 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
May 30, 2022
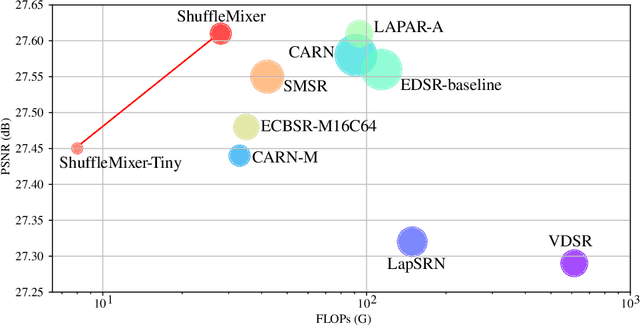
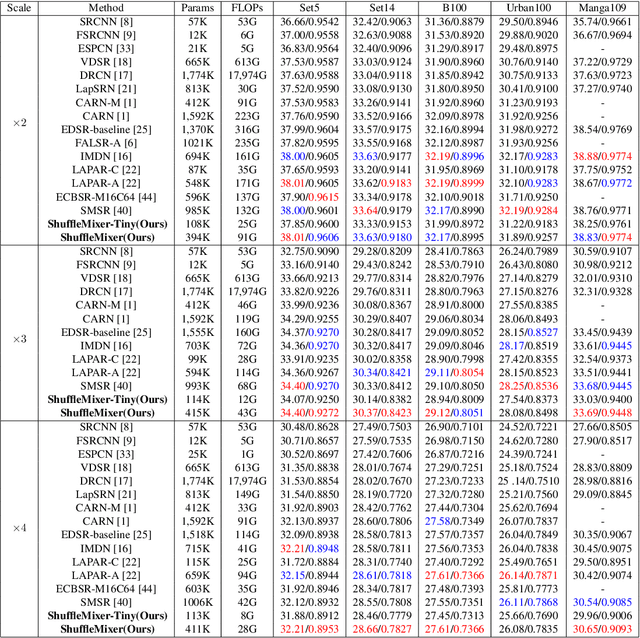
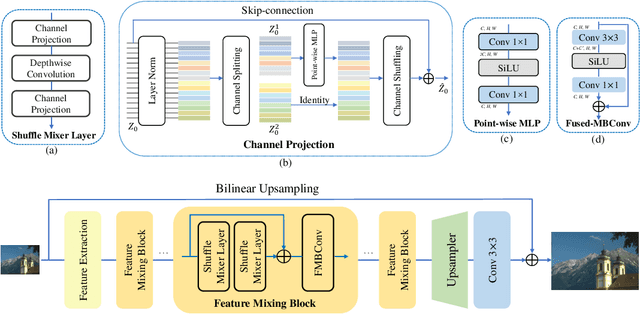
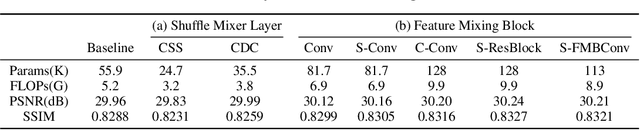
Lightweight and efficiency are critical drivers for the practical application of image super-resolution (SR) algorithms. We propose a simple and effective approach, ShuffleMixer, for lightweight image super-resolution that explores large convolution and channel split-shuffle operation. In contrast to previous SR models that simply stack multiple small kernel convolutions or complex operators to learn representations, we explore a large kernel ConvNet for mobile-friendly SR design. Specifically, we develop a large depth-wise convolution and two projection layers based on channel splitting and shuffling as the basic component to mix features efficiently. Since the contexts of natural images are strongly locally correlated, using large depth-wise convolutions only is insufficient to reconstruct fine details. To overcome this problem while maintaining the efficiency of the proposed module, we introduce Fused-MBConvs into the proposed network to model the local connectivity of different features. Experimental results demonstrate that the proposed ShuffleMixer is about 6x smaller than the state-of-the-art methods in terms of model parameters and FLOPs while achieving competitive performance. In NTIRE 2022, our primary method won the model complexity track of the Efficient Super-Resolution Challenge [23]. The code is available at https://github.com/sunny2109/MobileSR-NTIRE2022.
