 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafer Trajectory Planning with CBF-guided Diffusion Model for Unmanned Aerial Vehicles
Apr 19, 2026Safe and agile trajectory planning is essential for autonomous systems, especially during complex aerobatic maneuvers. Motivated by the recent success of diffusion models in generative tasks, this paper introduces AeroTrajGen, a novel framework for diffusion-based trajectory generation that incorporates control barrier function (CBF)-guided sampling during inference, specifically designed for unmanned aerial vehicles (UAVs). The proposed CBF-guided sampling addresses two critical challenges: (1) mitigating the inherent unpredictability and potential safety violations of diffusion models, and (2) reducing reliance on extensively safety-verified training data. During the reverse diffusion process, CBF-based guidance ensures collision-free trajectories by seamlessly integrating safety constraint gradients with the diffusion model's score function. The model features an obstacle-aware diffusion transformer architecture with multi-modal conditioning, including trajectory history, obstacles, maneuver styles, and goal, enabling the generation of smooth, highly agile trajectories across 14 distinct aerobatic maneuvers. Trained on a dataset of 2,000 expert demonstrations, AeroTrajGen is rigorously evaluated in simulation under multi-obstacle environments. Simulation results demonstrate that CBF-guided sampling reduces collision rates by 94.7% compared to unguided diffusion baselines, while preserving trajectory agility and diversity. Our code is open-sourced at https://github.com/RoboticsPolyu/CBF-DMP.
Controllable Generative Video Compression
Apr 08, 2026Perceptual video compression adopts generative video modeling to improve perceptual realism but frequently sacrifices signal fidelity, diverging from the goal of video compression to faithfully reproduce visual signal. To alleviate the dilemma between perception and fidelity, in this paper we propose Controllable Generative Video Compression (CGVC) paradigm to faithfully generate details guided by multiple visual conditions. Under the paradigm, representative keyframes of the scene are coded and used to provide structural priors for non-keyframe generation. Dense per-frame control prior is additionally coded to better preserve finer structure and semantics of each non-keyframe. Guided by these priors, non-keyframes are reconstructed by controllable video generation model with temporal and content consistency. Furthermore, to accurately recover color information of the video, we develop a color-distance-guided keyframe selection algorithm to adaptively choose keyframes. Experimental results show CGVC outperforms previous perceptual video compression method in terms of both signal fidelity and perceptual quality.
Comp-X: On Defining an Interactive Learned Image Compression Paradigm With Expert-driven LLM Agent
Aug 21, 2025We present Comp-X, the first intelligently interactive image compression paradigm empowered by the impressive reasoning capability of large language model (LLM) agent. Notably, commonly used image codecs usually suffer from limited coding modes and rely on manual mode selection by engineers, making them unfriendly for unprofessional users. To overcome this, we advance the evolution of image coding paradigm by introducing three key innovations: (i) multi-functional coding framework, which unifies different coding modes of various objective/requirements, including human-machine perception, variable coding, and spatial bit allocation, into one framework. (ii) interactive coding agent, where we propose an augmented in-context learning method with coding expert feedback to teach the LLM agent how to understand the coding request, mode selection, and the use of the coding tools. (iii) IIC-bench, the first dedicated benchmark comprising diverse user requests and the corresponding annotations from coding experts, which is systematically designed for intelligently interactive image compression evaluation. Extensive experimental results demonstrate that our proposed Comp-X can understand the coding requests efficiently and achieve impressive textual interaction capability. Meanwhile, it can maintain comparable compression performance even with a single coding framework, providing a promising avenue for artificial general intelligence (AGI) in image compression.
Why Compress What You Can Generate? When GPT-4o Generation Ushers in Image Compression Fields
Apr 30, 2025The rapid development of AIGC foundation models has revolutionized the paradigm of image compression, which paves the way for the abandonment of most pixel-level transform and coding, compelling us to ask: why compress what you can generate if the AIGC foundation model is powerful enough to faithfully generate intricate structure and fine-grained details from nothing more than some compact descriptors, i.e., texts, or cues. Fortunately, recent GPT-4o image generation of OpenAI has achieved impressive cross-modality generation, editing, and design capabilities, which motivates us to answer the above question by exploring its potential in image compression fields. In this work, we investigate two typical compression paradigms: textual coding and multimodal coding (i.e., text + extremely low-resolution image), where all/most pixel-level information is generated instead of compressing via the advanced GPT-4o image generation function. The essential challenge lies in how to maintain semantic and structure consistency during the decoding process. To overcome this, we propose a structure raster-scan prompt engineering mechanism to transform the image into textual space, which is compressed as the condition of GPT-4o image generation. Extensive experiments have shown that the combination of our designed structural raster-scan prompts and GPT-4o's image generation function achieved the impressive performance compared with recent multimodal/generative image compression at ultra-low bitrate, further indicating the potential of AIGC generation in image compression fields.
UniMIC: Towards Universal Multi-modality Perceptual Image Compression
Dec 09, 2024



