 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predictive Coding Based Multiscale Network with Encoder-Decoder LSTM for Video Prediction
Dec 30, 2022
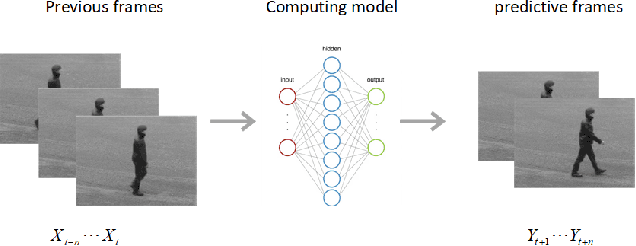
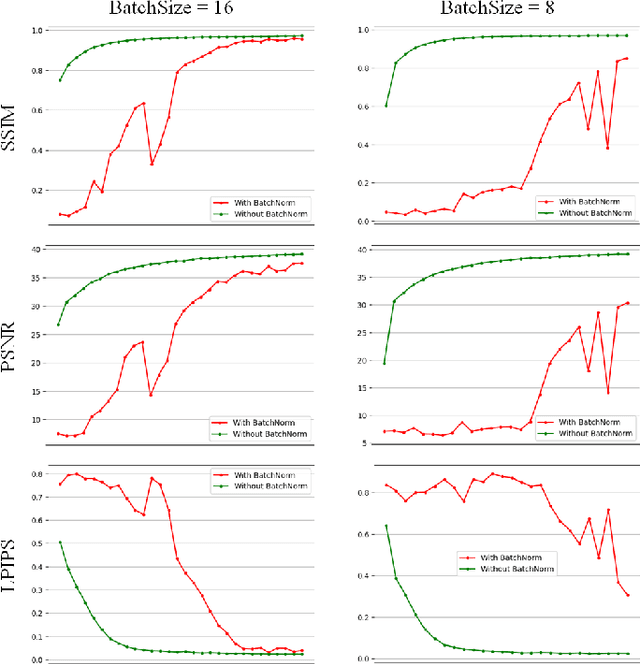
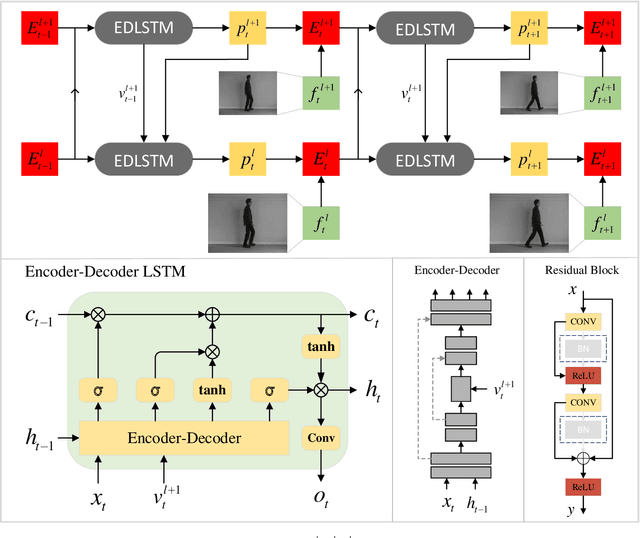
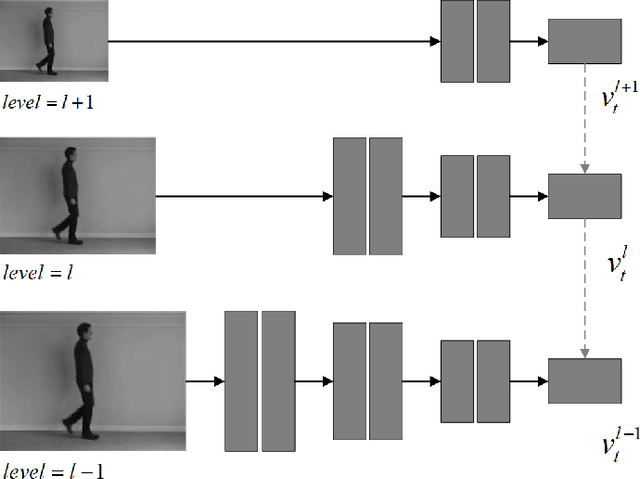
We are introducing a multi-scale predictive model for video prediction here, whose design is inspired by the "Predictive Coding" theories and "Coarse to Fine" approach. As a predictive coding model, it is updated by a combination of bottom-up and top-down information flows, which is different from traditional bottom-up training style. Its advantage is to reduce the dependence on input information and improve its ability to predict and generate images. Importantly, we achieve with a multi-scale approach -- higher level neurons generate coarser predictions (lower resolution), while the lower level generate finer predictions (higher resolution). This is different from the traditional predictive coding framework in which higher level predict the activity of neurons in lower level. To improve the predictive ability, we integrate an encoder-decoder network in the LSTM architecture and share the final encoded high-level semantic information between different levels. Additionally, since the output of each network level is an RGB image, a smaller LSTM hidden state can be used to retain and update the only necessary hidden information, avoiding being mapped to an overly discrete and complex space. In this way, we can reduce the difficulty of prediction and the computational overhead. Finally, we further explore the training strategies, to address the instability in adversarial training and mismatch between training and testing in long-term prediction. Code is available at https://github.com/Ling-CF/MSPN.
