 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometric Rectification of Creased Document Images based on Isometric Mapping
Dec 16, 2022
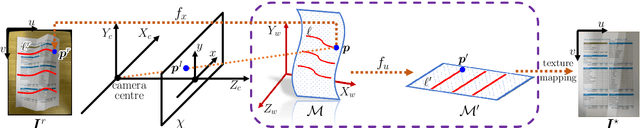

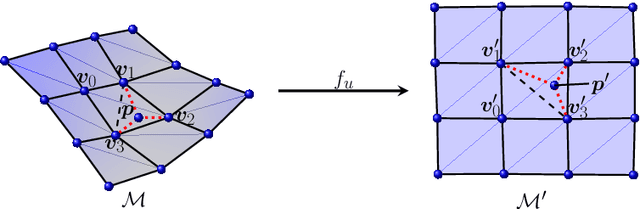
Geometric rectification of images of distorted documents finds wide applications in document digitization and Optical Character Recognition (OCR). Although smoothly curved deformations have been widely investigated by many works, the most challenging distortions, e.g. complex creases and large foldings, have not been studied in particular. The performance of existing approaches, when applied to largely creased or folded documents, is far from satisfying, leaving substantial room for improvement. To tackle this task, knowledge about document rectification should be incorporated into the computation, among which the developability of 3D document models and particular textural features in the images, such as straight lines, are the most essential ones. For this purpose, we propose a general framework of document image rectification in which a computational isometric mapping model is utilized for expressing a 3D document model and its flattening in the plane. Based on this framework, both model developability and textural features are considered in the computation. The experiments and comparisons to the state-of-the-art approaches demonstrated the effectiveness and outstanding performance of the proposed method. Our method is also flexible in that the rectification results can be enhanced by any other methods that extract high-quality feature lines in the images.
Feature Dropout: Revisiting the Role of Augmentations in Contrastive Learning
Dec 16, 2022


What role do augmentations play in contrastive learning? Recent work suggests that good augmentations are label-preserving with respect to a specific downstream task. We complicate this picture by showing that label-destroying augmentations can be useful in the foundation model setting, where the goal is to learn diverse, general-purpose representations for multiple downstream tasks. We perform contrastive learning experiments on a range of image and audio datasets with multiple downstream tasks (e.g. for digits superimposed on photographs, predicting the class of one vs. the other). We find that Viewmaker Networks, a recently proposed model for learning augmentations for contrastive learning, produce label-destroying augmentations that stochastically destroy features needed for different downstream tasks. These augmentations are interpretable (e.g. altering shapes, digits, or letters added to images) and surprisingly often result in better performance compared to expert-designed augmentations, despite not preserving label information. To support our empirical results, we theoretically analyze a simple contrastive learning setting with a linear model. In this setting, label-destroying augmentations are crucial for preventing one set of features from suppressing the learning of features useful for another downstream task. Our results highlight the need for analyzing the interaction between multiple downstream tasks when trying to explain the success of foundation models.
