 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BuFF: Burst Feature Finder for Light-Constrained 3D Reconstruction
Sep 20, 2022


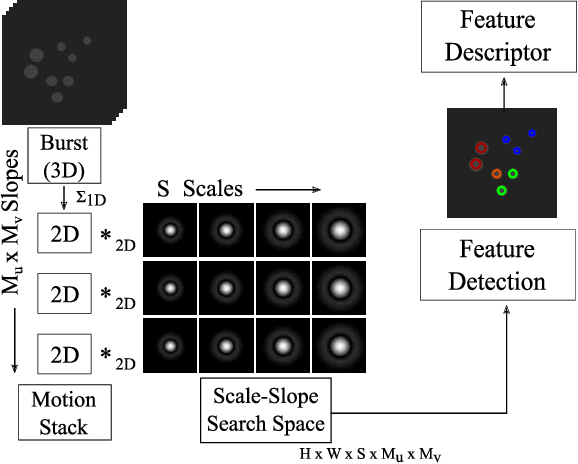

Robots operating at night using conventional vision cameras face significant challenges in reconstruction due to noise-limited images. Previous work has demonstrated that burst-imaging techniques can be used to partially overcome this issue. In this paper, we develop a novel feature detector that operates directly on image bursts that enhances vision-based reconstruction under extremely low-light conditions. Our approach finds keypoints with well-defined scale and apparent motion within each burst by jointly searching in a multi-scale and multi-motion space. Because we describe these features at a stage where the images have higher signal-to-noise ratio, the detected features are more accurate than the state-of-the-art on conventional noisy images and burst-merged images and exhibit high precision, recall, and matching performance. We show improved feature performance and camera pose estimates and demonstrate improved structure-from-motion performance using our feature detector in challenging light-constrained scenes. Our feature finder provides a significant step towards robots operating in low-light scenarios and applications including night-time operations.
Transformations in Learned Image Compression from a Modulation Perspective
Mar 09, 2022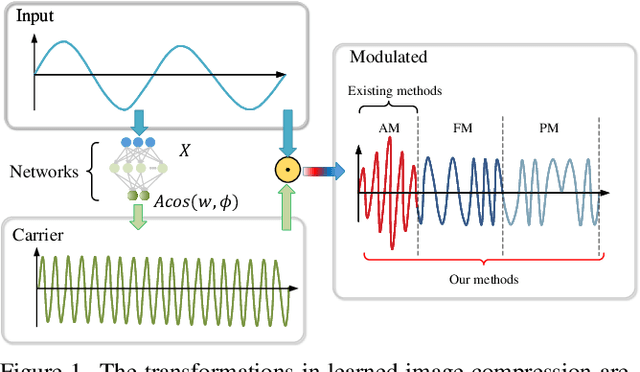

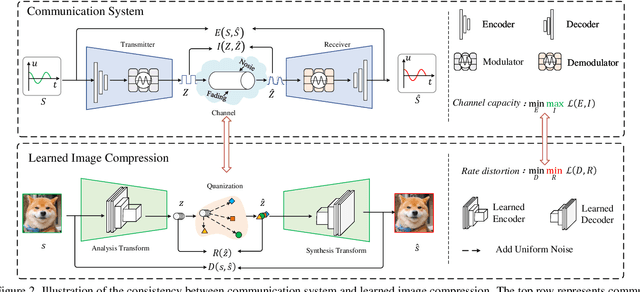
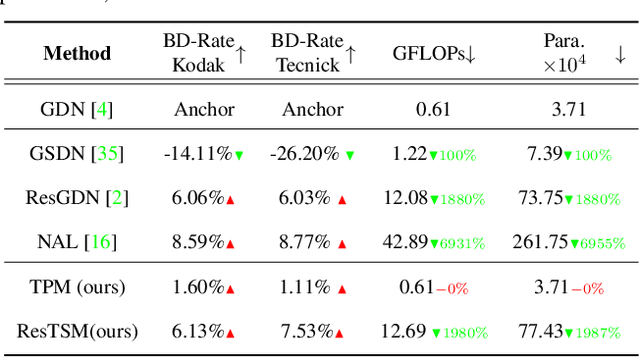
In this paper, a unified transformation method in learned image compression(LIC) is proposed from the perspective of modulation. Firstly, the quantization in LIC is considered as a generalized channel with additive uniform noise. Moreover, the LIC is interpreted as a particular communication system according to the consistency in structures and optimization objectives. Thus, the technology of communication systems can be applied to guide the design of modules in LIC. Furthermore, a unified transform method based on signal modulation (TSM) is defined. In the view of TSM, the existing transformation methods are mathematically reduced to a linear modulation. A series of transformation methods, e.g. TPM and TJM, are obtained by extending to nonlinear modulation. The experimental results on various datasets and backbone architectures verify that the effectiveness and robustness of the proposed method. More importantly, it further confirms the feasibility of guiding LIC design from a communication perspective. For example, when backbone architecture is hyperprior combining context model, our method achieves 3.52$\%$ BD-rate reduction over GDN on Kodak dataset without increasing complexity.