Morphology-based non-rigid registration of coronary computed tomography and intravascular images through virtual catheter path optimization
Dec 30, 2022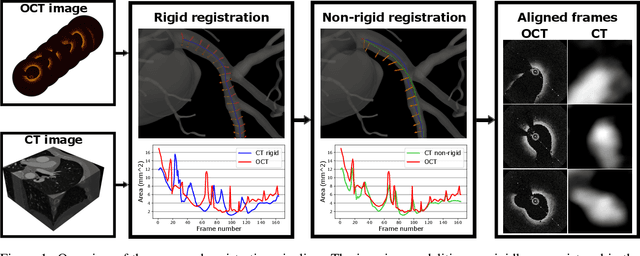

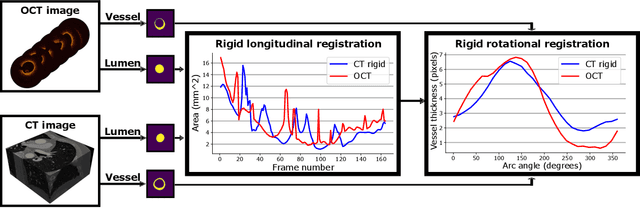
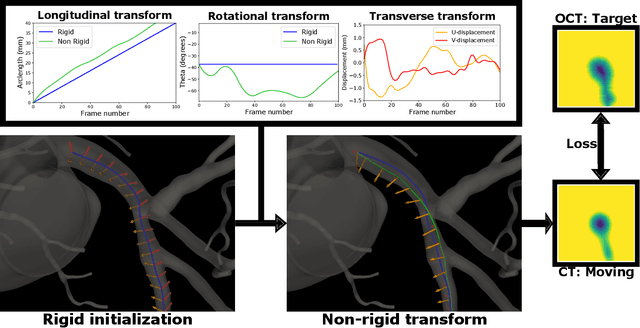
Coronary Computed Tomography Angiography (CCTA) provides information on the presence, extent, and severity of obstructive coronary artery disease. Large-scale clinical studies analyzing CCTA-derived metrics typically require ground-truth validation in the form of high-fidelity 3D intravascular imaging. However, manual rigid alignment of intravascular images to corresponding CCTA images is both time consuming and user-dependent. Moreover, intravascular modalities suffer from several non-rigid motion-induced distortions arising from distortions in the imaging catheter path. To address these issues, we here present a semi-automatic segmentation-based framework for both rigid and non-rigid matching of intravascular images to CCTA images. We formulate the problem in terms of finding the optimal \emph{virtual catheter path} that samples the CCTA data to recapitulate the coronary artery morphology found in the intravascular image. We validate our co-registration framework on a cohort of $n=40$ patients using bifurcation landmarks as ground truth for longitudinal and rotational registration. Our results indicate that our non-rigid registration significantly outperforms other co-registration approaches for luminal bifurcation alignment in both longitudinal (mean mismatch: 3.3 frames) and rotational directions (mean mismatch: 28.6 degrees). By providing a differentiable framework for automatic multi-modal intravascular data fusion, our developed co-registration modules significantly reduces the manual effort required to conduct large-scale multi-modal clinical studies while also providing a solid foundation for the development of machine learning-based co-registration approaches.
