 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GLFF: Global and Local Feature Fusion for Face Forgery Detection
Nov 26, 2022
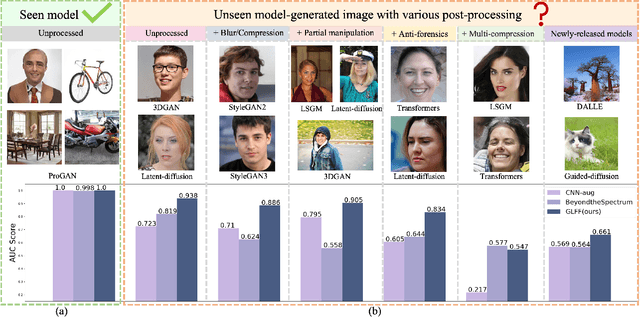
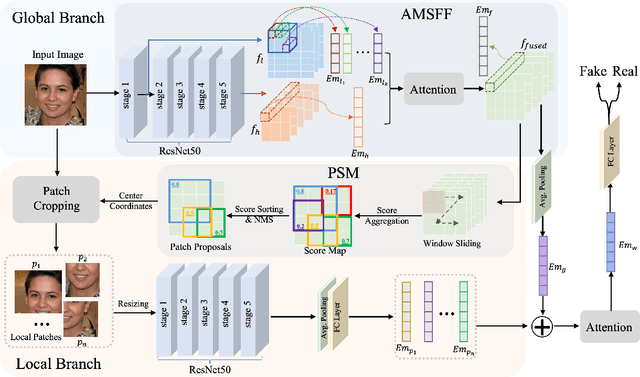
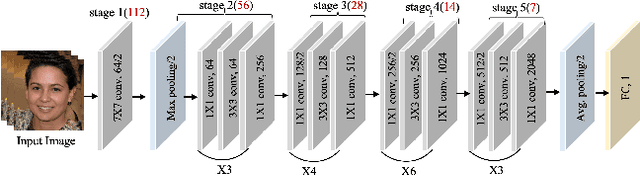

With the rapid development of deep generative models (such as Generative Adversarial Networks and Auto-encoders), AI-synthesized images of the human face are now of such high quality that humans can hardly distinguish them from pristine ones. Although existing detection methods have shown high performance in specific evaluation settings, e.g., on images from seen models or on images without real-world post-processings, they tend to suffer serious performance degradation in real-world scenarios where testing images can be generated by more powerful generation models or combined with various post-processing operations. To address this issue, we propose a Global and Local Feature Fusion (GLFF) to learn rich and discriminative representations by combining multi-scale global features from the whole image with refined local features from informative patches for face forgery detection. GLFF fuses information from two branches: the global branch to extract multi-scale semantic features and the local branch to select informative patches for detailed local artifacts extraction. Due to the lack of a face forgery dataset simulating real-world applications for evaluation, we further create a challenging face forgery dataset, named DeepFakeFaceForensics (DF^3), which contains 6 state-of-the-art generation models and a variety of post-processing techniques to approach the real-world scenarios. Experimental results demonstrate the superiority of our method to the state-of-the-art methods on the proposed DF^3 dataset and three other open-source datasets.
