 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Structural Sparsity in Neural Image Compression
Feb 24, 2022
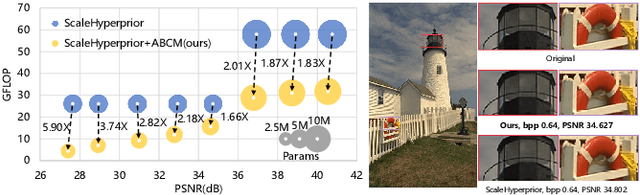
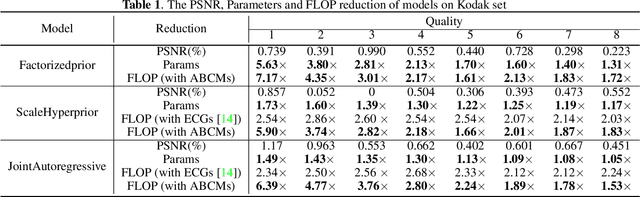
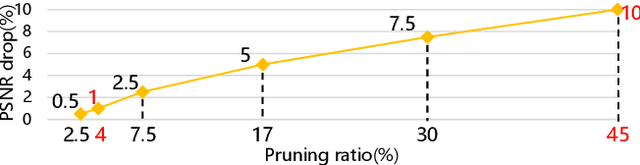

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
Image-to-Image Translation-based Data Augmentation for Robust EV Charging Inlet Detection
Dec 10, 2021

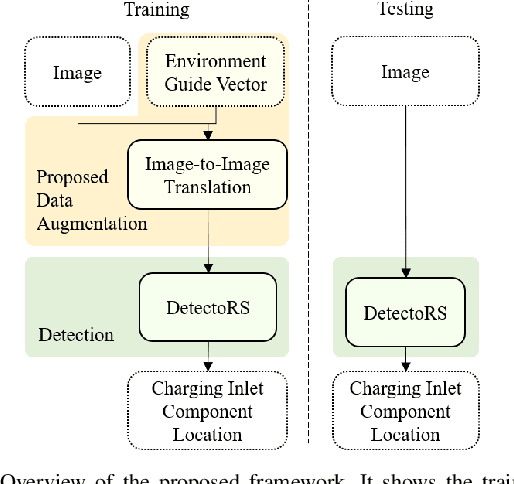

This work addresses the task of electric vehicle (EV) charging inlet detection for autonomous EV charging robots. Recently, automated EV charging systems have received huge attention to improve users' experience and to efficiently utilize charging infrastructures and parking lots. However, most related works have focused on system design, robot control, planning, and manipulation. Towards robust EV charging inlet detection, we propose a new dataset (EVCI dataset) and a novel data augmentation method that is based on image-to-image translation where typical image-to-image translation methods synthesize a new image in a different domain given an image. To the best of our knowledge, the EVCI dataset is the first EV charging inlet dataset. For the data augmentation method, we focus on being able to control synthesized images' captured environments (e.g., time, lighting) in an intuitive way. To achieve this, we first propose the environment guide vector that humans can intuitively interpret. We then propose a novel image-to-image translation network that translates a given image towards the environment described by the vector. Accordingly, it aims to synthesize a new image that has the same content as the given image while looking like captured in the provided environment by the environment guide vector. Lastly, we train a detection method using the augmented dataset. Through experiments on the EVCI dataset, we demonstrate that the proposed method outperforms the state-of-the-art methods. We also show that the proposed method is able to control synthesized images using an image and environment guide vectors.
