 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative Models for High-Resolution Range Profiles: Capturing Geometry-Driven Trends in a Large-Scale Maritime Dataset
Feb 09, 2026High-resolution range profiles (HRRPs) enable fast onboard processing for radar automatic target recognition, but their strong sensitivity to acquisition conditions limits robustness across operational scenarios. Conditional HRRP generation can mitigate this issue, yet prior studies are constrained by small, highly specific datasets. We study HRRP synthesis on a largescale maritime database representative of coastal surveillance variability. Our analysis indicates that the fundamental scenario drivers are geometric: ship dimensions and the desired aspect angle. Conditioning on these variables, we train generative models and show that the synthesized signatures reproduce the expected line-of-sight geometric trend observed in real data. These results highlight the central role of acquisition geometry for robust HRRP generation.
MFN Decomposition and Related Metrics for High-Resolution Range Profiles Generative Models
Feb 09, 2026High-resolution range profile (HRRP ) data are in vogue in radar automatic target recognition (RATR). With the interest in classifying models using HRRP, filling gaps in datasets using generative models has recently received promising contributions. Evaluating generated data is a challenging topic, even for explicit data like face images. However, the evaluation methods used in the state-ofthe-art of HRRP generation rely on classification models. Such models, called ''black-box'', do not allow either explainability on generated data or multi-level evaluation. This work focuses on decomposing HRRP data into three components: the mask, the features, and the noise. Using this decomposition, we propose two metrics based on the physical interpretation of those data. We take profit from an expensive dataset to evaluate our metrics on a challenging task and demonstrate the discriminative ability of those.
LmPT: Conditional Point Transformer for Anatomical Landmark Detection on 3D Point Clouds
Feb 02, 2026Accurate identification of anatomical landmarks is crucial for various medical applications. Traditional manual landmarking is time-consuming and prone to inter-observer variability, while rule-based methods are often tailored to specific geometries or limited sets of landmarks. In recent years, anatomical surfaces have been effectively represented as point clouds, which are lightweight structures composed of spatial coordinates. Following this strategy and to overcome the limitations of existing landmarking techniques, we propose Landmark Point Transformer (LmPT), a method for automatic anatomical landmark detection on point clouds that can leverage homologous bones from different species for translational research. The LmPT model incorporates a conditioning mechanism that enables adaptability to different input types to conduct cross-species learning. We focus the evaluation of our approach on femoral landmarking using both human and newly annotated dog femurs, demonstrating its generalization and effectiveness across species. The code and dog femur dataset will be publicly available at: https://github.com/Pierreoo/LandmarkPointTransformer.
* This paper has been accepted at International Symposium on Biomedical Imaging (ISBI) 2026
Adapting the Hypersphere Loss Function from Anomaly Detection to Anomaly Segmentation
Jan 23, 2023


We propose an incremental improvement to Fully Convolutional Data Description (FCDD), an adaptation of the one-class classification approach from anomaly detection to image anomaly segmentation (a.k.a. anomaly localization). We analyze its original loss function and propose a substitute that better resembles its predecessor, the Hypersphere Classifier (HSC). Both are compared on the MVTec Anomaly Detection Dataset (MVTec-AD) -- training images are flawless objects/textures and the goal is to segment unseen defects -- showing that consistent improvement is achieved by better designing the pixel-wise supervision.
Moving Frame Net: SE-Equivariant Network for Volumes
Nov 07, 2022



Equivariance of neural networks to transformations helps to improve their performance and reduce generalization error in computer vision tasks, as they apply to datasets presenting symmetries (e.g. scalings, rotations, translations). The method of moving frames is classical for deriving operators invariant to the action of a Lie group in a manifold.Recently, a rotation and translation equivariant neural network for image data was proposed based on the moving frames approach. In this paper we significantly improve that approach by reducing the computation of moving frames to only one, at the input stage, instead of repeated computations at each layer. The equivariance of the resulting architecture is proved theoretically and we build a rotation and translation equivariant neural network to process volumes, i.e. signals on the 3D space. Our trained model overperforms the benchmarks in the medical volume classification of most of the tested datasets from MedMNIST3D.