The Impact of Racial Distribution in Training Data on Face Recognition Bias: A Closer Look
Nov 26, 2022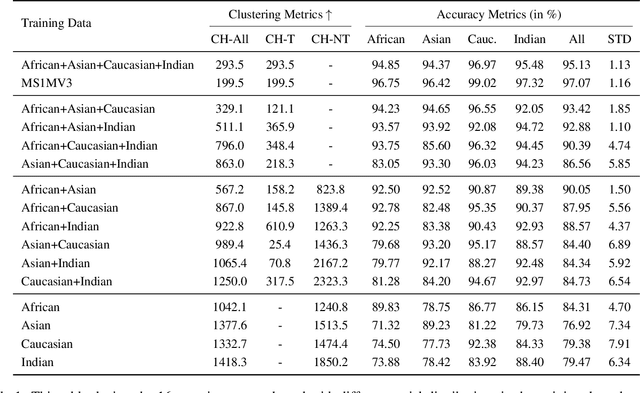
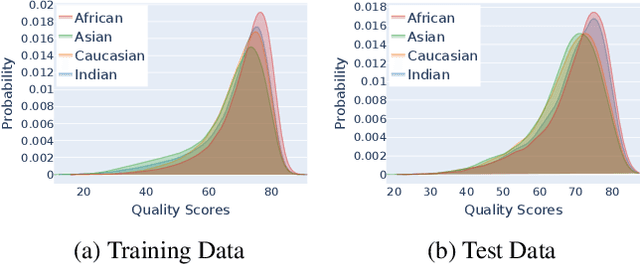
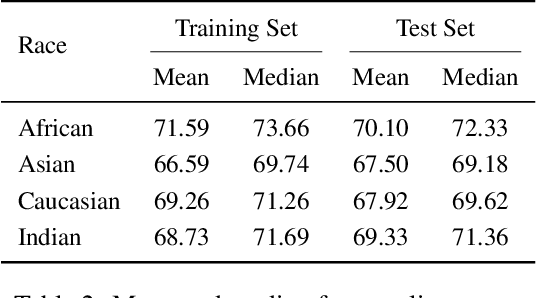
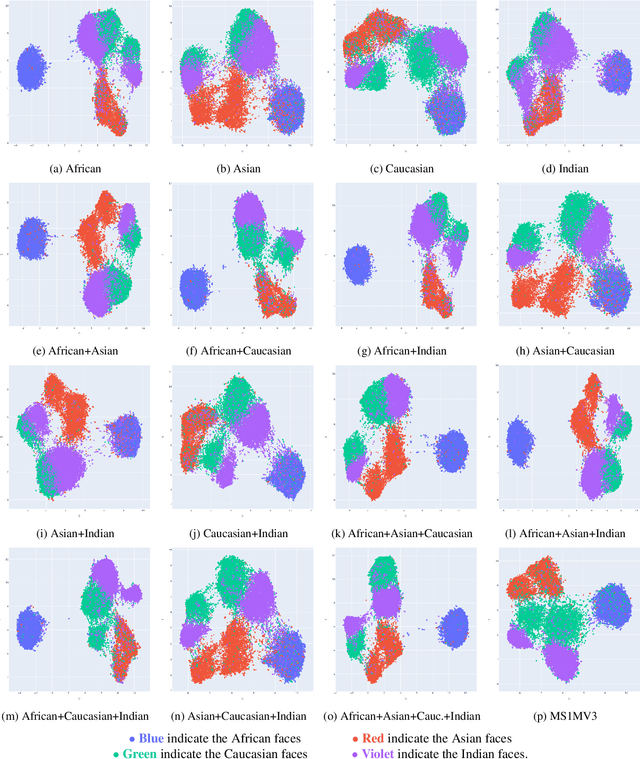
Face recognition algorithms, when used in the real world, can be very useful, but they can also be dangerous when biased toward certain demographics. So, it is essential to understand how these algorithms are trained and what factors affect their accuracy and fairness to build better ones. In this study, we shed some light on the effect of racial distribution in the training data on the performance of face recognition models. We conduct 16 different experiments with varying racial distributions of faces in the training data. We analyze these trained models using accuracy metrics, clustering metrics, UMAP projections, face quality, and decision thresholds. We show that a uniform distribution of races in the training datasets alone does not guarantee bias-free face recognition algorithms and how factors like face image quality play a crucial role. We also study the correlation between the clustering metrics and bias to understand whether clustering is a good indicator of bias. Finally, we introduce a metric called racial gradation to study the inter and intra race correlation in facial features and how they affect the learning ability of the face recognition models. With this study, we try to bring more understanding to an essential element of face recognition training, the data. A better understanding of the impact of training data on the bias of face recognition algorithms will aid in creating better datasets and, in turn, better face recognition systems.
