 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Neural Portraits
Nov 25, 2022

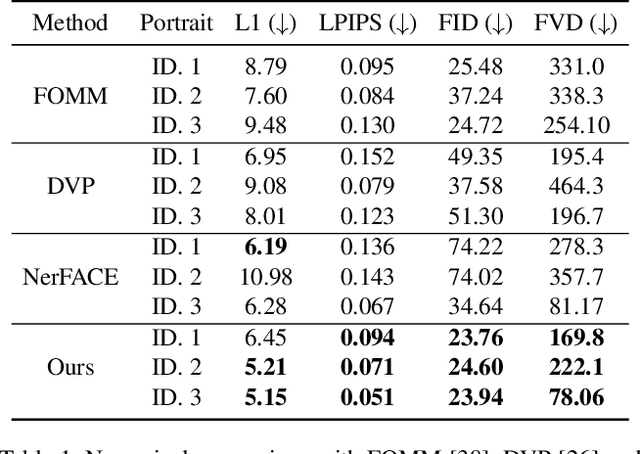
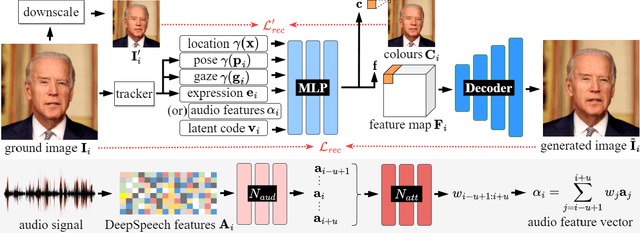
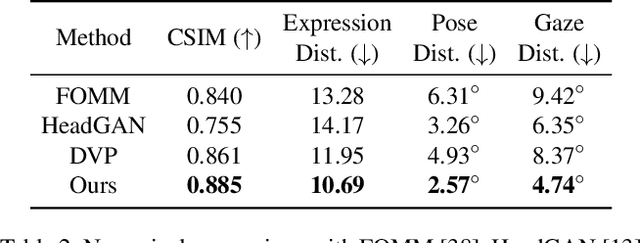
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
Efficient Feature Extraction for High-resolution Video Frame Interpolation
Nov 25, 2022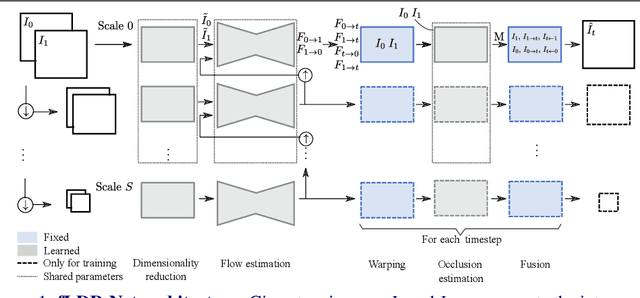
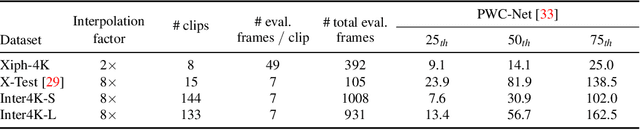
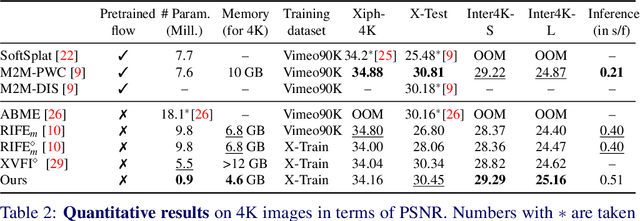
Most deep learning methods for video frame interpolation consist of three main components: feature extraction, motion estimation, and image synthesis. Existing approaches are mainly distinguishable in terms of how these modules are designed. However, when interpolating high-resolution images, e.g. at 4K, the design choices for achieving high accuracy within reasonable memory requirements are limited. The feature extraction layers help to compress the input and extract relevant information for the latter stages, such as motion estimation. However, these layers are often costly in parameters, computation time, and memory. We show how ideas from dimensionality reduction combined with a lightweight optimization can be used to compress the input representation while keeping the extracted information suitable for frame interpolation. Further, we require neither a pretrained flow network nor a synthesis network, additionally reducing the number of trainable parameters and required memory. When evaluating on three 4K benchmarks, we achieve state-of-the-art image quality among the methods without pretrained flow while having the lowest network complexity and memory requirements overall.
TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Nov 25, 2022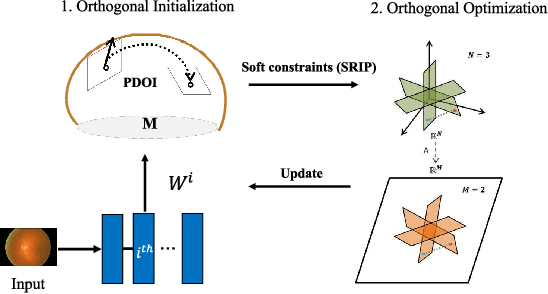
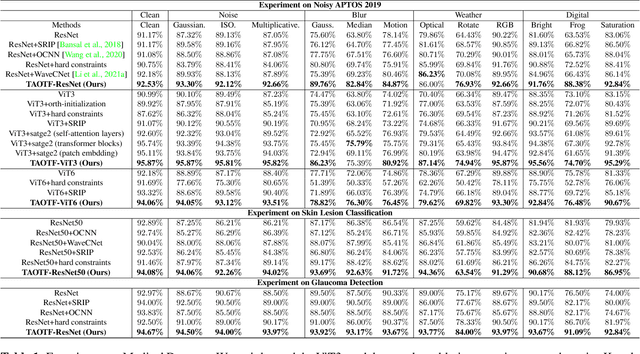
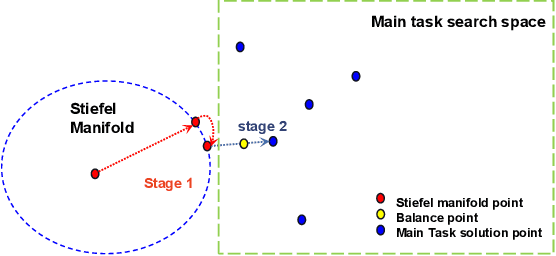
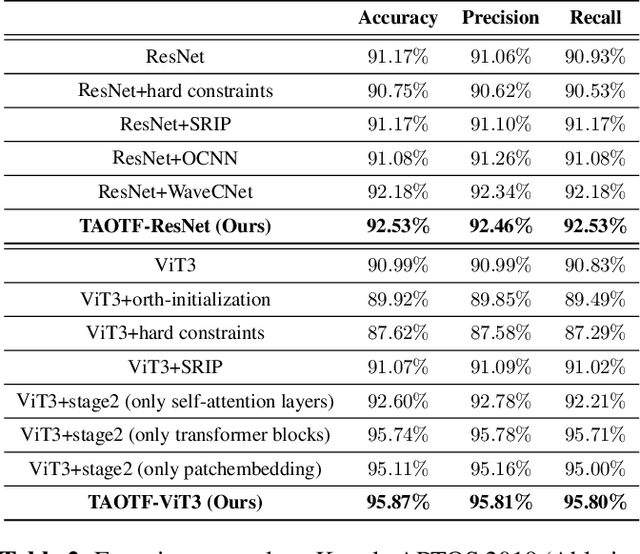
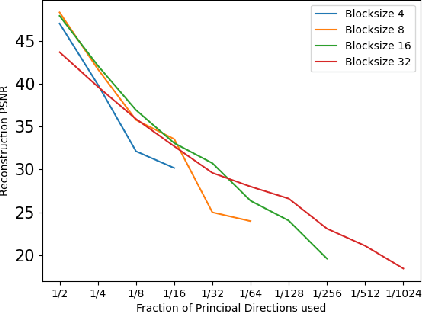
The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms
Dec 24, 2022
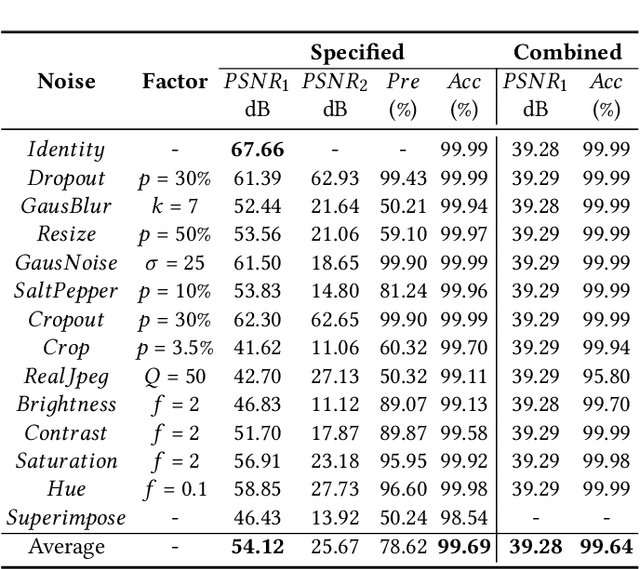
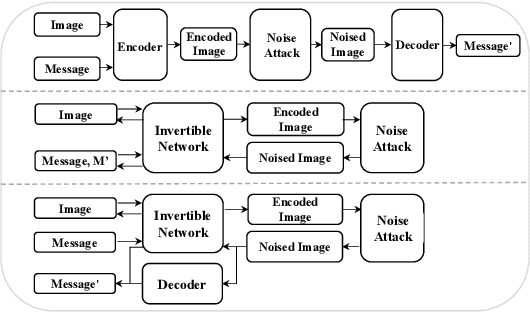
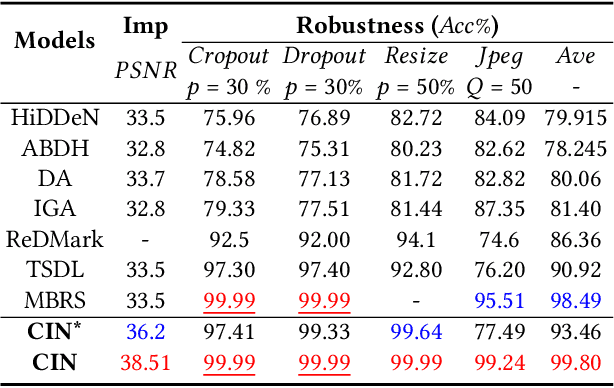
Blind watermarking provides powerful evidence for copyright protection, image authentication, and tampering identification. However, it remains a challenge to design a watermarking model with high imperceptibility and robustness against strong noise attacks. To resolve this issue, we present a framework Combining the Invertible and Non-invertible (CIN) mechanisms. The CIN is composed of the invertible part to achieve high imperceptibility and the non-invertible part to strengthen the robustness against strong noise attacks. For the invertible part, we develop a diffusion and extraction module (DEM) and a fusion and split module (FSM) to embed and extract watermarks symmetrically in an invertible way. For the non-invertible part, we introduce a non-invertible attention-based module (NIAM) and the noise-specific selection module (NSM) to solve the asymmetric extraction under a strong noise attack. Extensive experiments demonstrate that our framework outperforms the current state-of-the-art methods of imperceptibility and robustness significantly. Our framework can achieve an average of 99.99% accuracy and 67.66 dB PSNR under noise-free conditions, while 96.64% and 39.28 dB combined strong noise attacks. The code will be available in https://github.com/rmpku/CIN.