Evaluating Out-of-Distribution Performance on Document Image Classifiers
Oct 14, 2022


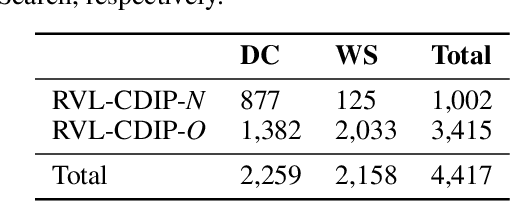
The ability of a document classifier to handle inputs that are drawn from a distribution different from the training distribution is crucial for robust deployment and generalizability. The RVL-CDIP corpus is the de facto standard benchmark for document classification, yet to our knowledge all studies that use this corpus do not include evaluation on out-of-distribution documents. In this paper, we curate and release a new out-of-distribution benchmark for evaluating out-of-distribution performance for document classifiers. Our new out-of-distribution benchmark consists of two types of documents: those that are not part of any of the 16 in-domain RVL-CDIP categories (RVL-CDIP-O), and those that are one of the 16 in-domain categories yet are drawn from a distribution different from that of the original RVL-CDIP dataset (RVL-CDIP-N). While prior work on document classification for in-domain RVL-CDIP documents reports high accuracy scores, we find that these models exhibit accuracy drops of between roughly 15-30% on our new out-of-domain RVL-CDIP-N benchmark, and further struggle to distinguish between in-domain RVL-CDIP-N and out-of-domain RVL-CDIP-O inputs. Our new benchmark provides researchers with a valuable new resource for analyzing out-of-distribution performance on document classifiers. Our new out-of-distribution data can be found at https://tinyurl.com/4he6my23.
CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion
Oct 19, 2022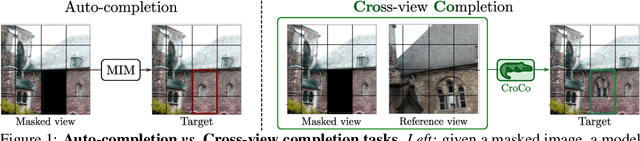
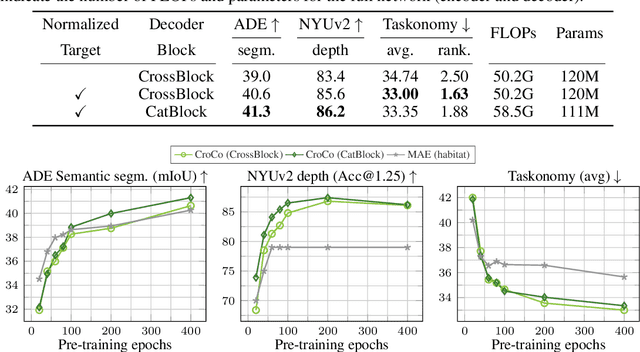


Masked Image Modeling (MIM) has recently been established as a potent pre-training paradigm. A pretext task is constructed by masking patches in an input image, and this masked content is then predicted by a neural network using visible patches as sole input. This pre-training leads to state-of-the-art performance when finetuned for high-level semantic tasks, e.g. image classification and object detection. In this paper we instead seek to learn representations that transfer well to a wide variety of 3D vision and lower-level geometric downstream tasks, such as depth prediction or optical flow estimation. Inspired by MIM, we propose an unsupervised representation learning task trained from pairs of images showing the same scene from different viewpoints. More precisely, we propose the pretext task of cross-view completion where the first input image is partially masked, and this masked content has to be reconstructed from the visible content and the second image. In single-view MIM, the masked content often cannot be inferred precisely from the visible portion only, so the model learns to act as a prior influenced by high-level semantics. In contrast, this ambiguity can be resolved with cross-view completion from the second unmasked image, on the condition that the model is able to understand the spatial relationship between the two images. Our experiments show that our pretext task leads to significantly improved performance for monocular 3D vision downstream tasks such as depth estimation. In addition, our model can be directly applied to binocular downstream tasks like optical flow or relative camera pose estimation, for which we obtain competitive results without bells and whistles, i.e., using a generic architecture without any task-specific design.
