 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bilateral Propagation Network for Depth Completion
Mar 17, 2024
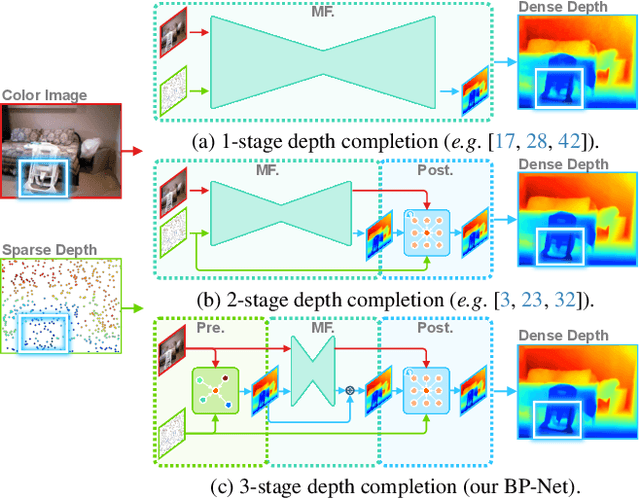
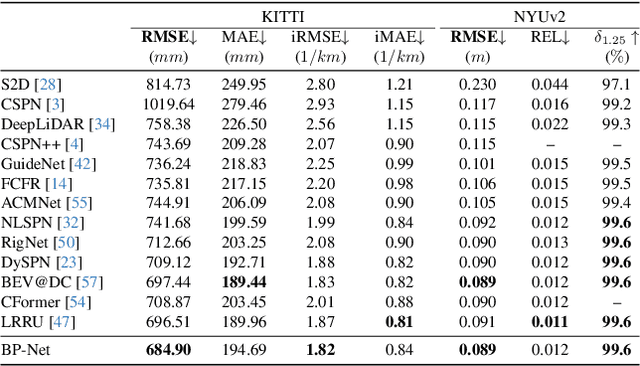
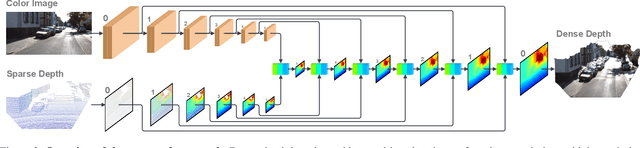
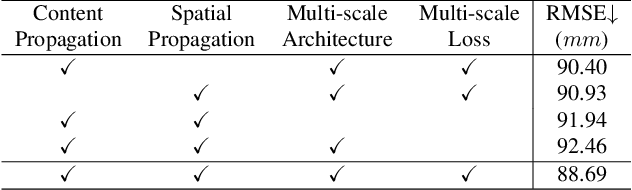
Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.
ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models
Mar 17, 2024
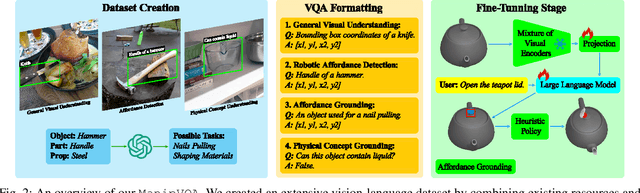


The integration of Multimodal Large Language Models (MLLMs) with robotic systems has significantly enhanced the ability of robots to interpret and act upon natural language instructions. Despite these advancements, conventional MLLMs are typically trained on generic image-text pairs, lacking essential robotics knowledge such as affordances and physical knowledge, which hampers their efficacy in manipulation tasks. To bridge this gap, we introduce ManipVQA, a novel framework designed to endow MLLMs with Manipulation-centric knowledge through a Visual Question-Answering format. This approach not only encompasses tool detection and affordance recognition but also extends to a comprehensive understanding of physical concepts. Our approach starts with collecting a varied set of images displaying interactive objects, which presents a broad range of challenges in tool object detection, affordance, and physical concept predictions. To seamlessly integrate this robotic-specific knowledge with the inherent vision-reasoning capabilities of MLLMs, we adopt a unified VQA format and devise a fine-tuning strategy that preserves the original vision-reasoning abilities while incorporating the new robotic insights. Empirical evaluations conducted in robotic simulators and across various vision task benchmarks demonstrate the robust performance of ManipVQA. Code and dataset will be made publicly available at https://github.com/SiyuanHuang95/ManipVQA.