Adaptive Fine-Grained Sketch-Based Image Retrieval
Jul 06, 2022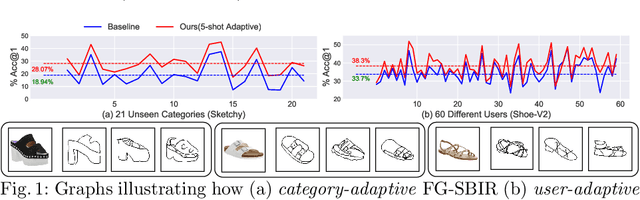
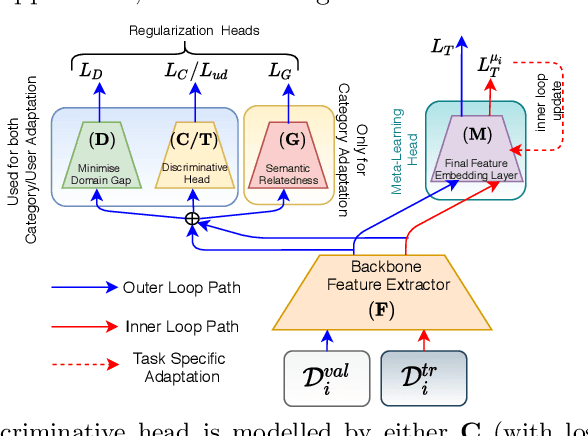
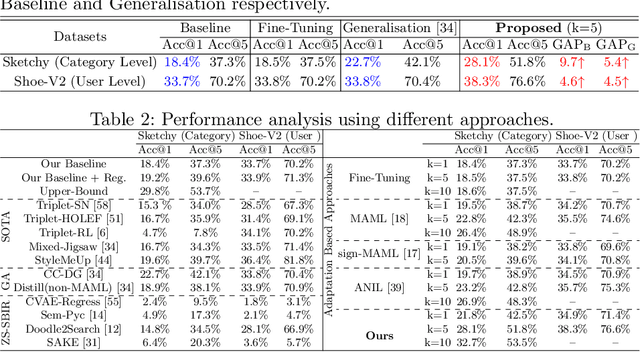
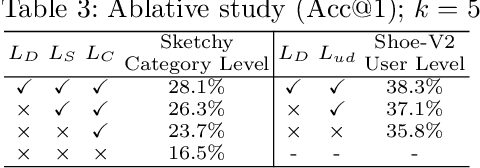
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted towards generalising a model to new categories without any training data from them. In real-world applications, however, a trained FG-SBIR model is often applied to both new categories and different human sketchers, i.e., different drawing styles. Although this complicates the generalisation problem, fortunately, a handful of examples are typically available, enabling the model to adapt to the new category/style. In this paper, we offer a novel perspective -- instead of asking for a model that generalises, we advocate for one that quickly adapts, with just very few samples during testing (in a few-shot manner). To solve this new problem, we introduce a novel model-agnostic meta-learning (MAML) based framework with several key modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the MAML training in the inner loop to make it more stable and tractable. (2) The margin in our contrastive loss is also meta-learned with the rest of the model. (3) Three additional regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR model more effective for category/style adaptation. Extensive experiments on public datasets suggest a large gain over generalisation and zero-shot based approaches, and a few strong few-shot baselines.
This changes to that : Combining causal and non-causal explanations to generate disease progression in capsule endoscopy
Dec 05, 2022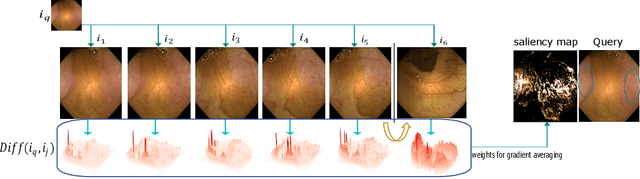
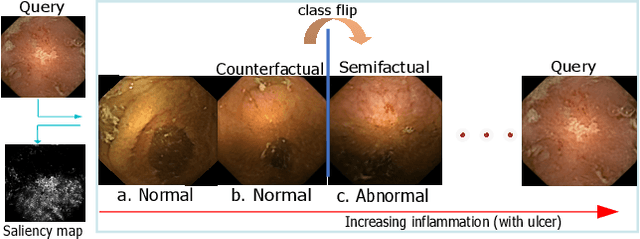
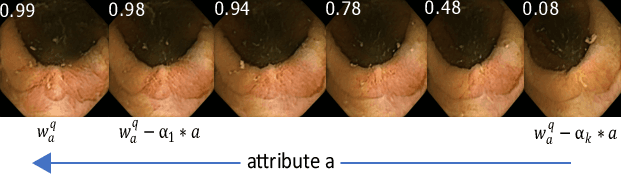
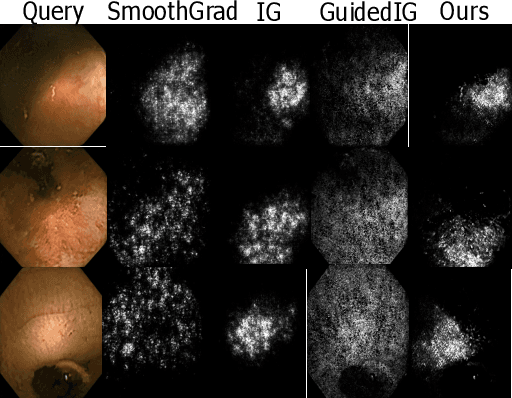
Due to the unequivocal need for understanding the decision processes of deep learning networks, both modal-dependent and model-agnostic techniques have become very popular. Although both of these ideas provide transparency for automated decision making, most methodologies focus on either using the modal-gradients (model-dependent) or ignoring the model internal states and reasoning with a model's behavior/outcome (model-agnostic) to instances. In this work, we propose a unified explanation approach that given an instance combines both model-dependent and agnostic explanations to produce an explanation set. The generated explanations are not only consistent in the neighborhood of a sample but can highlight causal relationships between image content and the outcome. We use Wireless Capsule Endoscopy (WCE) domain to illustrate the effectiveness of our explanations. The saliency maps generated by our approach are comparable or better on the softmax information score.