Scale Equivariant U-Net
Oct 10, 2022

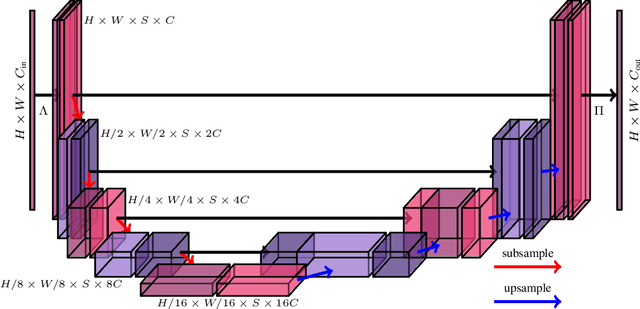
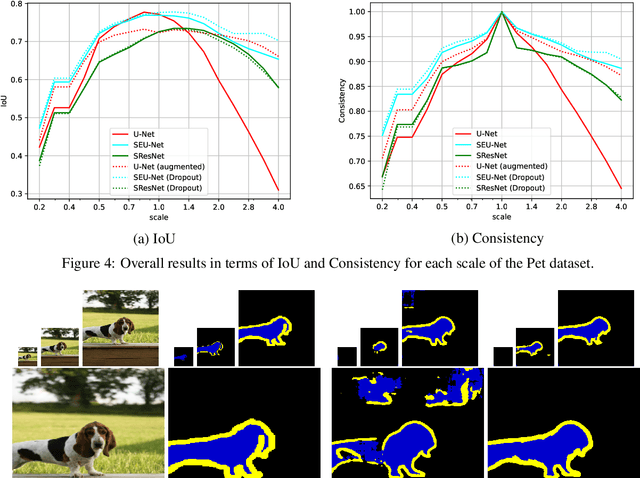
In neural networks, the property of being equivariant to transformations improves generalization when the corresponding symmetry is present in the data. In particular, scale-equivariant networks are suited to computer vision tasks where the same classes of objects appear at different scales, like in most semantic segmentation tasks. Recently, convolutional layers equivariant to a semigroup of scalings and translations have been proposed. However, the equivariance of subsampling and upsampling has never been explicitly studied even though they are necessary building blocks in some segmentation architectures. The U-Net is a representative example of such architectures, which includes the basic elements used for state-of-the-art semantic segmentation. Therefore, this paper introduces the Scale Equivariant U-Net (SEU-Net), a U-Net that is made approximately equivariant to a semigroup of scales and translations through careful application of subsampling and upsampling layers and the use of aforementioned scale-equivariant layers. Moreover, a scale-dropout is proposed in order to improve generalization to different scales in approximately scale-equivariant architectures. The proposed SEU-Net is trained for semantic segmentation of the Oxford Pet IIIT and the DIC-C2DH-HeLa dataset for cell segmentation. The generalization metric to unseen scales is dramatically improved in comparison to the U-Net, even when the U-Net is trained with scale jittering, and to a scale-equivariant architecture that does not perform upsampling operators inside the equivariant pipeline. The scale-dropout induces better generalization on the scale-equivariant models in the Pet experiment, but not on the cell segmentation experiment.
Morphological adjunctions represented by matrices in max-plus algebra for signal and image processing
Jul 28, 2022In discrete signal and image processing, many dilations and erosions can be written as the max-plus and min-plus product of a matrix on a vector. Previous studies considered operators on symmetrical, unbounded complete lattices, such as Cartesian powers of the completed real line. This paper focuses on adjunctions on closed hypercubes, which are the complete lattices used in practice to represent digital signals and images. We show that this constrains the representing matrices to be doubly-0-astic and we characterise the adjunctions that can be represented by them. A graph interpretation of the defined operators naturally arises from the adjacency relationship encoded by the matrices, as well as a max-plus spectral interpretation.
