 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pilot Study on the Comparison of Prefrontal Cortex Activities of Robotic Therapies on Elderly with Mild Cognitive Impairment
May 04, 2024



Demographic shifts have led to an increase in mild cognitive impairment (MCI), and this study investigates the effects of cognitive training (CT) and reminiscence therapy (RT) conducted by humans or socially assistive robots (SARs) on prefrontal cortex activation in elderly individuals with MCI, aiming to determine the most effective therapy-modality combination for promoting cognitive function. This pilot study employs a randomized control trial (RCT) design. Additionally, the study explores the efficacy of Reminiscence Therapy (RT) in comparison to Cognitive Training (CT). Eight MCI subjects, with a mean age of 70.125 years, were randomly assigned to ``human-led'' or ``SAR-led'' groups. Utilizing Functional Near-infrared Spectroscopy (fNIRS) to measure oxy-hemoglobin concentration changes in the dorsolateral prefrontal cortex (DLPFC), the study found no significant differences in the effects of human-led and SAR-led cognitive training on DLPFC activation. However, distinct patterns emerged in memory encoding and retrieval phases between RT and CT, shedding light on the impacts of these interventions on brain activation in the context of MCI.
Analyzing and Improving the Pyramidal Predictive Network for Future Video Frame Prediction
Jan 13, 2023



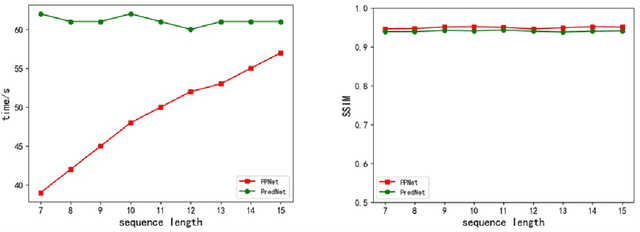
The pyramidal predictive network (PPNV1) proposes an interesting temporal pyramid architecture and yields promising results on the task of future video-frame prediction. We expose and analyze its signal dissemination and characteristic artifacts, and propose corresponding improvements in model architecture and training strategies to address them. Although the PPNV1 theoretically mimics the workings of human brain, its careless signal processing leads to aliasing in the network. We redesign the network architecture to solve the problems. In addition to improving the unreasonable information dissemination, the new architecture also aims to solve the aliasing in neural networks. Different inputs are no longer simply concatenated, and the downsampling and upsampling components have also been redesigned to ensure that the network can more easily construct images from Fourier features of low-frequency inputs. Finally, we further improve the training strategies, to alleviate the problem of input inconsistency during training and testing. Overall, the improved model is more interpretable, stronger, and the quality of its predictions is better. Code is available at https://github.com/Ling-CF/PPNV2.
Predictive Coding Based Multiscale Network with Encoder-Decoder LSTM for Video Prediction
Dec 30, 2022



We are introducing a multi-scale predictive model for video prediction here, whose design is inspired by the "Predictive Coding" theories and "Coarse to Fine" approach. As a predictive coding model, it is updated by a combination of bottom-up and top-down information flows, which is different from traditional bottom-up training style. Its advantage is to reduce the dependence on input information and improve its ability to predict and generate images. Importantly, we achieve with a multi-scale approach -- higher level neurons generate coarser predictions (lower resolution), while the lower level generate finer predictions (higher resolution). This is different from the traditional predictive coding framework in which higher level predict the activity of neurons in lower level. To improve the predictive ability, we integrate an encoder-decoder network in the LSTM architecture and share the final encoded high-level semantic information between different levels. Additionally, since the output of each network level is an RGB image, a smaller LSTM hidden state can be used to retain and update the only necessary hidden information, avoiding being mapped to an overly discrete and complex space. In this way, we can reduce the difficulty of prediction and the computational overhead. Finally, we further explore the training strategies, to address the instability in adversarial training and mismatch between training and testing in long-term prediction. Code is available at https://github.com/Ling-CF/MSPN.