RTN: Reinforced Transformer Network for Coronary CT Angiography Vessel-level Image Quality Assessment
Jul 13, 2022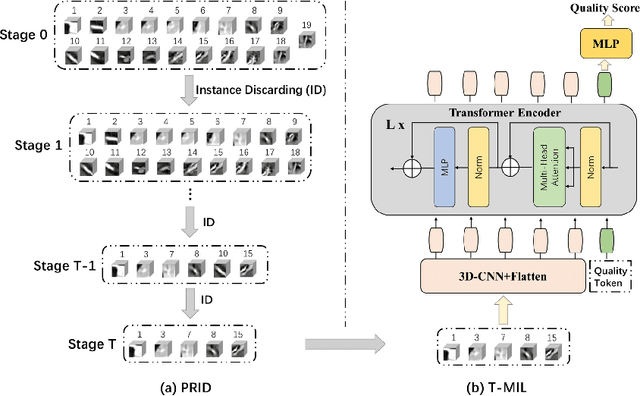
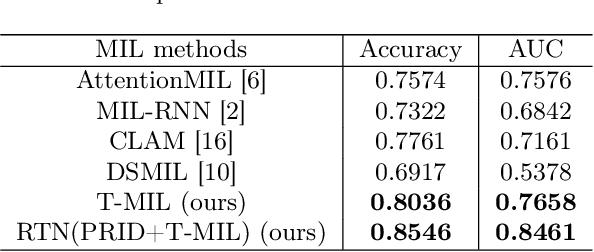


Coronary CT Angiography (CCTA) is susceptible to various distortions (e.g., artifacts and noise), which severely compromise the exact diagnosis of cardiovascular diseases. The appropriate CCTA Vessel-level Image Quality Assessment (CCTA VIQA) algorithm can be used to reduce the risk of error diagnosis. The primary challenges of CCTA VIQA are that the local part of coronary that determines final quality is hard to locate. To tackle the challenge, we formulate CCTA VIQA as a multiple-instance learning (MIL) problem, and exploit Transformer-based MIL backbone (termed as T-MIL) to aggregate the multiple instances along the coronary centerline into the final quality. However, not all instances are informative for final quality. There are some quality-irrelevant/negative instances intervening the exact quality assessment(e.g., instances covering only background or the coronary in instances is not identifiable). Therefore, we propose a Progressive Reinforcement learning based Instance Discarding module (termed as PRID) to progressively remove quality-irrelevant/negative instances for CCTA VIQA. Based on the above two modules, we propose a Reinforced Transformer Network (RTN) for automatic CCTA VIQA based on end-to-end optimization. Extensive experimental results demonstrate that our proposed method achieves the state-of-the-art performance on the real-world CCTA dataset, exceeding previous MIL methods by a large margin.
covEcho Resource constrained lung ultrasound image analysis tool for faster triaging and active learning
Jun 21, 2022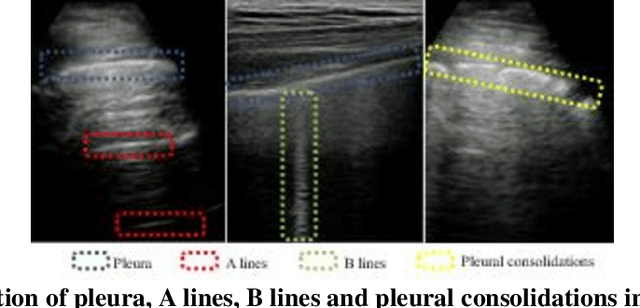
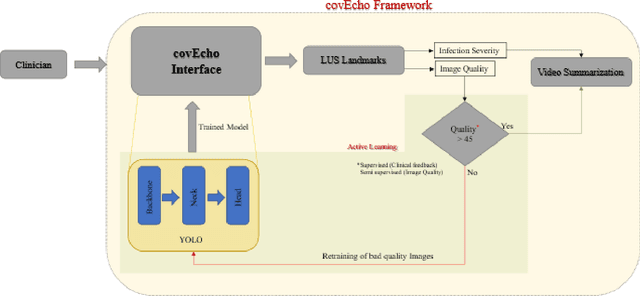
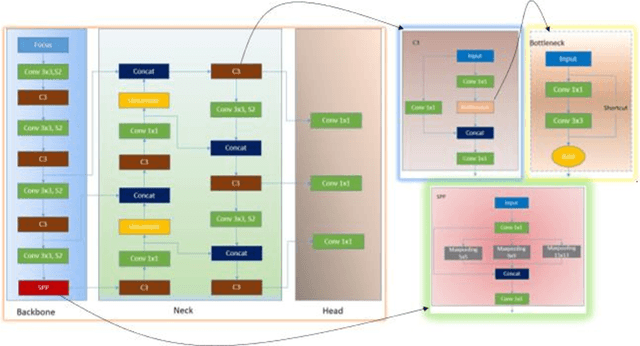
Lung ultrasound (LUS) is possibly the only medical imaging modality which could be used for continuous and periodic monitoring of the lung. This is extremely useful in tracking the lung manifestations either during the onset of lung infection or to track the effect of vaccination on lung as in pandemics such as COVID-19. There have been many attempts in automating the classification of severity of lung into various classes or automatic segmentation of various LUS landmarks and manifestations. However, all these approaches are based on training static machine learning models which require a significantly clinically annotated large dataset and are computationally heavy and most of the time