 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
There is a Time and Place for Reasoning Beyond the Image
Mar 28, 2022

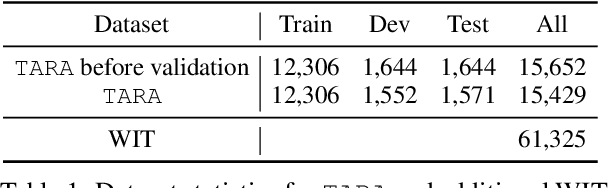

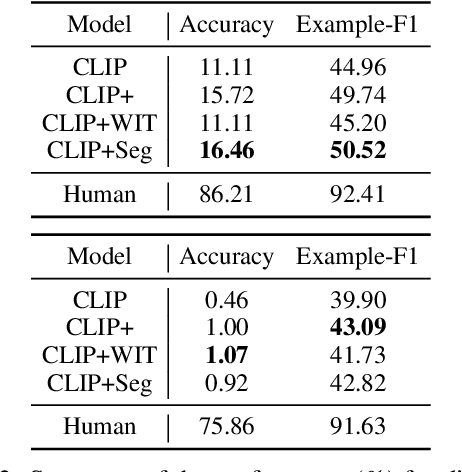
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings of the signs, the buildings, the crowds, and more. This reasoning could provide the time and place the image was taken, which will help us in subsequent tasks, such as automatic storyline construction, correction of image source in intended effect photographs, and upper-stream processing such as image clustering for certain location or time. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time, and location, automatically extracted from New York Times, and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which we believe it is possible to find the images' spatio-temporal information for evaluation purpose. We show that there exists a $70\%$ gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge. The data and code are publicly available at https://github.com/zeyofu/TARA.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022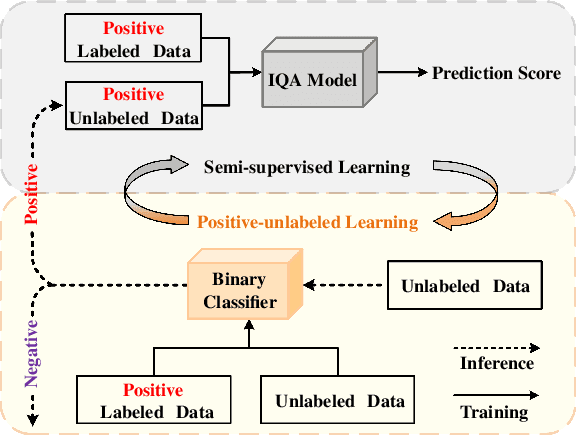
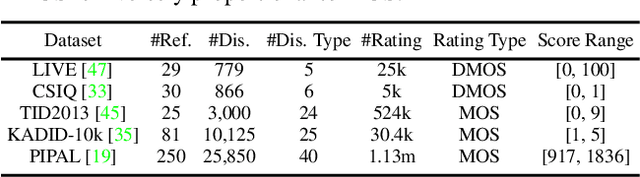
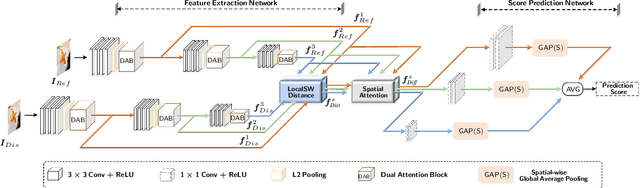
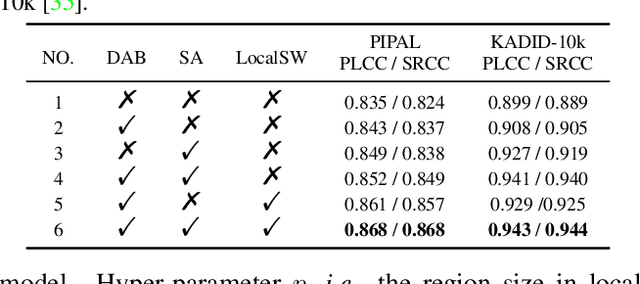
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.