Fully trainable Gaussian derivative convolutional layer
Jul 18, 2022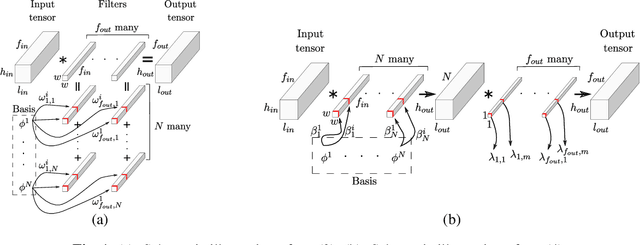
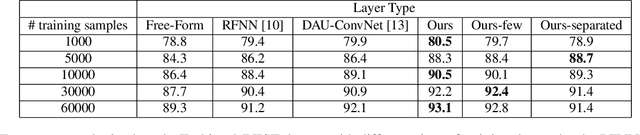

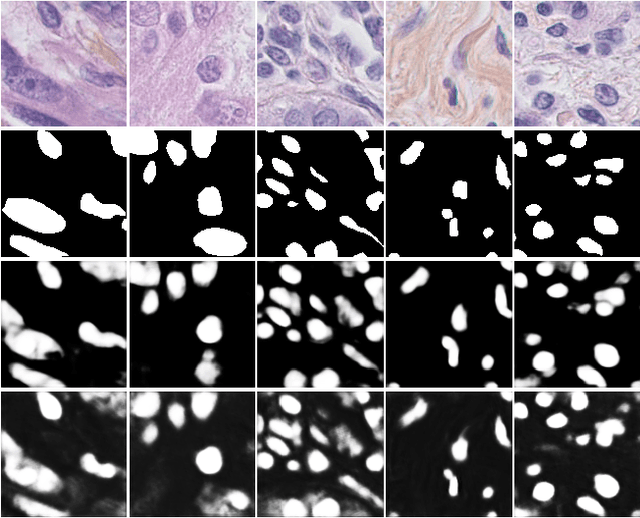
The Gaussian kernel and its derivatives have already been employed for Convolutional Neural Networks in several previous works. Most of these papers proposed to compute filters by linearly combining one or several bases of fixed or slightly trainable Gaussian kernels with or without their derivatives. In this article, we propose a high-level configurable layer based on anisotropic, oriented and shifted Gaussian derivative kernels which generalize notions encountered in previous related works while keeping their main advantage. The results show that the proposed layer has competitive performance compared to previous works and that it can be successfully included in common deep architectures such as VGG16 for image classification and U-net for image segmentation.
MorphoActivation: Generalizing ReLU activation function by mathematical morphology
Jul 13, 2022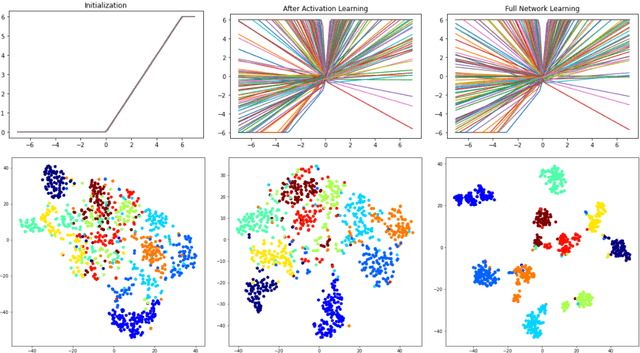
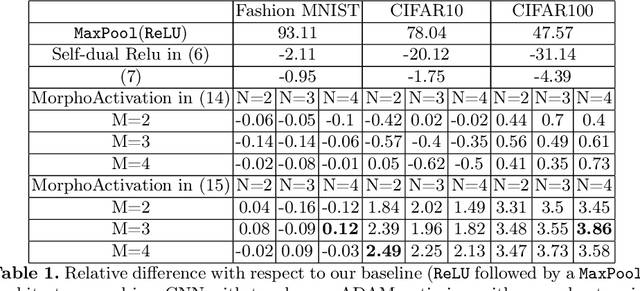
This paper analyses both nonlinear activation functions and spatial max-pooling for Deep Convolutional Neural Networks (DCNNs) by means of the algebraic basis of mathematical morphology. Additionally, a general family of activation functions is proposed by considering both max-pooling and nonlinear operators in the context of morphological representations. Experimental section validates the goodness of our approach on classical benchmarks for supervised learning by DCNN.