non-real time. In this work, a real-time light weight active learning-based approach is presented for faster triaging in COVID-19 subjects in resource constrained settings. The tool, based on the you look only once (YOLO) network, has the capability of providing the quality of images based on the identification of various LUS landmarks, artefacts and manifestations, prediction of severity of lung infection, possibility of active learning based on the feedback from clinicians or on the image quality and a summarization of the significant frames which are having high severity of infection and high image quality for further analysis. The results show that the proposed tool has a mean average precision (mAP) of 66% at an Intersection over Union (IoU) threshold of 0.5 for the prediction of LUS landmarks. The 14MB lightweight YOLOv5s network achieves 123 FPS while running in a Quadro P4000 GPU. The tool is available for usage and analysis upon request from the authors.
SVFormer: Semi-supervised Video Transformer for Action Recognition
Nov 23, 2022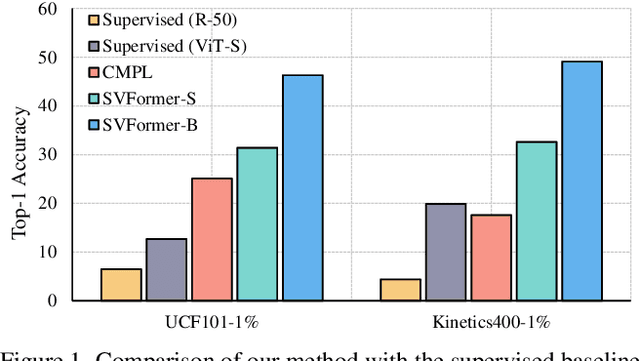
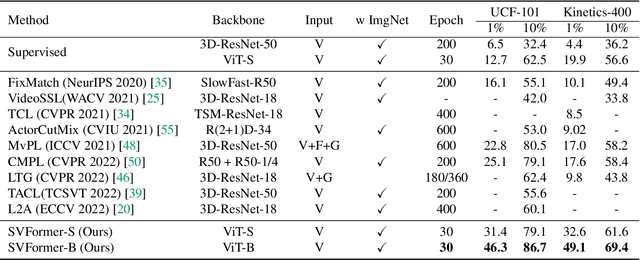


Semi-supervised action recognition is a challenging but critical task due to the high cost of video annotations. Existing approaches mainly use convolutional neural networks, yet current revolutionary vision transformer models have been less explored. In this paper, we investigate the use of transformer models under the SSL setting for action recognition. To this end, we introduce SVFormer, which adopts a steady pseudo-labeling framework (ie, EMA-Teacher) to cope with unlabeled video samples. While a wide range of data augmentations have been shown effective for semi-supervised image classification, they generally produce limited results for video recognition. We therefore introduce a novel augmentation strategy, Tube TokenMix, tailored for video data where video clips are mixed via a mask with consistent masked tokens over the temporal axis. In addition, we propose a temporal warping augmentation to cover the complex temporal variation in videos, which stretches selected frames to various temporal durations in the clip. Extensive experiments on three datasets Kinetics-400, UCF-101, and HMDB-51 verify the advantage of SVFormer. In particular, SVFormer outperforms the state-of-the-art by 31.5% with fewer training epochs under the 1% labeling rate of Kinetics-400. Our method can hopefully serve as a strong benchmark and encourage future search on semi-supervised action recognition with Transformer networks.