Visual Named Entity Linking: A New Dataset and A Baseline
Nov 09, 2022

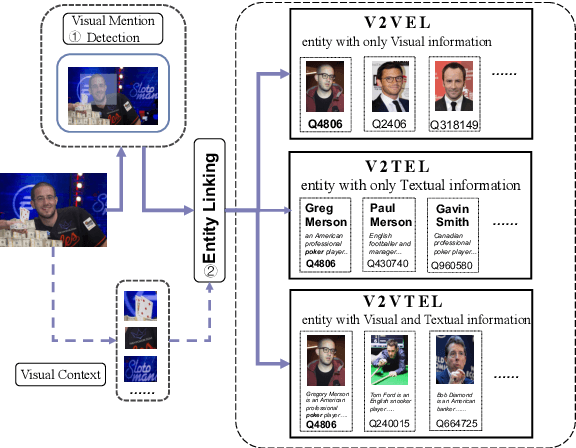
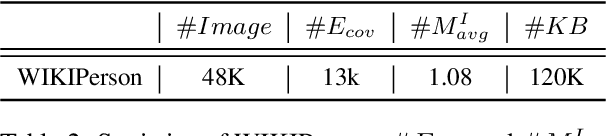
Visual Entity Linking (VEL) is a task to link regions of images with their corresponding entities in Knowledge Bases (KBs), which is beneficial for many computer vision tasks such as image retrieval, image caption, and visual question answering. While existing tasks in VEL either rely on textual data to complement a multi-modal linking or only link objects with general entities, which fails to perform named entity linking on large amounts of image data. In this paper, we consider a purely Visual-based Named Entity Linking (VNEL) task, where the input only consists of an image. The task is to identify objects of interest (i.e., visual entity mentions) in images and link them to corresponding named entities in KBs. Since each entity often contains rich visual and textual information in KBs, we thus propose three different sub-tasks, i.e., visual to visual entity linking (V2VEL), visual to textual entity linking (V2TEL), and visual to visual-textual entity linking (V2VTEL). In addition, we present a high-quality human-annotated visual person linking dataset, named WIKIPerson. Based on WIKIPerson, we establish a series of baseline algorithms for the solution of each sub-task, and conduct experiments to verify the quality of proposed datasets and the effectiveness of baseline methods. We envision this work to be helpful for soliciting more works regarding VNEL in the future. The codes and datasets are publicly available at https://github.com/ict-bigdatalab/VNEL.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 19, 2022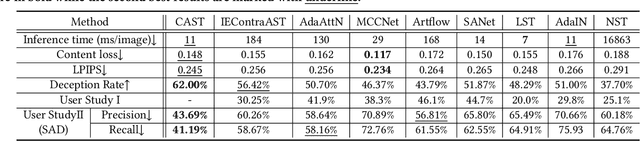