Detecting Network-based Internet Censorship via Latent Feature Representation Learning
Sep 12, 2022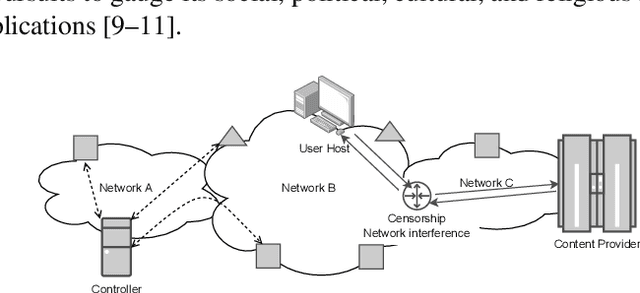

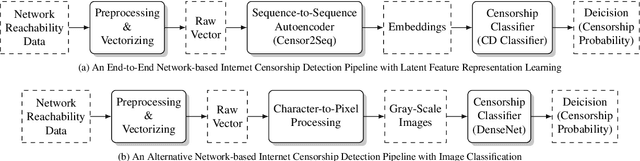

Internet censorship is a phenomenon of societal importance and attracts investigation from multiple disciplines. Several research groups, such as Censored Planet, have deployed large scale Internet measurement platforms to collect network reachability data. However, existing studies generally rely on manually designed rules (i.e., using censorship fingerprints) to detect network-based Internet censorship from the data. While this rule-based approach yields a high true positive detection rate, it suffers from several challenges: it requires human expertise, is laborious, and cannot detect any censorship not captured by the rules. Seeking to overcome these challenges, we design and evaluate a classification model based on latent feature representation learning and an image-based classification model to detect network-based Internet censorship. To infer latent feature representations from network reachability data, we propose a sequence-to-sequence autoencoder to capture the structure and the order of data elements in the data. To estimate the probability of censorship events from the inferred latent features, we rely on a densely connected multi-layer neural network model. Our image-based classification model encodes a network reachability data record as a gray-scale image and classifies the image as censored or not using a dense convolutional neural network. We compare and evaluate both approaches using data sets from Censored Planet via a hold-out evaluation. Both classification models are capable of detecting network-based Internet censorship as we were able to identify instances of censorship not detected by the known fingerprints. Latent feature representations likely encode more nuances in the data since the latent feature learning approach discovers a greater quantity, and a more diverse set, of new censorship instances.
A Neural Template Matching Method to Detect Knee Joint Areas
Sep 23, 2022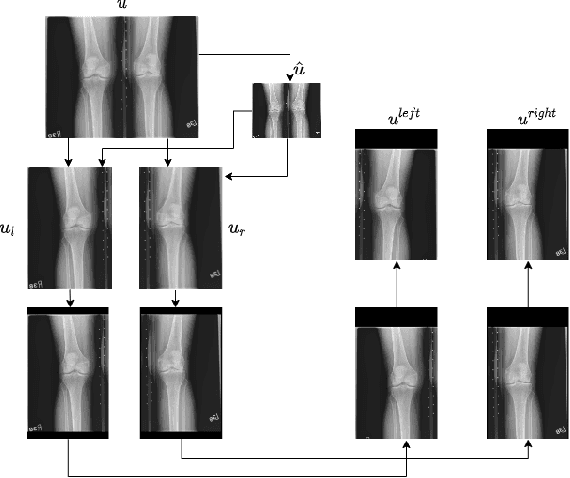
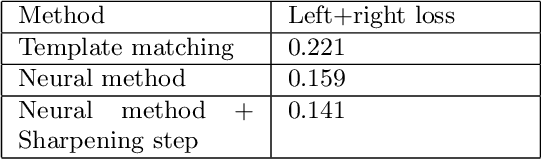
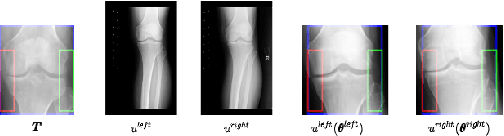
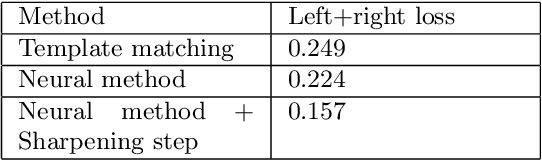
In this paper, new methods are considered to detect knee joint areas in bilateral PA fixed flexion knee X-ray images. The methods are of template matching type where the distance criterion is based on the negative normalized cross-correlation. The manual annotations are made on only one side of a single bilateral image when the templates are selected. The best matching patch search is formulated as an unconstrained continuous domain minimization problem. For the minimization problem different optimization methods are considered. The main method of the paper is a trainable optimizer where the method is taught to take zoomed and possibly rotated patches from its input images which look like the template. In the experiments, we compare the minimum values found by different optimization methods. We also look at some test images to examine the correspondence between the minimum value and how well the knee area is localized. It seems that making annotations only to a single image enables to detect knee joint areas quite precisely.