When CNN Meet with ViT: Towards Semi-Supervised Learning for Multi-Class Medical Image Semantic Segmentation
Aug 12, 2022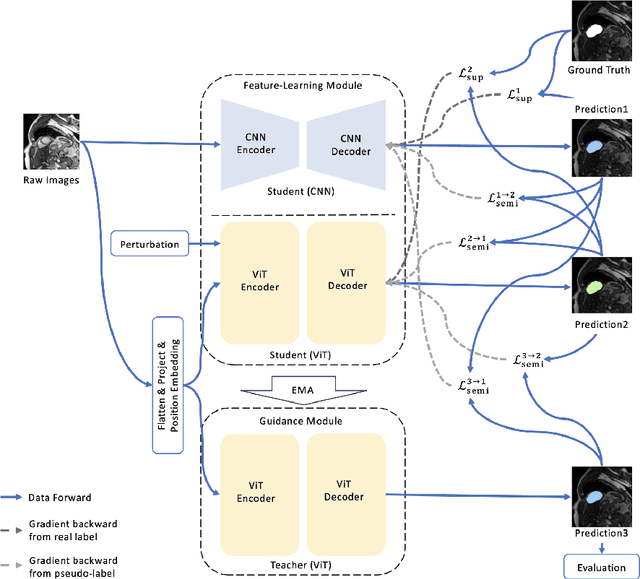
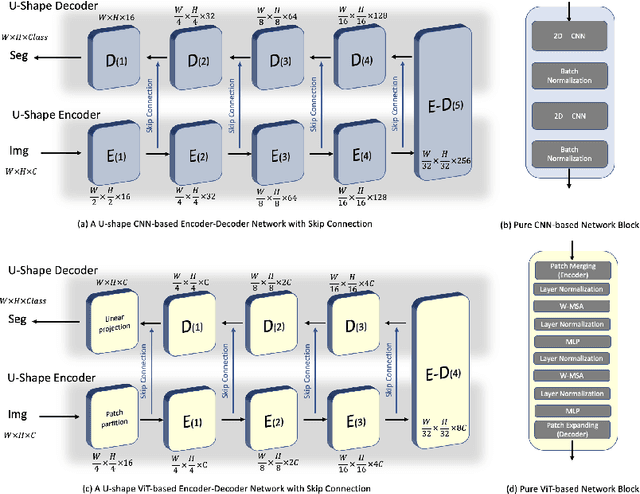
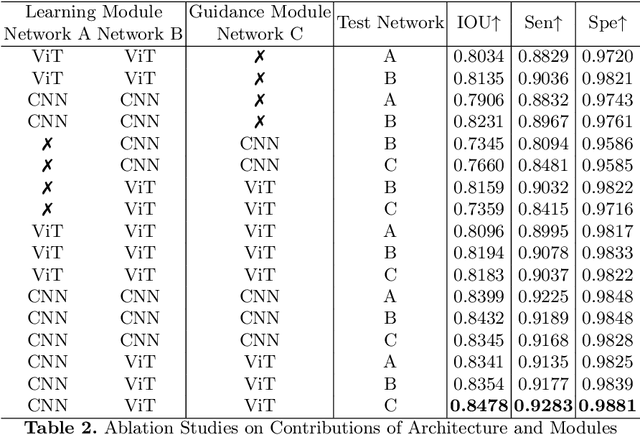
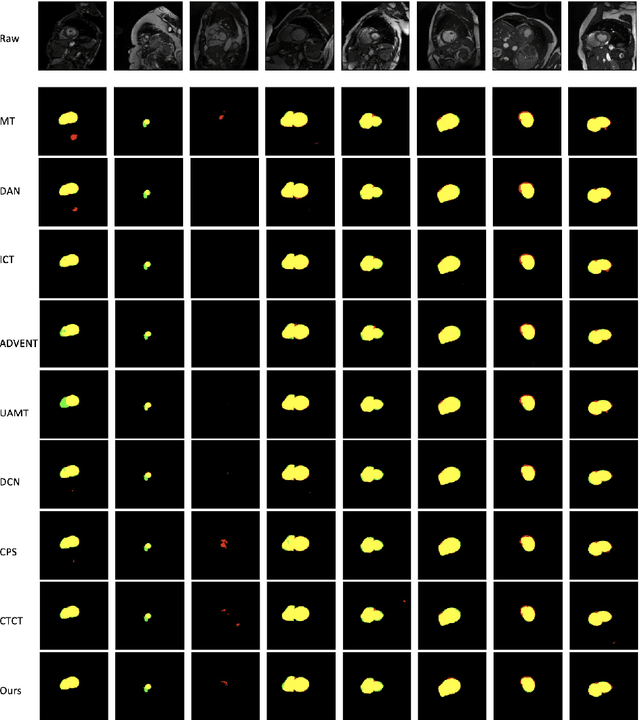
Due to the lack of quality annotation in medical imaging community, semi-supervised learning methods are highly valued in image semantic segmentation tasks. In this paper, an advanced consistency-aware pseudo-label-based self-ensembling approach is presented to fully utilize the power of Vision Transformer(ViT) and Convolutional Neural Network(CNN) in semi-supervised learning. Our proposed framework consists of a feature-learning module which is enhanced by ViT and CNN mutually, and a guidance module which is robust for consistency-aware purposes. The pseudo labels are inferred and utilized recurrently and separately by views of CNN and ViT in the feature-learning module to expand the data set and are beneficial to each other. Meanwhile, a perturbation scheme is designed for the feature-learning module, and averaging network weight is utilized to develop the guidance module. By doing so, the framework combines the feature-learning strength of CNN and ViT, strengthens the performance via dual-view co-training, and enables consistency-aware supervision in a semi-supervised manner. A topological exploration of all alternative supervision modes with CNN and ViT are detailed validated, demonstrating the most promising performance and specific setting of our method on semi-supervised medical image segmentation tasks. Experimental results show that the proposed method achieves state-of-the-art performance on a public benchmark data set with a variety of metrics. The code is publicly available.