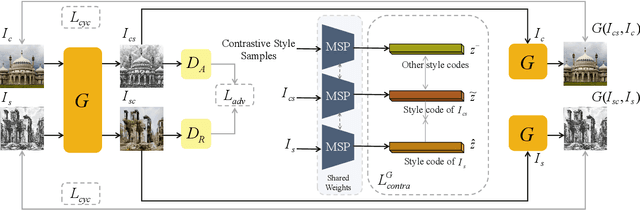
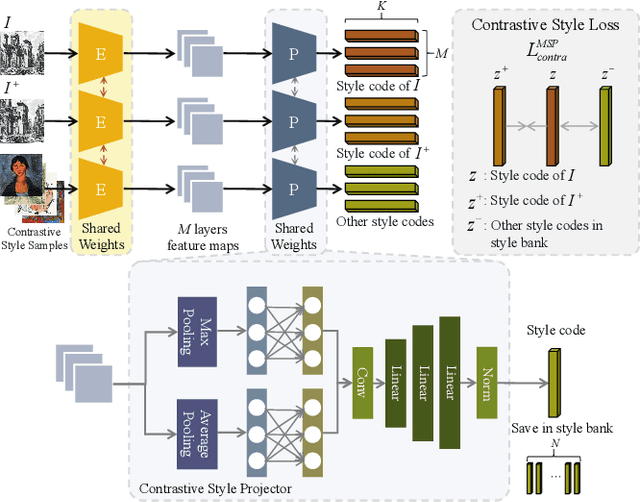
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising
Jul 16, 2022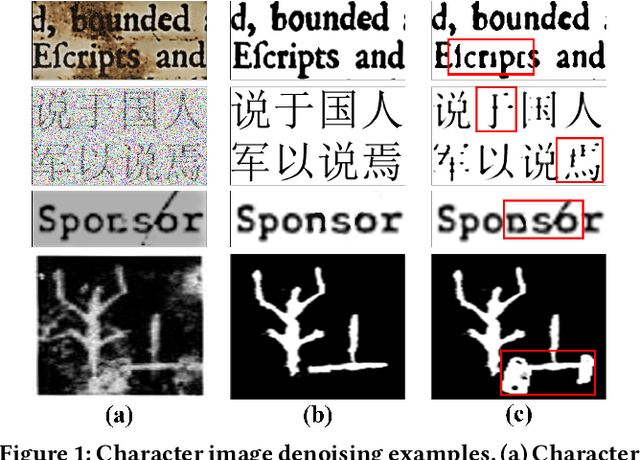
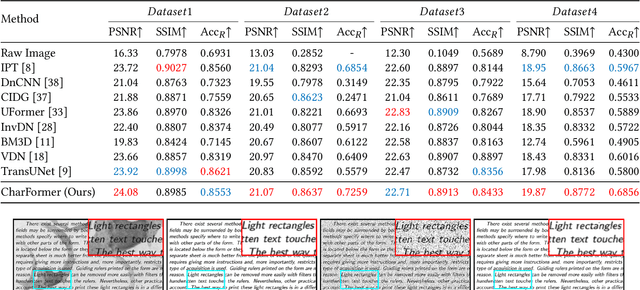
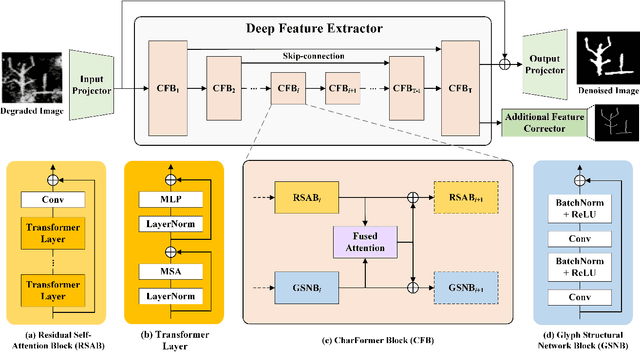
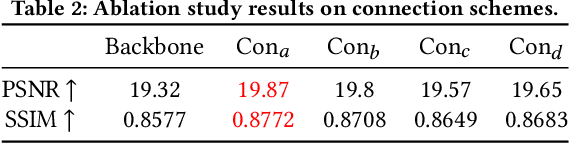
Degraded images commonly exist in the general sources of character images, leading to unsatisfactory character recognition results. Existing methods have dedicated efforts to restoring degraded character images. However, the denoising results obtained by these methods do not appear to improve character recognition performance. This is mainly because current methods only focus on pixel-level information and ignore critical features of a character, such as its glyph, resulting in character-glyph damage during the denoising process. In this paper, we introduce a novel generic framework based on glyph fusion and attention mechanisms, i.e., CharFormer, for precisely recovering character images without changing their inherent glyphs. Unlike existing frameworks, CharFormer introduces a parallel target task for capturing additional information and injecting it into the image denoising backbone, which will maintain the consistency of character glyphs during character image denoising. Moreover, we utilize attention-based networks for global-local feature interaction, which will help to deal with blind denoising and enhance denoising performance. We compare CharFormer with state-of-the-art methods on multiple datasets. The experimental results show the superiority of CharFormer quantitatively and qualitatively.