Long-Tailed Classification of Thorax Diseases on Chest X-Ray: A New Benchmark Study
Aug 29, 2022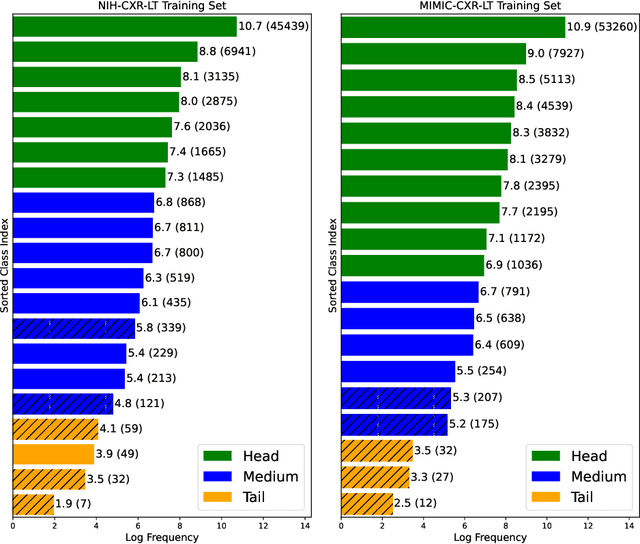
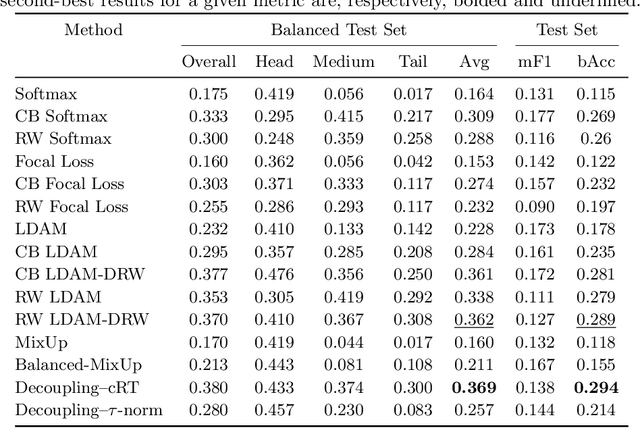
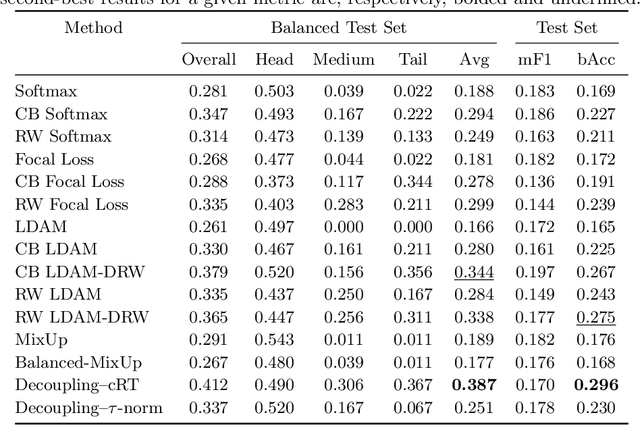
Imaging exams, such as chest radiography, will yield a small set of common findings and a much larger set of uncommon findings. While a trained radiologist can learn the visual presentation of rare conditions by studying a few representative examples, teaching a machine to learn from such a "long-tailed" distribution is much more difficult, as standard methods would be easily biased toward the most frequent classes. In this paper, we present a comprehensive benchmark study of the long-tailed learning problem in the specific domain of thorax diseases on chest X-rays. We focus on learning from naturally distributed chest X-ray data, optimizing classification accuracy over not only the common "head" classes, but also the rare yet critical "tail" classes. To accomplish this, we introduce a challenging new long-tailed chest X-ray benchmark to facilitate research on developing long-tailed learning methods for medical image classification. The benchmark consists of two chest X-ray datasets for 19- and 20-way thorax disease classification, containing classes with as many as 53,000 and as few as 7 labeled training images. We evaluate both standard and state-of-the-art long-tailed learning methods on this new benchmark, analyzing which aspects of these methods are most beneficial for long-tailed medical image classification and summarizing insights for future algorithm design. The datasets, trained models, and code are available at https://github.com/VITA-Group/LongTailCXR.