Domain generalization in fetal brain MRI segmentation \\with multi-reconstruction augmentation
Nov 25, 2022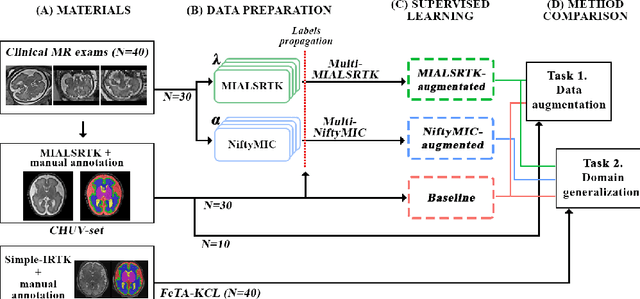

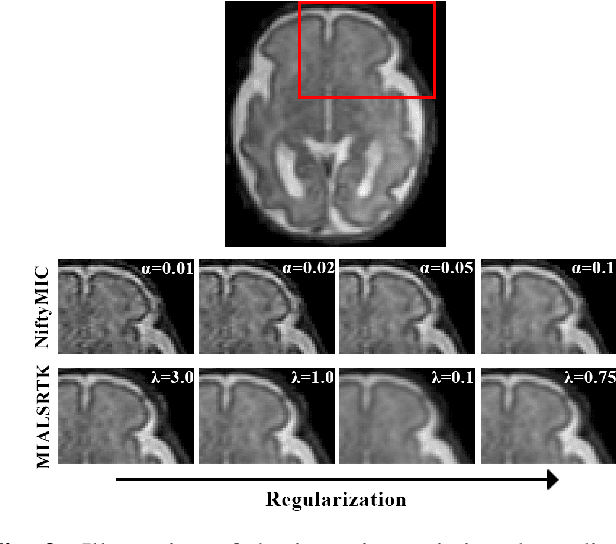
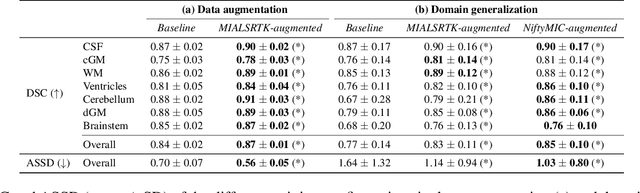
Quantitative analysis of in utero human brain development is crucial for abnormal characterization. Magnetic resonance image (MRI) segmentation is therefore an asset for quantitative analysis. However, the development of automated segmentation methods is hampered by the scarce availability of fetal brain MRI annotated datasets and the limited variability within these cohorts. In this context, we propose to leverage the power of fetal brain MRI super-resolution (SR) reconstruction methods to generate multiple reconstructions of a single subject with different parameters, thus as an efficient tuning-free data augmentation strategy. Overall, the latter significantly improves the generalization of segmentation methods over SR pipelines.
Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance
Oct 11, 2022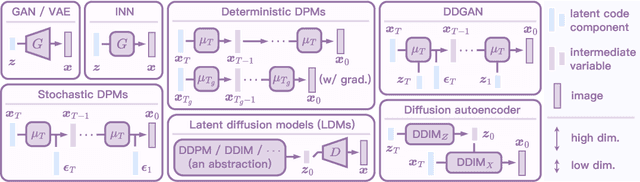



Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs.