SpectNet : End-to-End Audio Signal Classification Using Learnable Spectrograms
Nov 17, 2022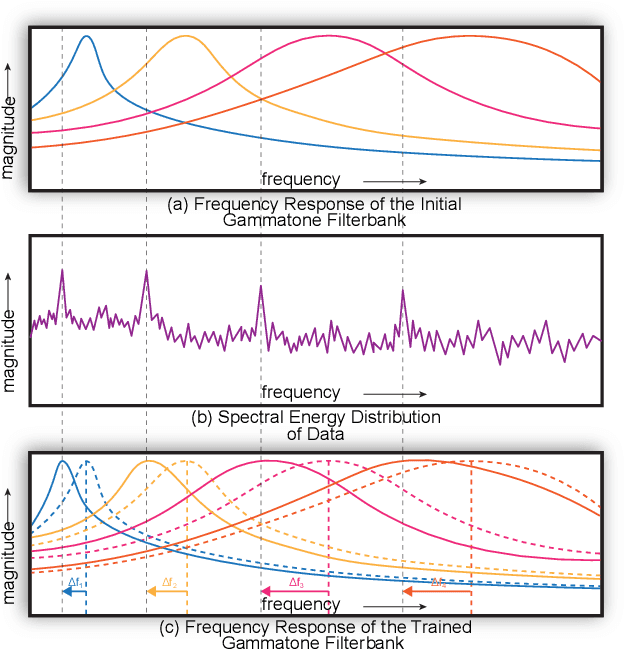
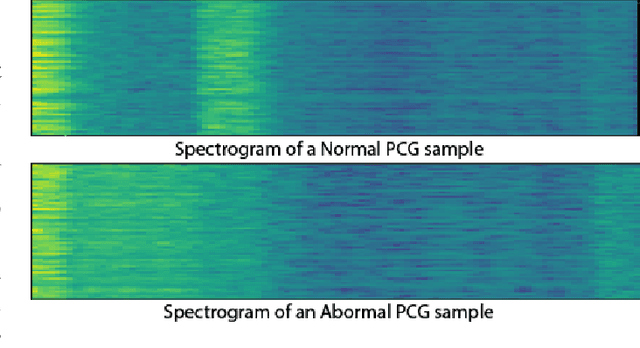
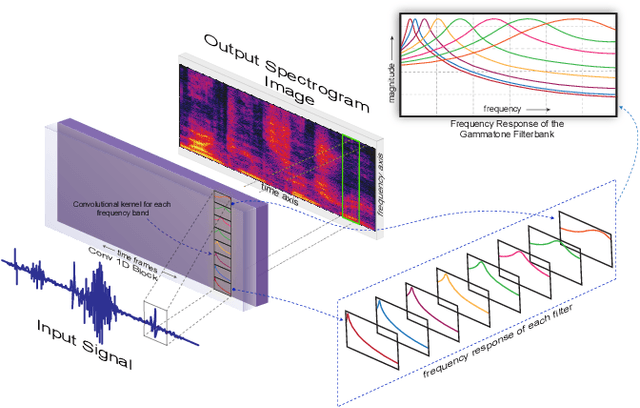
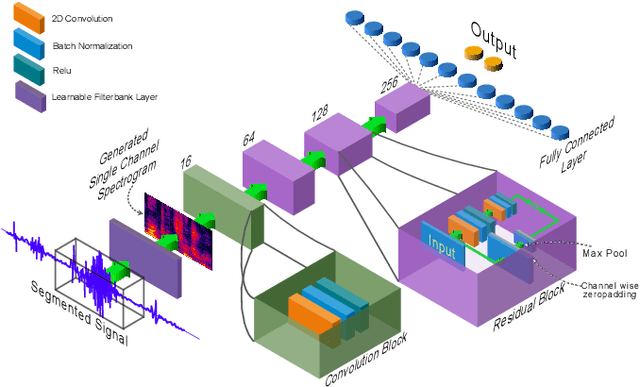
Pattern recognition from audio signals is an active research topic encompassing audio tagging, acoustic scene classification, music classification, and other areas. Spectrogram and mel-frequency cepstral coefficients (MFCC) are among the most commonly used features for audio signal analysis and classification. Recently, deep convolutional neural networks (CNN) have been successfully used for audio classification problems using spectrogram-based 2D features. In this paper, we present SpectNet, an integrated front-end layer that extracts spectrogram features within a CNN architecture that can be used for audio pattern recognition tasks. The front-end layer utilizes learnable gammatone filters that are initialized using mel-scale filters. The proposed layer outputs a 2D spectrogram image which can be fed into a 2D CNN for classification. The parameters of the entire network, including the front-end filterbank, can be updated via back-propagation. This training scheme allows for fine-tuning the spectrogram-image features according to the target audio dataset. The proposed method is evaluated in two different audio signal classification tasks: heart sound anomaly detection and acoustic scene classification. The proposed method shows a significant 1.02\% improvement in MACC for the heart sound classification task and 2.11\% improvement in accuracy for the acoustic scene classification task compared to the classical spectrogram image features. The source code of our experiments can be found at \url{https://github.com/mHealthBuet/SpectNet}
