 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guided Depth Super-Resolution by Deep Anisotropic Diffusion
Nov 21, 2022
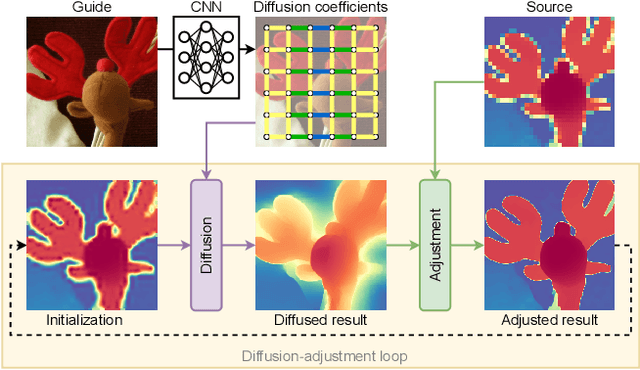
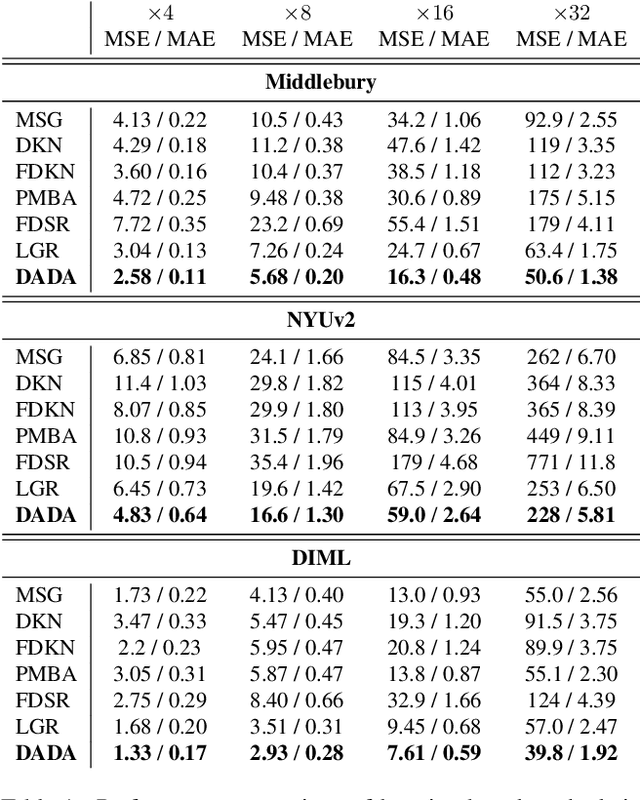
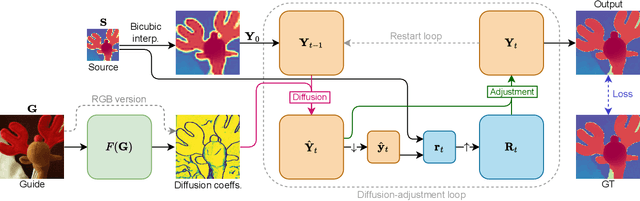
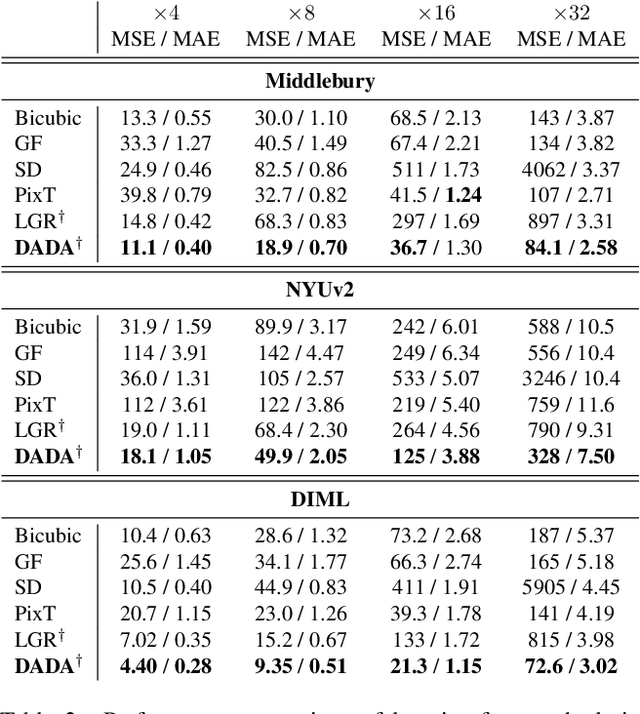
Performing super-resolution of a depth image using the guidance from an RGB image is a problem that concerns several fields, such as robotics, medical imaging, and remote sensing. While deep learning methods have achieved good results in this problem, recent work highlighted the value of combining modern methods with more formal frameworks. In this work, we propose a novel approach which combines guided anisotropic diffusion with a deep convolutional network and advances the state of the art for