FAPM: Fast Adaptive Patch Memory for Real-time Industrial Anomaly Detection
Nov 14, 2022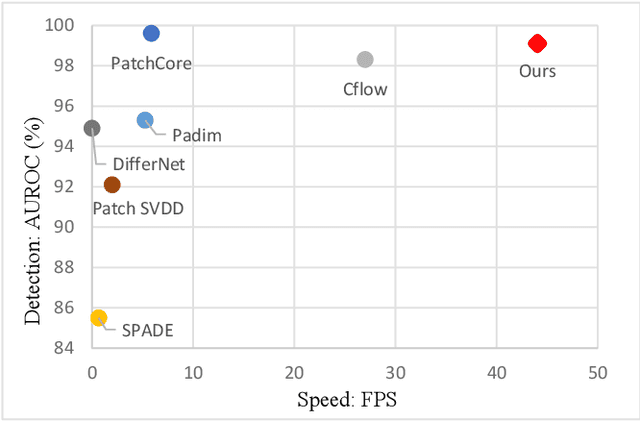

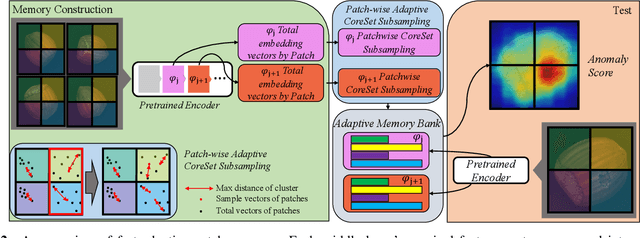

Feature embedding-based methods have performed exceptionally well in detecting industrial anomalies by comparing the features of the target image and the normal image. However, such approaches do not consider the inference speed, which is as important as accuracy in real-world applications. To relieve this issue, we propose a method called fast adaptive patch memory (FAPM) for real-time industrial anomaly detection. FAPM consists of patch-wise and layer-wise memory banks that save the embedding features of images in patch-level and layer-level, eliminating unnecessary repeated calculations. We also propose patch-wise adaptive coreset sampling for fast and accurate detection. FAPM performs well for both accuracy and speed compared to other state-of-the-art methods.