Learning Compact Features via In-Training Representation Alignment
Nov 23, 2022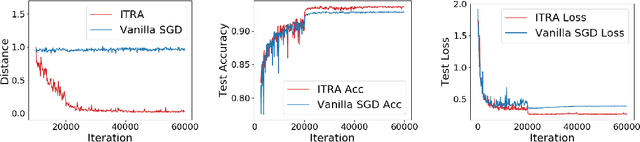
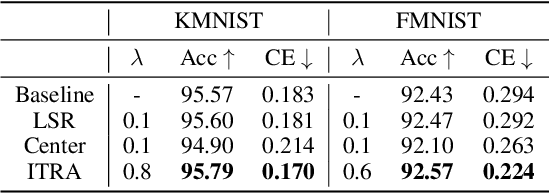
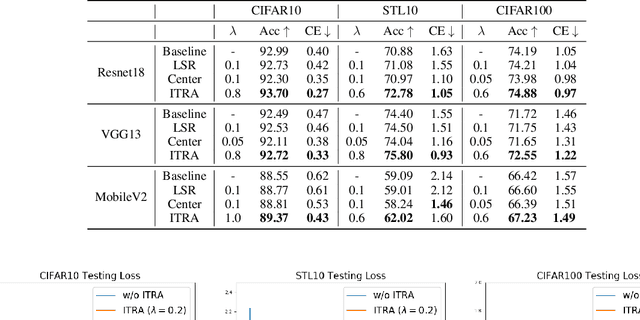
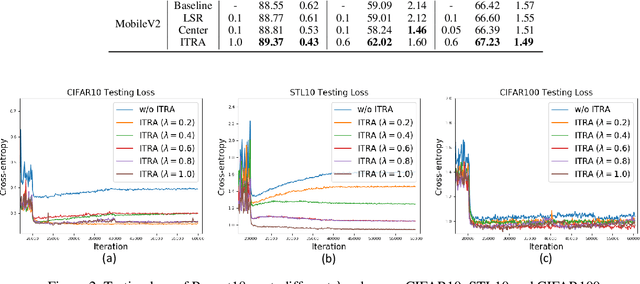
Deep neural networks (DNNs) for supervised learning can be viewed as a pipeline of the feature extractor (i.e., last hidden layer) and a linear classifier (i.e., output layer) that are trained jointly with stochastic gradient descent (SGD) on the loss function (e.g., cross-entropy). In each epoch, the true gradient of the loss function is estimated using a mini-batch sampled from the training set and model parameters are then updated with the mini-batch gradients. Although the latter provides an unbiased estimation of the former, they are subject to substantial variances derived from the size and number of sampled mini-batches, leading to noisy and jumpy updates. To stabilize such undesirable variance in estimating the true gradients, we propose In-Training Representation Alignment (ITRA) that explicitly aligns feature distributions of two different mini-batches with a matching loss in the SGD training process. We also provide a rigorous analysis of the desirable effects of the matching loss on feature representation learning: (1) extracting compact feature representation; (2) reducing over-adaption on mini-batches via an adaptive weighting mechanism; and (3) accommodating to multi-modalities. Finally, we conduct large-scale experiments on both image and text classifications to demonstrate its superior performance to the strong baselines.