Explainable Deep Learning to Profile Mitochondrial Disease Using High Dimensional Protein Expression Data
Oct 31, 2022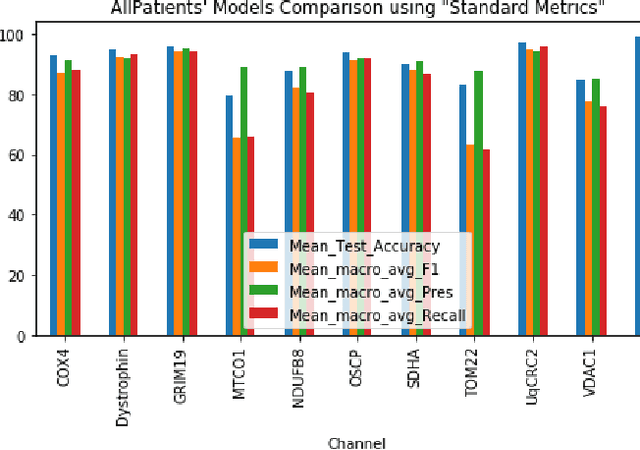
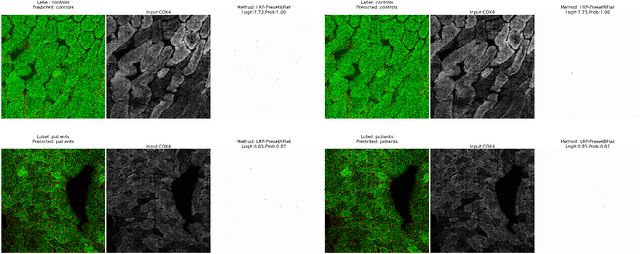
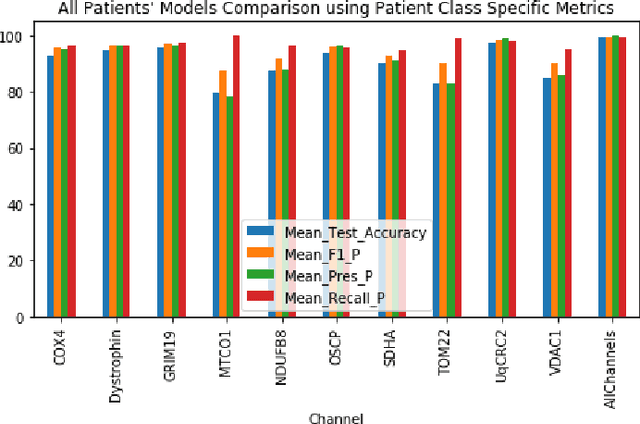

Mitochondrial diseases are currently untreatable due to our limited understanding of their pathology. We study the expression of various mitochondrial proteins in skeletal myofibres (SM) in order to discover processes involved in mitochondrial pathology using Imaging Mass Cytometry (IMC). IMC produces high dimensional multichannel pseudo-images representing spatial variation in the expression of a panel of proteins within a tissue, including subcellular variation. Statistical analysis of these images requires semi-automated annotation of thousands of SMs in IMC images of patient muscle biopsies. In this paper we investigate the use of deep learning (DL) on raw IMC data to analyse it without any manual pre-processing steps, statistical summaries or statistical models. For this we first train state-of-art computer vision DL models on all available image channels, both combined and individually. We observed better than expected accuracy for many of these models. We then apply state-of-the-art explainable techniques relevant to computer vision DL to find the basis of the predictions of these models. Some of the resulting visual explainable maps highlight features in the images that appear consistent with the latest hypotheses about mitochondrial disease progression within myofibres.
