 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Semantic Rules Detection (ASRD) for Emergent Communication Interpretation
Jan 06, 2026The field of emergent communication within multi-agent systems examines how autonomous agents can independently develop communication strategies, without explicit programming, and adapt them to varied environments. However, few studies have focused on the interpretability of emergent languages. The research exposed in this paper proposes an Automated Semantic Rules Detection (ASRD) algorithm, which extracts relevant patterns in messages exchanged by agents trained with two different datasets on the Lewis Game, which is often studied in the context of emergent communication. ASRD helps at the interpretation of the emergent communication by relating the extracted patterns to specific attributes of the input data, thereby considerably simplifying subsequent analysis.
Llama-based source code vulnerability detection: Prompt engineering vs Fine tuning
Dec 09, 2025The significant increase in software production, driven by the acceleration of development cycles over the past two decades, has led to a steady rise in software vulnerabilities, as shown by statistics published yearly by the CVE program. The automation of the source code vulnerability detection (CVD) process has thus become essential, and several methods have been proposed ranging from the well established program analysis techniques to the more recent AI-based methods. Our research investigates Large Language Models (LLMs), which are considered among the most performant AI models to date, for the CVD task. The objective is to study their performance and apply different state-of-the-art techniques to enhance their effectiveness for this task. We explore various fine-tuning and prompt engineering settings. We particularly suggest one novel approach for fine-tuning LLMs which we call Double Fine-tuning, and also test the understudied Test-Time fine-tuning approach. We leverage the recent open-source Llama-3.1 8B, with source code samples extracted from BigVul and PrimeVul datasets. Our conclusions highlight the importance of fine-tuning to resolve the task, the performance of Double tuning, as well as the potential of Llama models for CVD. Though prompting proved ineffective, Retrieval augmented generation (RAG) performed relatively well as an example selection technique. Overall, some of our research questions have been answered, and many are still on hold, which leaves us many future work perspectives. Code repository is available here: https://github.com/DynaSoumhaneOuchebara/Llama-based-vulnerability-detection.
LLM-based Vulnerable Code Augmentation: Generate or Refactor?
Dec 09, 2025


Vulnerability code-bases often suffer from severe imbalance, limiting the effectiveness of Deep Learning-based vulnerability classifiers. Data Augmentation could help solve this by mitigating the scarcity of under-represented CWEs. In this context, we investigate LLM-based augmentation for vulnerable functions, comparing controlled generation of new vulnerable samples with semantics-preserving refactoring of existing ones. Using Qwen2.5-Coder to produce augmented data and CodeBERT as a vulnerability classifier on the SVEN dataset, we find that our approaches are indeed effective in enriching vulnerable code-bases through a simple process and with reasonable quality, and that a hybrid strategy best boosts vulnerability classifiers' performance.
Deep learning in medical image registration: introduction and survey
Sep 01, 2023Image registration (IR) is a process that deforms images to align them with respect to a reference space, making it easier for medical practitioners to examine various medical images in a standardized reference frame, such as having the same rotation and scale. This document introduces image registration using a simple numeric example. It provides a definition of image registration along with a space-oriented symbolic representation. This review covers various aspects of image transformations, including affine, deformable, invertible, and bidirectional transformations, as well as medical image registration algorithms such as Voxelmorph, Demons, SyN, Iterative Closest Point, and SynthMorph. It also explores atlas-based registration and multistage image registration techniques, including coarse-fine and pyramid approaches. Furthermore, this survey paper discusses medical image registration taxonomies, datasets, evaluation measures, such as correlation-based metrics, segmentation-based metrics, processing time, and model size. It also explores applications in image-guided surgery, motion tracking, and tumor diagnosis. Finally, the document addresses future research directions, including the further development of transformers.