Differential invariants for SE(2)-equivariant networks
Jun 27, 2022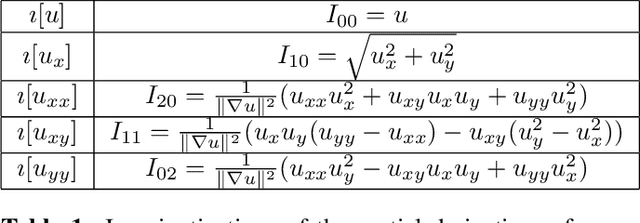
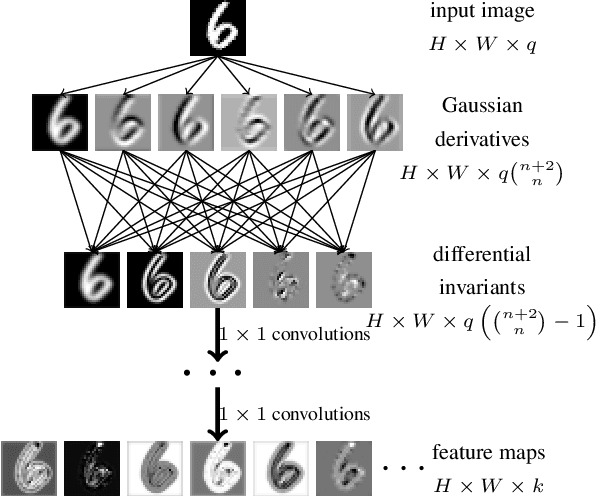
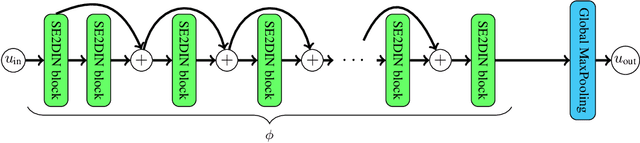
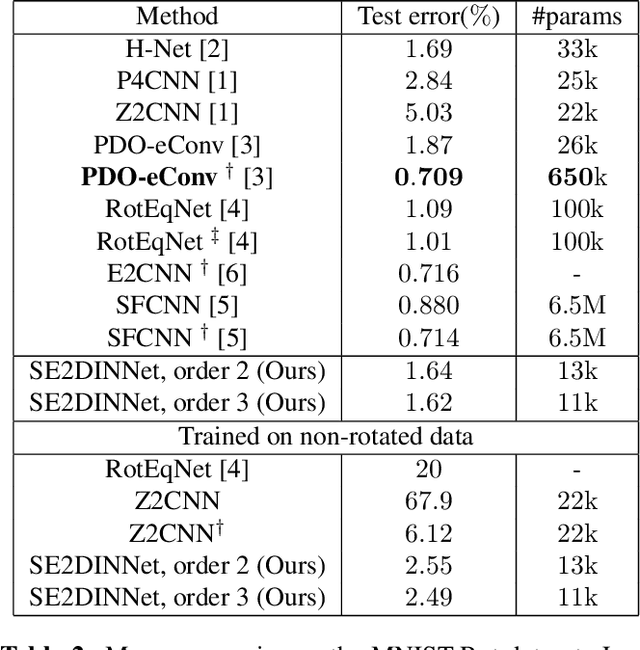
Symmetry is present in many tasks in computer vision, where the same class of objects can appear transformed, e.g. rotated due to different camera orientations, or scaled due to perspective. The knowledge of such symmetries in data coupled with equivariance of neural networks can improve their generalization to new samples. Differential invariants are equivariant operators computed from the partial derivatives of a function. In this paper we use differential invariants to define equivariant operators that form the layers of an equivariant neural network. Specifically, we derive invariants of the Special Euclidean Group SE(2), composed of rotations and translations, and apply them to construct a SE(2)-equivariant network, called SE(2) Differential Invariants Network (SE2DINNet). The network is subsequently tested in classification tasks which require a degree of equivariance or invariance to rotations. The results compare positively with the state-of-the-art, even though the proposed SE2DINNet has far less parameters than the compared models.