Semantic-Aware Latent Space Exploration for Face Image Restoration
Mar 06, 2022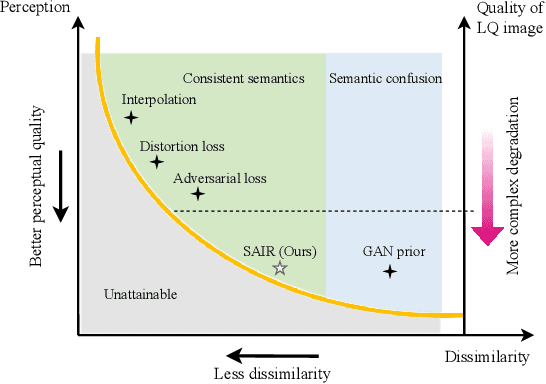
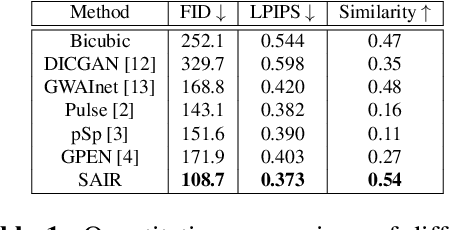
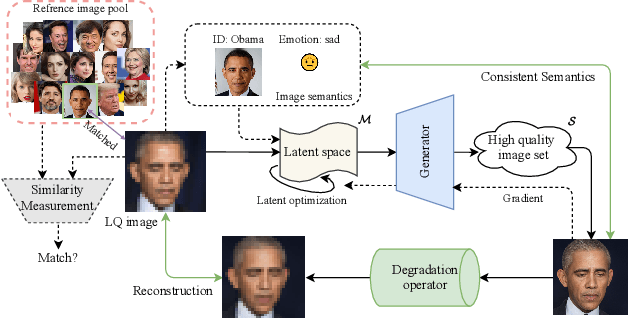
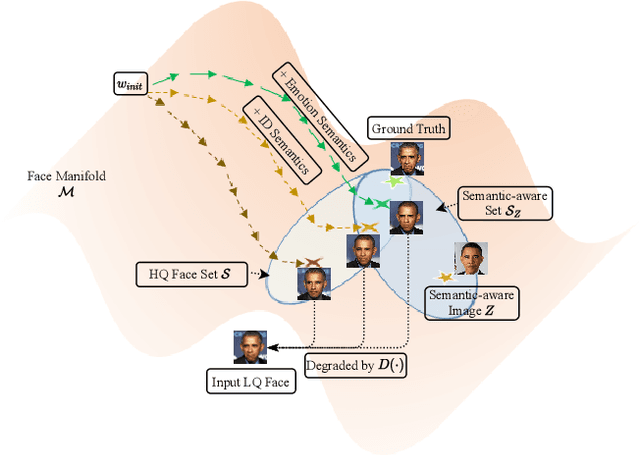
For image restoration, most existing deep learning based methods tend to overfit the training data leading to bad results when encountering unseen degradations out of the assumptions for training. To improve the robustness, generative adversarial network (GAN) prior based methods have been proposed, revealing a promising capability to restore photo-realistic and high-quality results. But these methods suffer from semantic confusion, especially on semantically significant images such as face images. In this paper, we propose a semantic-aware latent space exploration method for image restoration (SAIR). By explicitly modeling referenced semantics information, SAIR can consistently restore severely degraded images not only to high-resolution highly-realistic looks but also to correct semantics. Quantitative and qualitative experiments collectively demonstrate the effectiveness of the proposed SAIR. Our code can be found in https://github.com/Liamkuo/SAIR.
