 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeological Isolation in Online Social Networks: A Survey of Computational Definitions, Metrics, and Mitigation Strategies
Jan 12, 2026The proliferation of online social networks has significantly reshaped the way individuals access and engage with information. While these platforms offer unprecedented connectivity, they may foster environments where users are increasingly exposed to homogeneous content and like-minded interactions. Such dynamics are associated with selective exposure and the emergence of filter bubbles, echo chambers, tunnel vision, and polarization, which together can contribute to ideological isolation and raise concerns about information diversity and public discourse. This survey provides a comprehensive computational review of existing studies that define, analyze, quantify, and mitigate ideological isolation in online social networks. We examine the mechanisms underlying content personalization, user behavior patterns, and network structures that reinforce content-exposure concentration and narrowing dynamics. This paper also systematically reviews methodological approaches for detecting and measuring these isolation-related phenomena, covering network-, content-, and behavior-based metrics. We further organize computational mitigation strategies, including network-topological interventions and recommendation-level controls, and discuss their trade-offs and deployment considerations. By integrating definitions, metrics, and interventions across structural/topological, content-based, interactional, and cognitive isolation, this survey provides a unified computational framework. It serves as a reference for understanding and addressing the key challenges and opportunities in promoting information diversity and reducing ideological fragmentation in the digital age.
Probing then Editing: A Push-Pull Framework for Retain-Free Machine Unlearning in Industrial IoT
Nov 12, 2025In dynamic Industrial Internet of Things (IIoT) environments, models need the ability to selectively forget outdated or erroneous knowledge. However, existing methods typically rely on retain data to constrain model behavior, which increases computational and energy burdens and conflicts with industrial data silos and privacy compliance requirements. To address this, we propose a novel retain-free unlearning framework, referred to as Probing then Editing (PTE). PTE frames unlearning as a probe-edit process: first, it probes the decision boundary neighborhood of the model on the to-be-forgotten class via gradient ascent and generates corresponding editing instructions using the model's own predictions. Subsequently, a push-pull collaborative optimization is performed: the push branch actively dismantles the decision region of the target class using the editing instructions, while the pull branch applies masked knowledge distillation to anchor the model's knowledge on retained classes to their original states. Benefiting from this mechanism, PTE achieves efficient and balanced knowledge editing using only the to-be-forgotten data and the original model. Experimental results demonstrate that PTE achieves an excellent balance between unlearning effectiveness and model utility across multiple general and industrial benchmarks such as CWRU and SCUT-FD.
InfraredGP: Efficient Graph Partitioning via Spectral Graph Neural Networks with Negative Corrections
Aug 27, 2025



Graph partitioning (GP), a.k.a. community detection, is a classic problem that divides nodes of a graph into densely-connected blocks. From a perspective of graph signal processing, we find that graph Laplacian with a negative correction can derive graph frequencies beyond the conventional range $[0, 2]$. To explore whether the low-frequency information beyond this range can encode more informative properties about community structures, we propose InfraredGP. It (\romannumeral1) adopts a spectral GNN as its backbone combined with low-pass filters and a negative correction mechanism, (\romannumeral2) only feeds random inputs to this backbone, (\romannumeral3) derives graph embeddings via one feed-forward propagation (FFP) without any training, and (\romannumeral4) obtains feasible GP results by feeding the derived embeddings to BIRCH. Surprisingly, our experiments demonstrate that based solely on the negative correction mechanism that amplifies low-frequency information beyond $[0, 2]$, InfraredGP can derive distinguishable embeddings for some standard clustering modules (e.g., BIRCH) and obtain high-quality results for GP without any training. Following the IEEE HPEC Graph Challenge benchmark, we evaluate InfraredGP for both static and streaming GP, where InfraredGP can achieve much better efficiency (e.g., 16x-23x faster) and competitive quality over various baselines. We have made our code public at https://github.com/KuroginQin/InfraredGP
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