Current Trends in Deep Learning for Earth Observation: An Open-source Benchmark Arena for Image Classification
Jul 14, 2022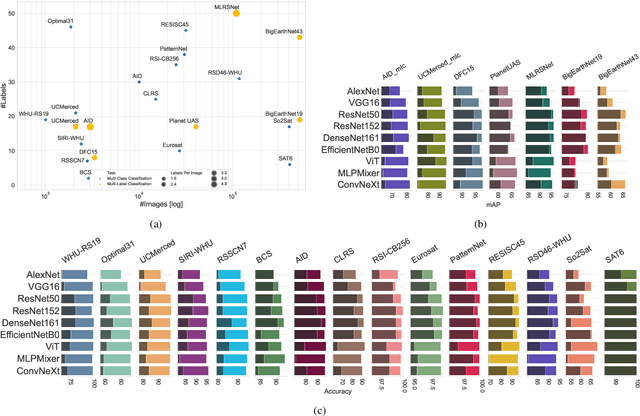
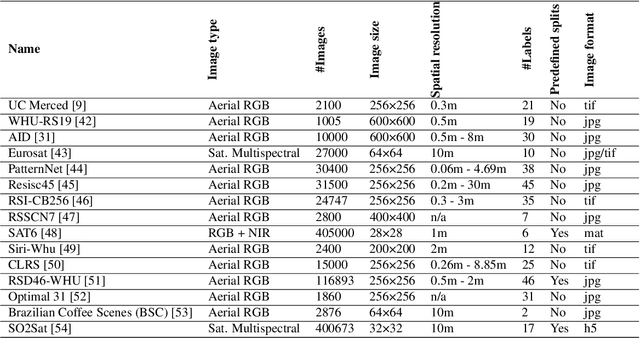
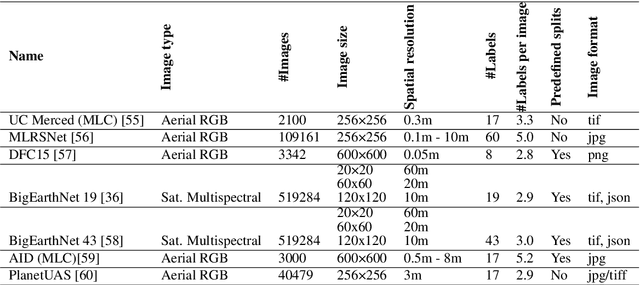
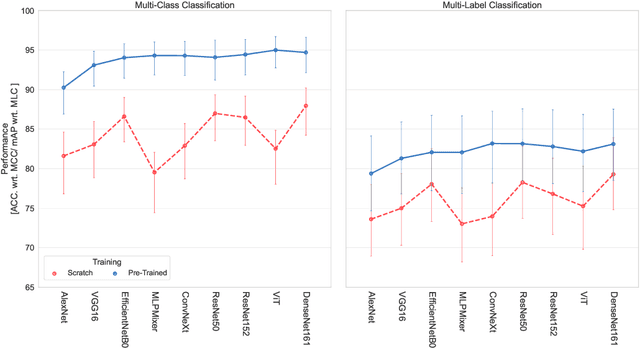
We present 'AiTLAS: Benchmark Arena' -- an open-source benchmark framework for evaluating state-of-the-art deep learning approaches for image classification in Earth Observation (EO). To this end, we present a comprehensive comparative analysis of more than 400 models derived from nine different state-of-the-art architectures, and compare them to a variety of multi-class and multi-label classification tasks from 22 datasets with different sizes and properties. In addition to models trained entirely on these datasets, we also benchmark models trained in the context of transfer learning, leveraging pre-trained model variants, as it is typically performed in practice. All presented approaches are general and can be easily extended to many other remote sensing image classification tasks not considered in this study. To ensure reproducibility and facilitate better usability and further developments, all of the experimental resources including the trained models, model configurations and processing details of the datasets (with their corresponding splits used for training and evaluating the models) are publicly available on the repository: https://github.com/biasvariancelabs/aitlas-arena.