Compound Multi-branch Feature Fusion for Real Image Restoration
Jun 02, 2022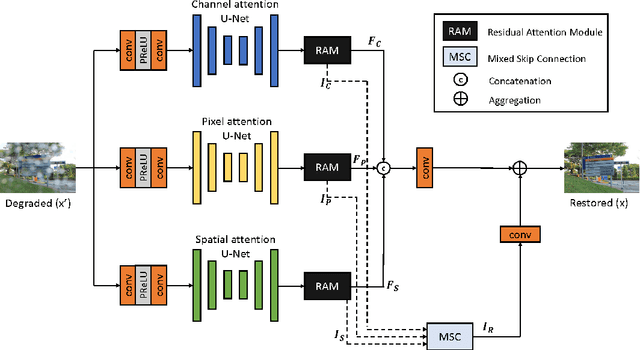
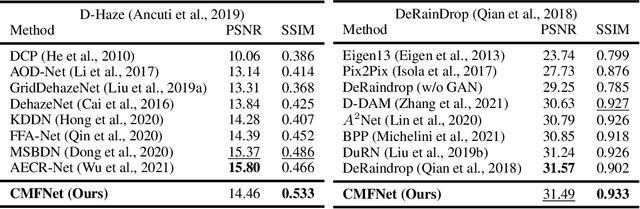
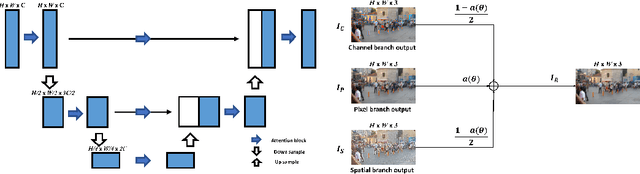
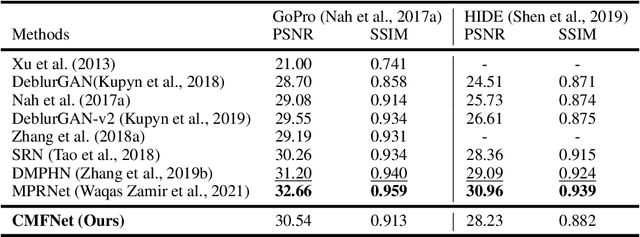
Image restoration is a challenging and ill-posed problem which also has been a long-standing issue. However, most of learning based restoration methods are proposed to target one degradation type which means they are lack of generalization. In this paper, we proposed a multi-branch restoration model inspired from the Human Visual System (i.e., Retinal Ganglion Cells) which can achieve multiple restoration tasks in a general framework. The experiments show that the proposed multi-branch architecture, called CMFNet, has competitive performance results on four datasets, including image dehazing, deraindrop, and deblurring, which are very common applications for autonomous cars. The source code and pretrained models of three restoration tasks are available at https://github.com/FanChiMao/CMFNet.
A Novel Hierarchical-Classification-Block Based Convolutional Neural Network for Source Camera Model Identification
Dec 08, 2022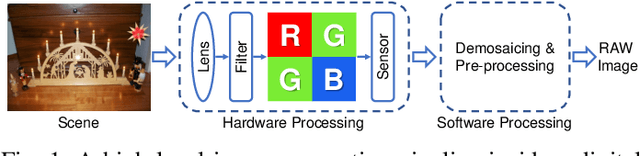
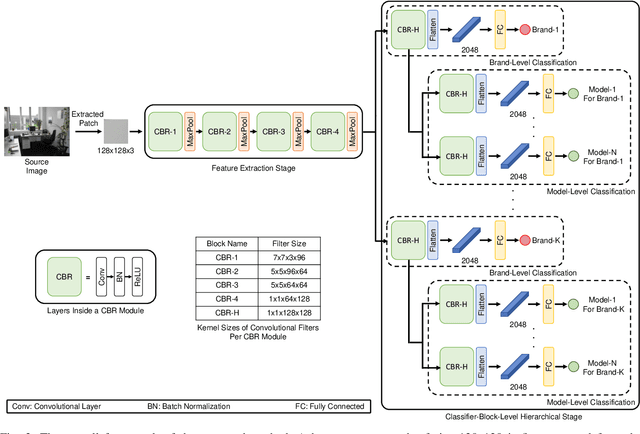


Digital security has been an active area of research interest due to the rapid adaptation of internet infrastructure, the increasing popularity of social media, and digital cameras. Due to inherent differences in working principles to generate an image, different camera brands left behind different intrinsic processing noises which can be used to identify the camera brand. In the last decade, many signal processing and deep learning-based methods have been proposed to identify and isolate this noise from the scene details in an image to detect the source camera brand. One prominent solution is to utilize a hierarchical classification system rather than the traditional single-classifier approach. Different individual networks are used for brand-level and model-level source camera identification. This approach allows for better scaling and requires minimal modifications for adding a new camera brand/model to the solution. However, using different full-fledged networks for both brand and model-level classification substantially increases memory consumption and training complexity. Moreover, extracted low-level features from the different network's initial layers often coincide, resulting in redundant weights. To mitigate the training and memory complexity, we propose a classifier-block-level hierarchical system instead of a network-level one for source camera model classification. Our proposed approach not only results in significantly fewer parameters but also retains the capability to add a new camera model with minimal modification. Thorough experimentation on the publicly available Dresden dataset shows that our proposed approach can achieve the same level of state-of-the-art performance but requires fewer parameters compared to a state-of-the-art network-level hierarchical-based system.