Image Synthesis with Disentangled Attributes for Chest X-Ray Nodule Augmentation and Detection
Jul 19, 2022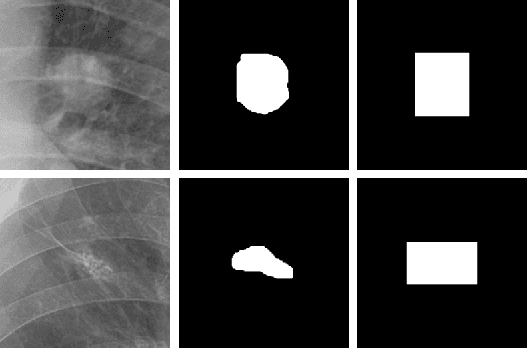
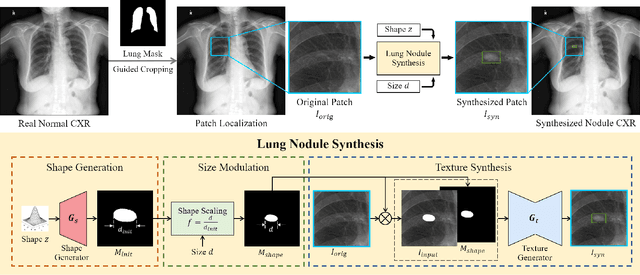
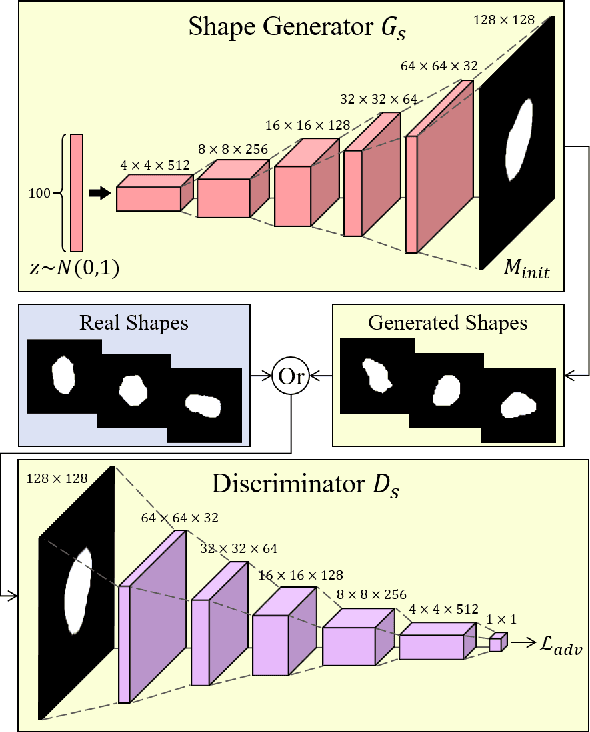
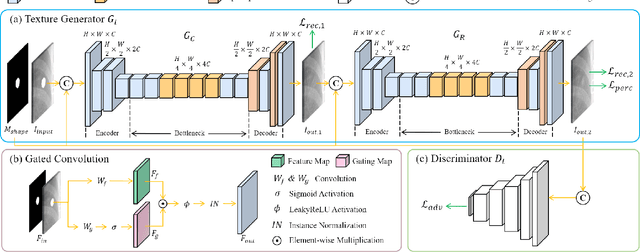
Lung nodule detection in chest X-ray (CXR) images is common to early screening of lung cancers. Deep-learning-based Computer-Assisted Diagnosis (CAD) systems can support radiologists for nodule screening in CXR. However, it requires large-scale and diverse medical data with high-quality annotations to train such robust and accurate CADs. To alleviate the limited availability of such datasets, lung nodule synthesis methods are proposed for the sake of data augmentation. Nevertheless, previous methods lack the ability to generate nodules that are realistic with the size attribute desired by the detector. To address this issue, we introduce a novel lung nodule synthesis framework in this paper, which decomposes nodule attributes into three main aspects including shape, size, and texture, respectively. A GAN-based Shape Generator firstly models nodule shapes by generating diverse shape masks. The following Size Modulation then enables quantitative control on the diameters of the generated nodule shapes in pixel-level granularity. A coarse-to-fine gated convolutional Texture Generator finally synthesizes visually plausible nodule textures conditioned on the modulated shape masks. Moreover, we propose to synthesize nodule CXR images by controlling the disentangled nodule attributes for data augmentation, in order to better compensate for the nodules that are easily missed in the detection task. Our experiments demonstrate the enhanced image quality, diversity, and controllability of the proposed lung nodule synthesis framework. We also validate the effectiveness of our data augmentation on greatly improving nodule detection performance.