Pyramidal Predictive Network: A Model for Visual-frame Prediction Based on Predictive Coding Theory
Aug 15, 2022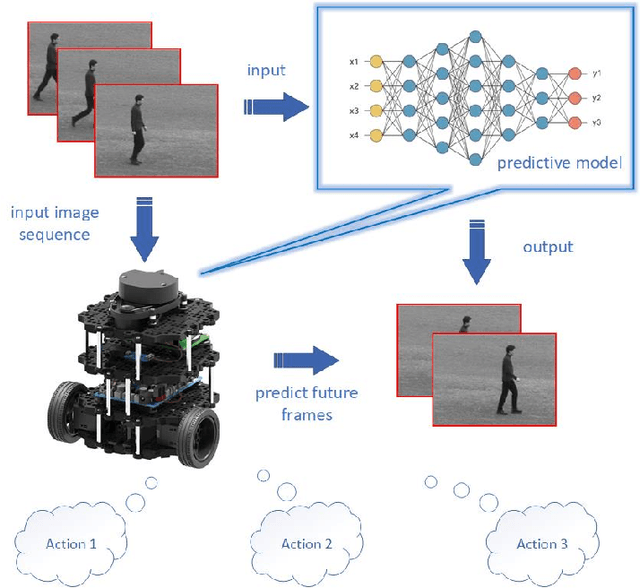
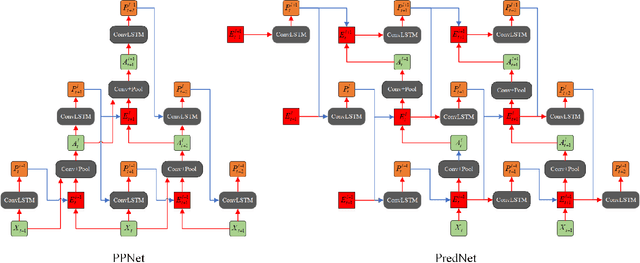
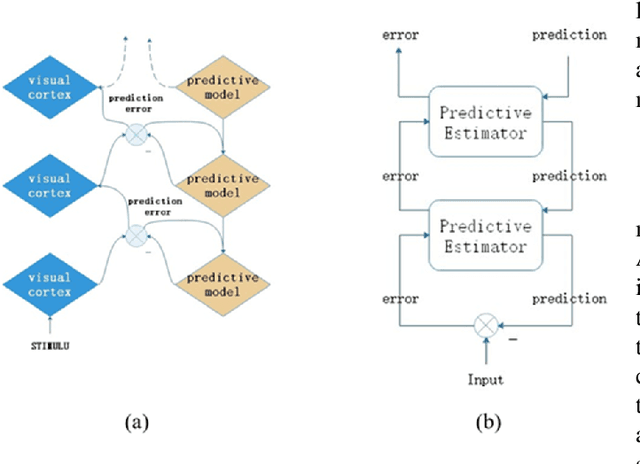
Inspired by the well-known predictive coding theory in cognitive science, we propose a novel neural network model for the task of visual-frame prediction. In this paper, our main work is to combine the theoretical framework of predictive coding and deep learning architectures, to design an efficient predictive network model for visual-frame prediction. The model is composed of a series of recurrent and convolutional units forming the top-down and bottom-up streams, respectively. It learns to predict future frames in a visual sequence, with ConvLSTMs on each layer in the network making local prediction from top to down. The main innovation of our model is that the update frequency of neural units on each of the layer decreases with the increasing of network levels, which results in the model appears like a pyramid from the perspective of time dimension, so we call it the Pyramid Predictive Network (PPNet). Particularly, this pyramid-like design is consistent to the neuronal activities in the neuroscience findings involved in the predictive coding framework. According to the experimental results, this model shows better compactness and comparable predictive performance with existing works, implying lower computational cost and higher prediction accuracy. Code will be available at https://github.com/Ling-CF/PPNet.