Self-Supervised Video Desmoking for Laparoscopic Surgery
Mar 17, 2024
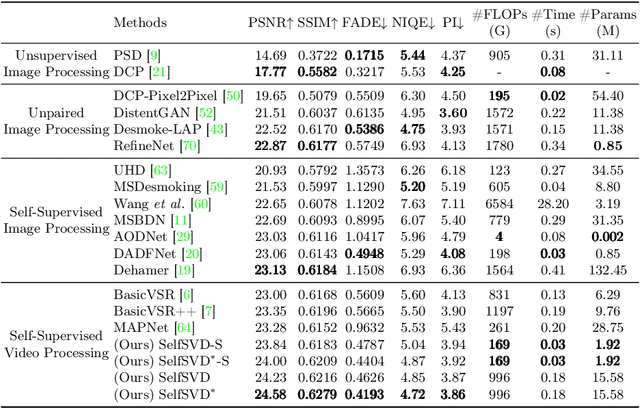
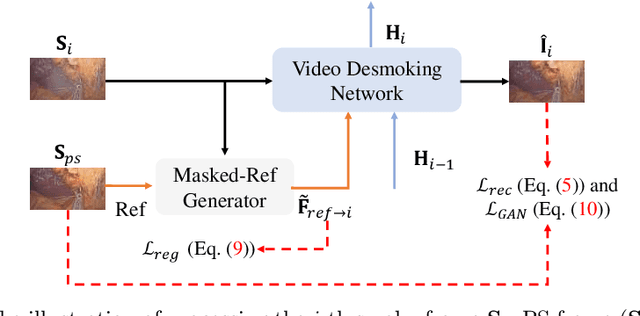
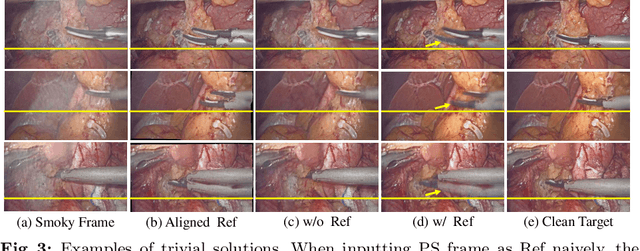
Due to the difficulty of collecting real paired data, most existing desmoking methods train the models by synthesizing smoke, generalizing poorly to real surgical scenarios. Although a few works have explored single-image real-world desmoking in unpaired learning manners, they still encounter challenges in handling dense smoke. In this work, we address these issues together by introducing the self-supervised surgery video desmoking (SelfSVD). On the one hand, we observe that the frame captured before the activation of high-energy devices is generally clear (named pre-smoke frame, PS frame), thus it can serve as supervision for other smoky frames, making real-world self-supervised video desmoking practically feasible. On the other hand, in order to enhance the desmoking performance, we further feed the valuable information from PS frame into models, where a masking strategy and a regularization term are presented to avoid trivial solutions. In addition, we construct a real surgery video dataset for desmoking, which covers a variety of smoky scenes. Extensive experiments on the dataset show that our SelfSVD can remove smoke more effectively and efficiently while recovering more photo-realistic details than the state-of-the-art methods. The dataset, codes, and pre-trained models are available at \url{https://github.com/ZcsrenlongZ/SelfSVD}.