Search Space Adaptation for Differentiable Neural Architecture Search in Image Classification
Jun 05, 2022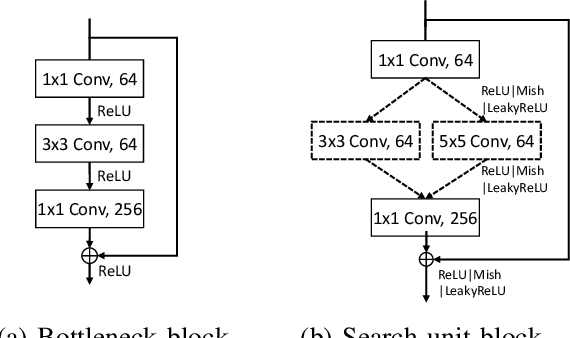
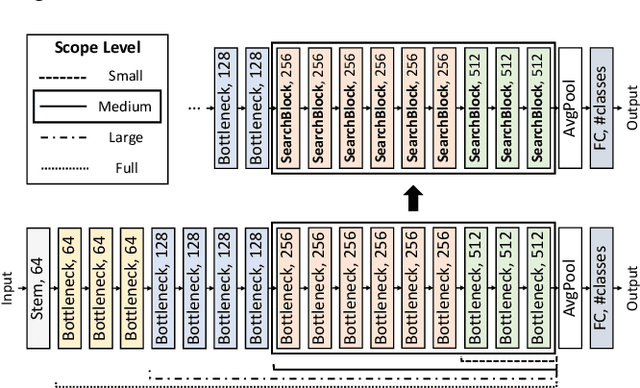
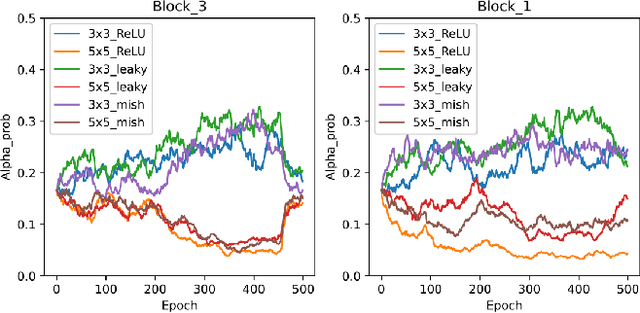
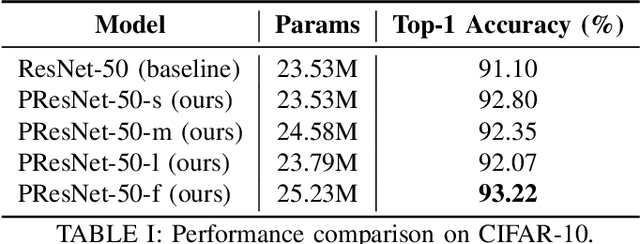
As deep neural networks achieve unprecedented performance in various tasks, neural architecture search (NAS), a research field for designing neural network architectures with automated processes, is actively underway. More recently, differentiable NAS has a great impact by reducing the search cost to the level of training a single network. Besides, the search space that defines candidate architectures to be searched directly affects the performance of the final architecture. In this paper, we propose an adaptation scheme of the search space by introducing a search scope. The effectiveness of proposed method is demonstrated with ProxylessNAS for the image classification task. Furthermore, we visualize the trajectory of architecture parameter updates and provide insights to improve the architecture search.
