 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can We Solve 3D Vision Tasks Starting from A 2D Vision Transformer?
Sep 18, 2022
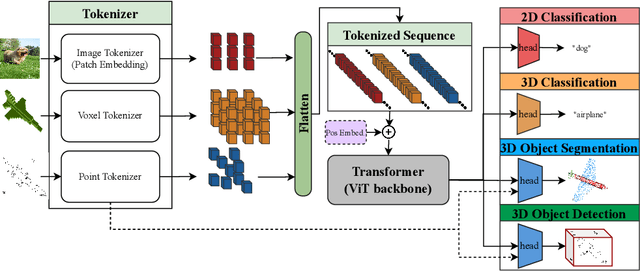

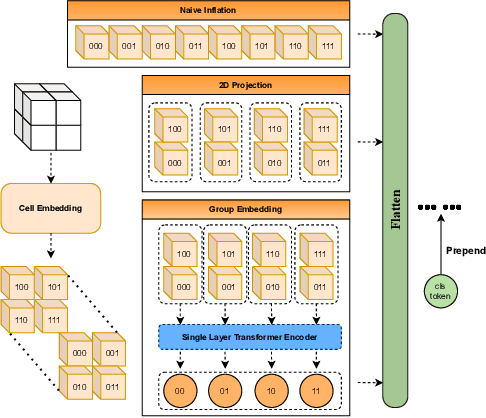
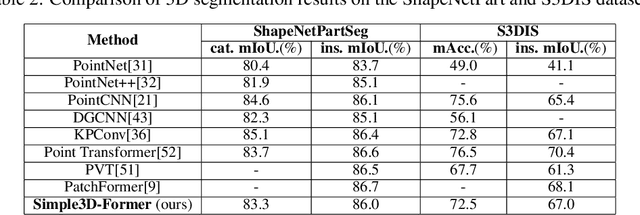
Vision Transformers (ViTs) have proven to be effective, in solving 2D image understanding tasks by training over large-scale image datasets; and meanwhile as a somehow separate track, in modeling the 3D visual world too such as voxels or point clouds. However, with the growing hope that transformers can become the "universal" modeling tool for heterogeneous data, ViTs for 2D and 3D tasks have so far adopted vastly different architecture designs that are hardly transferable. That invites an (over-)ambitious question: can we close the gap between the 2D and 3D ViT architectures? As a piloting study, this paper demonstrates the appealing promise to understand the 3D visual world, using a standard 2D ViT architecture, with only minimal customization at the input and output levels without redesigning the pipeline. To build a 3D ViT from its 2D sibling, we "inflate" the patch embedding and token sequence, accompanied with new positional encoding mechanisms designed to match the 3D data geometry. The resultant "minimalist" 3D ViT, named Simple3D-Former, performs surprisingly robustly on popular 3D tasks such as object classification, point cloud segmentation and indoor scene detection, compared to highly customized 3D-specific designs. It can hence act as a strong baseline for new 3D ViTs. Moreover, we note that pursing a unified 2D-3D ViT design has practical relevance besides just scientific curiosity. Specifically, we demonstrate that Simple3D-Former naturally enables to exploit the wealth of pre-trained weights from large-scale realistic 2D images (e.g., ImageNet), which can be plugged in to enhancing the 3D task performance "for free".
Image preprocessing and modified adaptive thresholding for improving OCR
Nov 30, 2021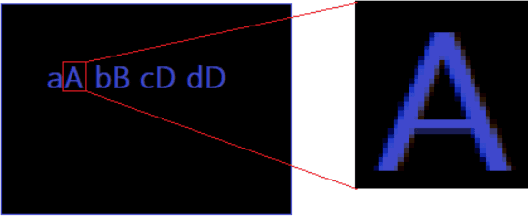


In this paper I have proposed a method to find the major pixel intensity inside the text and thresholding an image accordingly to make it easier to be used for optical character recognition (OCR) models. In our method, instead of editing whole image, I are removing all other features except the text boundaries and the color filling them. In this approach, the grayscale intensity of the letters from the input image are used as one of thresholding parameters. The performance of the developed model is finally validated with input images, with and without image processing followed by OCR by PyTesseract. Based on the results obtained, it can be observed that this algorithm can be efficiently applied in the field of image processing for OCR.