guided depth super-resolution. The edge transferring/enhancing properties of the diffusion are boosted by the contextual reasoning capabilities of modern networks, and a strict adjustment step guarantees perfect adherence to the source image. We achieve unprecedented results in three commonly used benchmarks for guided depth super-resolution. The performance gain compared to other methods is the largest at larger scales, such as x32 scaling. Code for the proposed method will be made available to promote reproducibility of our results.
Representative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022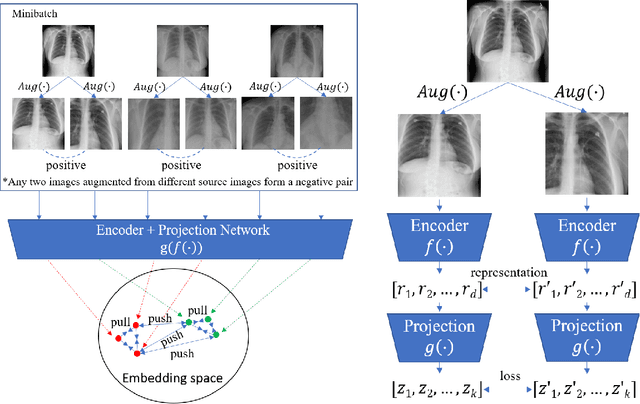
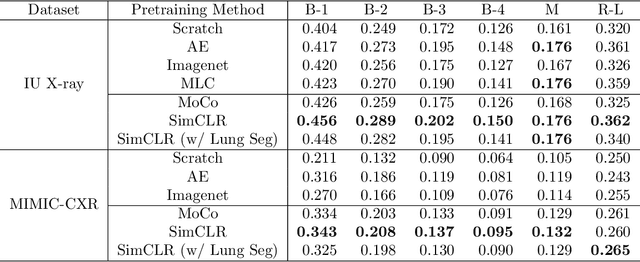

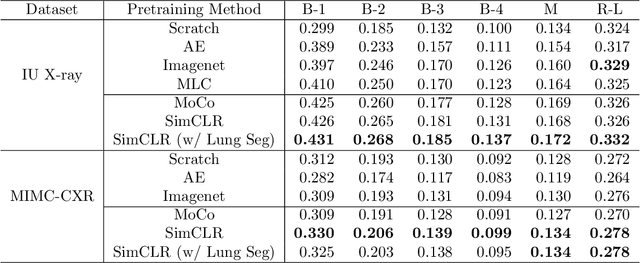
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.