Training Patch Analysis and Mining Skills for Image Restoration Deep Neural Networks
Jul 03, 2022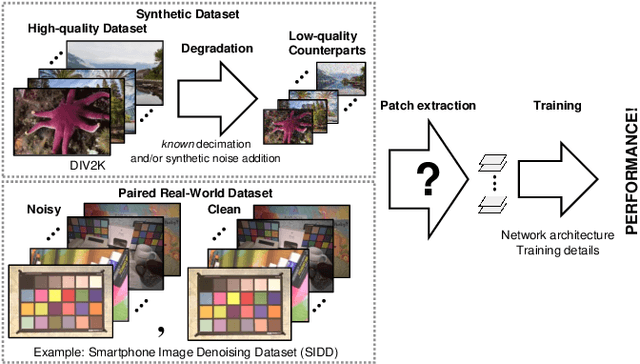
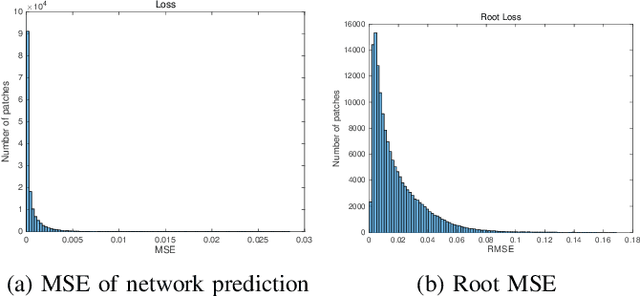
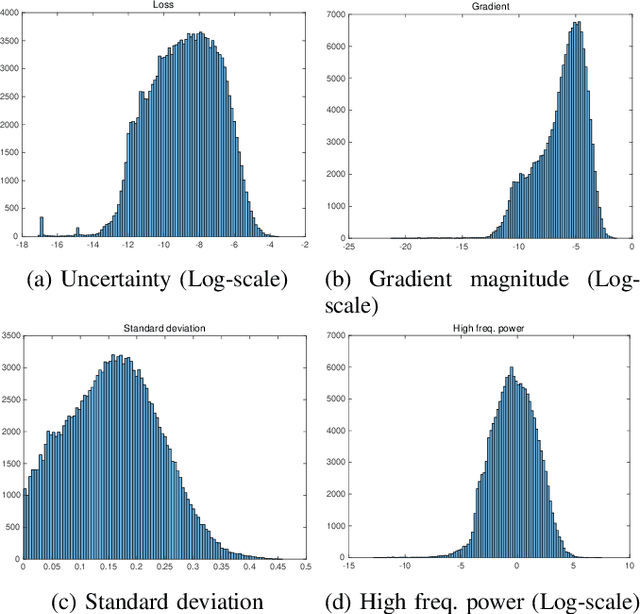
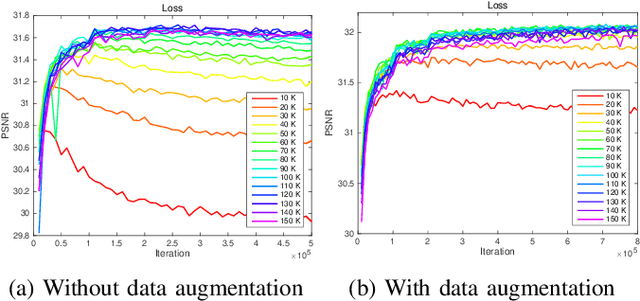
There have been numerous image restoration methods based on deep convolutional neural networks (CNNs). However, most of the literature on this topic focused on the network architecture and loss functions, while less detailed on the training methods. Hence, some of the works are not easily reproducible because it is required to know the hidden training skills to obtain the same results. To be specific with the training dataset, few works discussed how to prepare and order the training image patches. Moreover, it requires a high cost to capture new datasets to train a restoration network for the real-world scene. Hence, we believe it is necessary to study the preparation and selection of training data. In this regard, we present an analysis of the training patches and explore the consequences of different patch extraction methods. Eventually, we propose a guideline for the patch extraction from given training images.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Dec 06, 2022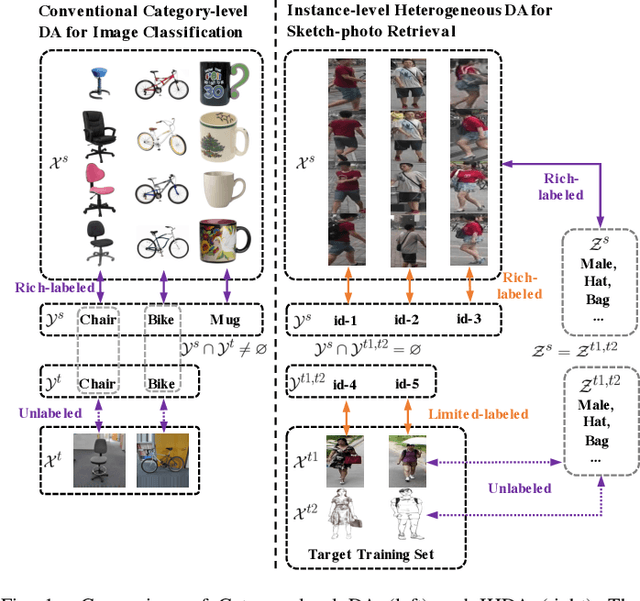
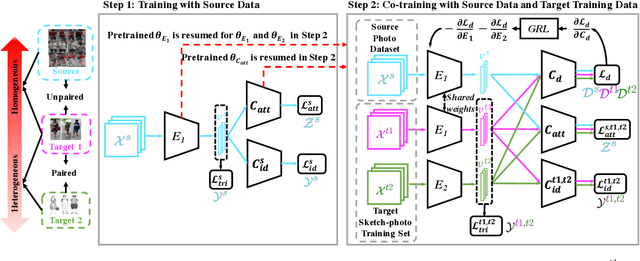

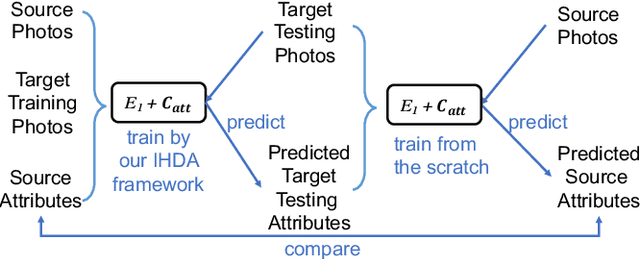
