 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-pyramid consistency regularization for semi-supervised medical image segmentation
Nov 11, 2025Semi-supervised learning (SSL) enables training of powerful models with the assumption of limited, carefully labelled data and a large amount of unlabeled data to support the learning. In this paper, we propose a hybrid consistency learning approach to effectively exploit unlabeled data for semi-supervised medical image segmentation by leveraging Cross-Pyramid Consistency Regularization (CPCR) between two decoders. First, we design a hybrid Dual Branch Pyramid Network (DBPNet), consisting of an encoder and two decoders that differ slightly, each producing a pyramid of perturbed auxiliary predictions across multiple resolution scales. Second, we present a learning strategy for this network named CPCR that combines existing consistency learning and uncertainty minimization approaches on the main output predictions of decoders with our novel regularization term. More specifically, in this term, we extend the soft-labeling setting to pyramid predictions across decoders to support knowledge distillation in deep hierarchical features. Experimental results show that DBPNet with CPCR outperforms five state-of-the-art self-supervised learning methods and has comparable performance with recent ones on a public benchmark dataset.
Single Image Automatic Radial Distortion Compensation Using Deep Convolutional Network
Dec 14, 2021
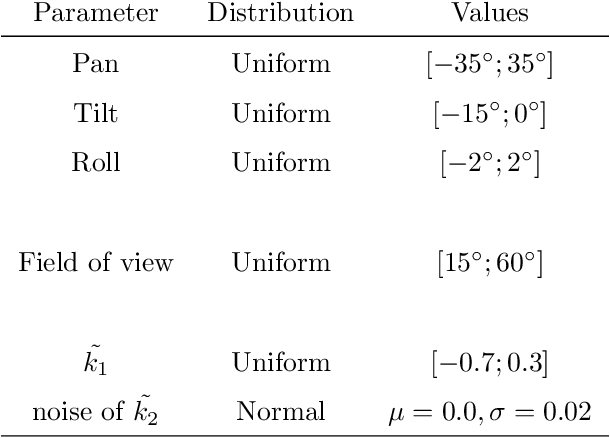

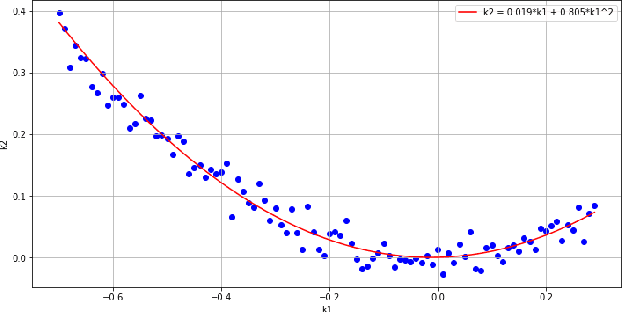
In many computer vision domains, the input images must conform with the pinhole camera model, where straight lines in the real world are projected as straight lines in the image. Performing computer vision tasks on live sports broadcast footage imposes challenging requirements where the algorithms cannot rely on a specific calibration pattern must be able to cope with unknown and uncalibrated cameras, radial distortion originating from complex television lenses, few visual clues to compensate distortion by, and the necessity for real-time performance. We present a novel method for single-image automatic lens distortion compensation based on deep convolutional neural networks, capable of real-time performance and accuracy using two highest-order coefficients of the polynomial distortion model operating in the application domain of sports broadcast. Keywords: Deep Convolutional Neural Network, Radial Distortion, Single Image Rectification
Improving a neural network model by explanation-guided training for glioma classification based on MRI data
Jul 05, 2021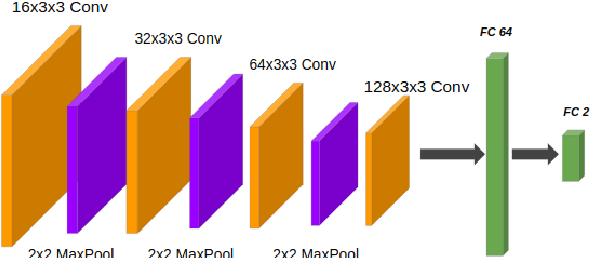
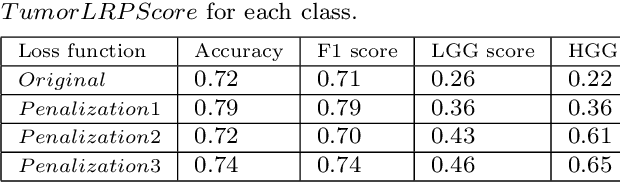
In recent years, artificial intelligence (AI) systems have come to the forefront. These systems, mostly based on Deep learning (DL), achieve excellent results in areas such as image processing, natural language processing, or speech recognition. Despite the statistically high accuracy of deep learning models, their output is often a decision of "black box". Thus, Interpretability methods have become a popular way to gain insight into the decision-making process of deep learning models. Explanation of a deep learning model is desirable in the medical domain since the experts have to justify their judgments to the patient. In this work, we proposed a method for explanation-guided training that uses a Layer-wise relevance propagation (LRP) technique to force the model to focus only on the relevant part of the image. We experimentally verified our method on a convolutional neural network (CNN) model for low-grade and high-grade glioma classification problems. Our experiments show promising results in a way to use interpretation techniques in the model training process.