Model-Guided Multi-Contrast Deep Unfolding Network for MRI Super-resolution Reconstruction
Sep 15, 2022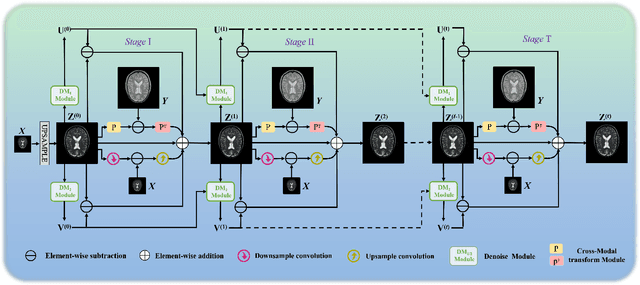
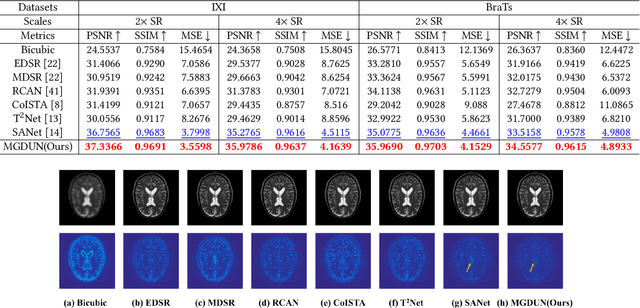
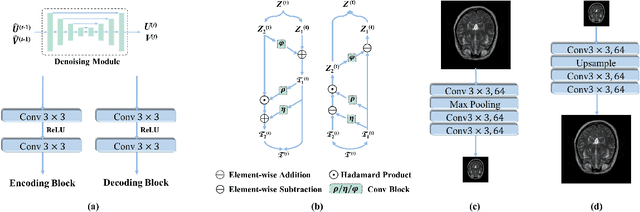
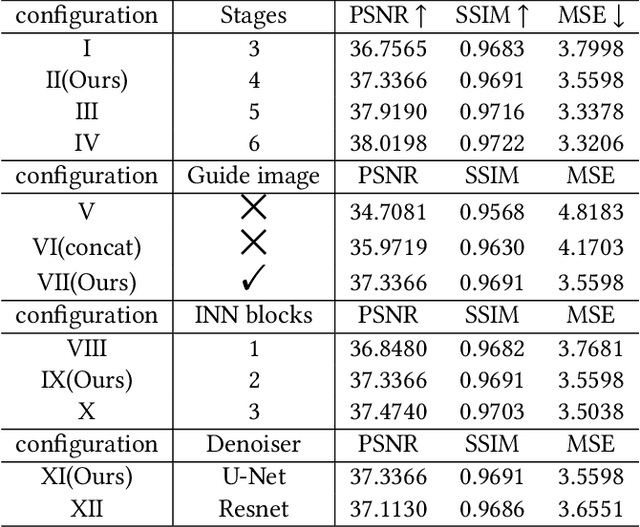
Magnetic resonance imaging (MRI) with high resolution (HR) provides more detailed information for accurate diagnosis and quantitative image analysis. Despite the significant advances, most existing super-resolution (SR) reconstruction network for medical images has two flaws: 1) All of them are designed in a black-box principle, thus lacking sufficient interpretability and further limiting their practical applications. Interpretable neural network models are of significant interest since they enhance the trustworthiness required in clinical practice when dealing with medical images. 2) most existing SR reconstruction approaches only use a single contrast or use a simple multi-contrast fusion mechanism, neglecting the complex relationships between different contrasts that are critical for SR improvement. To deal with these issues, in this paper, a novel Model-Guided interpretable Deep Unfolding Network (MGDUN) for medical image SR reconstruction is proposed. The Model-Guided image SR reconstruction approach solves manually designed objective functions to reconstruct HR MRI. We show how to unfold an iterative MGDUN algorithm into a novel model-guided deep unfolding network by taking the MRI observation matrix and explicit multi-contrast relationship matrix into account during the end-to-end optimization. Extensive experiments on the multi-contrast IXI dataset and BraTs 2019 dataset demonstrate the superiority of our proposed model.