Recognition-Aware Learned Image Compression
Feb 01, 2022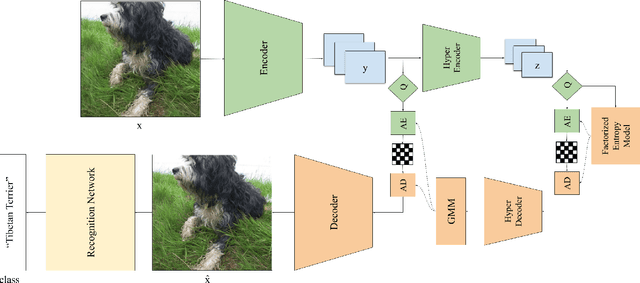
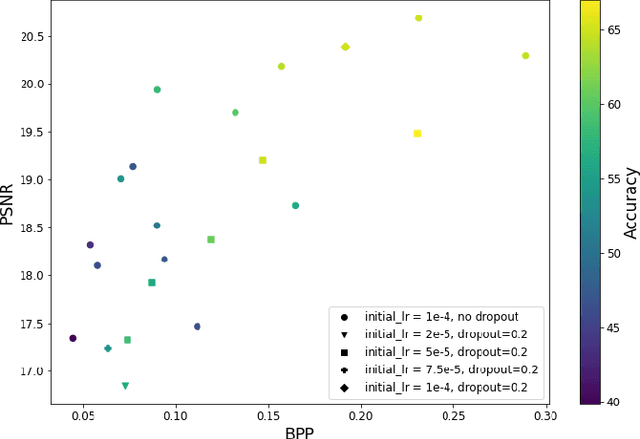

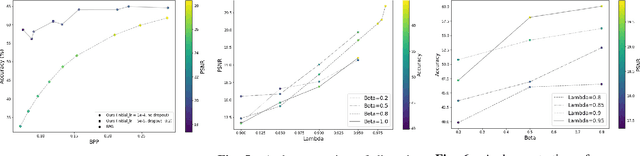
Learned image compression methods generally optimize a rate-distortion loss, trading off improvements in visual distortion for added bitrate. Increasingly, however, compressed imagery is used as an input to deep learning networks for various tasks such as classification, object detection, and superresolution. We propose a recognition-aware learned compression method, which optimizes a rate-distortion loss alongside a task-specific loss, jointly learning compression and recognition networks. We augment a hierarchical autoencoder-based compression network with an EfficientNet recognition model and use two hyperparameters to trade off between distortion, bitrate, and recognition performance. We characterize the classification accuracy of our proposed method as a function of bitrate and find that for low bitrates our method achieves as much as 26% higher recognition accuracy at equivalent bitrates compared to traditional methods such as Better Portable Graphics (BPG).
Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model
Aug 22, 2022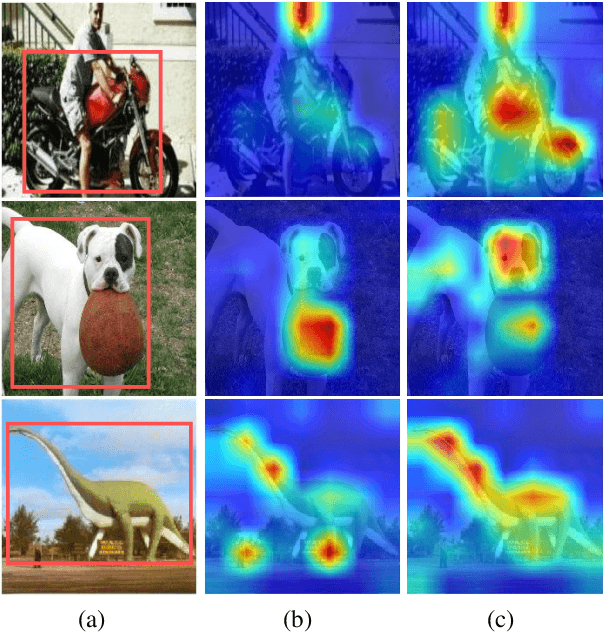
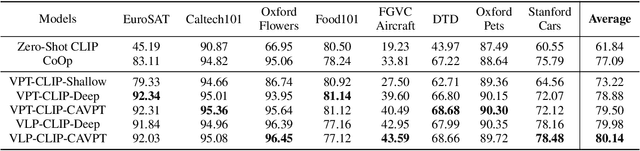
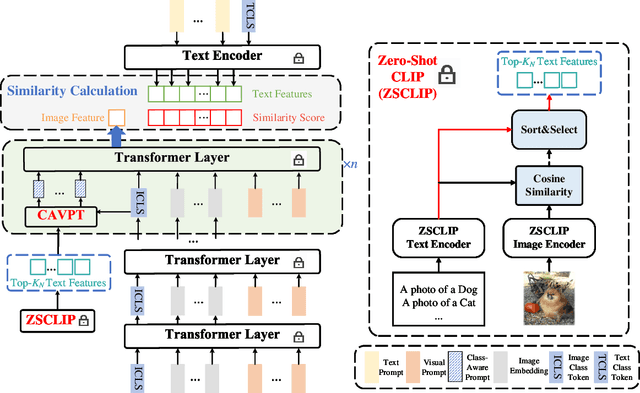

With the emergence of large pre-trained vison-language model like CLIP, transferrable representations can be adapted to a wide range of downstream tasks via prompt tuning. Prompt tuning tries to probe the beneficial information for downstream tasks from the general knowledge stored in both the image and text encoders of the pre-trained vision-language model. A recently proposed method named Context Optimization (CoOp) introduces a set of learnable vectors as text prompt from the language side, while tuning the text prompt alone can not affect the computed visual features of the image encoder, thus leading to sub-optimal. In this paper, we propose a dual modality prompt tuning paradigm through learning text prompts and visual prompts for both the text and image encoder simultaneously. In addition, to make the visual prompt concentrate more on the target visual concept, we propose Class-Aware Visual Prompt Tuning (CAVPT), which is generated dynamically by performing the cross attention between language descriptions of template prompts and visual class token embeddings. Our method provides a new paradigm for tuning the large pre-trained vision-language model and extensive experimental results on 8 datasets demonstrate the effectiveness of the proposed method. Our code is available in the supplementary materials.
Generative Category-Level Shape and Pose Estimation with Semantic Primitives
Oct 03, 2022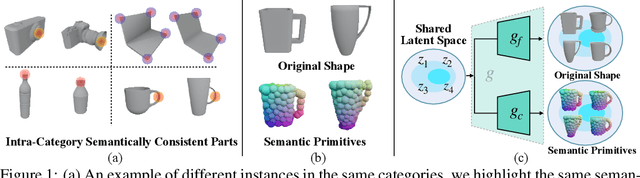
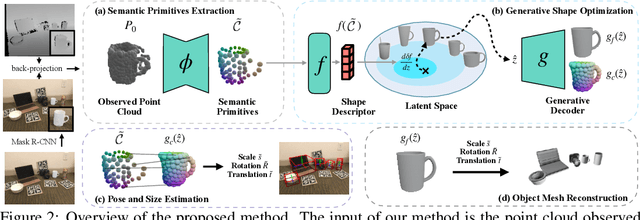
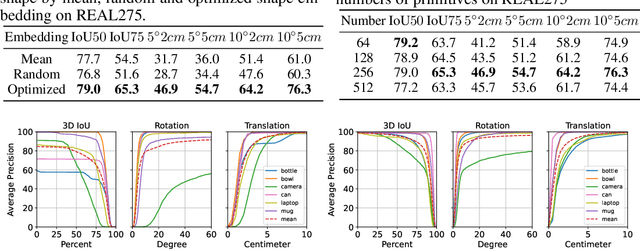