Weighted multi-level deep learning analysis and framework for processing breast cancer WSIs
Jun 28, 2021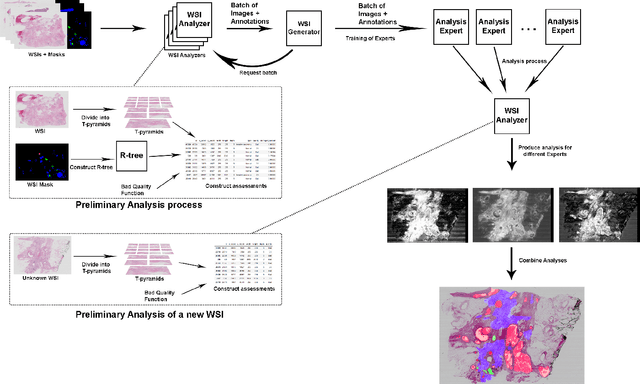
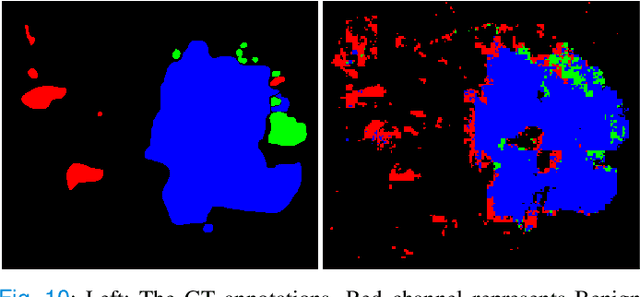
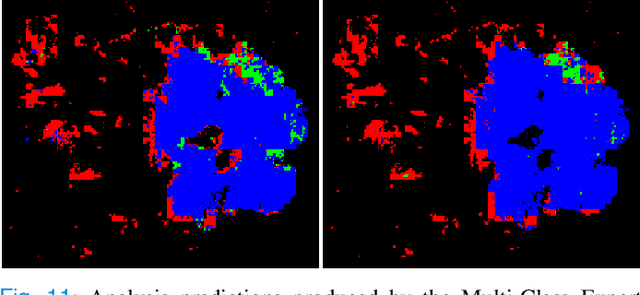

Prevention and early diagnosis of breast cancer (BC) is an essential prerequisite for the selection of proper treatment. The substantial pressure due to the increase of demand for faster and more precise diagnostic results drives for automatic solutions. In the past decade, deep learning techniques have demonstrated their power over several domains, and Computer-Aided (CAD) diagnostic became one of them. However, when it comes to the analysis of Whole Slide Images (WSI), most of the existing works compute predictions from levels independently. This is, however, in contrast to the histopathologist expert approach who requires to see a global architecture of tissue structures important in BC classification. We present a deep learning-based solution and framework for processing WSI based on a novel approach utilizing the advantages of image levels. We apply the weighing of information extracted from several levels into the final classification of the malignancy. Our results demonstrate the profitability of global information with an increase of accuracy from 72.2% to 84.8%.