Fast Nearest Convolution for Real-Time Efficient Image Super-Resolution
Aug 24, 2022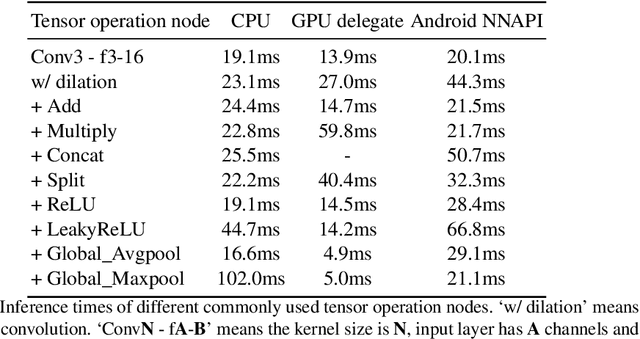
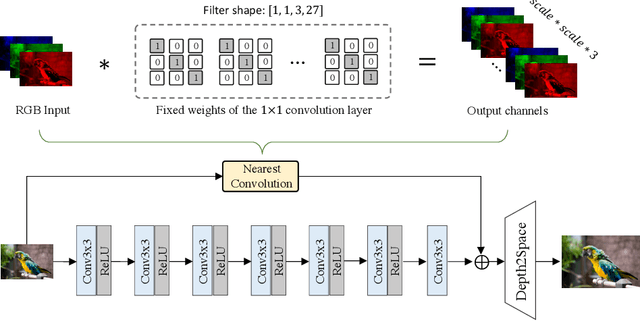
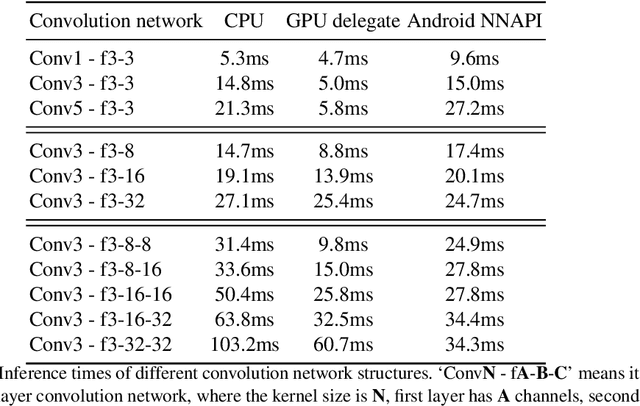

Deep learning-based single image super-resolution (SISR) approaches have drawn much attention and achieved remarkable success on modern advanced GPUs. However, most state-of-the-art methods require a huge number of parameters, memories, and computational resources, which usually show inferior inference times when applying them to current mobile device CPUs/NPUs. In this paper, we propose a simple plain convolution network with a fast nearest convolution module (NCNet), which is NPU-friendly and can perform a reliable super-resolution in real-time. The proposed nearest convolution has the same performance as the nearest upsampling but is much faster and more suitable for Android NNAPI. Our model can be easily deployed on mobile devices with 8-bit quantization and is fully compatible with all major mobile AI accelerators. Moreover, we conduct comprehensive experiments on different tensor operations on a mobile device to illustrate the efficiency of our network architecture. Our NCNet is trained and validated on the DIV2K 3x dataset, and the comparison with other efficient SR methods demonstrated that the NCNet can achieve high fidelity SR results while using fewer inference times. Our codes and pretrained models are publicly available at \url{https://github.com/Algolzw/NCNet}.
PO-ELIC: Perception-Oriented Efficient Learned Image Coding
May 28, 2022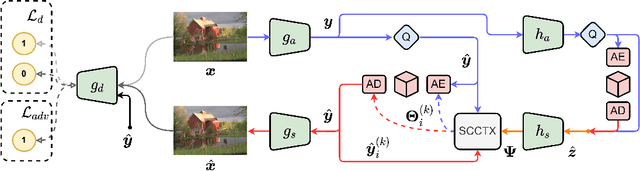

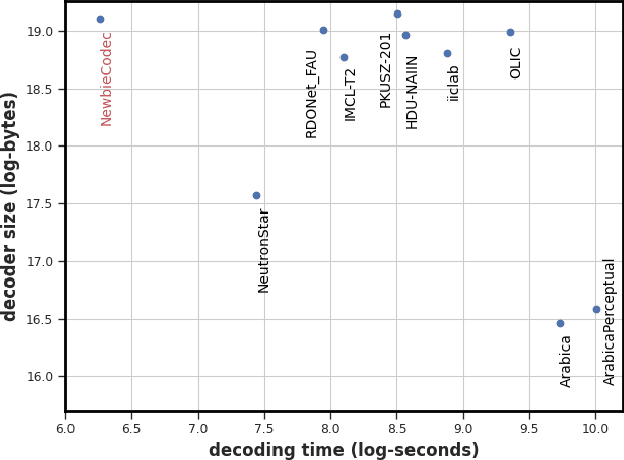

In the past years, learned image compression (LIC) has achieved remarkable performance. The recent LIC methods outperform VVC in both PSNR and MS-SSIM. However, the low bit-rate reconstructions of LIC suffer from artifacts such as blurring, color drifting and texture missing. Moreover, those varied artifacts make image quality metrics correlate badly with human perceptual quality. In this paper, we propose PO-ELIC, i.e., Perception-Oriented Efficient Learned Image Coding. To be specific, we adapt ELIC, one of the state-of-the-art LIC models, with adversarial training techniques. We apply a mixture of losses including hinge-form adversarial loss, Charbonnier loss, and style loss, to finetune the model towards better perceptual quality. Experimental results demonstrate that our method achieves comparable perceptual quality with HiFiC with much lower bitrate.