Towards a self-organizing pre-symbolic neural model representing sensorimotor primitives
Jul 12, 2020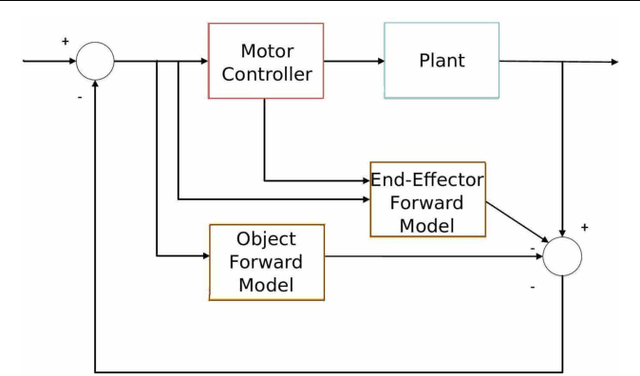

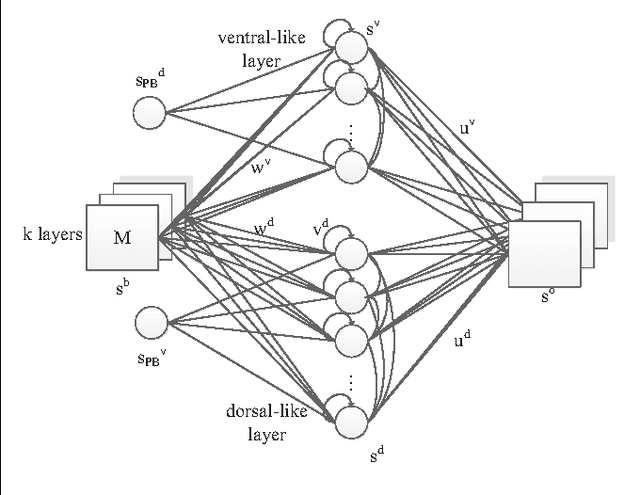

The acquisition of symbolic and linguistic representations of sensorimotor behavior is a cognitive process performed by an agent when it is executing and/or observing own and others' actions. According to Piaget's theory of cognitive development, these representations develop during the sensorimotor stage and the pre-operational stage. We propose a model that relates the conceptualization of the higher-level information from visual stimuli to the development of ventral/dorsal visual streams. This model employs neural network architecture incorporating a predictive sensory module based on an RNNPB (Recurrent Neural Network with Parametric Biases) and a horizontal product model. We exemplify this model through a robot passively observing an object to learn its features and movements. During the learning process of observing sensorimotor primitives, i.e. observing a set of trajectories of arm movements and its oriented object features, the pre-symbolic representation is self-organized in the parametric units. These representational units act as bifurcation parameters, guiding the robot to recognize and predict various learned sensorimotor primitives. The pre-symbolic representation also accounts for the learning of sensorimotor primitives in a latent learning context.
Encoding Longer-term Contextual Multi-modal Information in a Predictive Coding Model
Apr 17, 2018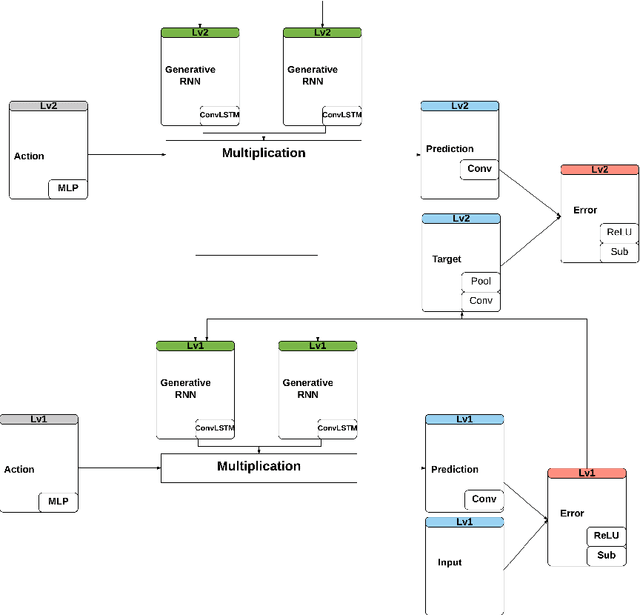
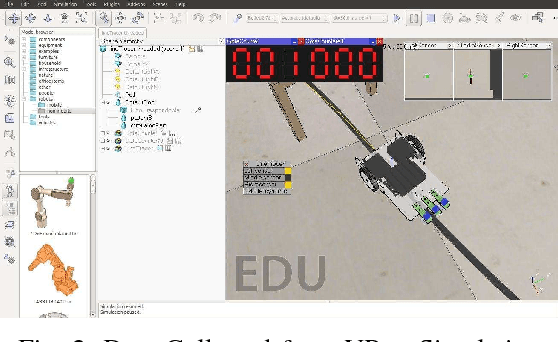


Studies suggest that within the hierarchical architecture, the topological higher level possibly represents a conscious category of the current sensory events with slower changing activities. They attempt to predict the activities on the lower level by relaying the predicted information. On the other hand, the incoming sensory information corrects such prediction of the events on the higher level by the novel or surprising signal. We propose a predictive hierarchical artificial neural network model that examines this hypothesis on neurorobotic platforms, based on the AFA-PredNet model. In this neural network model, there are different temporal scales of predictions exist on different levels of the hierarchical predictive coding, which are defined in the temporal parameters in the neurons. Also, both the fast and the slow-changing neural activities are modulated by the active motor activities. A neurorobotic experiment based on the architecture was also conducted based on the data collected from the VRep simulator.