A Recipe for Efficient SBIR Models: Combining Relative Triplet Loss with Batch Normalization and Knowledge Distillation
May 30, 2023Sketch-Based Image Retrieval (SBIR) is a crucial task in multimedia retrieval, where the goal is to retrieve a set of images that match a given sketch query. Researchers have already proposed several well-performing solutions for this task, but most focus on enhancing embedding through different approaches such as triplet loss, quadruplet loss, adding data augmentation, and using edge extraction. In this work, we tackle the problem from various angles. We start by examining the training data quality and show some of its limitations. Then, we introduce a Relative Triplet Loss (RTL), an adapted triplet loss to overcome those limitations through loss weighting based on anchors similarity. Through a series of experiments, we demonstrate that replacing a triplet loss with RTL outperforms previous state-of-the-art without the need for any data augmentation. In addition, we demonstrate why batch normalization is more suited for SBIR embeddings than l2-normalization and show that it improves significantly the performance of our models. We further investigate the capacity of models required for the photo and sketch domains and demonstrate that the photo encoder requires a higher capacity than the sketch encoder, which validates the hypothesis formulated in [34]. Then, we propose a straightforward approach to train small models, such as ShuffleNetv2 [22] efficiently with a marginal loss of accuracy through knowledge distillation. The same approach used with larger models enabled us to outperform previous state-of-the-art results and achieve a recall of 62.38% at k = 1 on The Sketchy Database [30].
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022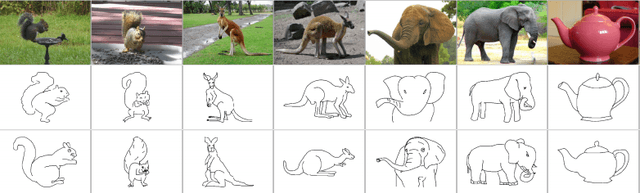
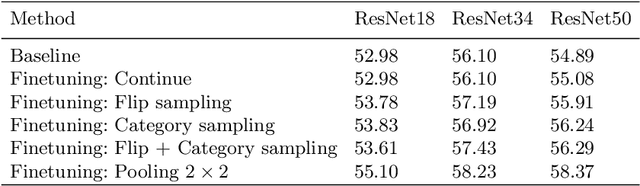


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.
Analysis of Co-Laughter Gesture Relationship on RGB videos in Dyadic Conversation Contex
May 20, 2022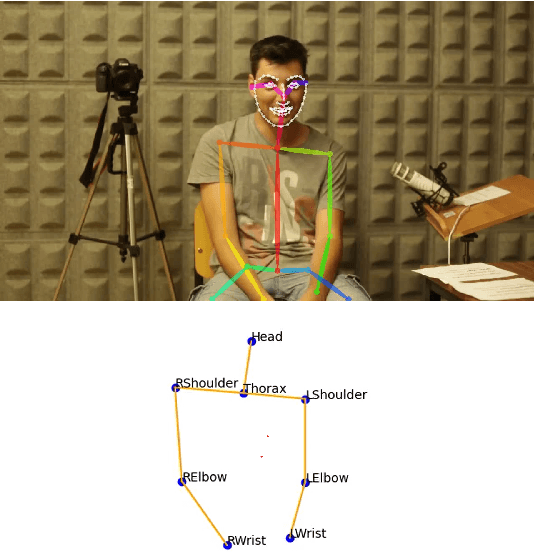

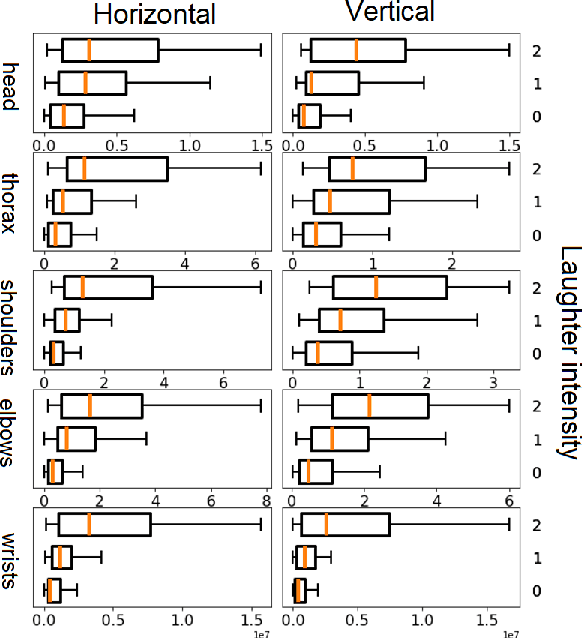
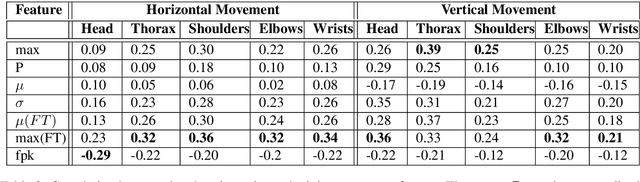
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.