Mixture-of-Prompt-Experts for Multi-modal Semantic Understanding
Mar 17, 2024
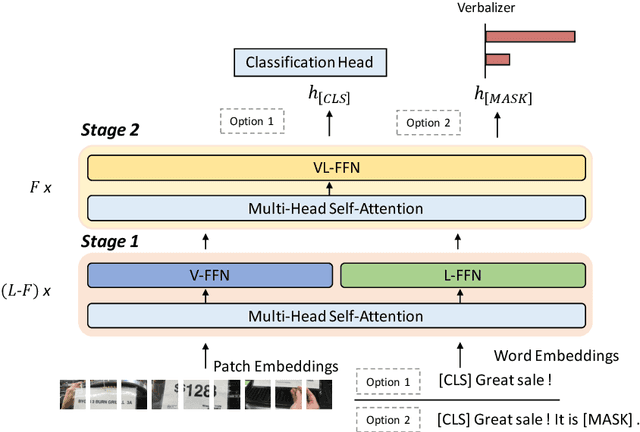
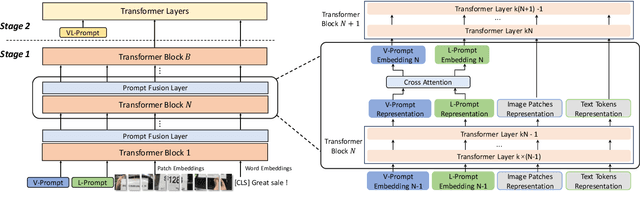

Deep multimodal semantic understanding that goes beyond the mere superficial content relation mining has received increasing attention in the realm of artificial intelligence. The challenges of collecting and annotating high-quality multi-modal data have underscored the significance of few-shot learning. In this paper, we focus on two critical tasks under this context: few-shot multi-modal sarcasm detection (MSD) and multi-modal sentiment analysis (MSA). To address them, we propose Mixture-of-Prompt-Experts with Block-Aware Prompt Fusion (MoPE-BAF), a novel multi-modal soft prompt framework based on the unified vision-language model (VLM). Specifically, we design three experts of soft prompts: a text prompt and an image prompt that extract modality-specific features to enrich the single-modal representation, and a unified prompt to assist multi-modal interaction. Additionally, we reorganize Transformer layers into several blocks and introduce cross-modal prompt attention between adjacent blocks, which smoothens the transition from single-modal representation to multi-modal fusion. On both MSD and MSA datasets in few-shot setting, our proposed model not only surpasses the 8.2B model InstructBLIP with merely 2% parameters (150M), but also significantly outperforms other widely-used prompt methods on VLMs or task-specific methods.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.
Block and Detail: Scaffolding Sketch-to-Image Generation
Feb 28, 2024We introduce a novel sketch-to-image tool that aligns with the iterative refinement process of artists. Our tool lets users sketch blocking strokes to coarsely represent the placement and form of objects and detail strokes to refine their shape and silhouettes. We develop a two-pass algorithm for generating high-fidelity images from such sketches at any point in the iterative process. In the first pass we use a ControlNet to generate an image that strictly follows all the strokes (blocking and detail) and in the second pass we add variation by renoising regions surrounding blocking strokes. We also present a dataset generation scheme that, when used to train a ControlNet architecture, allows regions that do not contain strokes to be interpreted as not-yet-specified regions rather than empty space. We show that this partial-sketch-aware ControlNet can generate coherent elements from partial sketches that only contain a small number of strokes. The high-fidelity images produced by our approach serve as scaffolds that can help the user adjust the shape and proportions of objects or add additional elements to the composition. We demonstrate the effectiveness of our approach with a variety of examples and evaluative comparisons.