Deep Learning Approaches on Image Captioning: A Review
Jan 31, 2022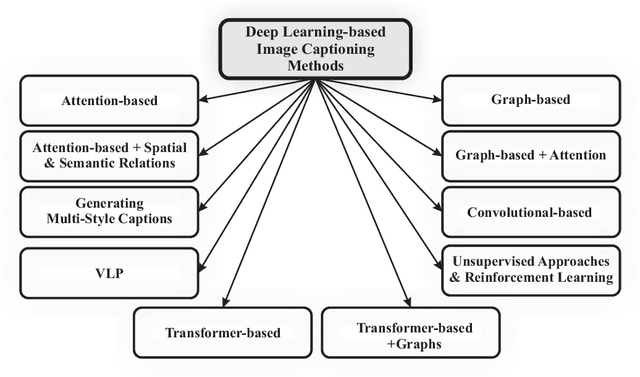
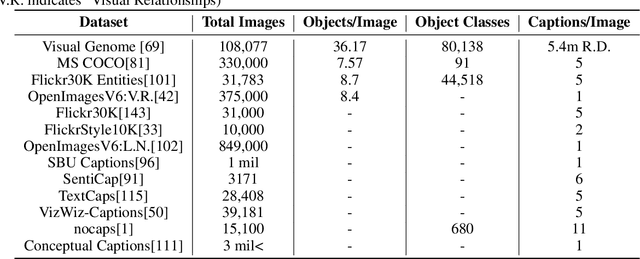
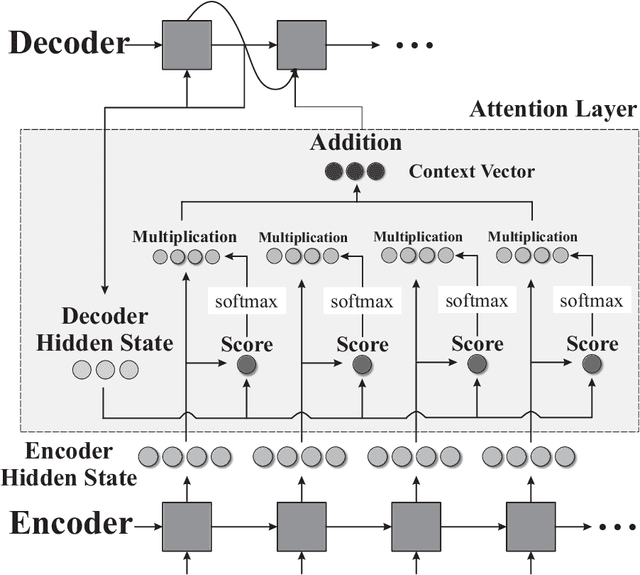
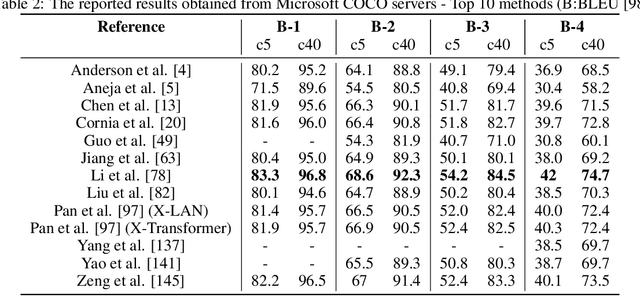
Automatic image captioning, which involves describing the contents of an image, is a challenging problem with many applications in various research fields. One notable example is designing assistants for the visually impaired. Recently, there have been significant advances in image captioning methods owing to the breakthroughs in deep learning. This survey paper aims to provide a structured review of recent image captioning techniques, and their performance, focusing mainly on deep learning methods. We also review widely-used datasets and performance metrics, in addition to the discussions on open problems and unsolved challenges in image captioning.