We present UniMIC, a universal multi-modality image compression framework, intending to unify the rate-distortion-perception (RDP) optimization for multiple image codecs simultaneously through excavating cross-modality generative priors. Unlike most existing works that need to design and optimize image codecs from scratch, our UniMIC introduces the visual codec repository, which incorporates amounts of representative image codecs and directly uses them as the basic codecs for various practical applications. Moreover, we propose multi-grained textual coding, where variable-length content prompt and compression prompt are designed and encoded to assist the perceptual reconstruction through the multi-modality conditional generation. In particular, a universal perception compensator is proposed to improve the perception quality of decoded images from all basic codecs at the decoder side by reusing text-assisted diffusion priors from stable diffusion. With the cooperation of the above three strategies, our UniMIC achieves a significant improvement of RDP optimization for different compression codecs, e.g., traditional and learnable codecs, and different compression costs, e.g., ultra-low bitrates. The code will be available in https://github.com/Amygyx/UniMIC .
Towards Defining an Efficient and Expandable File Format for AI-Generated Contents
Oct 15, 2024



Recently, AI-generated content (AIGC) has gained significant traction due to its powerful creation capability. However, the storage and transmission of large amounts of high-quality AIGC images inevitably pose new challenges for recent file formats. To overcome this, we define a new file format for AIGC images, named AIGIF, enabling ultra-low bitrate coding of AIGC images. Unlike compressing AIGC images intuitively with pixel-wise space as existing file formats, AIGIF instead compresses the generation syntax. This raises a crucial question: Which generation syntax elements, e.g., text prompt, device configuration, etc, are necessary for compression/transmission? To answer this question, we systematically investigate the effects of three essential factors: platform, generative model, and data configuration. We experimentally find that a well-designed composable bitstream structure incorporating the above three factors can achieve an impressive compression ratio of even up to 1/10,000 while still ensuring high fidelity. We also introduce an expandable syntax in AIGIF to support the extension of the most advanced generation models to be developed in the future.
Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression
May 12, 2023



Despite a short history, neural image codecs have been shown to surpass classical image codecs in terms of rate-distortion performance. However, most of them suffer from significantly longer decoding times, which hinders the practical applications of neural image codecs. This issue is especially pronounced when employing an effective yet time-consuming autoregressive context model since it would increase entropy decoding time by orders of magnitude. In this paper, unlike most previous works that pursue optimal RD performance while temporally overlooking the coding complexity, we make a systematical investigation on the rate-distortion-complexity (RDC) optimization in neural image compression. By quantifying the decoding complexity as a factor in the optimization goal, we are now able to precisely control the RDC trade-off and then demonstrate how the rate-distortion performance of neural image codecs could adapt to various complexity demands. Going beyond the investigation of RDC optimization, a variable-complexity neural codec is designed to leverage the spatial dependencies adaptively according to industrial demands, which supports fine-grained complexity adjustment by balancing the RDC tradeoff. By implementing this scheme in a powerful base model, we demonstrate the feasibility and flexibility of RDC optimization for neural image codecs.
Semantically Structured Image Compression via Irregular Group-Based Decoupling
May 04, 2023



Image compression techniques typically focus on compressing rectangular images for human consumption, however, resulting in transmitting redundant content for downstream applications. To overcome this limitation, some previous works propose to semantically structure the bitstream, which can meet specific application requirements by selective transmission and reconstruction. Nevertheless, they divide the input image into multiple rectangular regions according to semantics and ignore avoiding information interaction among them, causing waste of bitrate and distorted reconstruction of region boundaries. In this paper, we propose to decouple an image into multiple groups with irregular shapes based on a customized group mask and compress them independently. Our group mask describes the image at a finer granularity, enabling significant bitrate saving by reducing the transmission of redundant content. Moreover, to ensure the fidelity of selective reconstruction, this paper proposes the concept of group-independent transform that maintain the independence among distinct groups. And we instantiate it by the proposed Group-Independent Swin-Block (GI Swin-Block). Experimental results demonstrate that our framework structures the bitstream with negligible cost, and exhibits superior performance on both visual quality and intelligent task supporting.
Image Coding for Machines with Omnipotent Feature Learning
Jul 07, 2022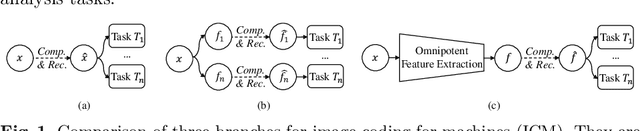