Memory-augmented Deep Unfolding Network for Guided Image Super-resolution
Feb 12, 2022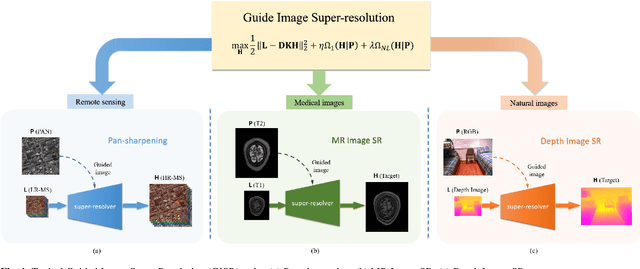
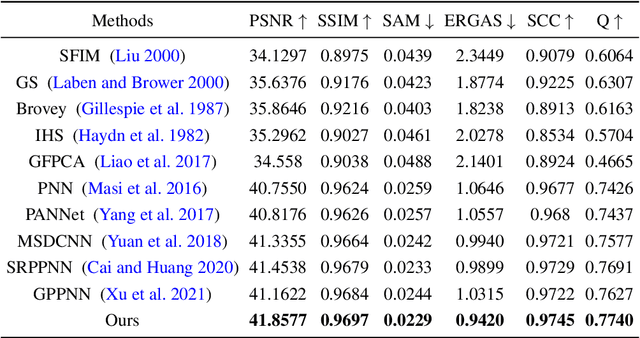
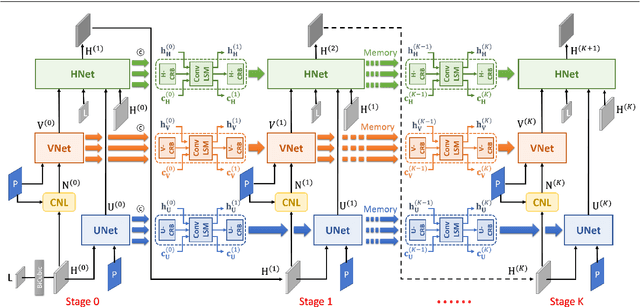
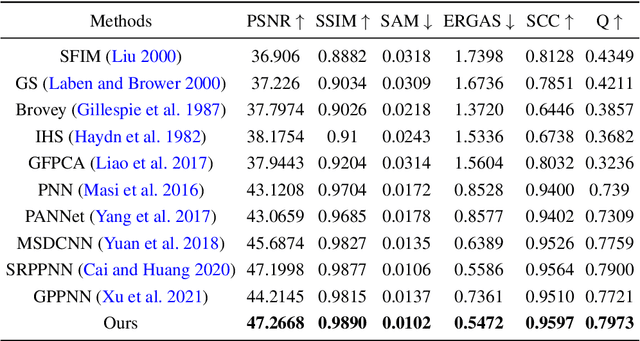
Guided image super-resolution (GISR) aims to obtain a high-resolution (HR) target image by enhancing the spatial resolution of a low-resolution (LR) target image under the guidance of a HR image. However, previous model-based methods mainly takes the entire image as a whole, and assume the prior distribution between the HR target image and the HR guidance image, simply ignoring many non-local common characteristics between them. To alleviate this issue, we firstly propose a maximal a posterior (MAP) estimation model for GISR with two types of prior on the HR target image, i.e., local implicit prior and global implicit prior. The local implicit prior aims to model the complex relationship between the HR target image and the HR guidance image from a local perspective, and the global implicit prior considers the non-local auto-regression property between the two images from a global perspective. Secondly, we design a novel alternating optimization algorithm to solve this model for GISR. The algorithm is in a concise framework that facilitates to be replicated into commonly used deep network structures. Thirdly, to reduce the information loss across iterative stages, the persistent memory mechanism is introduced to augment the information representation by exploiting the Long short-term memory unit (LSTM) in the image and feature spaces. In this way, a deep network with certain interpretation and high representation ability is built. Extensive experimental results validate the superiority of our method on a variety of GISR tasks, including Pan-sharpening, depth image super-resolution, and MR image super-resolution.