Local positional graphs and attentive local features for a data and runtime-efficient hierarchical place recognition pipeline
Mar 15, 2024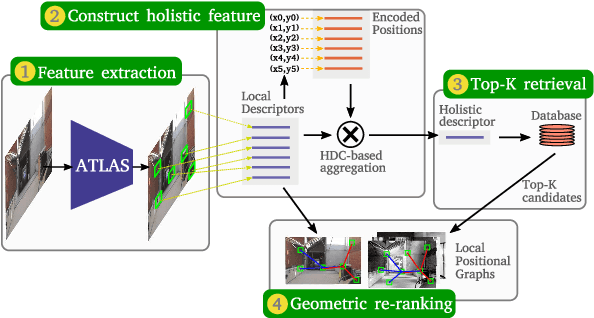
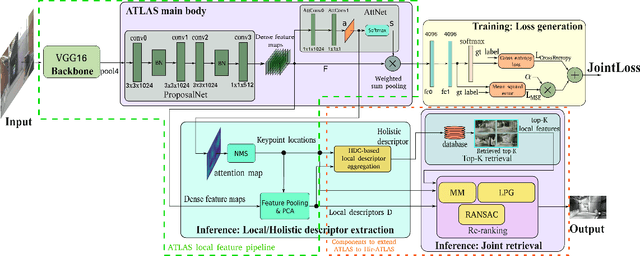
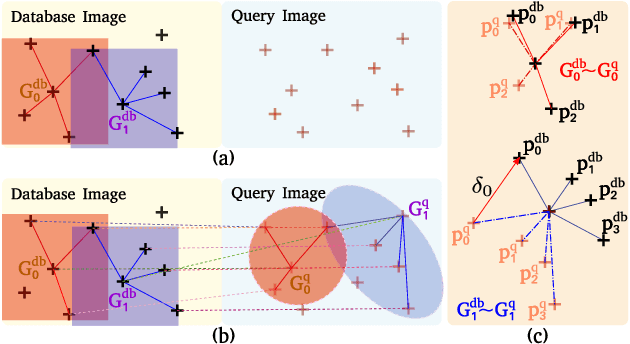

Large-scale applications of Visual Place Recognition (VPR) require computationally efficient approaches. Further, a well-balanced combination of data-based and training-free approaches can decrease the required amount of training data and effort and can reduce the influence of distribution shifts between the training and application phases. This paper proposes a runtime and data-efficient hierarchical VPR pipeline that extends existing approaches and presents novel ideas. There are three main contributions: First, we propose Local Positional Graphs (LPG), a training-free and runtime-efficient approach to encode spatial context information of local image features. LPG can be combined with existing local feature detectors and descriptors and considerably improves the image-matching quality compared to existing techniques in our experiments. Second, we present Attentive Local SPED (ATLAS), an extension of our previous local features approach with an attention module that improves the feature quality while maintaining high data efficiency. The influence of the proposed modifications is evaluated in an extensive ablation study. Third, we present a hierarchical pipeline that exploits hyperdimensional computing to use the same local features as holistic HDC-descriptors for fast candidate selection and for candidate reranking. We combine all contributions in a runtime and data-efficient VPR pipeline that shows benefits over the state-of-the-art method Patch-NetVLAD on a large collection of standard place recognition datasets with 15$\%$ better performance in VPR accuracy, 54$\times$ faster feature comparison speed, and 55$\times$ less descriptor storage occupancy, making our method promising for real-world high-performance large-scale VPR in changing environments. Code will be made available with publication of this paper.