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at https://github.com/fandulu/IHDA.
UVCGAN: UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation
Mar 21, 2022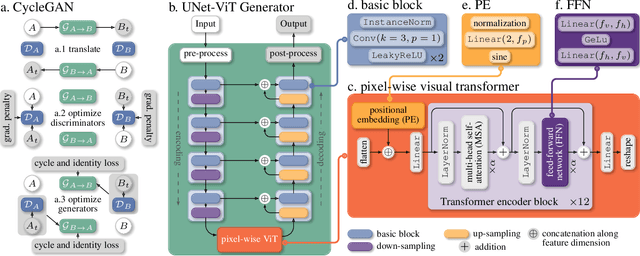


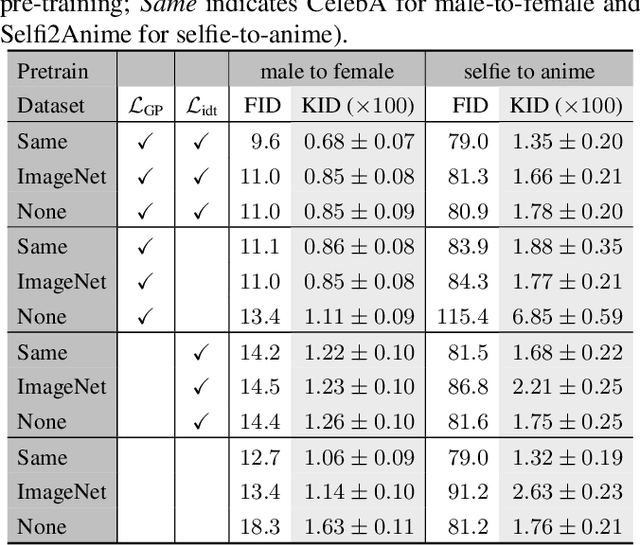
Image-to-image translation has broad applications in art, design, and scientific simulations. The original CycleGAN model emphasizes one-to-one mapping via a cycle-consistent loss, while more recent works promote one-to-many mapping to boost the diversity of the translated images. With scientific simulation and one-to-one needs in mind, this work examines if equipping CycleGAN with a vision transformer (ViT) and employing advanced generative adversarial network (GAN) training techniques can achieve better performance. The resulting UNet ViT Cycle-consistent GAN (UVCGAN) model is compared with previous best-performing models on open benchmark image-to-image translation datasets, Selfie2Anime and CelebA. UVCGAN performs better and retains a strong correlation between the original and translated images. An accompanying ablation study shows that the gradient penalty and BERT-like pre-training also contribute to the improvement.~To promote reproducibility and open science, the source code, hyperparameter configurations, and pre-trained model will be made available at: https://github.com/LS4GAN/uvcgan.