SketchySGD: Reliable Stochastic Optimization via Robust Curvature Estimates
Nov 16, 2022
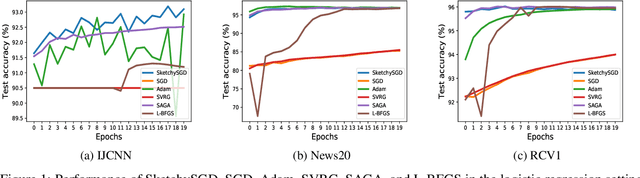
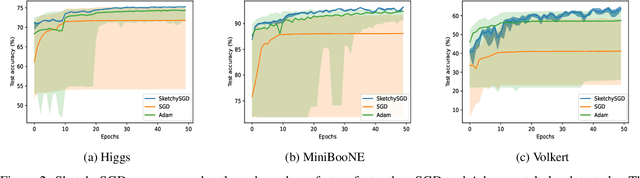
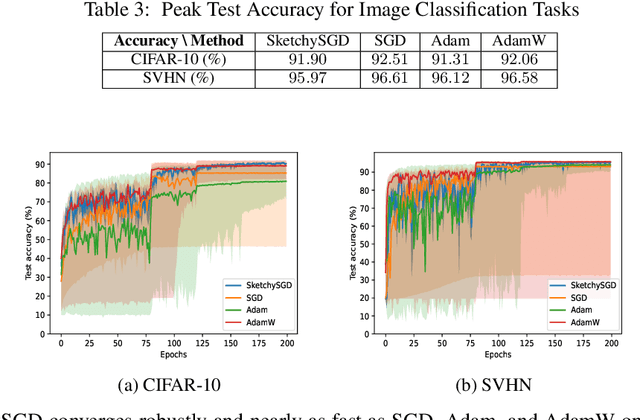
We introduce SketchySGD, a stochastic quasi-Newton method that uses sketching to approximate the curvature of the loss function. Quasi-Newton methods are among the most effective algorithms in traditional optimization, where they converge much faster than first-order methods such as SGD. However, for contemporary deep learning, quasi-Newton methods are considered inferior to first-order methods like SGD and Adam owing to higher per-iteration complexity and fragility due to inexact gradients. SketchySGD circumvents these issues by a novel combination of subsampling, randomized low-rank approximation, and dynamic regularization. In the convex case, we show SketchySGD with a fixed stepsize converges to a small ball around the optimum at a faster rate than SGD. In the non-convex case, SketchySGD converges linearly under two additional assumptions, interpolation and the Polyak-Lojaciewicz condition, the latter of which holds with high probability for wide neural networks. Numerical experiments on image and tabular data demonstrate the improved reliability and speed of SketchySGD for deep learning, compared to standard optimizers such as SGD and Adam and existing quasi-Newton methods.
Camera simulation for robot simulation: how important are various camera model components?
Nov 16, 2022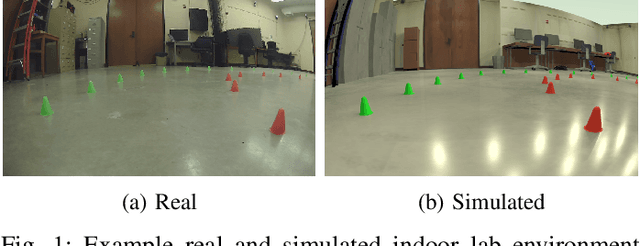



Modeling cameras for the simulation of autonomous robotics is critical for generating synthetic images with appropriate realism to effectively evaluate a perception algorithm in simulation. In many cases though, simulated images are produced by traditional rendering techniques that exclude or superficially handle processing steps and aspects encountered in the actual camera pipeline. The purpose of this contribution is to quantify the degree to which the exclusion from the camera model of various image generation steps or aspects affect the sim-to-real gap in robotics. We investigate what happens if one ignores aspects tied to processes from within the physical camera, e.g., lens distortion, noise, and signal processing; scene effects, e.g., lighting and reflection; and rendering quality. The results of the study demonstrate, quantitatively, that large-scale changes to color, scene, and location have far greater impact than model aspects concerned with local, feature-level artifacts. Moreover, we show that these scene-level aspects can stem from lens distortion and signal processing, particularly when considering white-balance and auto-exposure modeling.
Unsupervised Domain Adaptation Based on the Predictive Uncertainty of Models
Nov 16, 2022
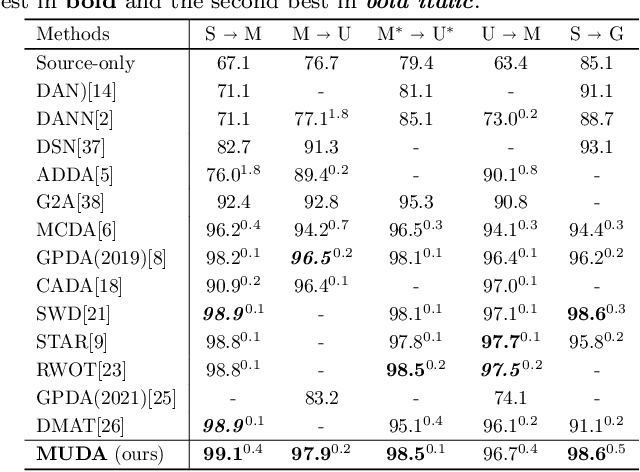

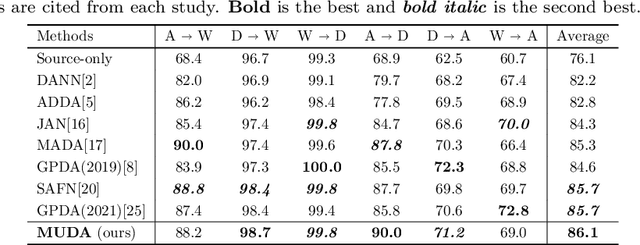
Unsupervised domain adaptation (UDA) aims to improve the prediction performance in the target domain under distribution shifts from the source domain. The key principle of UDA is to minimize the divergence between the source and the target domains. To follow this principle, many methods employ a domain discriminator to match the feature distributions. Some recent methods evaluate the discrepancy between two predictions on target samples to detect those that deviate from the source distribution. However, their performance is limited because they either match the marginal distributions or measure the divergence conservatively. In this paper, we present a novel UDA method that learns domain-invariant features that minimize the domain divergence. We propose model uncertainty as a measure of the domain divergence. Our UDA method based on model uncertainty (MUDA) adopts a Bayesian framework and provides an efficient way to evaluate model uncertainty by means of Monte Carlo dropout sampling. Empirical results on image recognition tasks show that our method is superior to existing state-of-the-art methods. We also extend MUDA to multi-source domain adaptation problems.