Deep Learning for Multi-Level Detection and Localization of Myocardial Scars Based on Regional Strain Validated on Virtual Patients
Mar 15, 2024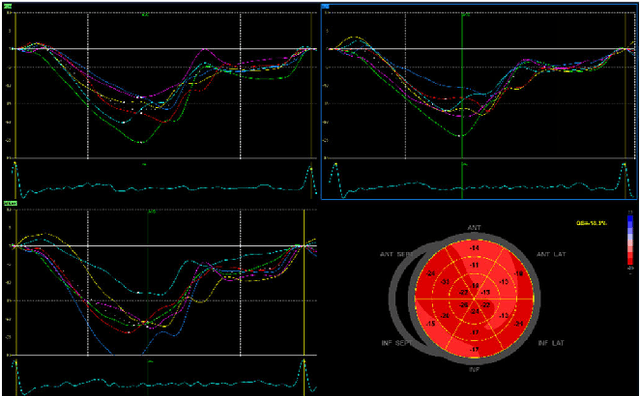
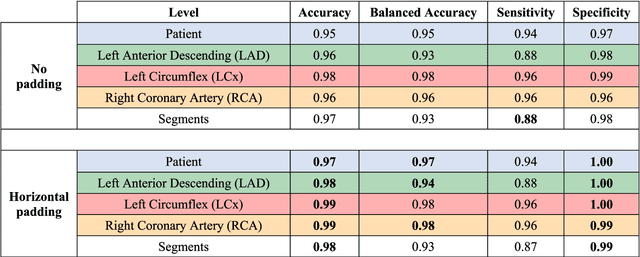

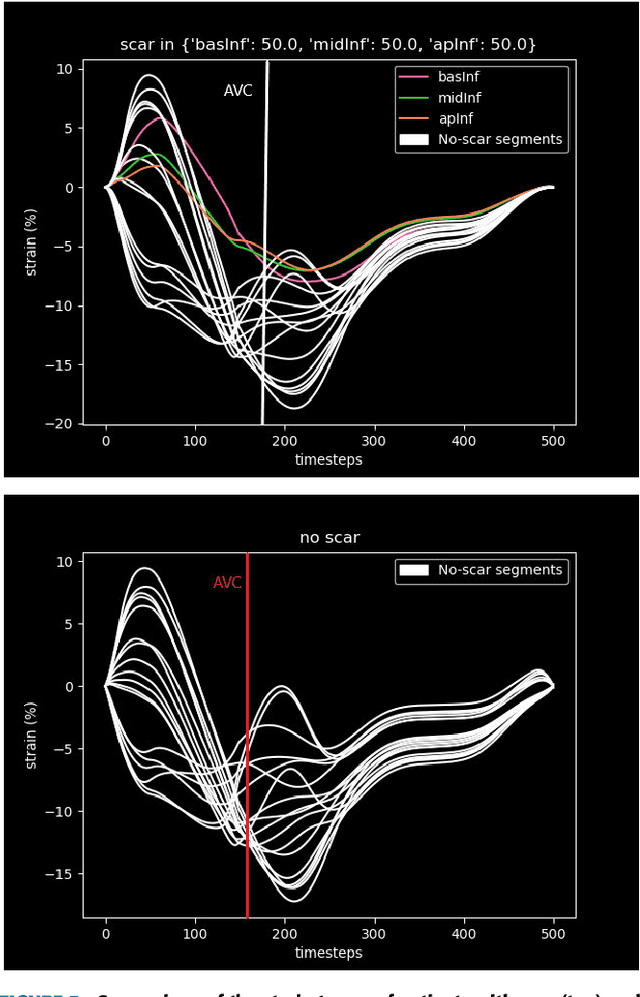
How well the heart is functioning can be quantified through measurements of myocardial deformation via echocardiography. Clinical assessment of cardiac function is generally focused on global indices of relative shortening, however, territorial, and segmental strain indices have shown to be abnormal in regions of myocardial disease, such as scar. In this work, we propose a single framework to predict myocardial disease substrates at global, territorial, and segmental levels using regional myocardial strain traces as input to a convolutional neural network (CNN)-based classification algorithm. An anatomically meaningful representation of the input data from the clinically standard bullseye representation to a multi-channel 2D image is proposed, to formulate the task as an image classification problem, thus enabling the use of state-of-the-art neural network configurations. A Fully Convolutional Network (FCN) is trained to detect and localize myocardial scar from regional left ventricular (LV) strain patterns. Simulated regional strain data from a controlled dataset of virtual patients with varying degrees and locations of myocardial scar is used for training and validation. The proposed method successfully detects and localizes the scars on 98% of the 5490 left ventricle (LV) segments of the 305 patients in the test set using strain traces only. Due to the sparse existence of scar, only 10% of the LV segments in the virtual patient cohort have scar. Taking the imbalance into account, the class balanced accuracy is calculated as 95%. The performance is reported on global, territorial, and segmental levels. The proposed method proves successful on the strain traces of the virtual cohort and offers the potential to solve the regional myocardial scar detection problem on the strain traces of the real patient cohorts.