Frequency Cam: Imaging Periodic Signals in Real-Time
Nov 01, 2022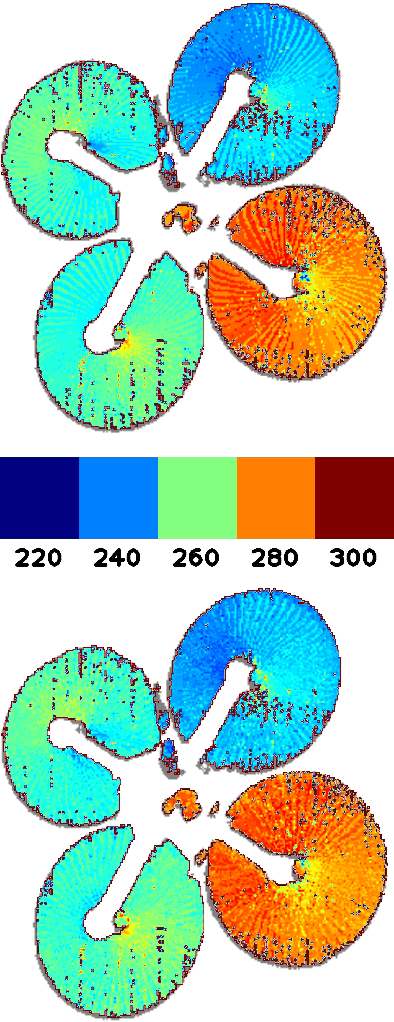
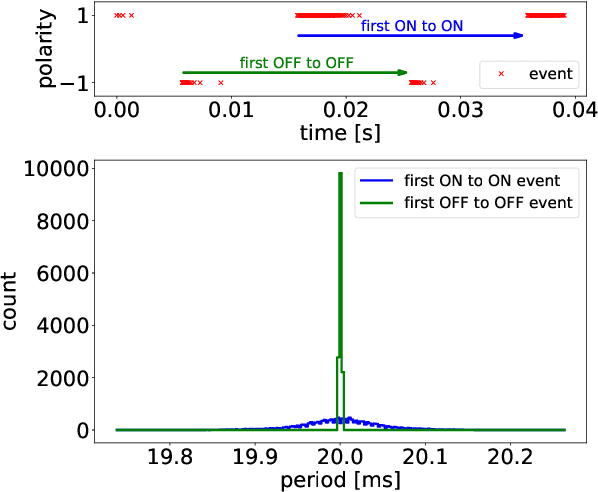
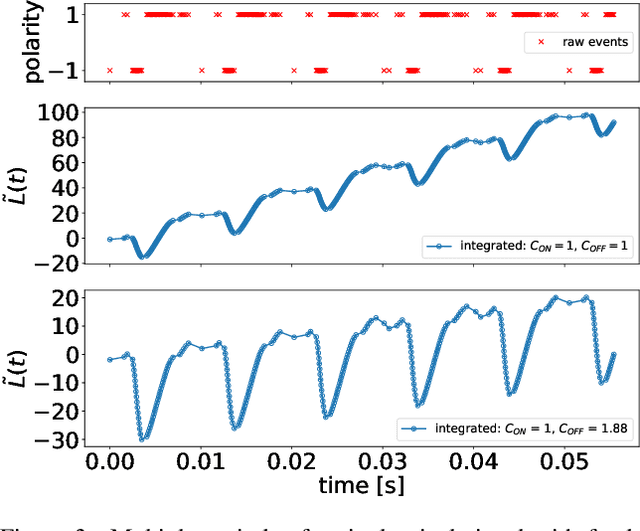
Due to their high temporal resolution and large dynamic range event cameras are uniquely suited for the analysis of time-periodic signals in an image. In this work we present an efficient and fully asynchronous event camera algorithm for detecting the fundamental frequency at which image pixels flicker. The algorithm employs a second-order digital infinite impulse response (IIR) filter to perform an approximate per-pixel brightness reconstruction and is more robust to high-frequency noise than the baseline method we compare to. We further demonstrate that using the falling edge of the signal leads to more accurate period estimates than the rising edge, and that for certain signals interpolating the zero-level crossings can further increase accuracy. Our experiments find that the outstanding capabilities of the camera in detecting frequencies up to 64kHz for a single pixel do not carry over to full sensor imaging as readout bandwidth limitations become a serious obstacle. This suggests that a hardware implementation closer to the sensor will allow for greatly improved frequency imaging. We discuss the important design parameters for fullsensor frequency imaging and present Frequency Cam, an open-source implementation as a ROS node that can run on a single core of a laptop CPU at more than 50 million events per second. It produces results that are qualitatively very similar to those obtained from the closed source vibration analysis module in Prophesee's Metavision Toolkit. The code for Frequency Cam and a demonstration video can be found at https://github.com/berndpfrommer/frequency_cam