AlignVE: Visual Entailment Recognition Based on Alignment Relations
Nov 16, 2022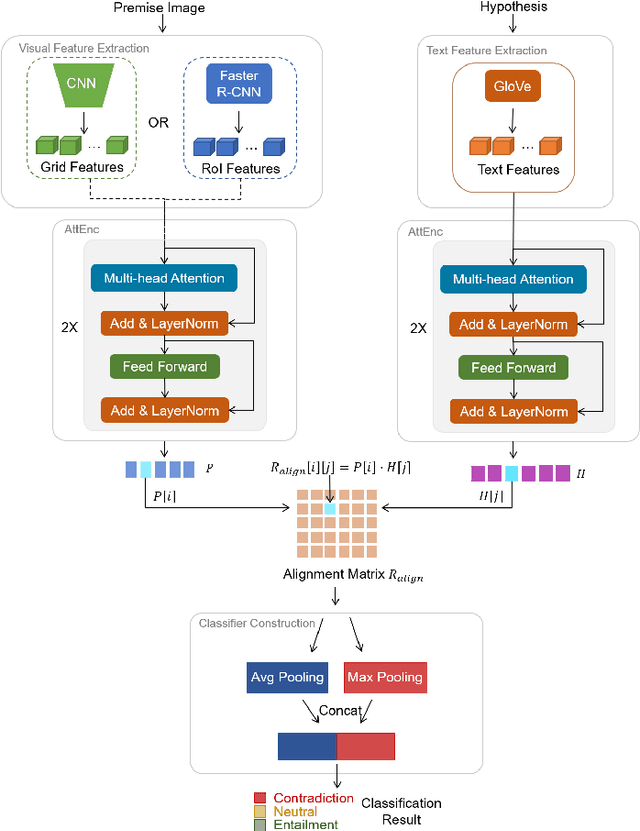
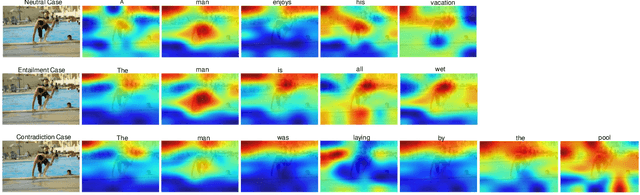


Visual entailment (VE) is to recognize whether the semantics of a hypothesis text can be inferred from the given premise image, which is one special task among recent emerged vision and language understanding tasks. Currently, most of the existing VE approaches are derived from the methods of visual question answering. They recognize visual entailment by quantifying the similarity between the hypothesis and premise in the content semantic features from multi modalities. Such approaches, however, ignore the VE's unique nature of relation inference between the premise and hypothesis. Therefore, in this paper, a new architecture called AlignVE is proposed to solve the visual entailment problem with a relation interaction method. It models the relation between the premise and hypothesis as an alignment matrix. Then it introduces a pooling operation to get feature vectors with a fixed size. Finally, it goes through the fully-connected layer and normalization layer to complete the classification. Experiments show that our alignment-based architecture reaches 72.45\% accuracy on SNLI-VE dataset, outperforming previous content-based models under the same settings.