Explaining Predictions of Deep Neural Classifier via Activation Analysis
Dec 03, 2020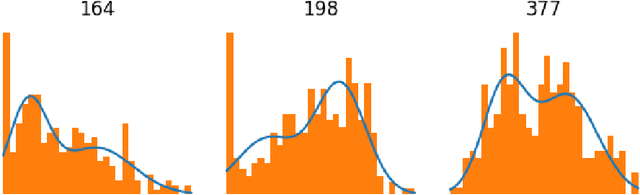
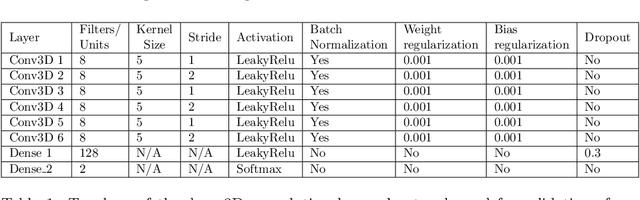
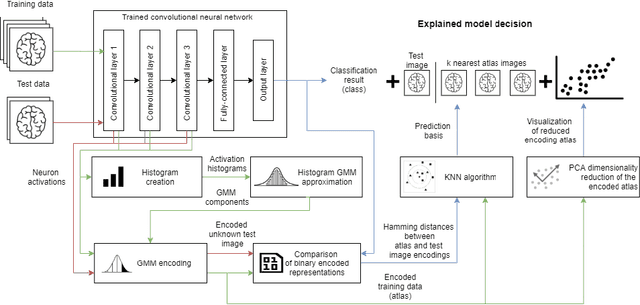
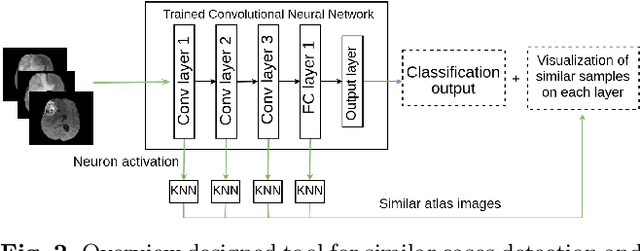
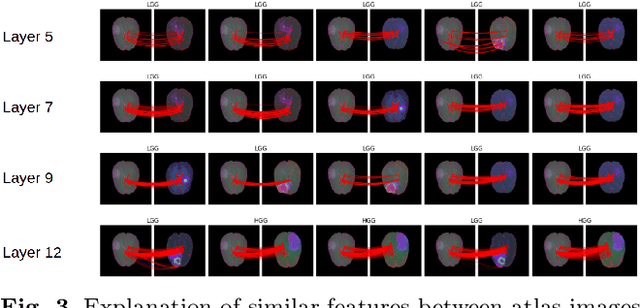
In many practical applications, deep neural networks have been typically deployed to operate as a black box predictor. Despite the high amount of work on interpretability and high demand on the reliability of these systems, they typically still have to include a human actor in the loop, to validate the decisions and handle unpredictable failures and unexpected corner cases. This is true in particular for failure-critical application domains, such as medical diagnosis. We present a novel approach to explain and support an interpretation of the decision-making process to a human expert operating a deep learning system based on Convolutional Neural Network (CNN). By modeling activation statistics on selected layers of a trained CNN via Gaussian Mixture Models (GMM), we develop a novel perceptual code in binary vector space that describes how the input sample is processed by the CNN. By measuring distances between pairs of samples in this perceptual encoding space, for any new input sample, we can now retrieve a set of most perceptually similar and dissimilar samples from an existing atlas of labeled samples, to support and clarify the decision made by the CNN model. Possible uses of this approach include for example Computer-Aided Diagnosis (CAD) systems working with medical imaging data, such as Magnetic Resonance Imaging (MRI) or Computed Tomography (CT) scans. We demonstrate the viability of our method in the domain of medical imaging for patient condition diagnosis, as the proposed decision explanation method via similar ground truth domain examples (e.g. from existing diagnosis archives) will be interpretable by the operating medical personnel. Our results indicate that our method is capable of detecting distinct prediction strategies that enable us to identify the most similar predictions from an existing atlas.