A Late Multi-Modal Fusion Model for Detecting Hybrid Spam E-mail
Oct 26, 2022
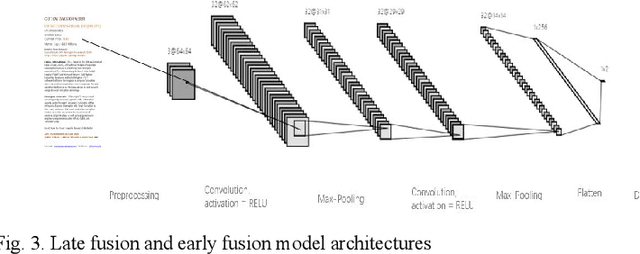
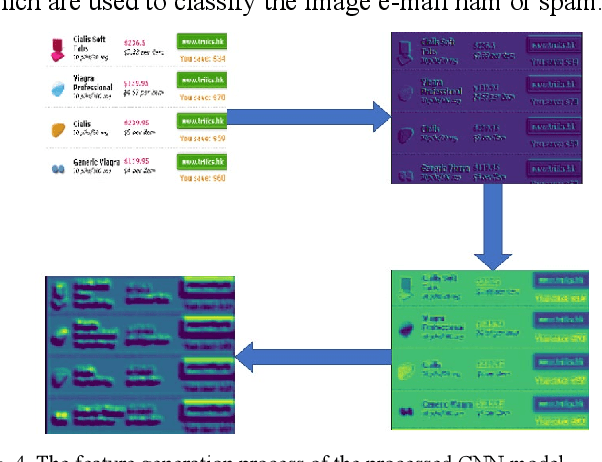

In recent years, spammers are now trying to obfuscate their intents by introducing hybrid spam e-mail combining both image and text parts, which is more challenging to detect in comparison to e-mails containing text or image only. The motivation behind this research is to design an effective approach filtering out hybrid spam e-mails to avoid situations where traditional text-based or image-baesd only filters fail to detect hybrid spam e-mails. To the best of our knowledge, a few studies have been conducted with the goal of detecting hybrid spam e-mails. Ordinarily, Optical Character Recognition (OCR) technology is used to eliminate the image parts of spam by transforming images into text. However, the research questions are that although OCR scanning is a very successful technique in processing text-and-image hybrid spam, it is not an effective solution for dealing with huge quantities due to the CPU power required and the execution time it takes to scan e-mail files. And the OCR techniques are not always reliable in the transformation processes. To address such problems, we propose new late multi-modal fusion training frameworks for a text-and-image hybrid spam e-mail filtering system compared to the classical early fusion detection frameworks based on the OCR method. Convolutional Neural Network (CNN) and Continuous Bag of Words were implemented to extract features from image and text parts of hybrid spam respectively, whereas generated features were fed to sigmoid layer and Machine Learning based classifiers including Random Forest (RF), Decision Tree (DT), Naive Bayes (NB) and Support Vector Machine (SVM) to determine the e-mail ham or spam.
