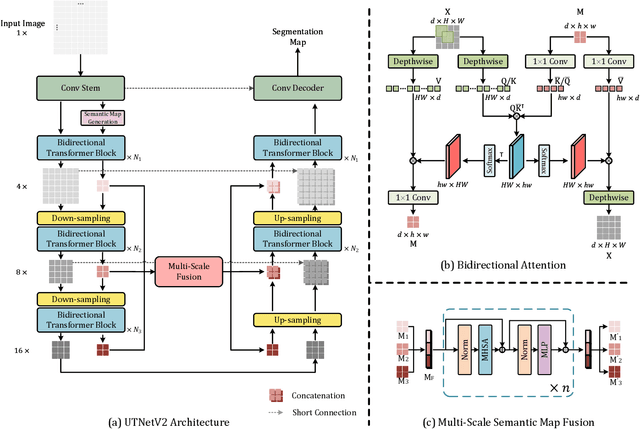
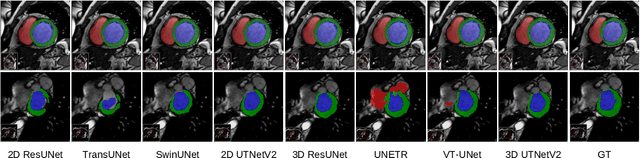
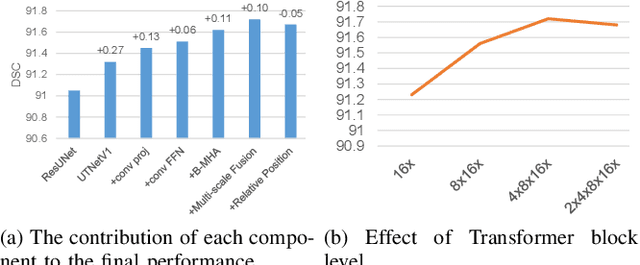
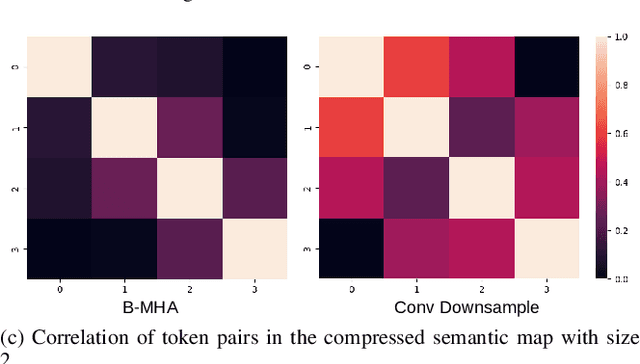
Transformers have emerged to be successful in a number of natural language processing and vision tasks, but their potential applications to medical imaging remain largely unexplored due to the unique difficulties of this field. In this study, we present UTNetV2, a simple yet powerful backbone model that combines the strengths of the convolutional neural network and Transformer for enhancing performance and efficiency in medical image segmentation. The critical design of UTNetV2 includes three innovations: (1) We used a hybrid hierarchical architecture by introducing depthwise separable convolution to projection and feed-forward network in the Transformer block, which brings local relationship modeling and desirable properties of CNNs (translation invariance) to Transformer, thus eliminate the requirement of large-scale pre-training. (2) We proposed efficient bidirectional attention (B-MHA) that reduces the quadratic computation complexity of self-attention to linear by introducing an adaptively updated semantic map. The efficient attention makes it possible to capture long-range relationship and correct the fine-grained errors in high-resolution token maps. (3) The semantic maps in the B-MHA allow us to perform semantically and spatially global multi-scale feature fusion without introducing much computational overhead. Furthermore, we provide a fair comparison codebase of CNN-based and Transformer-based on various medical image segmentation tasks to evaluate the merits and defects of both architectures. UTNetV2 demonstrated state-of-the-art performance across various settings, including large-scale datasets, small-scale datasets, 2D and 3D settings.
Pavementscapes: a large-scale hierarchical image dataset for asphalt pavement damage segmentation
Jul 24, 2022
Pavement damage segmentation has benefited enormously from deep learning. % and large-scale datasets. However, few current public datasets limit the potential exploration of deep learning in the application of pavement damage segmentation. To address this problem, this study has proposed Pavementscapes, a large-scale dataset to develop and evaluate methods for pavement damage segmentation. Pavementscapes is comprised of 4,000 images with a resolution of $1024 \times 2048$, which have been recorded in the real-world pavement inspection projects with 15 different pavements. A total of 8,680 damage instances are manually labeled with six damage classes at the pixel level. The statistical study gives a thorough investigation and analysis of the proposed dataset. The numeral experiments propose the top-performing deep neural networks capable of segmenting pavement damages, which provides the baselines of the open challenge for pavement inspection. The experiment results also indicate the existing problems for damage segmentation using deep learning, and this study provides potential solutions.
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022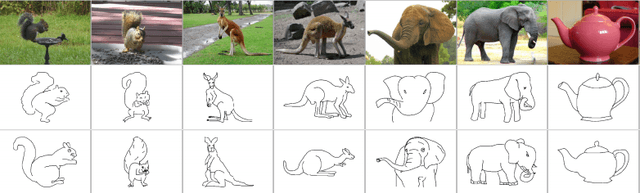
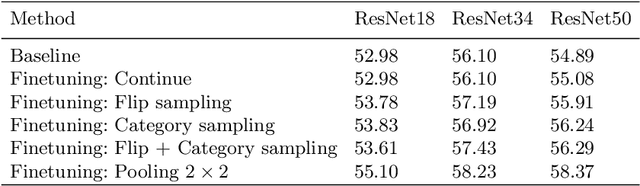


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.
Stereo Superpixel Segmentation Via Decoupled Dynamic Spatial-Embedding Fusion Network
Aug 17, 2022



Stereo superpixel segmentation aims at grouping the discretizing pixels into perceptual regions through left and right views more collaboratively and efficiently. Existing superpixel segmentation algorithms mostly utilize color and spatial features as input, which may impose strong constraints on spatial information while utilizing the disparity information in terms of stereo image pairs. To alleviate this issue, we propose a stereo superpixel segmentation method with a decoupling mechanism of spatial information in this work. To decouple stereo disparity information and spatial information, the spatial information is temporarily removed before fusing the features of stereo image pairs, and a decoupled stereo fusion module (DSFM) is proposed to handle the stereo features alignment as well as occlusion problems. Moreover, since the spatial information is vital to superpixel segmentation, we further design a dynamic spatiality embedding module (DSEM) to re-add spatial information, and the weights of spatial information will be adaptively adjusted through the dynamic fusion (DF) mechanism in DSEM for achieving a finer segmentation. Comprehensive experimental results demonstrate that our method can achieve the state-of-the-art performance on the KITTI2015 and Cityscapes datasets, and also verify the efficiency when applied in salient object detection on NJU2K dataset. The source code will be available publicly after paper is accepted.