SBPF: Sensitiveness Based Pruning Framework For Convolutional Neural Network On Image Classification
Aug 09, 2022



Pruning techniques are used comprehensively to compress convolutional neural networks (CNNs) on image classification. However, the majority of pruning methods require a well pre-trained model to provide useful supporting parameters, such as C1-norm, BatchNorm value and gradient information, which may lead to inconsistency of filter evaluation if the parameters of the pre-trained model are not well optimized. Therefore, we propose a sensitiveness based method to evaluate the importance of each layer from the perspective of inference accuracy by adding extra damage for the original model. Because the performance of the accuracy is determined by the distribution of parameters across all layers rather than individual parameter, the sensitiveness based method will be robust to update of parameters. Namely, we can obtain similar importance evaluation of each convolutional layer between the imperfect-trained and fully trained models. For VGG-16 on CIFAR-10, even when the original model is only trained with 50 epochs, we can get same evaluation of layer importance as the results when the model is trained fully. Then we will remove filters proportional from each layer by the quantified sensitiveness. Our sensitiveness based pruning framework is verified efficiently on VGG-16, a customized Conv-4 and ResNet-18 with CIFAR-10, MNIST and CIFAR-100, respectively.
Image Super-Resolution With Deep Variational Autoencoders
Mar 17, 2022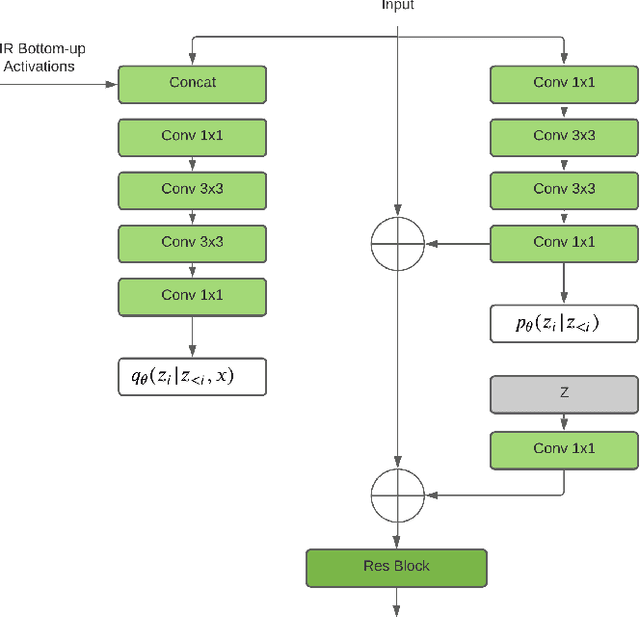
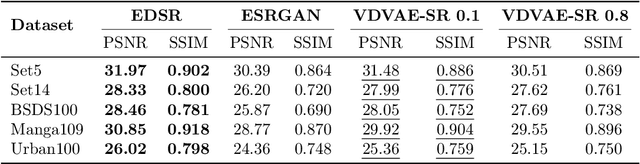
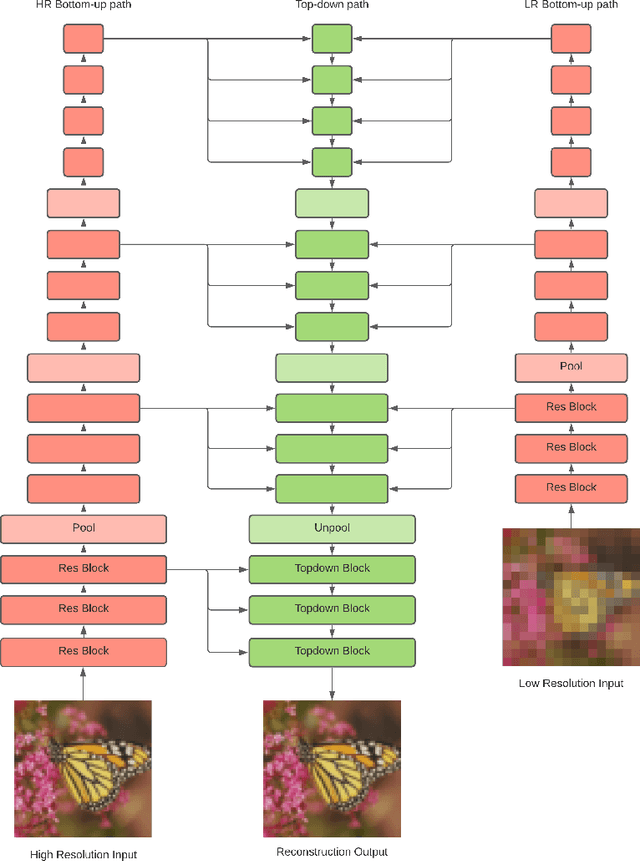
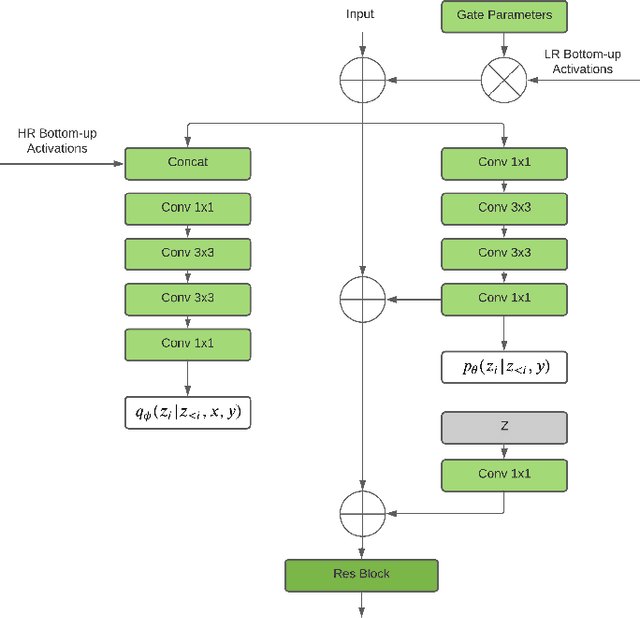
Image super-resolution (SR) techniques are used to generate a high-resolution image from a low-resolution image. Until now, deep generative models such as autoregressive models and Generative Adversarial Networks (GANs) have proven to be effective at modelling high-resolution images. Models based on Variational Autoencoders (VAEs) have often been criticized for their feeble generative performance, but with new advancements such as VDVAE (very deep VAE), there is now strong evidence that deep VAEs have the potential to outperform current state-of-the-art models for high-resolution image generation. In this paper, we introduce VDVAE-SR, a new model that aims to exploit the most recent deep VAE methodologies to improve upon image super-resolution using transfer learning on pretrained VDVAEs. Through qualitative and quantitative evaluations, we show that the proposed model is competitive with other state-of-the-art methods.