A Comprehensive Survey of Image Augmentation Techniques for Deep Learning
May 03, 2022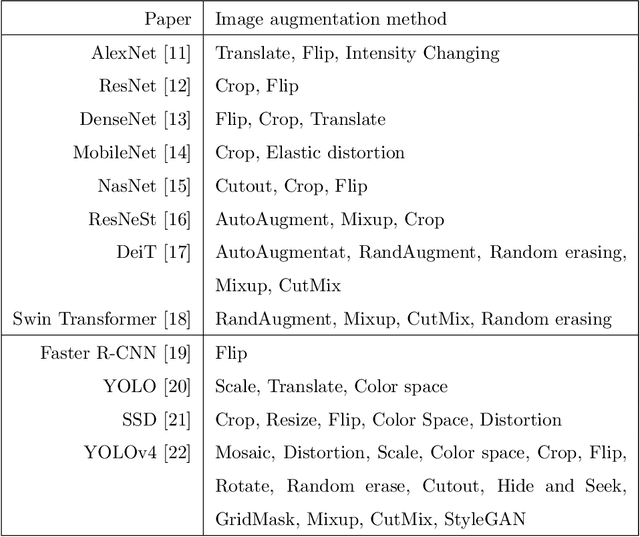
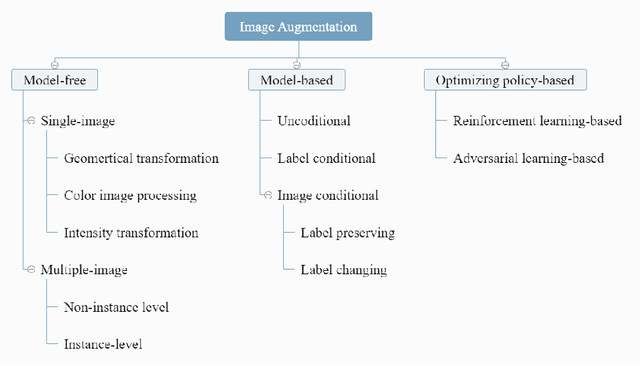
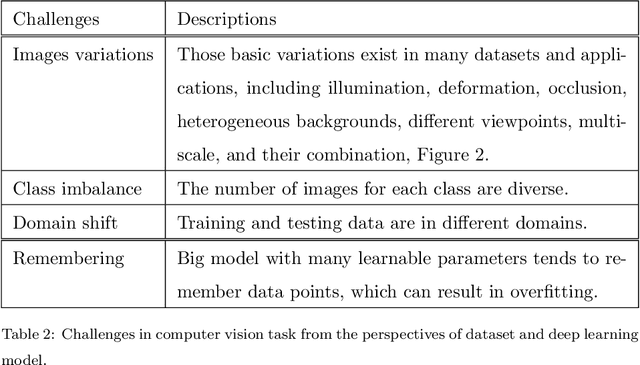

Deep learning has been achieving decent performance in computer vision requiring a large volume of images, however, collecting images is expensive and difficult in many scenarios. To alleviate this issue, many image augmentation algorithms have been proposed as effective and efficient strategies. Understanding current algorithms is essential to find suitable methods or develop novel techniques for given tasks. In this paper, we perform a comprehensive survey on image augmentation for deep learning with a novel informative taxonomy. To get the basic idea why we need image augmentation, we introduce the challenges in computer vision tasks and vicinity distribution. Then, the algorithms are split into three categories; model-free, model-based, and optimizing policy-based. The model-free category employs image processing methods while the model-based method leverages trainable image generation models. In contrast, the optimizing policy-based approach aims to find the optimal operations or their combinations. Furthermore, we discuss the current trend of common applications with two more active topics, leveraging different ways to understand image augmentation, such as group and kernel theory, and deploying image augmentation for unsupervised learning. Based on the analysis, we believe that our survey gives a better understanding helpful to choose suitable methods or design novel algorithms for practical applications.