AFA-PredNet: The action modulation within predictive coding
Apr 11, 2018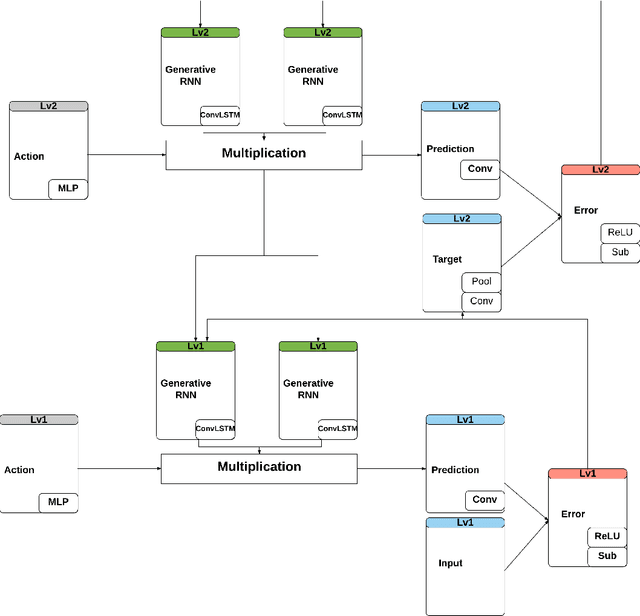



The predictive processing (PP) hypothesizes that the predictive inference of our sensorimotor system is encoded implicitly in the regularities between perception and action. We propose a neural architecture in which such regularities of active inference are encoded hierarchically. We further suggest that this encoding emerges during the embodied learning process when the appropriate action is selected to minimize the prediction error in perception. Therefore, this predictive stream in the sensorimotor loop is generated in a top-down manner. Specifically, it is constantly modulated by the motor actions and is updated by the bottom-up prediction error signals. In this way, the top-down prediction originally comes from the prior experience from both perception and action representing the higher levels of this hierarchical cognition. In our proposed embodied model, we extend the PredNet Network, a hierarchical predictive coding network, with the motor action units implemented by a multi-layer perceptron network (MLP) to modulate the network top-down prediction. Two experiments, a minimalistic world experiment, and a mobile robot experiment are conducted to evaluate the proposed model in a qualitative way. In the neural representation, it can be observed that the causal inference of predictive percept from motor actions can be also observed while the agent is interacting with the environment.
