 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025



A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
EraseNet: A Recurrent Residual Network for Supervised Document Cleaning
Oct 03, 2022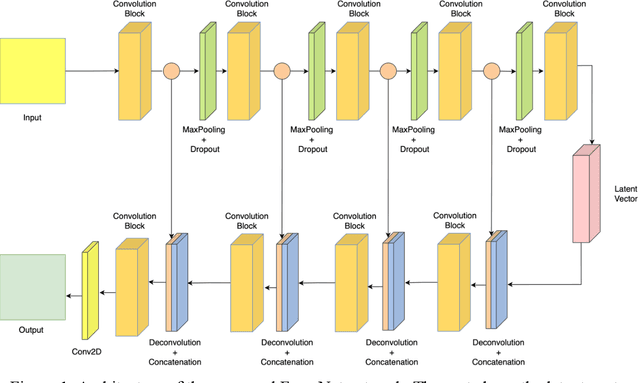
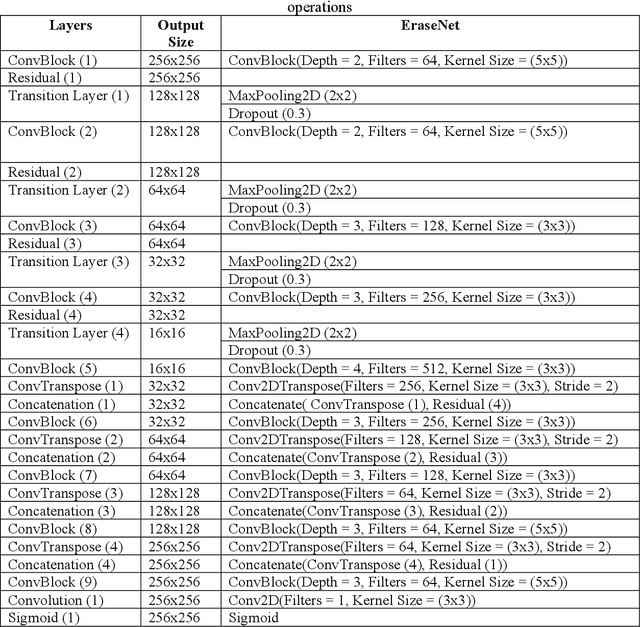
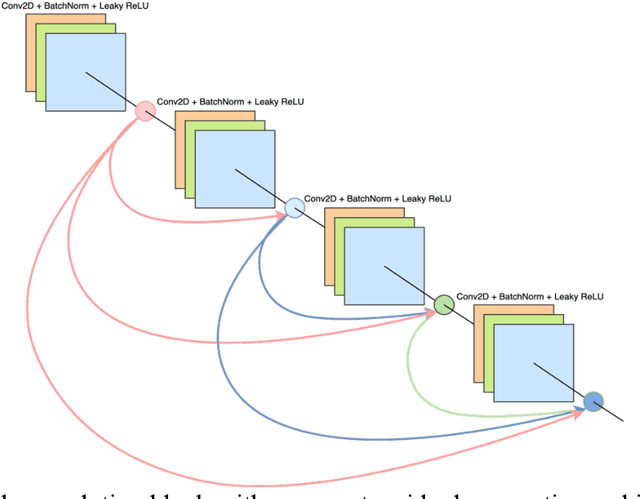
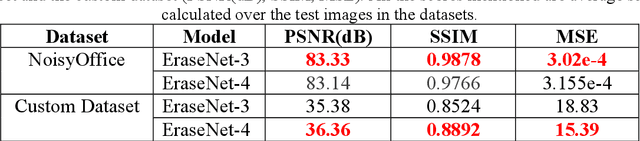
Document denoising is considered one of the most challenging tasks in computer vision. There exist millions of documents that are still to be digitized, but problems like document degradation due to natural and man-made factors make this task very difficult. This paper introduces a supervised approach for cleaning dirty documents using a new fully convolutional auto-encoder architecture. This paper focuses on restoring documents with discrepancies like deformities caused due to aging of a document, creases left on the pages that were xeroxed, random black patches, lightly visible text, etc., and also improving the quality of the image for better optical character recognition system (OCR) performance. Removing noise from scanned documents is a very important step before the documents as this noise can severely affect the performance of an OCR system. The experiments in this paper have shown promising results as the model is able to learn a variety of ordinary as well as unusual noises and rectify them efficiently.