Generative Negative Text Replay for Continual Vision-Language Pretraining
Oct 31, 2022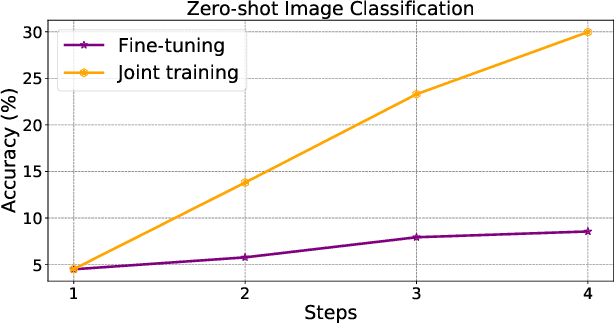
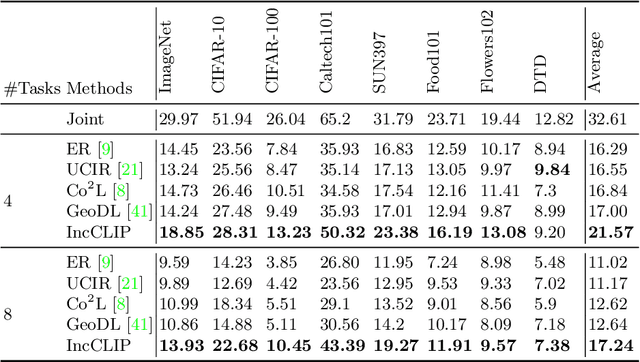
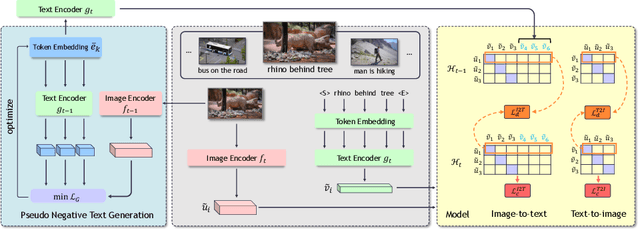
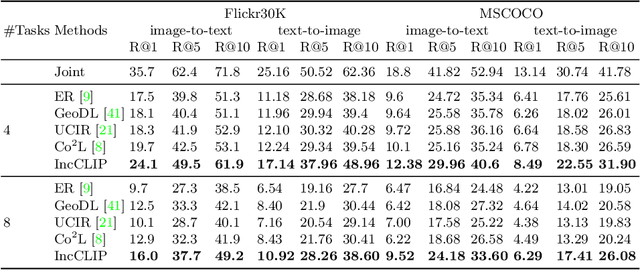
Vision-language pre-training (VLP) has attracted increasing attention recently. With a large amount of image-text pairs, VLP models trained with contrastive loss have achieved impressive performance in various tasks, especially the zero-shot generalization on downstream datasets. In practical applications, however, massive data are usually collected in a streaming fashion, requiring VLP models to continuously integrate novel knowledge from incoming data and retain learned knowledge. In this work, we focus on learning a VLP model with sequential chunks of image-text pair data. To tackle the catastrophic forgetting issue in this multi-modal continual learning setting, we first introduce pseudo text replay that generates hard negative texts conditioned on the training images in memory, which not only better preserves learned knowledge but also improves the diversity of negative samples in the contrastive loss. Moreover, we propose multi-modal knowledge distillation between images and texts to align the instance-wise prediction between old and new models. We incrementally pre-train our model on both the instance and class incremental splits of the Conceptual Caption dataset, and evaluate the model on zero-shot image classification and image-text retrieval tasks. Our method consistently outperforms the existing baselines with a large margin, which demonstrates its superiority. Notably, we realize an average performance boost of $4.60\%$ on image-classification downstream datasets for the class incremental split.