Mar 09, 2025Large Vision and Language Models have exhibited remarkable human-like intelligence in tasks such as natural language comprehension, problem-solving, logical reasoning, and knowledge retrieval. However, training and serving these models require substantial computational resources, posing a significant barrier to their widespread application and further research. To mitigate this challenge, various model compression techniques have been developed to reduce computational requirements. Nevertheless, existing methods often employ uniform quantization configurations, failing to account for the varying difficulties across different layers in quantizing large neural network models. This paper tackles this issue by leveraging layer-sensitivity features, such as activation sensitivity and weight distribution Kurtosis, to identify layers that are challenging to quantize accurately and allocate additional memory budget. The proposed methods, named SensiBoost and KurtBoost, respectively, demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
FaultGPT: Industrial Fault Diagnosis Question Answering System by Vision Language Models
Feb 21, 2025


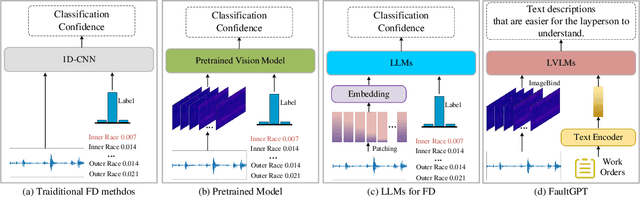
Recently, employing single-modality large language models based on mechanical vibration signals as Tuning Predictors has introduced new perspectives in intelligent fault diagnosis. However, the potential of these methods to leverage multimodal data remains underexploited, particularly in complex mechanical systems where relying on a single data source often fails to capture comprehensive fault information. In this paper, we present FaultGPT, a novel model that generates fault diagnosis reports directly from raw vibration signals. By leveraging large vision-language models (LVLM) and text-based supervision, FaultGPT performs end-to-end fault diagnosis question answering (FDQA), distinguishing itself from traditional classification or regression approaches. Specifically, we construct a large-scale FDQA instruction dataset for instruction tuning of LVLM. This dataset includes vibration time-frequency image-text label pairs and human instruction-ground truth pairs. To enhance the capability in generating high-quality fault diagnosis reports, we design a multi-scale cross-modal image decoder to extract fine-grained fault semantics and conducted instruction tuning without introducing additional training parameters into the LVLM. Extensive experiments, including fault diagnosis report generation, few-shot and zero-shot evaluation across multiple datasets, validate the superior performance and adaptability of FaultGPT in diverse industrial scenarios.
PerceiverS: A Multi-Scale Perceiver with Effective Segmentation for Long-Term Expressive Symbolic Music Generation
Nov 13, 2024Music generation has progressed significantly, especially in the domain of audio generation. However, generating symbolic music that is both long-structured and expressive remains a significant challenge. In this paper, we propose PerceiverS (Segmentation and Scale), a novel architecture designed to address this issue by leveraging both Effective Segmentation and Multi-Scale attention mechanisms. Our approach enhances symbolic music generation by simultaneously learning long-term structural dependencies and short-term expressive details. By combining cross-attention and self-attention in a Multi-Scale setting, PerceiverS captures long-range musical structure while preserving performance nuances. The proposed model, evaluated on datasets like Maestro, demonstrates improvements in generating coherent and diverse music with both structural consistency and expressive variation. The project demos and the generated music samples can be accessed through the link: https://perceivers.github.io.
Towards General Industrial Intelligence: A Survey on IIoT-Enhanced Continual Large Models
Sep 02, 2024



Currently, most applications in the Industrial Internet of Things (IIoT) still rely on CNN-based neural networks. Although Transformer-based large models (LMs), including language, vision, and multimodal models, have demonstrated impressive capabilities in AI-generated content (AIGC), their application in industrial domains, such as detection, planning, and control, remains relatively limited. Deploying pre-trained LMs in industrial environments often encounters the challenge of stability and plasticity due to the complexity of tasks, the diversity of data, and the dynamic nature of user demands. To address these challenges, the pre-training and fine-tuning strategy, coupled with continual learning, has proven to be an effective solution, enabling models to adapt to dynamic demands while continuously optimizing their inference and decision-making capabilities. This paper surveys the integration of LMs into IIoT-enhanced General Industrial Intelligence (GII), focusing on two key areas: LMs for GII and LMs on GII. The former focuses on leveraging LMs to provide optimized solutions for industrial application challenges, while the latter investigates continuous optimization of LMs learning and inference capabilities in collaborative scenarios involving industrial devices, edge computing, and cloud computing. This paper provides insights into the future development of GII, aiming to establish a comprehensive theoretical framework and research direction for GII, thereby advancing GII towards a more general and adaptive future.