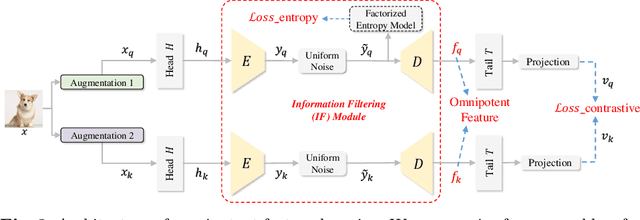
Image Coding for Machines (ICM) aims to compress images for AI tasks analysis rather than meeting human perception. Learning a kind of feature that is both general (for AI tasks) and compact (for compression) is pivotal for its success. In this paper, we attempt to develop an ICM framework by learning universal features while also considering compression. We name such features as omnipotent features and the corresponding framework as Omni-ICM. Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task into the Omni-ICM framework to learn omnipotent features. However, it is non-trivial to coordinate semantics modeling in SSL and redundancy removing in compression, so we design a novel information filtering (IF) module between them by co-optimization of instance distinguishment and entropy minimization to adaptively drop information that is weakly related to AI tasks (e.g., some texture redundancy). Different from previous task-specific solutions, Omni-ICM could directly support AI tasks analysis based on the learned omnipotent features without joint training or extra transformation. Albeit simple and intuitive, Omni-ICM significantly outperforms existing traditional and learning-based codecs on multiple fundamental vision tasks.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020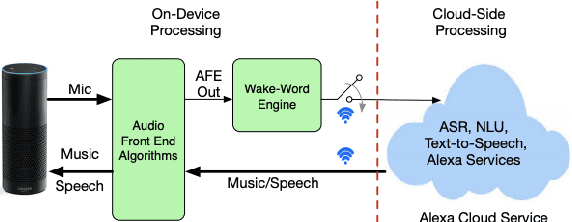
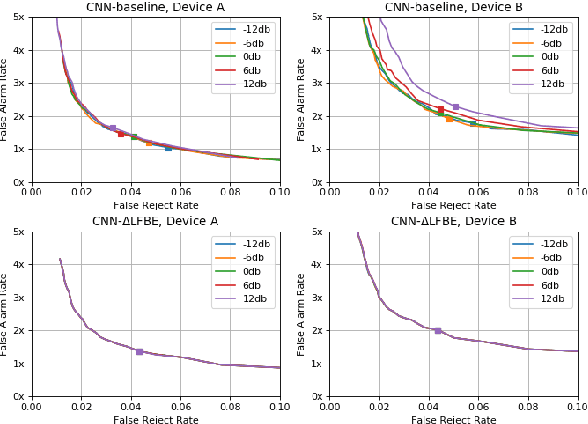
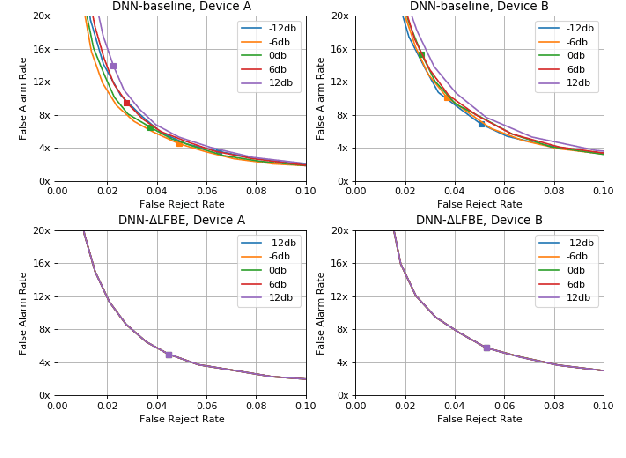
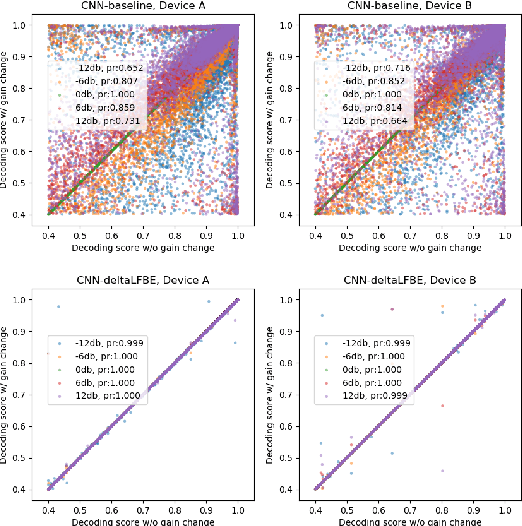
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.