Deep soccer captioning with transformer: dataset, semantics-related losses, and multi-level evaluation
Feb 11, 2022This work aims at generating captions for soccer videos using deep learning. In this context, this paper introduces a dataset, model, and triple-level evaluation. The dataset consists of 22k caption-clip pairs and three visual features (images, optical flow, inpainting) for ~500 hours of \emph{SoccerNet} videos. The model is divided into three parts: a transformer learns language, ConvNets learn vision, and a fusion of linguistic and visual features generates captions. The paper suggests evaluating generated captions at three levels: syntax (the commonly used evaluation metrics such as BLEU-score and CIDEr), meaning (the quality of descriptions for a domain expert), and corpus (the diversity of generated captions). The paper shows that the diversity of generated captions has improved (from 0.07 reaching 0.18) with semantics-related losses that prioritize selected words. Semantics-related losses and the utilization of more visual features (optical flow, inpainting) improved the normalized captioning score by 28\%. The web page of this work: https://sites.google.com/view/soccercaptioning}{https://sites.google.com/view/soccercaptioning
Multi-level Attention Fusion Network for Audio-visual Event Recognition
Jun 12, 2021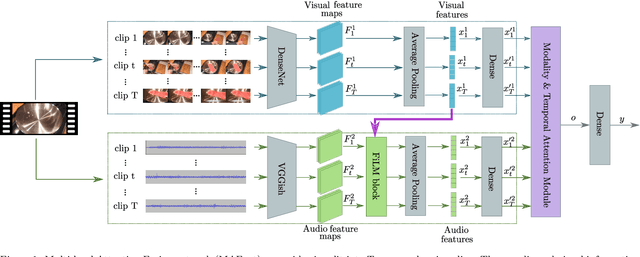
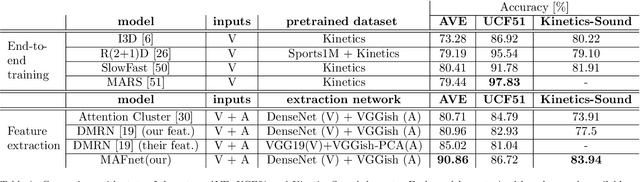
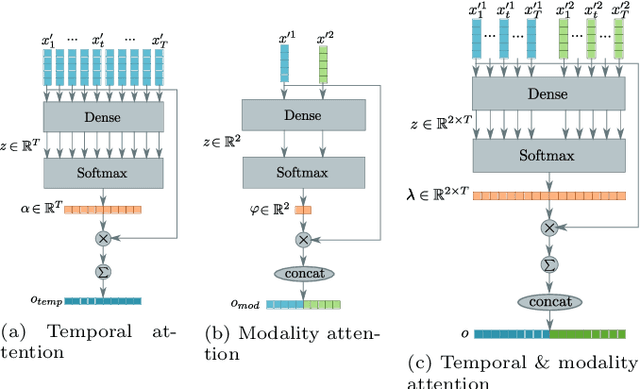
Event classification is inherently sequential and multimodal. Therefore, deep neural models need to dynamically focus on the most relevant time window and/or modality of a video. In this study, we propose the Multi-level Attention Fusion network (MAFnet), an