* 11 pages, 9 figures and 1 table. Preliminary results of the method was presented as poster in IEEE conference International Ultrasonics Symposium 2022 in Venice, Italy
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 18, 2024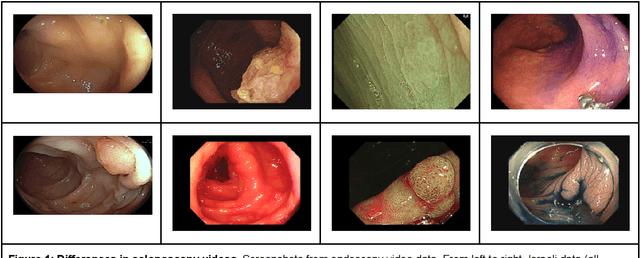
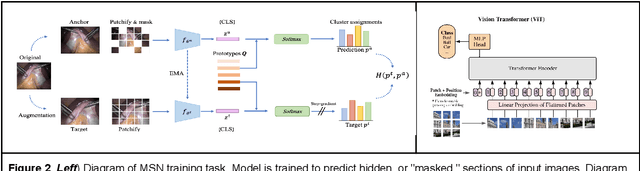
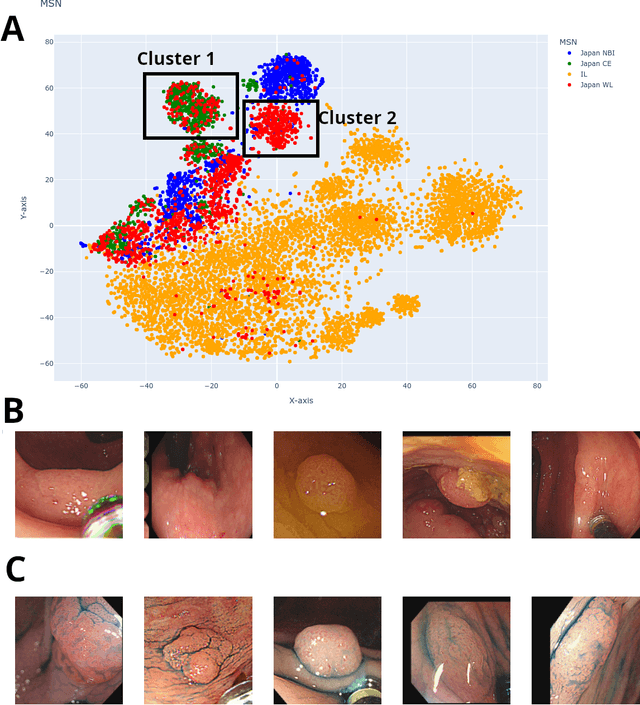
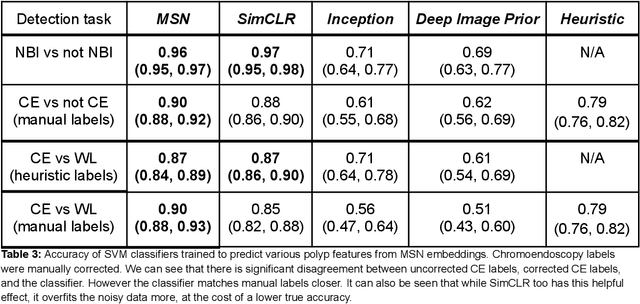
Background: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. Methods: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. Results: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). Conclusion: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
CCC++: Optimized Color Classified Colorization with Segment Anything Model (SAM) Empowered Object Selective Color Harmonization
Mar 18, 2024
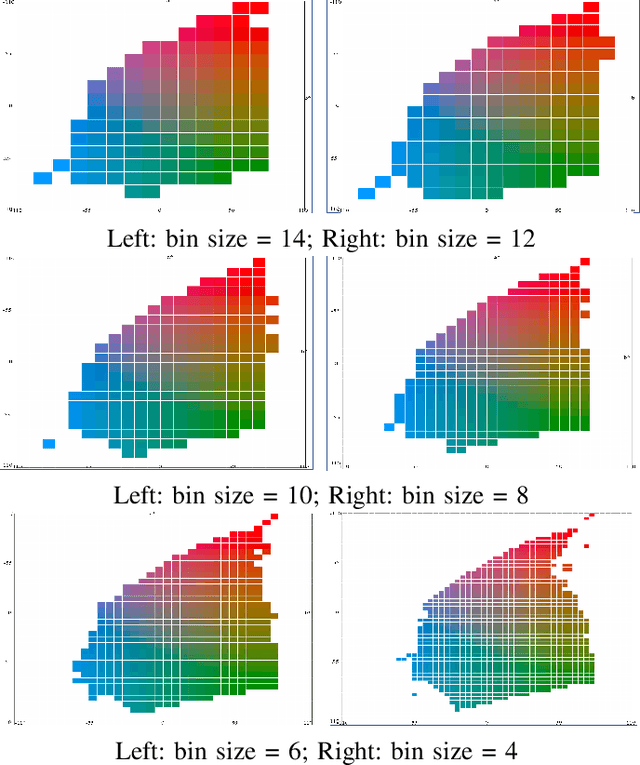
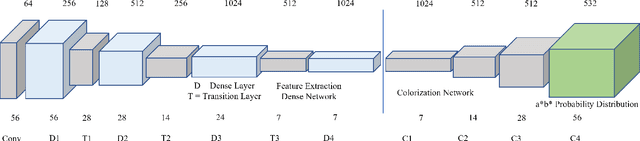
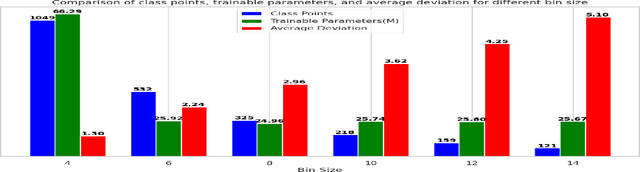
In this paper, we formulate the colorization problem into a multinomial classification problem and then apply a weighted function to classes. We propose a set of formulas to transform color values into color classes and vice versa. To optimize the classes, we experiment with different bin sizes for color class transformation. Observing class appearance, standard deviation, and model parameters on various extremely large-scale real-time images in practice we propose 532 color classes for our classification task. During training, we propose a class-weighted function based on true class appearance in each batch to ensure proper saturation of individual objects. We adjust the weights of the major classes, which are more frequently observed, by lowering them, while escalating the weights of the minor classes, which are less commonly observed. In our class re-weight formula, we propose a hyper-parameter for finding the optimal trade-off between the major and minor appeared classes. As we apply regularization to enhance the stability of the minor class, occasional minor noise may appear at the object's edges. We propose a novel object-selective color harmonization method empowered by the Segment Anything Model (SAM) to refine and enhance these edges. We propose two new color image evaluation metrics, the Color Class Activation Ratio (CCAR), and the True Activation Ratio (TAR), to quantify the richness of color components. We compare our proposed model with state-of-the-art models using six different dataset: Place, ADE, Celeba, COCO, Oxford 102 Flower, and ImageNet, in qualitative and quantitative approaches. The experimental results show that our proposed model outstrips other models in visualization, CNR and in our proposed CCAR and TAR measurement criteria while maintaining satisfactory performance in regression (MSE, PSNR), similarity (SSIM, LPIPS, UIUI), and generative criteria (FID).