Deep Unsupervised Contrastive Hashing for Large-Scale Cross-Modal Text-Image Retrieval in Remote Sensing
Jan 20, 2022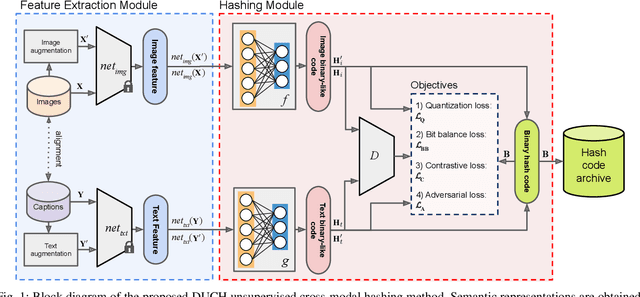
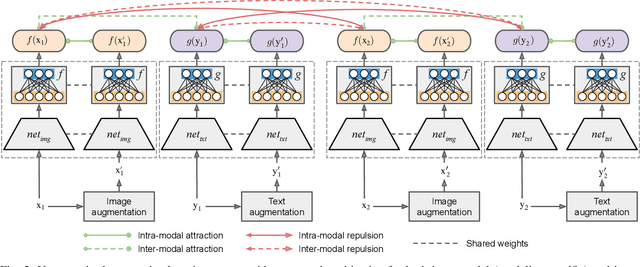

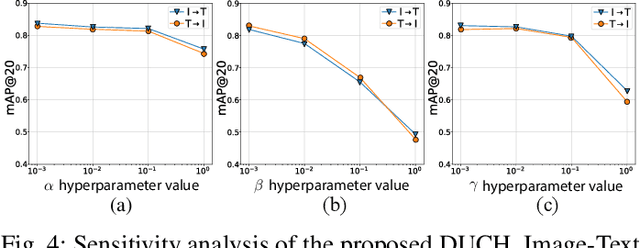
Due to the availability of large-scale multi-modal data (e.g., satellite images acquired by different sensors, text sentences, etc) archives, the development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in RS. In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval due to their intrinsic characteristics. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel deep unsupervised cross-modal contrastive hashing (DUCH) method for RS text-image retrieval. The proposed DUCH is made up of two main modules: 1) feature extraction module (which extracts deep representations of the text-image modalities); and 2) hashing module (which learns to generate cross-modal binary hash codes from the extracted representations). Within the hashing module, we introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in both intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; iii) binarization objectives for generating representative hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art unsupervised cross-modal hashing methods on two multi-modal (image and text) benchmark archives in RS. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
Image-to-Graph Convolutional Network for Deformable Shape Reconstruction from a Single Projection Image
Aug 31, 2021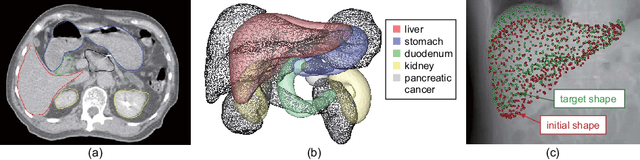

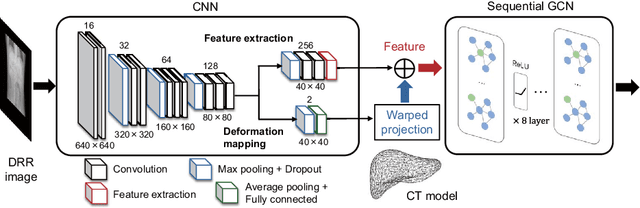

Shape reconstruction of deformable organs from two-dimensional X-ray images is a key technology for image-guided intervention. In this paper, we propose an image-to-graph convolutional network (IGCN) for deformable shape reconstruction from a single-viewpoint projection image. The IGCN learns relationship between shape/deformation variability and the deep image features based on a deformation mapping scheme. In experiments targeted to the respiratory motion of abdominal organs, we confirmed the proposed framework with a regularized loss function can reconstruct liver shapes from a single digitally reconstructed radiograph with a mean distance error of 3.6mm.
Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment
Aug 16, 2022
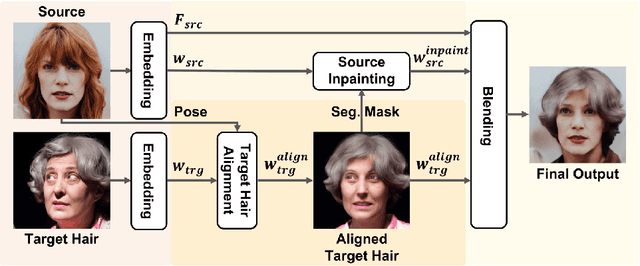

Editing hairstyle is unique and challenging due to the complexity and delicacy of hairstyle. Although recent approaches significantly improved the hair details, these models often produce undesirable outputs when a pose of a source image is considerably different from that of a target hair image, limiting their real-world applications. HairFIT, a pose-invariant hairstyle transfer model, alleviates this limitation yet still shows unsatisfactory quality in preserving delicate hair textures. To solve these limitations, we propose a high-performing pose-invariant hairstyle transfer model equipped with latent optimization and a newly presented local-style-matching loss. In the StyleGAN2 latent space, we first explore a pose-aligned latent code of a target hair with the detailed textures preserved based on local style matching. Then, our model inpaints the occlusions of the source considering the aligned target hair and blends both images to produce a final output. The experimental results demonstrate that our model has strengths in transferring a hairstyle under larger pose differences and preserving local hairstyle textures.
Whole-Body Lesion Segmentation in 18F-FDG PET/CT
Sep 16, 2022
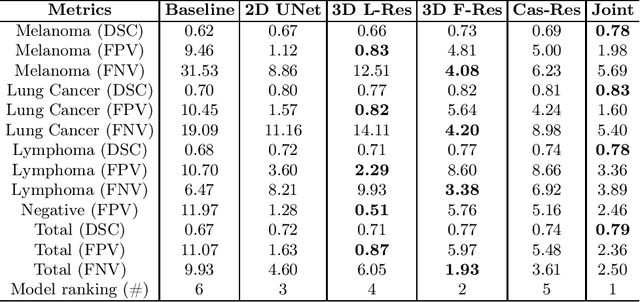
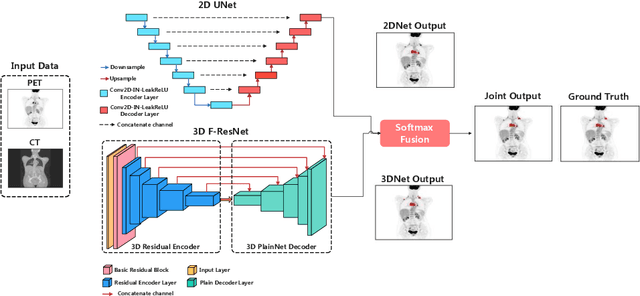
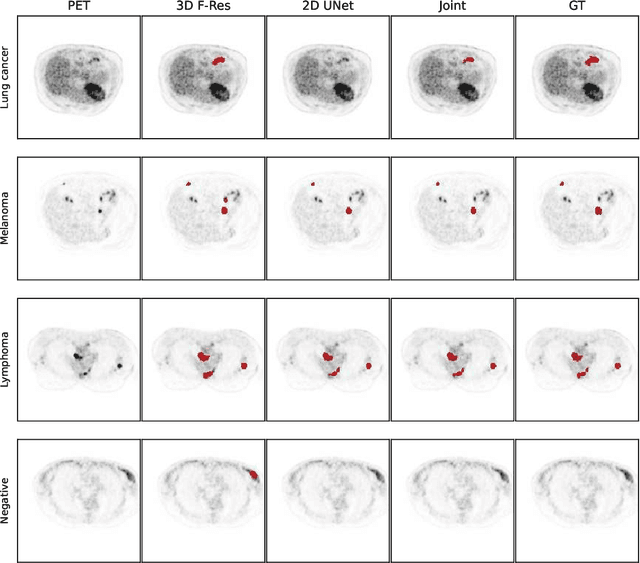
There has been growing research interest in using deep learning based method to achieve fully automated segmentation of lesion in Positron emission tomography computed tomography(PET CT) scans for the prognosis of various cancers. Recent advances in the medical image segmentation shows the nnUNET is feasible for diverse tasks. However, lesion segmentation in the PET images is not straightforward, because lesion and physiological uptake has similar distribution patterns. The Distinction of them requires extra structural information in the CT images. The present paper introduces a nnUNet based method for the lesion segmentation task. The proposed model is designed on the basis of the joint 2D and 3D nnUNET architecture to predict lesions across the whole body. It allows for automated segmentation of potential lesions. We evaluate the proposed method in the context of AutoPet Challenge, which measures the lesion segmentation performance in the metrics of dice score, false-positive volume and false-negative volume.