Revisiting Document Image Dewarping by Grid Regularization
Mar 31, 2022

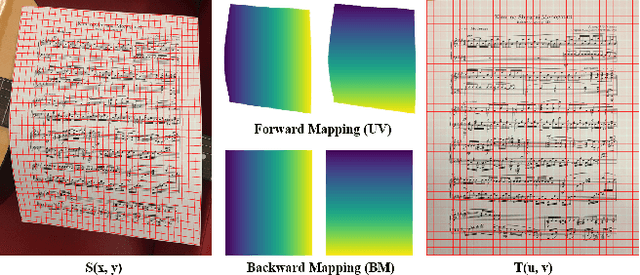
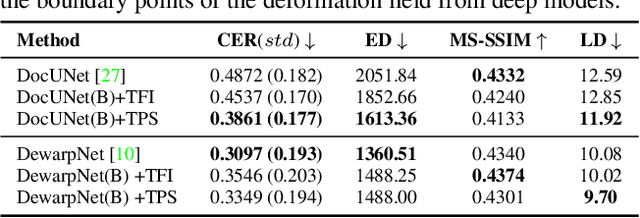
This paper addresses the problem of document image dewarping, which aims at eliminating the geometric distortion in document images for document digitization. Instead of designing a better neural network to approximate the optical flow fields between the inputs and outputs, we pursue the best readability by taking the text lines and the document boundaries into account from a constrained optimization perspective. Specifically, our proposed method first learns the boundary points and the pixels in the text lines and then follows the most simple observation that the boundaries and text lines in both horizontal and vertical directions should be kept after dewarping to introduce a novel grid regularization scheme. To obtain the final forward mapping for dewarping, we solve an optimization problem with our proposed grid regularization. The experiments comprehensively demonstrate that our proposed approach outperforms the prior arts by large margins in terms of readability (with the metrics of Character Errors Rate and the Edit Distance) while maintaining the best image quality on the publicly-available DocUNet benchmark.
Weighted Contrastive Hashing
Sep 28, 2022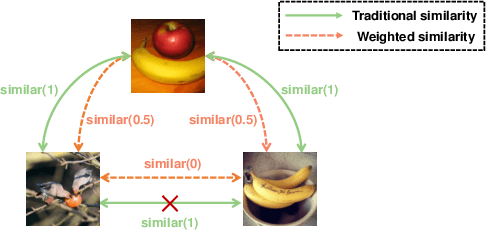
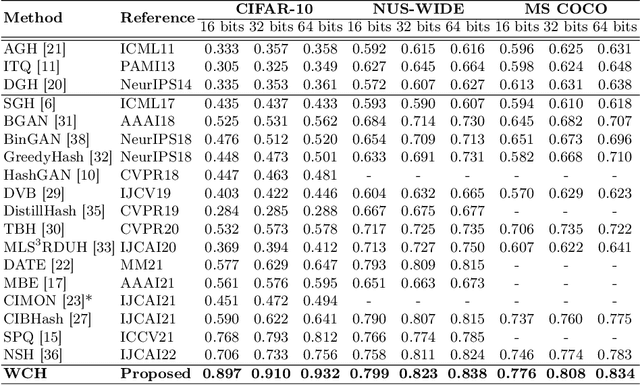
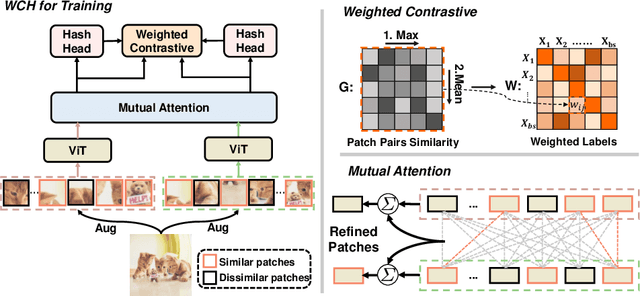
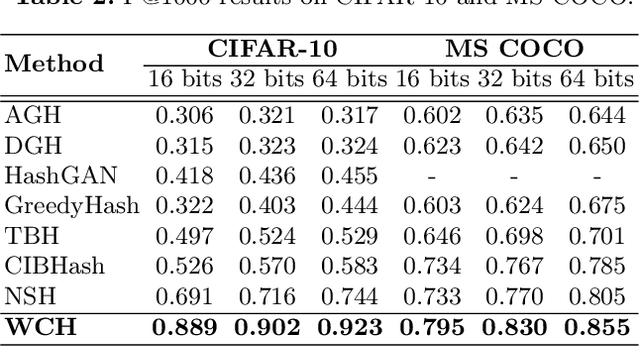
The development of unsupervised hashing is advanced by the recent popular contrastive learning paradigm. However, previous contrastive learning-based works have been hampered by (1) insufficient data similarity mining based on global-only image representations, and (2) the hash code semantic loss caused by the data augmentation. In this paper, we propose a novel method, namely Weighted Contrative Hashing (WCH), to take a step towards solving these two problems. We introduce a novel mutual attention module to alleviate the problem of information asymmetry in network features caused by the missing image structure during contrative augmentation. Furthermore, we explore the fine-grained semantic relations between images, i.e., we divide the images into multiple patches and calculate similarities between patches. The aggregated weighted similarities, which reflect the deep image relations, are distilled to facilitate the hash codes learning with a distillation loss, so as to obtain better retrieval performance. Extensive experiments show that the proposed WCH significantly outperforms existing unsupervised hashing methods on three benchmark datasets.