Toward Abstraction from Multi-modal Data: Empirical Studies on Multiple Time-scale Recurrent Models
Feb 07, 2017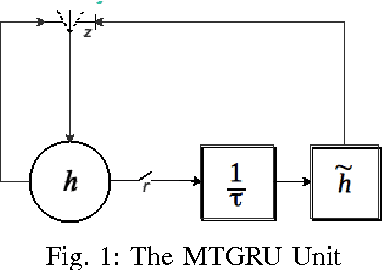
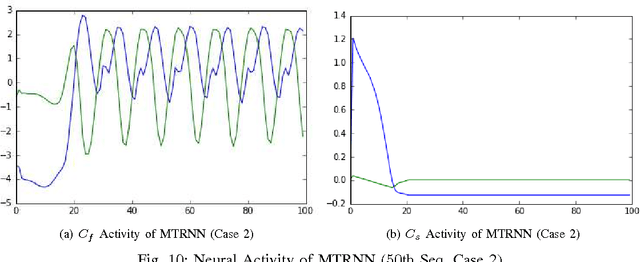
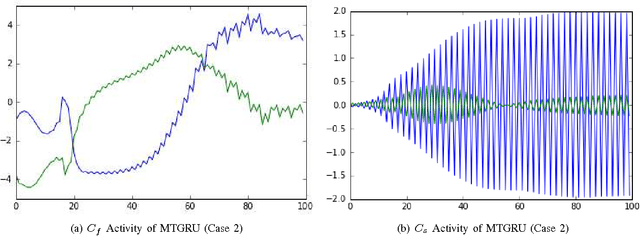

The abstraction tasks are challenging for multi- modal sequences as they require a deeper semantic understanding and a novel text generation for the data. Although the recurrent neural networks (RNN) can be used to model the context of the time-sequences, in most cases the long-term dependencies of multi-modal data make the back-propagation through time training of RNN tend to vanish in the time domain. Recently, inspired from Multiple Time-scale Recurrent Neural Network (MTRNN), an extension of Gated Recurrent Unit (GRU), called Multiple Time-scale Gated Recurrent Unit (MTGRU), has been proposed to learn the long-term dependencies in natural language processing. Particularly it is also able to accomplish the abstraction task for paragraphs given that the time constants are well defined. In this paper, we compare the MTRNN and MTGRU in terms of its learning performances as well as their abstraction representation on higher level (with a slower neural activation). This was done by conducting two studies based on a smaller data- set (two-dimension time sequences from non-linear functions) and a relatively large data-set (43-dimension time sequences from iCub manipulation tasks with multi-modal data). We conclude that gated recurrent mechanisms may be necessary for learning long-term dependencies in large dimension multi-modal data-sets (e.g. learning of robot manipulation), even when natural language commands was not involved. But for smaller learning tasks with simple time-sequences, generic version of recurrent models, such as MTRNN, were sufficient to accomplish the abstraction task.
A Hierarchical Emotion Regulated Sensorimotor Model: Case Studies
May 11, 2016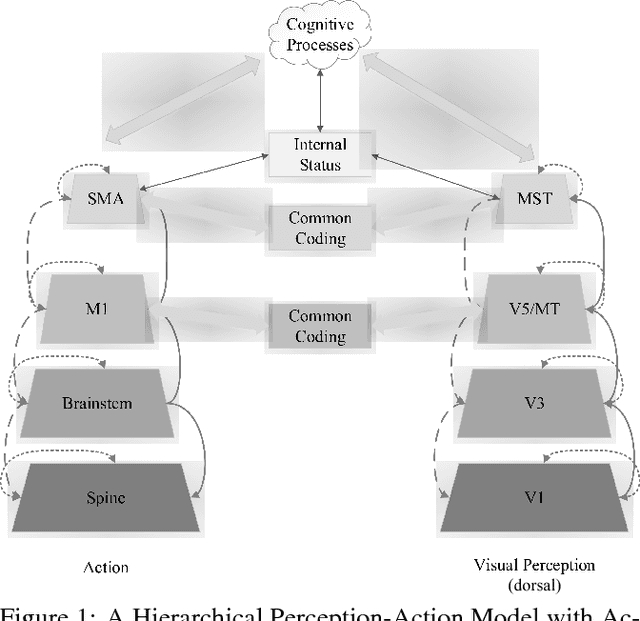

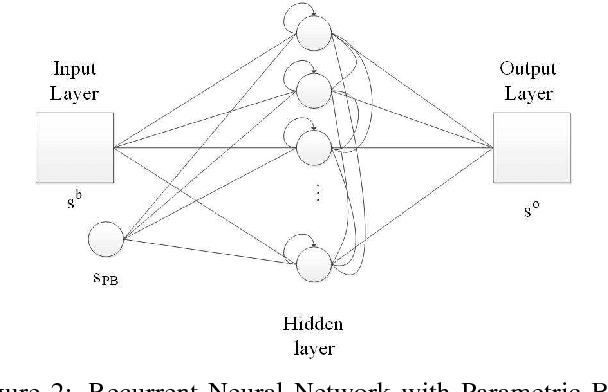
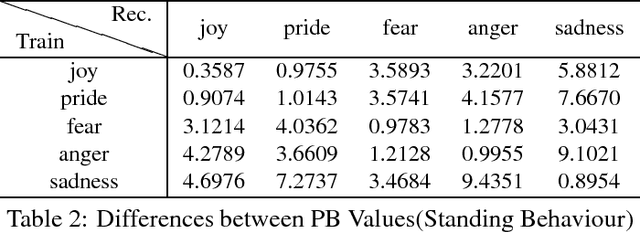
Inspired by the hierarchical cognitive architecture and the perception-action model (PAM), we propose that the internal status acts as a kind of common-coding representation which affects, mediates and even regulates the sensorimotor behaviours. These regulation can be depicted in the Bayesian framework, that is why cognitive agents are able to generate behaviours with subtle differences according to their emotion or recognize the emotion by perception. A novel recurrent neural network called recurrent neural network with parametric bias units (RNNPB) runs in three modes, constructing a two-level emotion regulated learning model, was further applied to testify this theory in two different cases.