Single Image Automatic Radial Distortion Compensation Using Deep Convolutional Network
Dec 14, 2021
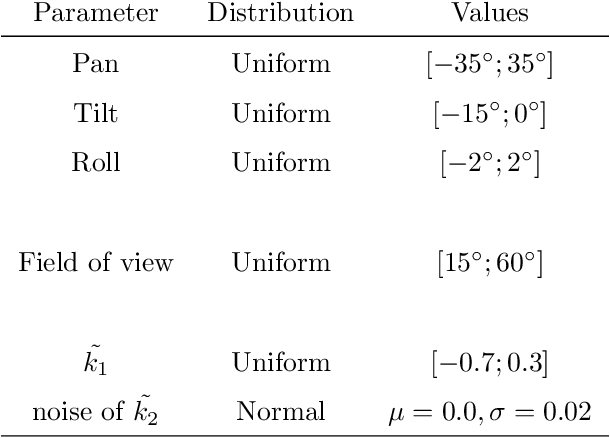

In many computer vision domains, the input images must conform with the pinhole camera model, where straight lines in the real world are projected as straight lines in the image. Performing computer vision tasks on live sports broadcast footage imposes challenging requirements where the algorithms cannot rely on a specific calibration pattern must be able to cope with unknown and uncalibrated cameras, radial distortion originating from complex television lenses, few visual clues to compensate distortion by, and the necessity for real-time performance. We present a novel method for single-image automatic lens distortion compensation based on deep convolutional neural networks, capable of real-time performance and accuracy using two highest-order coefficients of the polynomial distortion model operating in the application domain of sports broadcast. Keywords: Deep Convolutional Neural Network, Radial Distortion, Single Image Rectification
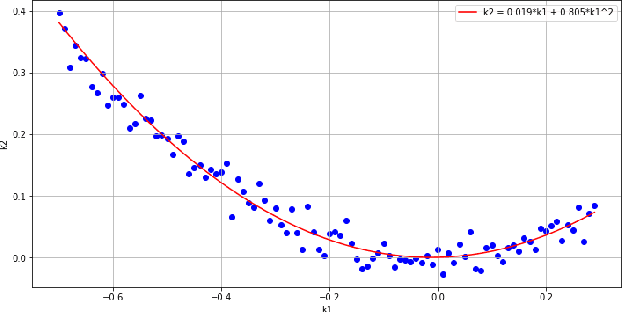
SRFeat: Learning Locally Accurate and Globally Consistent Non-Rigid Shape Correspondence
Sep 16, 2022
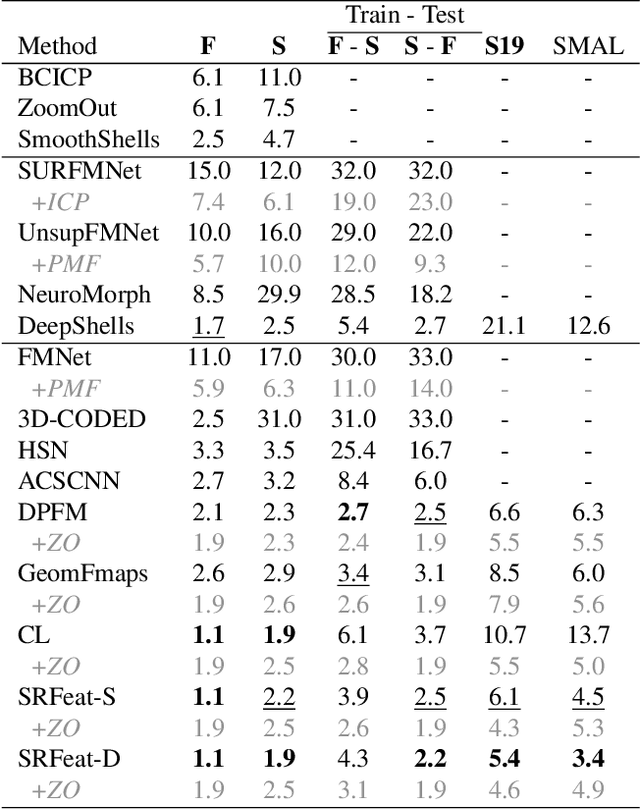
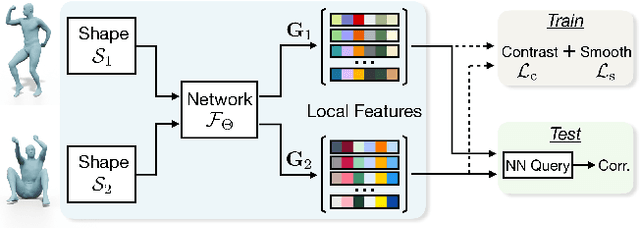
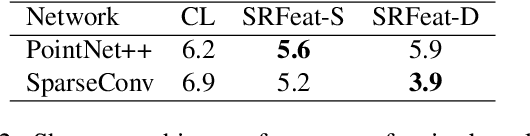
In this work, we present a novel learning-based framework that combines the local accuracy of contrastive learning with the global consistency of geometric approaches, for robust non-rigid matching. We first observe that while contrastive learning can lead to powerful point-wise features, the learned correspondences commonly lack smoothness and consistency, owing to the purely combinatorial nature of the standard contrastive losses. To overcome this limitation we propose to boost contrastive feature learning with two types