Beyond Invariance: Test-Time Label-Shift Adaptation for Distributions with "Spurious" Correlations
Nov 28, 2022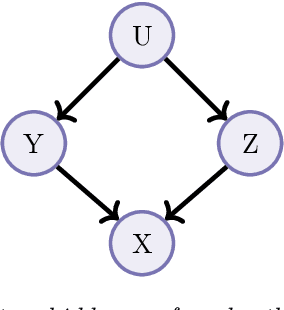
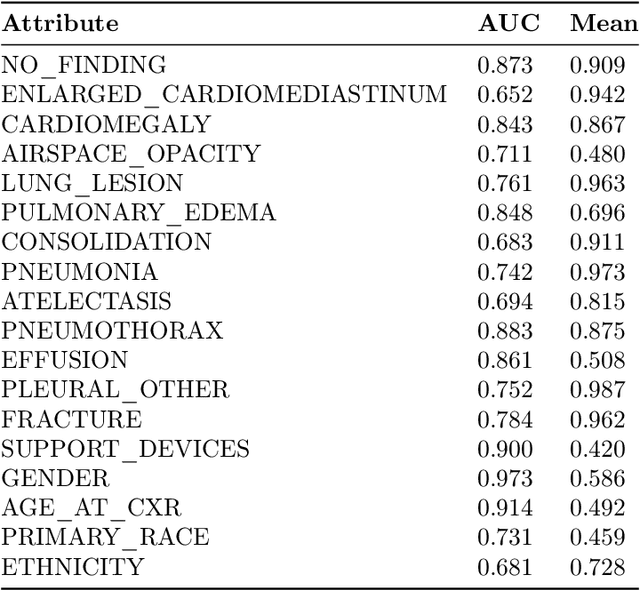
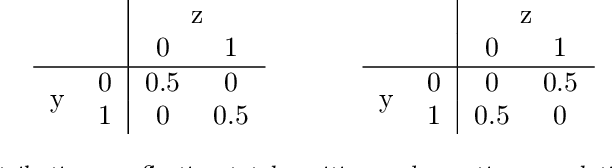
Spurious correlations, or correlations that change across domains where a model can be deployed, present significant challenges to real-world applications of machine learning models. However, such correlations are not always "spurious"; often, they provide valuable prior information for a prediction beyond what can be extracted from the input alone. Here, we present a test-time adaptation method that exploits the spurious correlation phenomenon, in contrast to recent approaches that attempt to eliminate spurious correlations through invariance. We consider situations where the prior distribution $p(y, z)$, which models the marginal dependence between the class label $y$ and the nuisance factors $z$, may change across domains, but the generative model for features $p(\mathbf{x}|y, z)$ is constant. We note that this is an expanded version of the label shift assumption, where the labels now also include the nuisance factors $z$. Based on this observation, we train a classifier to predict $p(y, z|\mathbf{x})$ on the source distribution, and implement a test-time label shift correction that adapts to changes in the marginal distribution $p(y, z)$ using unlabeled samples from the target domain. We call our method "Test-Time Label-Shift Adaptation" or TTLSA. We apply our method to two different image datasets -- the CheXpert chest X-ray dataset and the colored MNIST dataset -- and show that it gives better downstream results than methods that try to train classifiers which are invariant to the changes in prior distribution. Code reproducing experiments is available at https://github.com/nalzok/test-time-label-shift .