GHM Wavelet Transform for Deep Image Super Resolution
Apr 16, 2022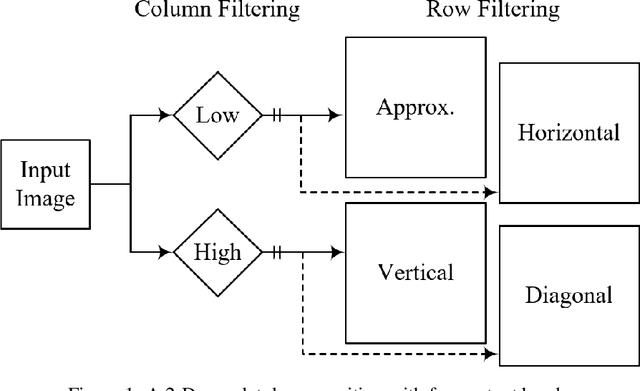
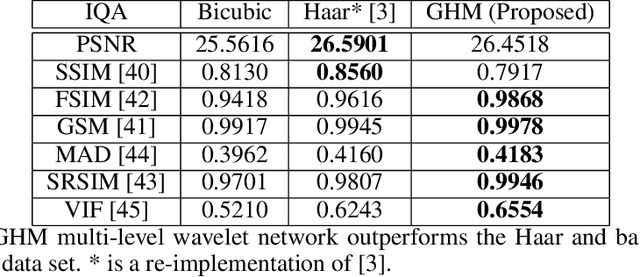
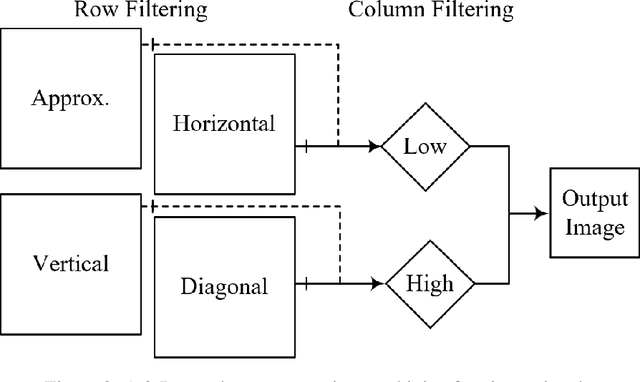
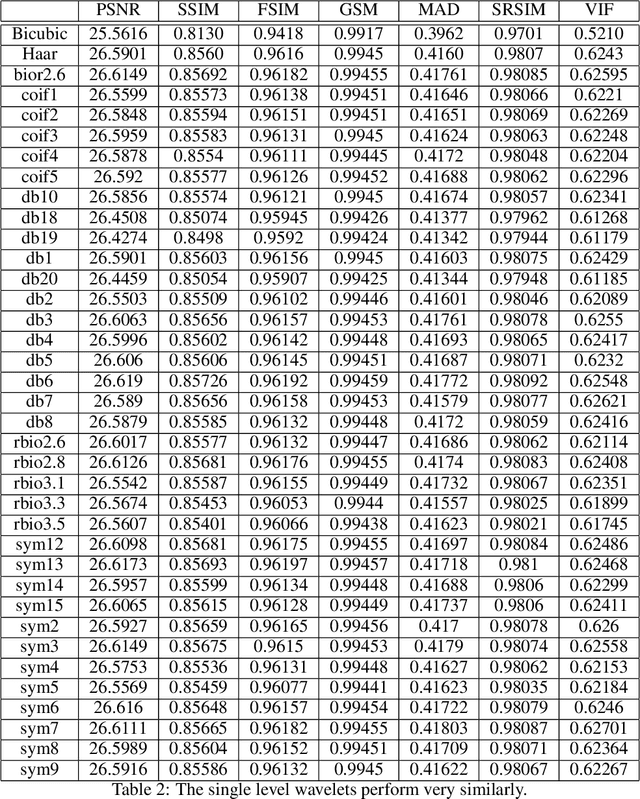
The GHM multi-level discrete wavelet transform is proposed as preprocessing for image super resolution with convolutional neural networks. Previous works perform analysis with the Haar wavelet only. In this work, 37 single-level wavelets are experimentally analyzed from Haar, Daubechies, Biorthogonal, Reverse Biorthogonal, Coiflets, and Symlets wavelet families. All single-level wavelets report similar results indicating that the convolutional neural network is invariant to choice of wavelet in a single-level filter approach. However, the GHM multi-level wavelet achieves higher quality reconstructions than the single-level wavelets. Three large data sets are used for the experiments: DIV2K, a dataset of textures, and a dataset of satellite images. The approximate high resolution images are compared using seven objective error measurements. A convolutional neural network based approach using wavelet transformed images has good results in the literature.