Time-aware Heterogeneous Graph Transformer with Adaptive Attention Merging for Health Event Prediction
Apr 23, 2024The widespread application of Electronic Health Records (EHR) data in the medical field has led to early successes in disease risk prediction using deep learning methods. These methods typically require extensive data for training due to their large parameter sets. However, existing works do not exploit the full potential of EHR data. A significant challenge arises from the infrequent occurrence of many medical codes within EHR data, limiting their clinical applicability. Current research often lacks in critical areas: 1) incorporating disease domain knowledge; 2) heterogeneously learning disease representations with rich meanings; 3) capturing the temporal dynamics of disease progression. To overcome these limitations, we introduce a novel heterogeneous graph learning model designed to assimilate disease domain knowledge and elucidate the intricate relationships between drugs and diseases. This model innovatively incorporates temporal data into visit-level embeddings and leverages a time-aware transformer alongside an adaptive attention mechanism to produce patient representations. When evaluated on two healthcare datasets, our approach demonstrated notable enhancements in both prediction accuracy and interpretability over existing methodologies, signifying a substantial advancement towards personalized and proactive healthcare management.
An Enhanced Grey Wolf Optimizer with Elite Inheritance and Balance Search Mechanisms
Apr 09, 2024The Grey Wolf Optimizer (GWO) is recognized as a novel meta-heuristic algorithm inspired by the social leadership hierarchy and hunting mechanism of grey wolves. It is well-known for its simple parameter setting, fast convergence speed, and strong optimization capability. In the original GWO, there are two significant design flaws in its fundamental optimization mechanisms. Problem (1): the algorithm fails to inherit from elite positions from the last iteration when generating the next positions of the wolf population, potentially leading to suboptimal solutions. Problem (2): the positions of the population are updated based on the central position of the three leading wolves (alpha, beta, delta), without a balanced mechanism between local and global search. To tackle these problems, an enhanced Grey Wolf Optimizer with Elite Inheritance Mechanism and Balance Search Mechanism, named as EBGWO, is proposed to improve the effectiveness of the position updating and the quality of the convergence solutions. The IEEE CEC 2014 benchmark functions suite and a series of simulation tests are employed to evaluate the performance of the proposed algorithm. The simulation tests involve a comparative study between EBGWO, three GWO variants, GWO and two well-known meta-heuristic algorithms. The experimental results demonstrate that the proposed EBGWO algorithm outperforms other meta-heuristic algorithms in both accuracy and convergence speed. Three engineering optimization problems are adopted to prove its capability in processing real-world problems. The results indicate that the proposed EBGWO outperforms several popular algorithms.
Balancing Information Perception with Yin-Yang: Agent-Based Information Neutrality Model for Recommendation Systems
Apr 07, 2024While preference-based recommendation algorithms effectively enhance user engagement by recommending personalized content, they often result in the creation of ``filter bubbles''. These bubbles restrict the range of information users interact with, inadvertently reinforcing their existing viewpoints. Previous research has focused on modifying these underlying algorithms to tackle this issue. Yet, approaches that maintain the integrity of the original algorithms remain largely unexplored. This paper introduces an Agent-based Information Neutrality model grounded in the Yin-Yang theory, namely, AbIN. This innovative approach targets the imbalance in information perception within existing recommendation systems. It is designed to integrate with these preference-based systems, ensuring the delivery of recommendations with neutral information. Our empirical evaluation of this model proved its efficacy, showcasing its capacity to expand information diversity while respecting user preferences. Consequently, AbIN emerges as an instrumental tool in mitigating the negative impact of filter bubbles on information consumption.