Underwater Image Enhancement Using Pre-trained Transformer
Apr 08, 2022
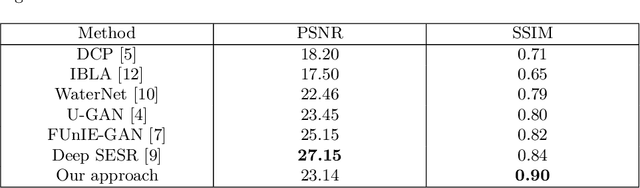
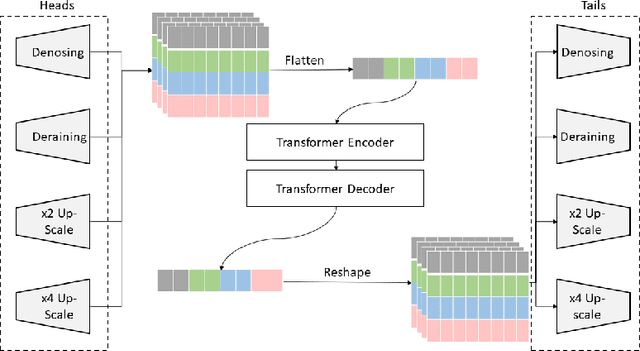
The goal of this work is to apply a denoising image transformer to remove the distortion from underwater images and compare it with other similar approaches. Automatic restoration of underwater images plays an important role since it allows to increase the quality of the images, without the need for more expensive equipment. This is a critical example of the important role of the machine learning algorithms to support marine exploration and monitoring, reducing the need for human intervention like the manual processing of the images, thus saving time, effort, and cost. This paper is the first application of the image transformer-based approach called "Pre-Trained Image Processing Transformer" to underwater images. This approach is tested on the UFO-120 dataset, containing 1500 images with the corresponding clean images.
Morphological adjunctions represented by matrices in max-plus algebra for signal and image processing
Jul 28, 2022In discrete signal and image processing, many dilations and erosions can be written as the max-plus and min-plus product of a matrix on a vector. Previous studies considered operators on symmetrical, unbounded complete lattices, such as Cartesian powers of the completed real line. This paper focuses on adjunctions on closed hypercubes, which are the complete lattices used in practice to represent digital signals and images. We show that this constrains the representing matrices to be doubly-0-astic and we characterise the adjunctions that can be represented by them. A graph interpretation of the defined operators naturally arises from the adjacency relationship encoded by the matrices, as well as a max-plus spectral interpretation.
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022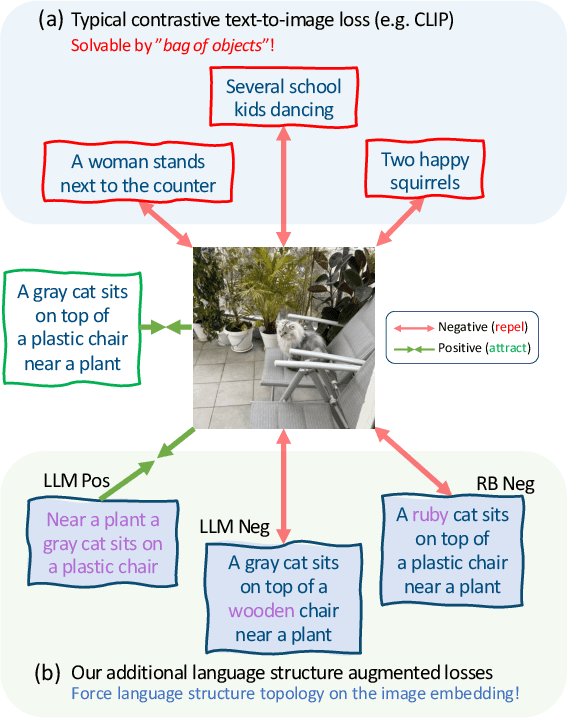