Extremely Low-light Image Enhancement with Scene Text Restoration
Apr 01, 2022
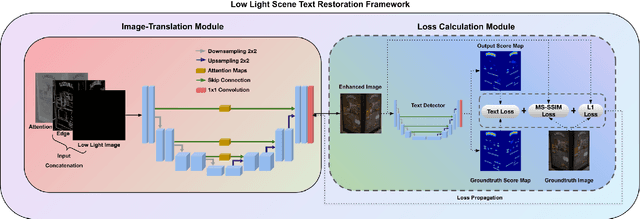


Deep learning-based methods have made impressive progress in enhancing extremely low-light images - the image quality of the reconstructed images has generally improved. However, we found out that most of these methods could not sufficiently recover the image details, for instance, the texts in the scene. In this paper, a novel image enhancement framework is proposed to precisely restore the scene texts, as well as the overall quality of the image simultaneously under extremely low-light images conditions. Mainly, we employed a self-regularised attention map, an edge map, and a novel text detection loss. In addition, leveraging synthetic low-light images is beneficial for image enhancement on the genuine ones in terms of text detection. The quantitative and qualitative experimental results have shown that the proposed model outperforms state-of-the-art methods in image restoration, text detection, and text spotting on See In the Dark and ICDAR15 datasets.
Generalization Differences between End-to-End and Neuro-Symbolic Vision-Language Reasoning Systems
Oct 26, 2022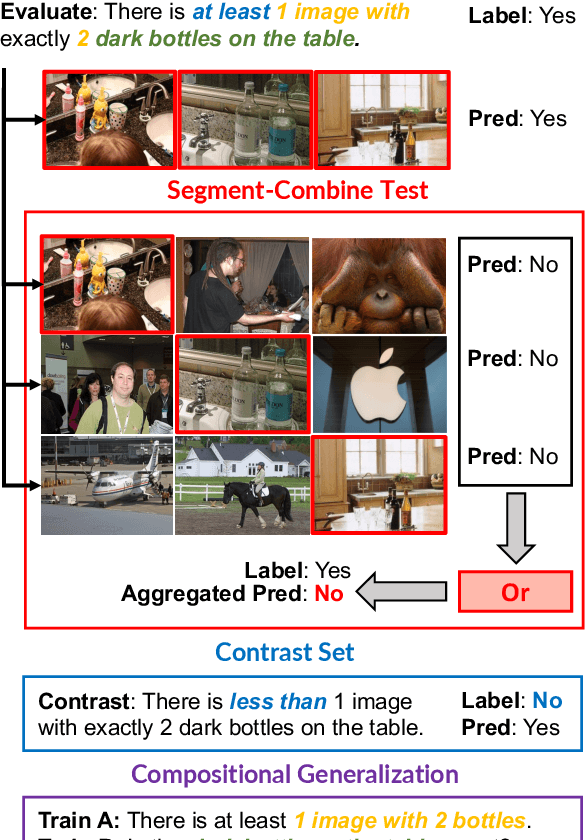

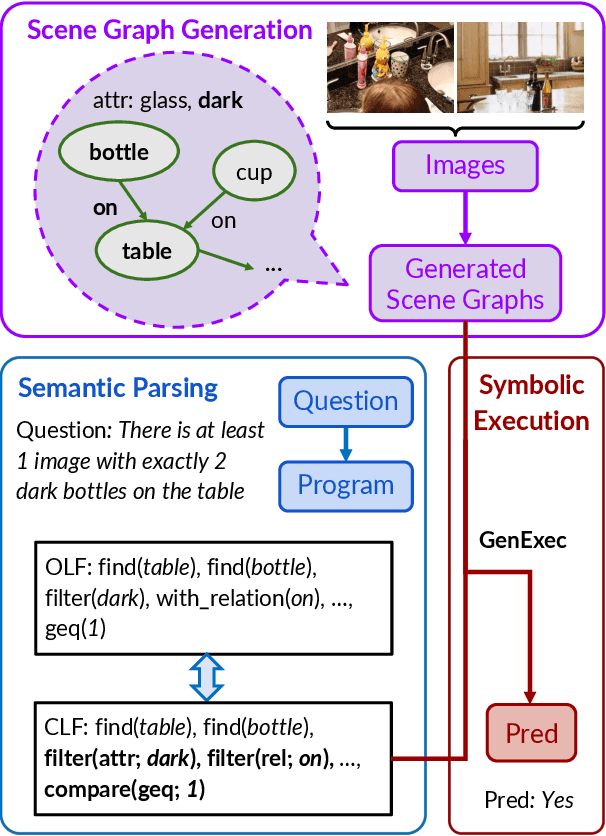

For vision-and-language reasoning tasks, both fully connectionist, end-to-end methods and hybrid, neuro-symbolic methods have achieved high in-distribution performance. In which out-of-distribution settings does each paradigm excel? We investigate this question on both single-image and multi-image visual question-answering through four types of generalization tests: a novel segment-combine test for multi-image queries, contrast set, compositional generalization, and cross-benchmark transfer. Vision-and-language end-to-end trained systems exhibit sizeable performance drops across all these tests. Neuro-symbolic methods suffer even more on cross-benchmark transfer from GQA to VQA, but they show smaller accuracy drops on the other generalization tests and their performance quickly improves by few-shot training. Overall, our results demonstrate the complementary benefits of these two paradigms, and emphasize the importance of using a diverse suite of generalization tests to fully characterize model robustness to distribution shift.
Image Coding for Machines with Omnipotent Feature Learning
Jul 07, 2022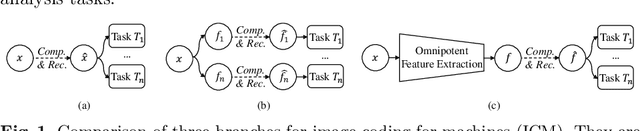


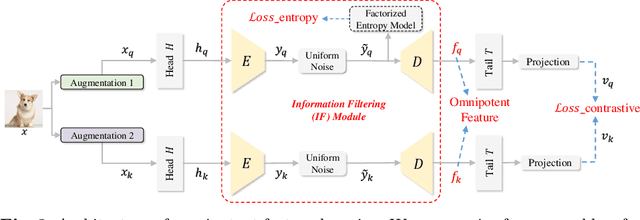
