 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmful Visual Content Manipulation Matters in Misinformation Detection Under Multimedia Scenarios
Mar 22, 2026Nowadays, the widespread dissemination of misinformation across numerous social media platforms has led to severe negative effects on society. To address this challenge, the automatic detection of misinformation, particularly under multimedia scenarios, has gained significant attention from both academic and industrial communities, leading to the emergence of a research task known as Multimodal Misinformation Detection (MMD). Typically, current MMD approaches focus on capturing the semantic relationships and inconsistency between various modalities but often overlook certain critical indicators within multimodal content. Recent research has shown that manipulated features within visual content in social media articles serve as valuable clues for MMD. Meanwhile, we argue that the potential intentions behind the manipulation, e.g., harmful and harmless, also matter in MMD. Therefore, in this study, we aim to identify such multimodal misinformation by capturing two types of features: manipulation features, which represent if visual content has been manipulated, and intention features, which assess the nature of these manipulations, distinguishing between harmful and harmless intentions. Unfortunately, the manipulation and intention labels that supervise these features to be discriminative are unknown. To address this, we introduce two weakly supervised indicators as substitutes by incorporating supplementary datasets focused on image manipulation detection and framing two different classification tasks as positive and unlabeled learning issues. With this framework, we introduce an innovative MMD approach, titled Harmful Visual Content Manipulation Matters in MMD (HAVC-M4 D). Comprehensive experiments conducted on four prevalent MMD datasets indicate that HAVC-M4 D significantly and consistently enhances the performance of existing MMD methods.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
When CNN Meet with ViT: Towards Semi-Supervised Learning for Multi-Class Medical Image Semantic Segmentation
Aug 12, 2022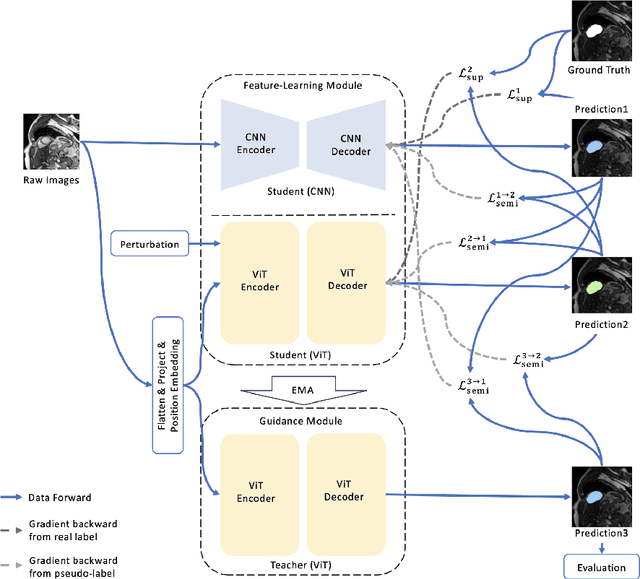
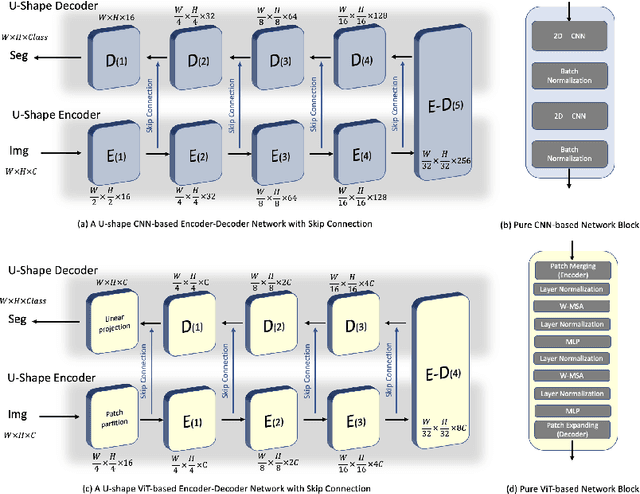
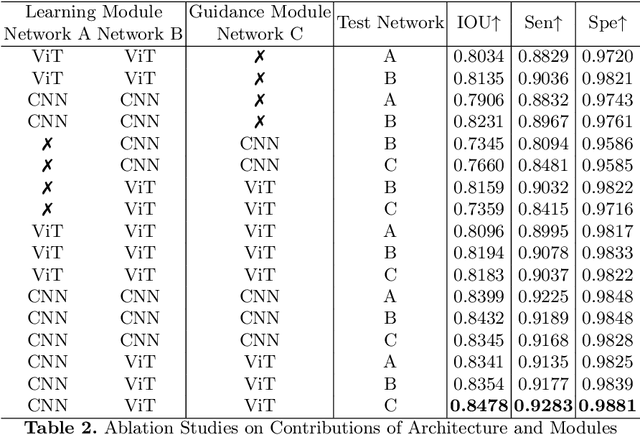
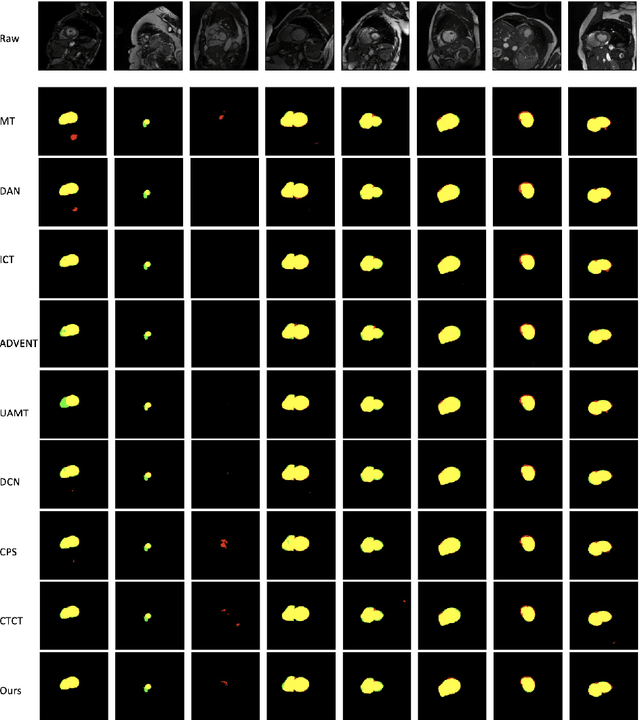
Due to the lack of quality annotation in medical imaging community, semi-supervised learning methods are highly valued in image semantic segmentation tasks. In this paper, an advanced consistency-aware pseudo-label-based self-ensembling approach is presented to fully utilize the power of Vision Transformer(ViT) and Convolutional Neural Network(CNN) in semi-supervised learning. Our proposed framework consists of a feature-learning module which is enhanced by ViT and CNN mutually, and a guidance module which is robust for consistency-aware purposes. The pseudo labels are inferred and utilized recurrently and separately by views of CNN and ViT in the feature-learning module to expand the data set and are beneficial to each other. Meanwhile, a perturbation scheme is designed for the feature-learning module, and averaging network weight is utilized to develop the guidance module. By doing so, the framework combines the feature-learning strength of CNN and ViT, strengthens the performance via dual-view co-training, and enables consistency-aware supervision in a semi-supervised manner. A topological exploration of all alternative supervision modes with CNN and ViT are detailed validated, demonstrating the most promising performance and specific setting of our method on semi-supervised medical image segmentation tasks. Experimental results show that the proposed method achieves state-of-the-art performance on a public benchmark data set with a variety of metrics. The code is publicly available.