Empowering autonomous agents with 3D understanding for daily objects is a grand challenge in robotics applications. When exploring in an unknown environment, existing methods for object pose estimation are still not satisfactory due to the diversity of object shapes. In this paper, we propose a novel framework for category-level object shape and pose estimation from a single RGB-D image. To handle the intra-category variation, we adopt a semantic primitive representation that encodes diverse shapes into a unified latent space, which is the key to establish reliable correspondences between observed point clouds and estimated shapes. Then, by using a SIM(3)-invariant shape descriptor, we gracefully decouple the shape and pose of an object, thus supporting latent shape optimization of target objects in arbitrary poses. Extensive experiments show that the proposed method achieves SOTA pose estimation performance and better generalization in the real-world dataset. Code and video are available at https://zju3dv.github.io/gCasp
EraseNet: A Recurrent Residual Network for Supervised Document Cleaning
Oct 03, 2022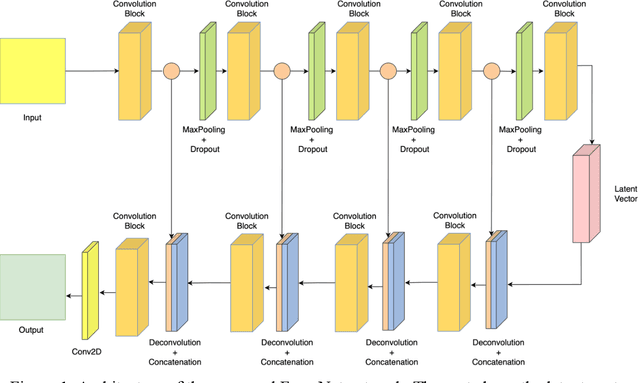
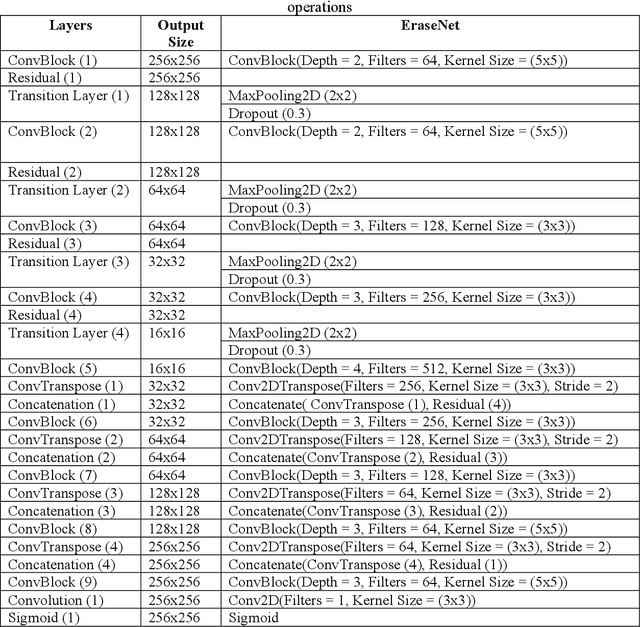
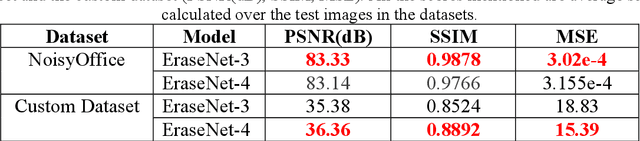
Document denoising is considered one of the most challenging tasks in computer vision. There exist millions of documents that are still to be digitized, but problems like document degradation due to natural and man-made factors make this task very difficult. This paper introduces a supervised approach for cleaning dirty documents using a new fully convolutional auto-encoder architecture. This paper focuses on restoring documents with discrepancies like deformities caused due to aging of a document, creases left on the pages that were xeroxed, random black patches, lightly visible text, etc., and also improving the quality of the image for better optical character recognition system (OCR) performance. Removing noise from scanned documents is a very important step before the documents as this noise can severely affect the performance of an OCR system. The experiments in this paper have shown promising results as the model is able to learn a variety of ordinary as well as unusual noises and rectify them efficiently.