Image Coding for Machines (ICM) aims to compress images for AI tasks analysis rather than meeting human perception. Learning a kind of feature that is both general (for AI tasks) and compact (for compression) is pivotal for its success. In this paper, we attempt to develop an ICM framework by learning universal features while also considering compression. We name such features as omnipotent features and the corresponding framework as Omni-ICM. Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task into the Omni-ICM framework to learn omnipotent features. However, it is non-trivial to coordinate semantics modeling in SSL and redundancy removing in compression, so we design a novel information filtering (IF) module between them by co-optimization of instance distinguishment and entropy minimization to adaptively drop information that is weakly related to AI tasks (e.g., some texture redundancy). Different from previous task-specific solutions, Omni-ICM could directly support AI tasks analysis based on the learned omnipotent features without joint training or extra transformation. Albeit simple and intuitive, Omni-ICM significantly outperforms existing traditional and learning-based codecs on multiple fundamental vision tasks.
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
Dec 15, 2022Handwritten Text Recognition (HTR) is more interesting and challenging than printed text due to uneven variations in the handwriting style of the writers, content, and time. HTR becomes more challenging for the Indic languages because of (i) multiple characters combined to form conjuncts which increase the number of characters of respective languages, and (ii) near to 100 unique basic Unicode characters in each Indic script. Recently, many recognition methods based on the encoder-decoder framework have been proposed to handle such problems. They still face many challenges, such as image blur and incomplete characters due to varying writing styles and ink density. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we enhance the performance of Indic handwritten text recognizers using global semantic information. We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts. The semantic information is used in both the encoder for supervision and the decoder for initialization. The semantic information is predicted from the word embedding of a pre-trained language model. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art results on handwritten texts of ten Indic languages.