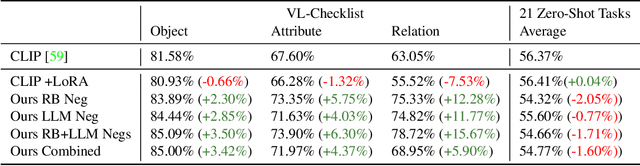
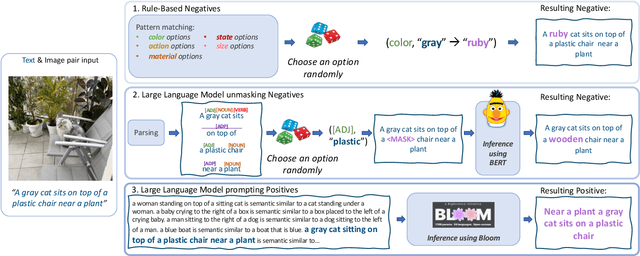

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
Learning Implicit Probability Distribution Functions for Symmetric Orientation Estimation from RGB Images Without Pose Labels
Nov 21, 2022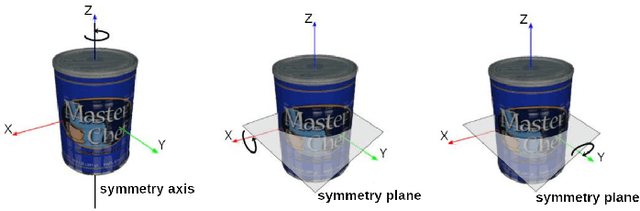
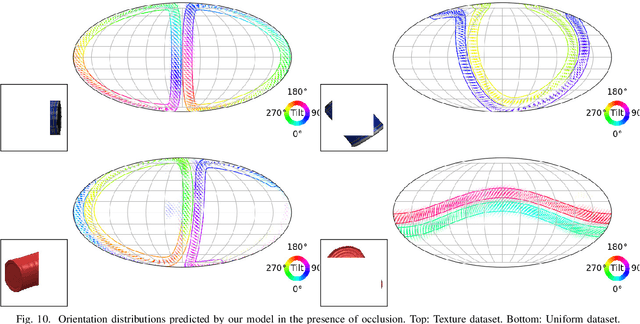
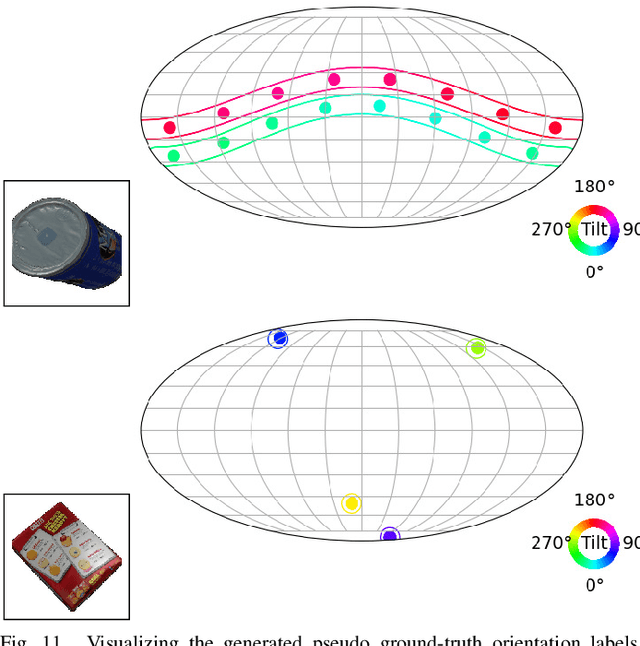

Object pose estimation is a necessary prerequisite for autonomous robotic manipulation, but the presence of symmetry increases the complexity of the pose estimation task. Existing methods for object pose estimation output a single 6D pose. Thus, they lack the ability to reason about symmetries. Lately, modeling object orientation as a non-parametric probability distribution on the SO(3) manifold by neural networks has shown impressive results. However, acquiring large-scale datasets to train pose estimation models remains a bottleneck. To address this limitation, we introduce an automatic pose labeling scheme. Given RGB-D images without object pose annotations and 3D object models, we design a two-stage pipeline consisting of point cloud registration and render-and-compare validation to generate multiple symmetrical pseudo-ground-truth pose labels for each image. Using the generated pose labels, we train an ImplicitPDF model to estimate the likelihood of an orientation hypothesis given an RGB image. An efficient hierarchical sampling of the SO(3) manifold enables tractable generation of the complete set of symmetries at multiple resolutions. During inference, the most likely orientation of the target object is estimated using gradient ascent. We evaluate the proposed automatic pose labeling scheme and the ImplicitPDF model on a photorealistic dataset and the T-Less dataset, demonstrating the advantages of the proposed method.