Mastering Spatial Graph Prediction of Road Networks
Oct 03, 2022
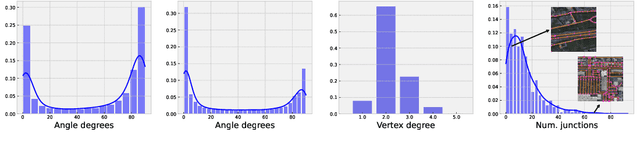
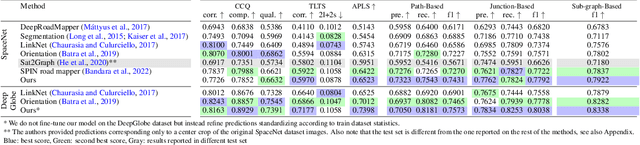
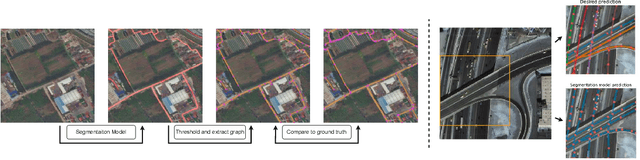
Accurately predicting road networks from satellite images requires a global understanding of the network topology. We propose to capture such high-level information by introducing a graph-based framework that simulates the addition of sequences of graph edges using a reinforcement learning (RL) approach. In particular, given a partially generated graph associated with a satellite image, an RL agent nominates modifications that maximize a cumulative reward. As opposed to standard supervised techniques that tend to be more restricted to commonly used surrogate losses, these rewards can be based on various complex, potentially non-continuous, metrics of interest. This yields more power and flexibility to encode problem-dependent knowledge. Empirical results on several benchmark datasets demonstrate enhanced performance and increased high-level reasoning about the graph topology when using a tree-based search. We further highlight the superiority of our approach under substantial occlusions by introducing a new synthetic benchmark dataset for this task.
Privacy-Preserving Feature Coding for Machines
Oct 03, 2022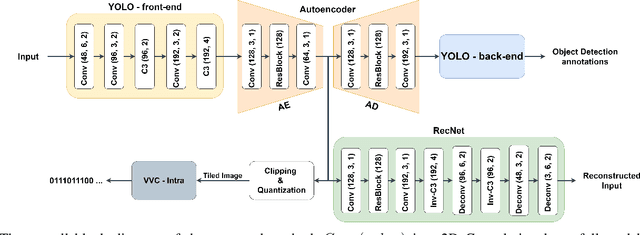
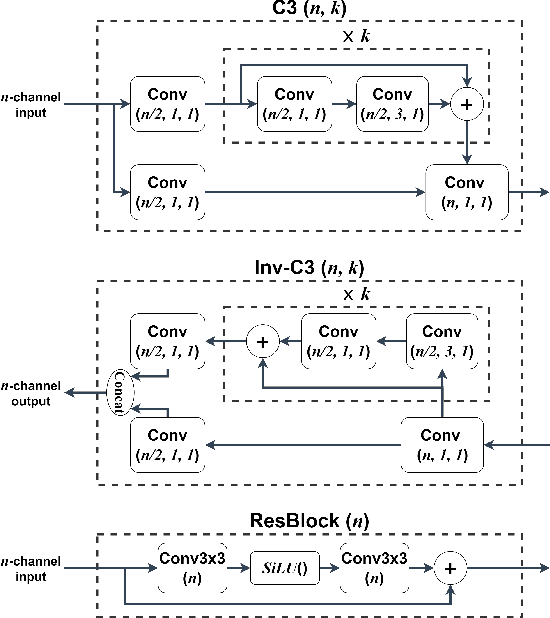

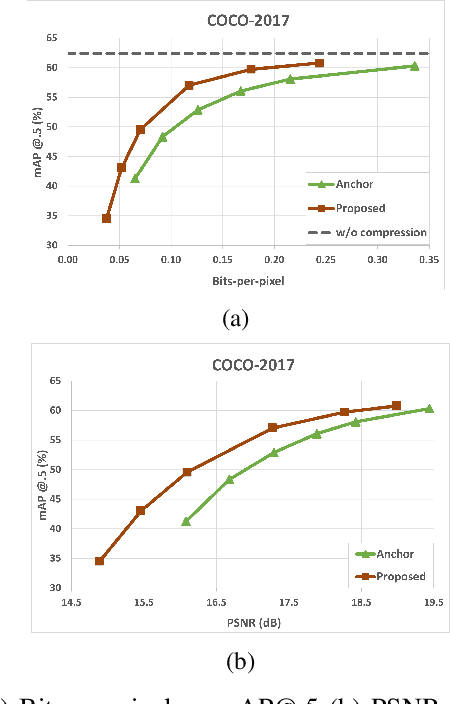
Automated machine vision pipelines do not need the exact visual content to perform their tasks. Therefore, there is a potential to remove private information from the data without significantly affecting the machine vision accuracy. We present a novel method to create a privacy-preserving latent representation of an image that could be used by a downstream machine vision model. This latent representation