EDeNN: Event Decay Neural Networks for low latency vision
Sep 09, 2022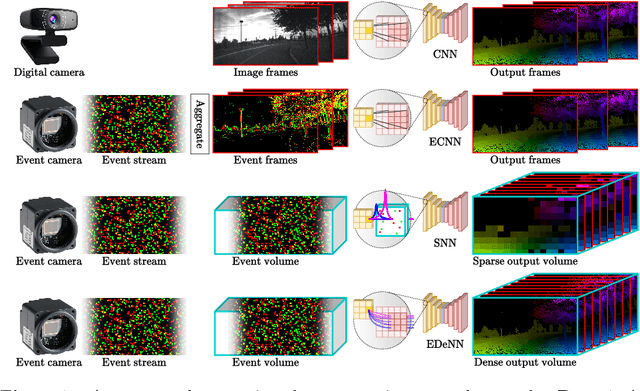

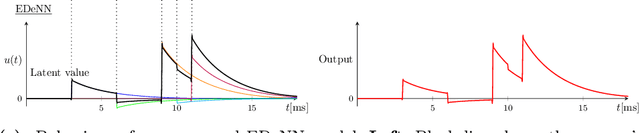
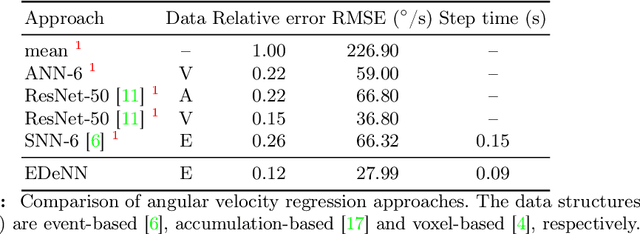
Despite the success of neural networks in computer vision tasks, digital 'neurons' are a very loose approximation of biological neurons. Today's learning approaches are designed to function on digital devices with digital data representations such as image frames. In contrast, biological vision systems are generally much more capable and efficient than state-of-the-art digital computer vision algorithms. Event cameras are an emerging sensor technology which imitates biological vision with asynchronously firing pixels, eschewing the concept of the image frame. To leverage modern learning techniques, many event-based algorithms are forced to accumulate events back to image frames, somewhat squandering the advantages of event cameras. We follow the opposite paradigm and develop a new type of neural network which operates closer to the original event data stream. We demonstrate state-of-the-art performance in angular velocity regression and competitive optical flow estimation, while avoiding difficulties related to training SNN. Furthermore, the processing latency of our proposed approached is less than 1/10 any other implementation, while continuous inference increases this improvement by another order of magnitude.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022
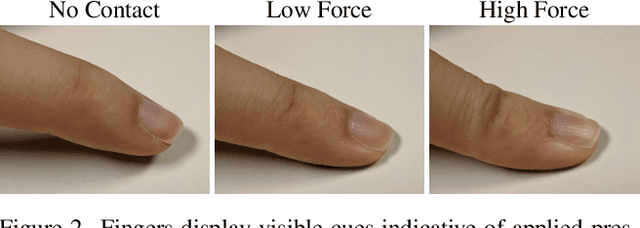
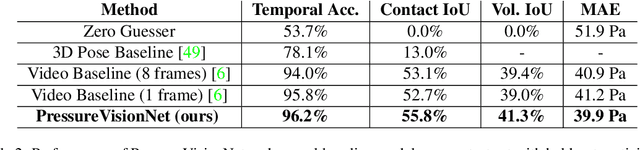
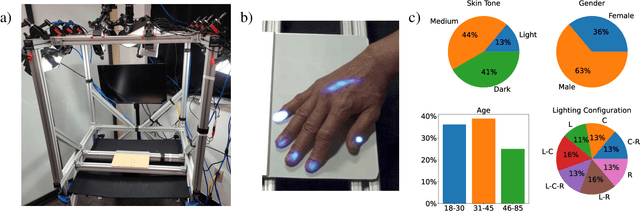
People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.