 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCropVLM: A Domain-Adapted Vision-Language Model for Open-Set Crop Analysis
May 05, 2026High-throughput plant phenotyping, the quantitative measurement of observable plant traits, is critical for modern breeding but remains constrained by a "phenotyping bottleneck," where manual data collection is labor-intensive and prone to observer bias. Conventional closed-set computer vision systems fail to address this challenge, as they require extensive species-specific annotation and lack the flexibility to handle diverse breeding populations. To bridge this gap, we present CropVLM, a Vision-Language Model (VLM) adapted for the agricultural domain via Domain-Specific Semantic Alignment (DSSA). Trained on 52,987 manually selected image-caption pairs covering 37 species in natural field conditions, CropVLM effectively maps agronomic terminology to fine-grained visual features. We further introduce the Hybrid Open-Set Localization Network (HOS-Net), an architecture that integrates CropVLM to enable the detection of novel crops solely from natural language descriptions without retraining. By eliminating the reliance on species-specific training data, CropVLM provides a scalable solution for high-throughput phenotyping, accelerating genetic gain and facilitating large-scale biodiversity research essential for sustainable agriculture. The trained model weights and complete pipeline implementation are publicly available at: [https://github.com/boudiafA/CropVLM](https://github.com/boudiafA/CropVLM). In comprehensive evaluations, CropVLM achieves 72.51% zero-shot classification accuracy, outperforming seven CLIP-style baselines. Our detection pipeline demonstrates superior zero-shot generalization to novel species, achieving 49.17 AP50 on our CVTCropDet benchmark and 50.73 AP50 on tropical fruit species, compared to 34.89 and 48.58 for the next-best method, respectively.
AgriChat: A Multimodal Large Language Model for Agriculture Image Understanding
Mar 14, 2026The deployment of Multimodal Large Language Models (MLLMs) in agriculture is currently stalled by a critical trade-off: the existing literature lacks the large-scale agricultural datasets required for robust model development and evaluation, while current state-of-the-art models lack the verified domain expertise necessary to reason across diverse taxonomies. To address these challenges, we propose the Vision-to-Verified-Knowledge (V2VK) pipeline, a novel generative AI-driven annotation framework that integrates visual captioning with web-augmented scientific retrieval to autonomously generate the AgriMM benchmark, effectively eliminating biological hallucinations by grounding training data in verified phytopathological literature. The AgriMM benchmark contains over 3,000 agricultural classes and more than 607k VQAs spanning multiple tasks, including fine-grained plant species identification, plant disease symptom recognition, crop counting, and ripeness assessment. Leveraging this verifiable data, we present AgriChat, a specialized MLLM that presents broad knowledge across thousands of agricultural classes and provides detailed agricultural assessments with extensive explanations. Extensive evaluation across diverse tasks, datasets, and evaluation conditions reveals both the capabilities and limitations of current agricultural MLLMs, while demonstrating AgriChat's superior performance over other open-source models, including internal and external benchmarks. The results validate that preserving visual detail combined with web-verified knowledge constitutes a reliable pathway toward robust and trustworthy agricultural AI. The code and dataset are publicly available at https://github.com/boudiafA/AgriChat .
Underwater Image Enhancement Using Pre-trained Transformer
Apr 08, 2022
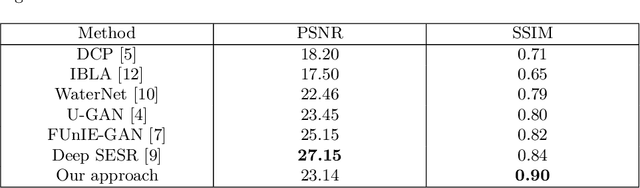
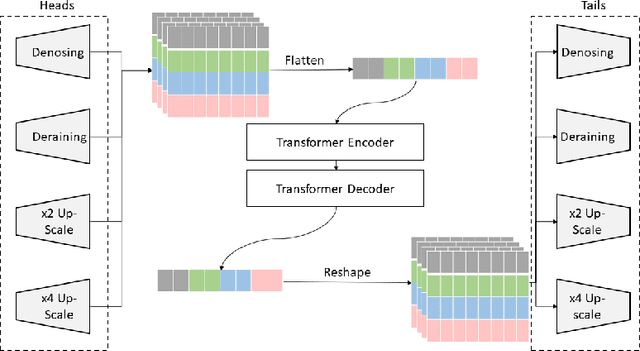
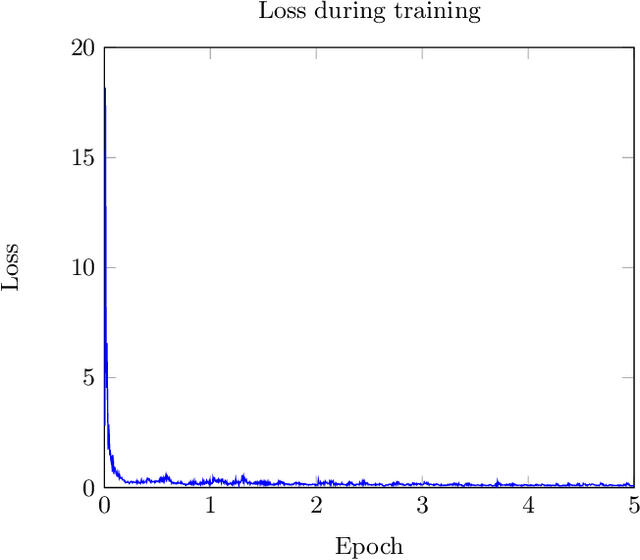
The goal of this work is to apply a denoising image transformer to remove the distortion from underwater images and compare it with other similar approaches. Automatic restoration of underwater images plays an important role since it allows to increase the quality of the images, without the need for more expensive equipment. This is a critical example of the important role of the machine learning algorithms to support marine exploration and monitoring, reducing the need for human intervention like the manual processing of the images, thus saving time, effort, and cost. This paper is the first application of the image transformer-based approach called "Pre-Trained Image Processing Transformer" to underwater images. This approach is tested on the UFO-120 dataset, containing 1500 images with the corresponding clean images.