Sensorimotor Input as a Language Generalisation Tool: A Neurorobotics Model for Generation and Generalisation of Noun-Verb Combinations with Sensorimotor Inputs
May 11, 2016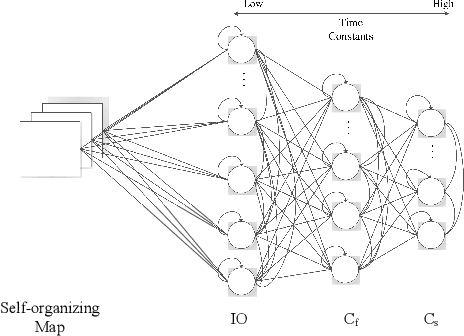
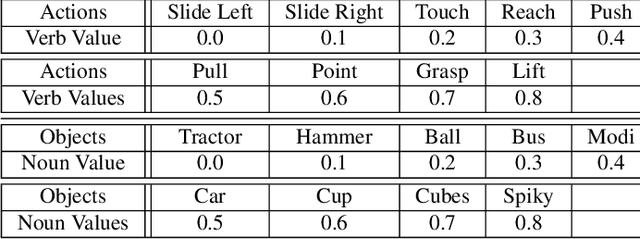
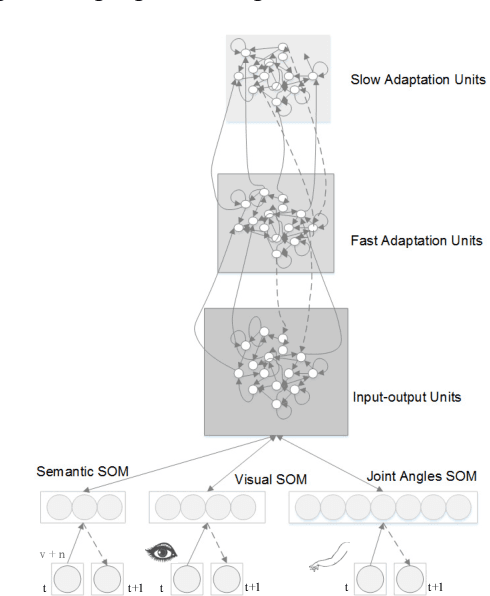

The paper presents a neurorobotics cognitive model to explain the understanding and generalisation of nouns and verbs combinations when a vocal command consisting of a verb-noun sentence is provided to a humanoid robot. This generalisation process is done via the grounding process: different objects are being interacted, and associated, with different motor behaviours, following a learning approach inspired by developmental language acquisition in infants. This cognitive model is based on Multiple Time-scale Recurrent Neural Networks (MTRNN).With the data obtained from object manipulation tasks with a humanoid robot platform, the robotic agent implemented with this model can ground the primitive embodied structure of verbs through training with verb-noun combination samples. Moreover, we show that a functional hierarchical architecture, based on MTRNN, is able to generalise and produce novel combinations of noun-verb sentences. Further analyses of the learned network dynamics and representations also demonstrate how the generalisation is possible via the exploitation of this functional hierarchical recurrent network.