is constructed using adversarial training to prevent accurate reconstruction of the input while preserving the task accuracy. Specifically, we split a Deep Neural Network (DNN) model and insert an autoencoder whose purpose is to both reduce the dimensionality as well as remove information relevant to input reconstruction while minimizing the impact on task accuracy. Our results show that input reconstruction ability can be reduced by about 0.8 dB at the equivalent task accuracy, with degradation concentrated near the edges, which is important for privacy. At the same time, 30% bit savings are achieved compared to coding the features directly.
Can you recommend content to creatives instead of final consumers? A RecSys based on user's preferred visual styles
Aug 23, 2022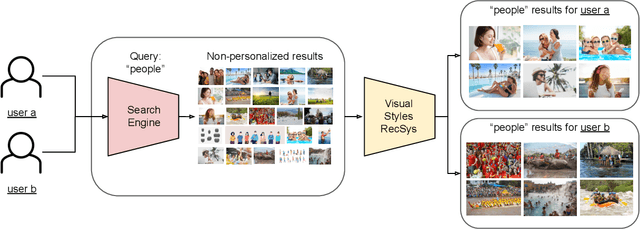


Providing meaningful recommendations in a content marketplace is challenging due to the fact that users are not the final content consumers. Instead, most users are creatives whose interests, linked to the projects they work on, change rapidly and abruptly. To address the challenging task of recommending images to content creators, we design a RecSys that learns visual styles preferences transversal to the semantics of the projects users work on. We analyze the challenges of the task compared to content-based recommendations driven by semantics, propose an evaluation setup, and explain its applications in a global image marketplace. This technical report is an extension of the paper "Learning Users' Preferred Visual Styles in an Image Marketplace", presented at ACM RecSys '22.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021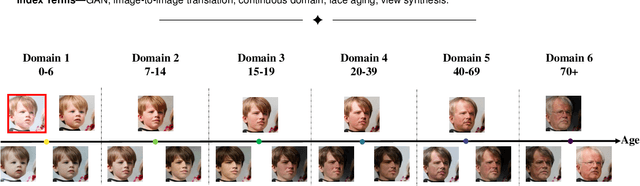

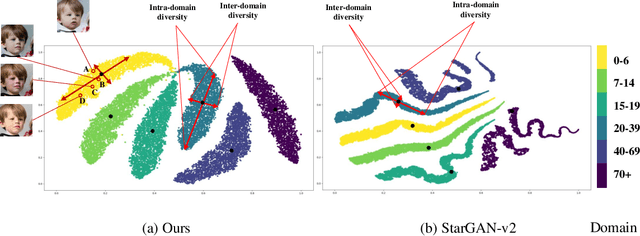
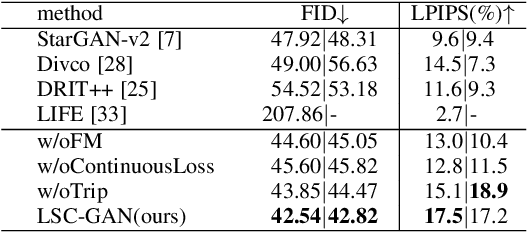
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.