 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Improving the Pyramidal Predictive Network for Future Video Frame Prediction
Jan 13, 2023



The pyramidal predictive network (PPNV1) proposes an interesting temporal pyramid architecture and yields promising results on the task of future video-frame prediction. We expose and analyze its signal dissemination and characteristic artifacts, and propose corresponding improvements in model architecture and training strategies to address them. Although the PPNV1 theoretically mimics the workings of human brain, its careless signal processing leads to aliasing in the network. We redesign the network architecture to solve the problems. In addition to improving the unreasonable information dissemination, the new architecture also aims to solve the aliasing in neural networks. Different inputs are no longer simply concatenated, and the downsampling and upsampling components have also been redesigned to ensure that the network can more easily construct images from Fourier features of low-frequency inputs. Finally, we further improve the training strategies, to alleviate the problem of input inconsistency during training and testing. Overall, the improved model is more interpretable, stronger, and the quality of its predictions is better. Code is available at https://github.com/Ling-CF/PPNV2.
Predictive Coding Based Multiscale Network with Encoder-Decoder LSTM for Video Prediction
Dec 30, 2022



We are introducing a multi-scale predictive model for video prediction here, whose design is inspired by the "Predictive Coding" theories and "Coarse to Fine" approach. As a predictive coding model, it is updated by a combination of bottom-up and top-down information flows, which is different from traditional bottom-up training style. Its advantage is to reduce the dependence on input information and improve its ability to predict and generate images. Importantly, we achieve with a multi-scale approach -- higher level neurons generate coarser predictions (lower resolution), while the lower level generate finer predictions (higher resolution). This is different from the traditional predictive coding framework in which higher level predict the activity of neurons in lower level. To improve the predictive ability, we integrate an encoder-decoder network in the LSTM architecture and share the final encoded high-level semantic information between different levels. Additionally, since the output of each network level is an RGB image, a smaller LSTM hidden state can be used to retain and update the only necessary hidden information, avoiding being mapped to an overly discrete and complex space. In this way, we can reduce the difficulty of prediction and the computational overhead. Finally, we further explore the training strategies, to address the instability in adversarial training and mismatch between training and testing in long-term prediction. Code is available at https://github.com/Ling-CF/MSPN.
Pyramidal Predictive Network: A Model for Visual-frame Prediction Based on Predictive Coding Theory
Aug 15, 2022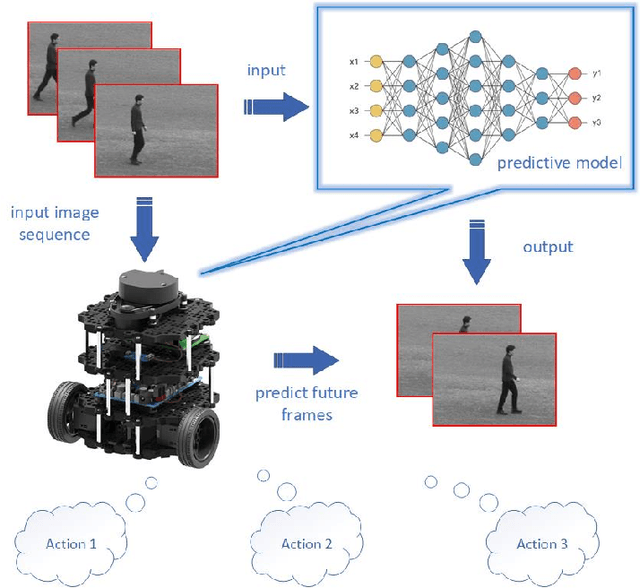
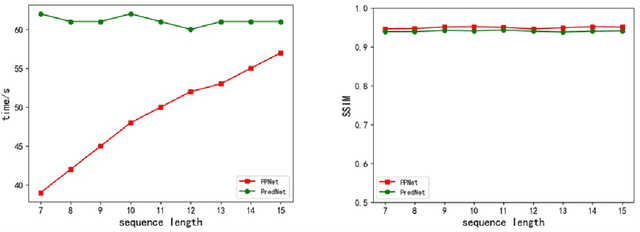
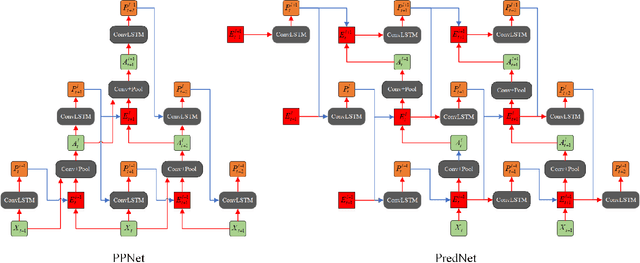
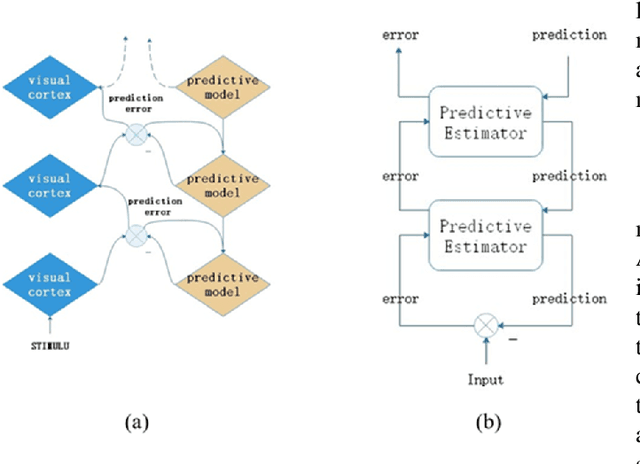
Inspired by the well-known predictive coding theory in cognitive science, we propose a novel neural network model for the task of visual-frame prediction. In this paper, our main work is to combine the theoretical framework of predictive coding and deep learning architectures, to design an efficient predictive network model for visual-frame prediction. The model is composed of a series of recurrent and convolutional units forming the top-down and bottom-up streams, respectively. It learns to predict future frames in a visual sequence, with ConvLSTMs on each layer in the network making local prediction from top to down. The main innovation of our model is that the update frequency of neural units on each of the layer decreases with the increasing of network levels, which results in the model appears like a pyramid from the perspective of time dimension, so we call it the Pyramid Predictive Network (PPNet). Particularly, this pyramid-like design is consistent to the neuronal activities in the neuroscience findings involved in the predictive coding framework. According to the experimental results, this model shows better compactness and comparable predictive performance with existing works, implying lower computational cost and higher prediction accuracy. Code will be available at https://github.com/Ling-CF/PPNet.