Test-time Adaptation with Calibration of Medical Image Classification Nets for Label Distribution Shift
Jul 09, 2022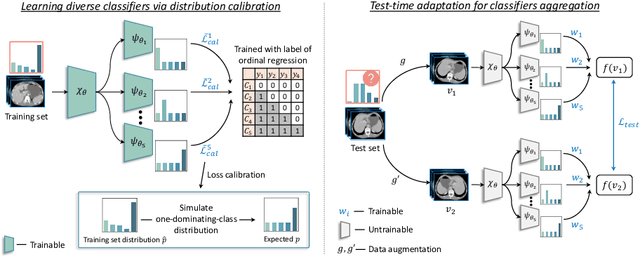
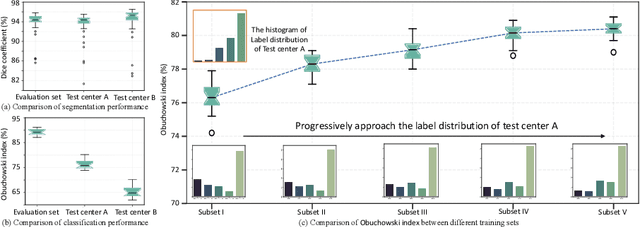
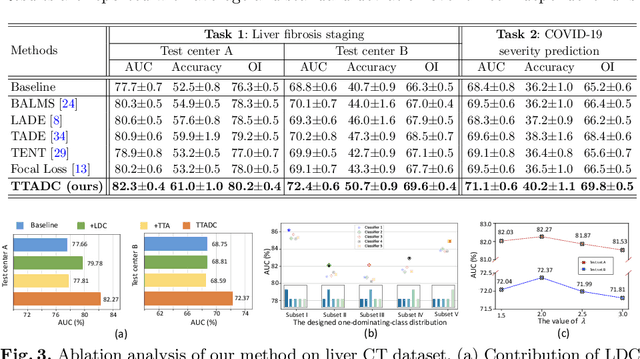
Class distribution plays an important role in learning deep classifiers. When the proportion of each class in the test set differs from the training set, the performance of classification nets usually degrades. Such a label distribution shift problem is common in medical diagnosis since the prevalence of disease vary over location and time. In this paper, we propose the first method to tackle label shift for medical image classification, which effectively adapt the model learned from a single training label distribution to arbitrary unknown test label distribution. Our approach innovates distribution calibration to learn multiple representative classifiers, which are capable of handling different one-dominating-class distributions. When given a test image, the diverse classifiers are dynamically aggregated via the consistency-driven test-time adaptation, to deal with the unknown test label distribution. We validate our method on two important medical image classification tasks including liver fibrosis staging and COVID-19 severity prediction. Our experiments clearly show the decreased model performance under label shift. With our method, model performance significantly improves on all the test datasets with different label shifts for both medical image diagnosis tasks.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 12, 2022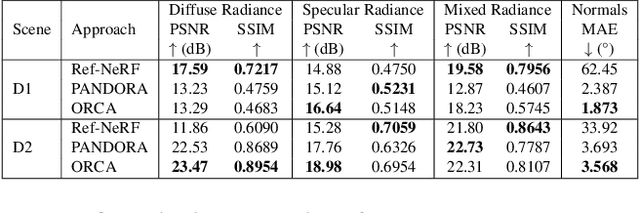