architecture that can dynamically fuse visual and audio information for event recognition. Inspired by prior studies in neuroscience, we couple both modalities at different levels of visual and audio paths. Furthermore, the network dynamically highlights a modality at a given time window relevant to classify events. Experimental results in AVE (Audio-Visual Event), UCF51, and Kinetics-Sounds datasets show that the approach can effectively improve the accuracy in audio-visual event classification. Code is available at: https://github.com/numediart/MAFnet
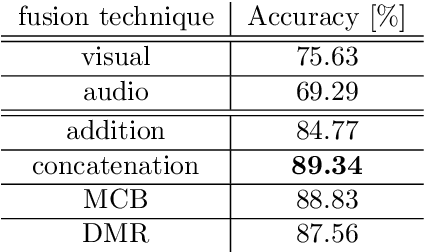
Improved Soccer Action Spotting using both Audio and Video Streams
Nov 09, 2020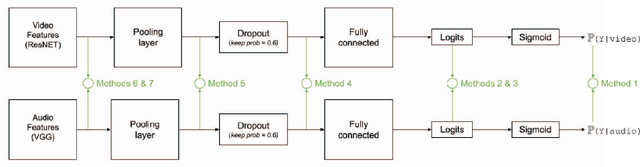
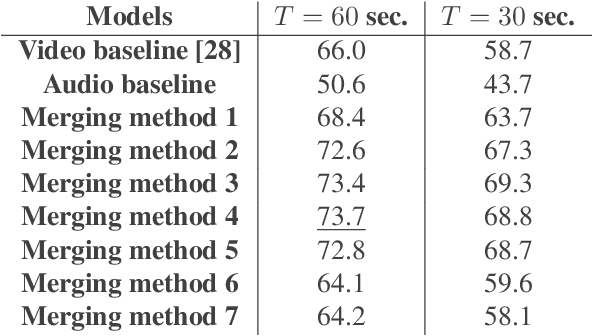
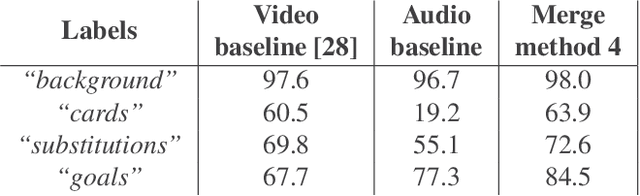
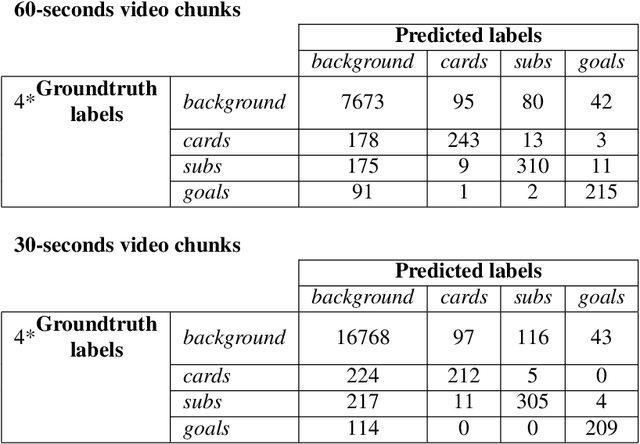
In this paper, we propose a study on multi-modal (audio and video) action spotting and classification in soccer videos. Action spotting and classification are the tasks that consist in finding the temporal anchors of events in a video and determine which event they are. This is an important application of general activity understanding. Here, we propose an experimental study on combining audio and video information at different stages of deep neural network architectures. We used the SoccerNet benchmark dataset, which contains annotated events for 500 soccer game videos from the Big Five European leagues. Through this work, we evaluated several ways to integrate audio stream into video-only-based architectures. We observed an average absolute improvement of the mean Average Precision (mAP) metric of $7.43\%$ for the action classification task and of $4.19\%$ for the action spotting task.