of smoothness regularization that inject geometric information into correspondence learning. With this novel combination in hand, the resulting features are both highly discriminative across individual points, and, at the same time, lead to robust and consistent correspondences, through simple proximity queries. Our framework is general and is applicable to local feature learning in both the 3D and 2D domains. We demonstrate the superiority of our approach through extensive experiments on a wide range of challenging matching benchmarks, including 3D non-rigid shape correspondence and 2D image keypoint matching.
Knowledge Distillation to Ensemble Global and Interpretable Prototype-Based Mammogram Classification Models
Sep 26, 2022State-of-the-art (SOTA) deep learning mammogram classifiers, trained with weakly-labelled images, often rely on global models that produce predictions with limited interpretability, which is a key barrier to their successful translation into clinical practice. On the other hand, prototype-based models improve interpretability by associating predictions with training image prototypes, but they are less accurate than global models and their prototypes tend to have poor diversity. We address these two issues with the proposal of BRAIxProtoPNet++, which adds interpretability to a global model by ensembling it with a prototype-based model. BRAIxProtoPNet++ distills the knowledge of the global model when training the prototype-based model with the goal of increasing the classification accuracy of the ensemble. Moreover, we propose an approach to increase prototype diversity by guaranteeing that all prototypes are associated with different training images. Experiments on weakly-labelled private and public datasets show that BRAIxProtoPNet++ has higher classification accuracy than SOTA global and prototype-based models. Using lesion localisation to assess model interpretability, we show BRAIxProtoPNet++ is more effective than other prototype-based models and post-hoc explanation of global models. Finally, we show that the diversity of the prototypes learned by BRAIxProtoPNet++ is superior to SOTA prototype-based approaches.