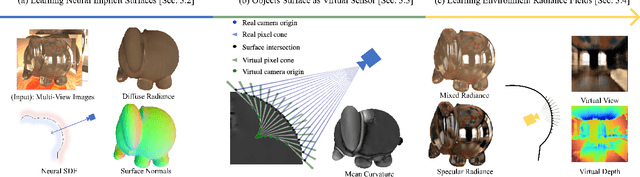
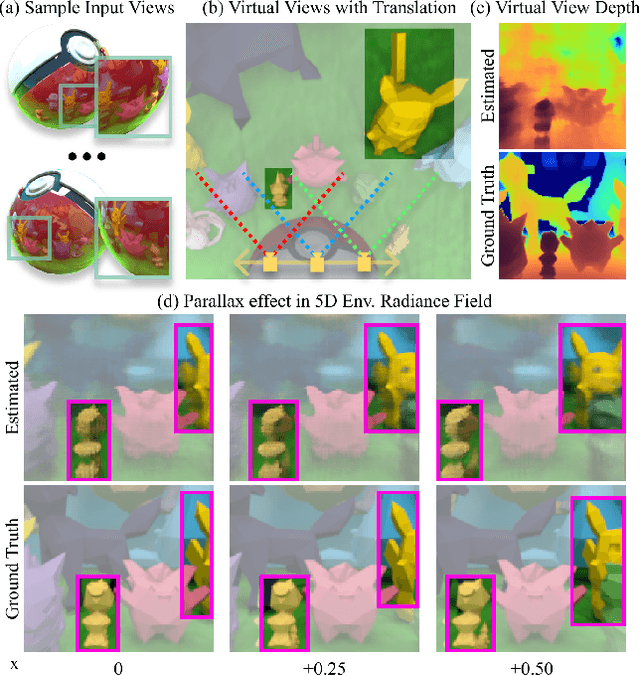
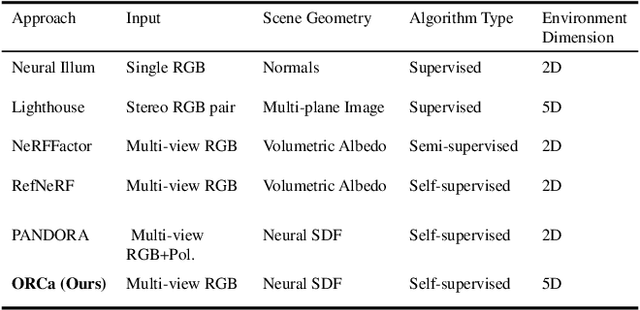
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022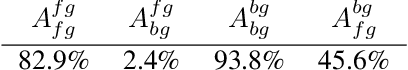



Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Blind Image Deconvolution Using Variational Deep Image Prior
Feb 01, 2022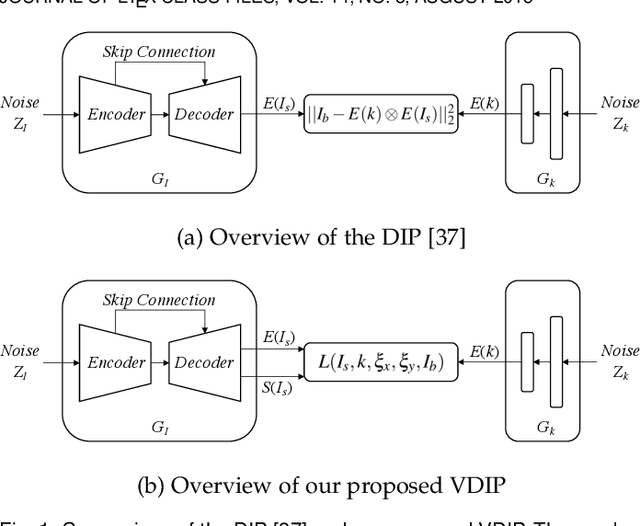
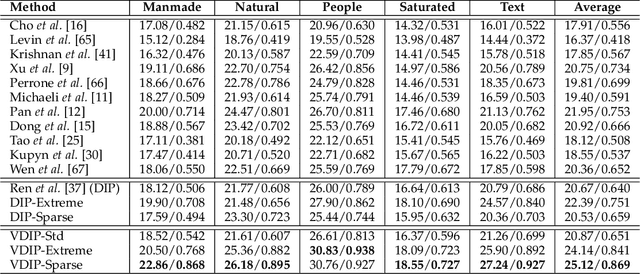
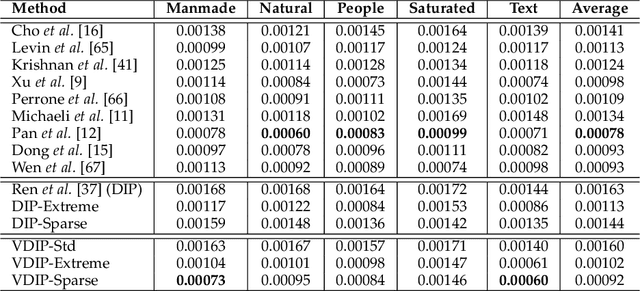
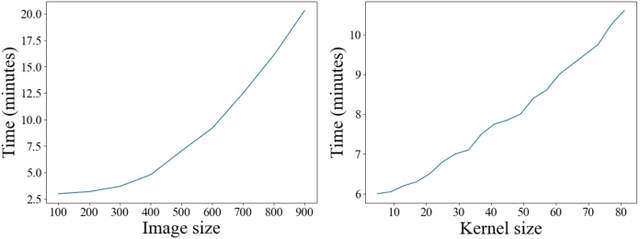
Conventional deconvolution methods utilize hand-crafted image priors to constrain the optimization. While deep-learning-based methods have simplified the optimization by end-to-end training, they fail to generalize well to blurs unseen in the training dataset. Thus, training image-specific models is important for higher generalization. Deep image prior (DIP) provides an approach to optimize the weights of a randomly initialized network with a single degraded image by maximum a posteriori (MAP), which shows that the architecture of a network can serve as the hand-crafted image prior. Different from the conventional hand-crafted image priors that are statistically obtained, it is hard to find a proper network architecture because the relationship between images and their corresponding network architectures is unclear. As a result, the network architecture cannot provide enough constraint for the latent sharp image. This paper proposes a new variational deep image prior (VDIP) for blind image deconvolution, which exploits additive hand-crafted image priors on latent sharp images and approximates a distribution for each pixel to avoid suboptimal solutions. Our mathematical analysis shows that the proposed method can better constrain the optimization. The experimental results further demonstrate that the generated images have better quality than that of the original DIP on benchmark datasets. The source code of our VDIP is available at https://github.com/Dong-Huo/VDIP-Deconvolution.
I2I: Image to Icosahedral Projection for $\mathrm{SO}(3)$ Object Reasoning from Single-View Images
Jul 18, 2022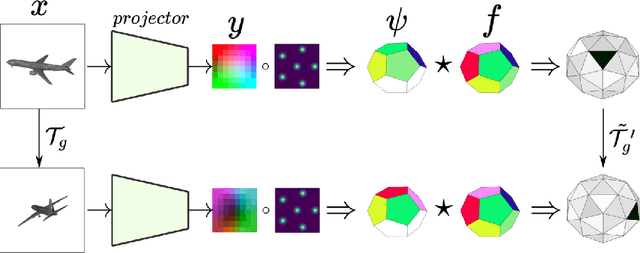
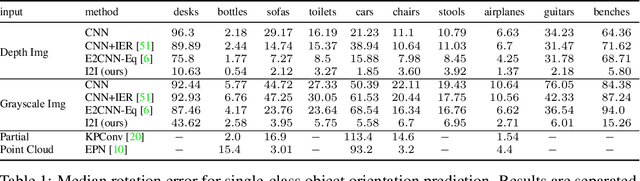
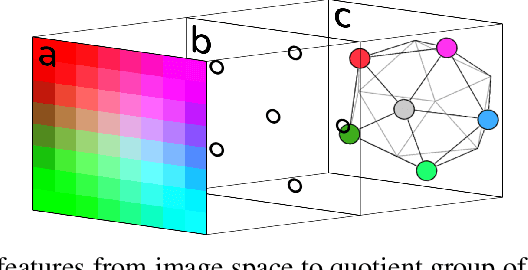
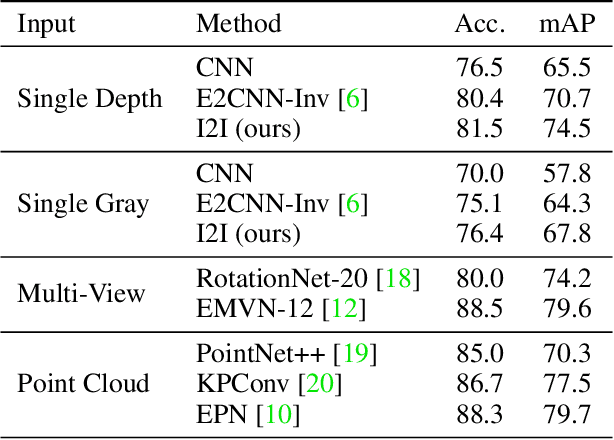
Reasoning about 3D objects based on 2D images is challenging due to large variations in appearance caused by viewing the object from different orientations. Ideally, our model would be invariant or equivariant to changes in object pose. Unfortunately, this is typically not possible with 2D image input because we do not have an a priori model of how the image would change under out-of-plane object rotations. The only $\mathrm{SO}(3)$-equivariant models that currently exist require point cloud input rather than 2D images. In this paper, we propose a novel model architecture based on icosahedral group convolution that reasons in $\mathrm{SO(3)}$ by projecting the input image onto an icosahedron. As a result of this projection, the model is approximately equivariant to rotation in $\mathrm{SO}(3)$. We apply this model to an object pose estimation task and find that it outperforms reasonable baselines.
GLeaD: Improving GANs with A Generator-Leading Task
Dec 07, 2022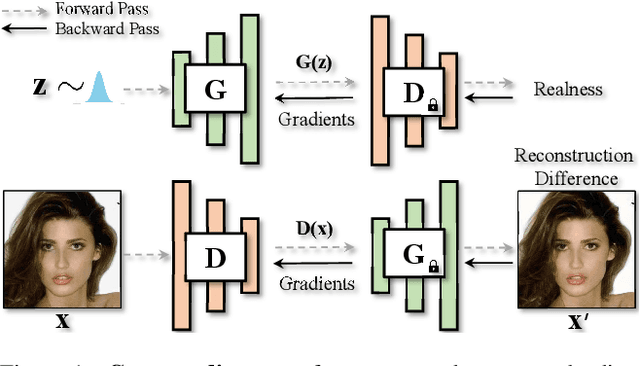
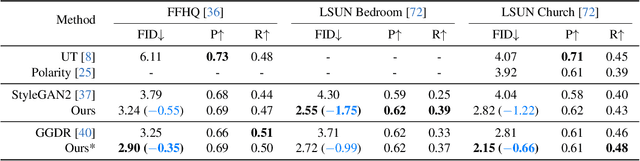


Generative adversarial network (GAN) is formulated as a two-player game between a generator (G) and a discriminator (D), where D is asked to differentiate whether an image comes from real data or is produced by G. Under such a formulation, D plays as the rule maker and hence tends to dominate the competition. Towards a fairer game in GANs, we propose a new paradigm for adversarial training, which makes G assign a task to D as well. Specifically, given an image, we expect D to extract representative features that can be adequately decoded by G to reconstruct the input. That way, instead of learning freely, D is urged to align with the view of G for domain classification. Experimental results on various datasets demonstrate the substantial superiority of our approach over the baselines. For instance, we improve the FID of StyleGAN2 from 4.30 to 2.55 on LSUN Bedroom and from 4.04 to 2.82 on LSUN Church. We believe that the pioneering attempt present in this work could inspire the community with better designed generator-leading tasks for GAN improvement.