 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extracting Training Data from Diffusion Models
Jan 30, 2023



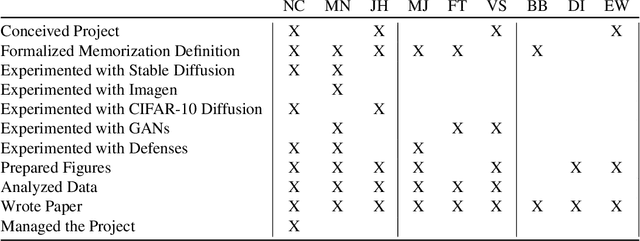
Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
Adversarially Slicing Generative Networks: Discriminator Slices Feature for One-Dimensional Optimal Transport
Jan 30, 2023
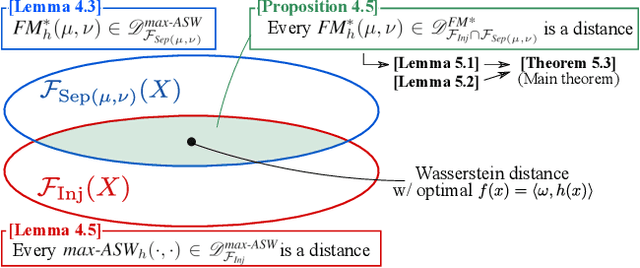
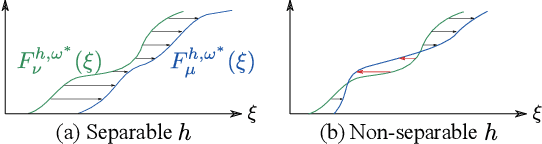

Generative adversarial networks (GANs) learn a target probability distribution by optimizing a generator and a discriminator with minimax objectives. This paper addresses the question of whether such optimization actually provides the generator with gradients that make its distribution close to the target distribution. We derive sufficient conditions for the discriminator to serve as the distance between the distributions by connecting the GAN formulation with the concept of sliced optimal transport. Furthermore, by leveraging these theoretical results, we propose a novel GAN training scheme, called adversarially slicing generative network (ASGN). With only simple modifications, the ASGN is applicable to a broad class of existing GANs. Experiments on synthetic and image datasets support our theoretical results and the ASGN's effectiveness as compared to usual GANs.
SEMICON: A Learning-to-hash Solution for Large-scale Fine-grained Image Retrieval
Sep 28, 2022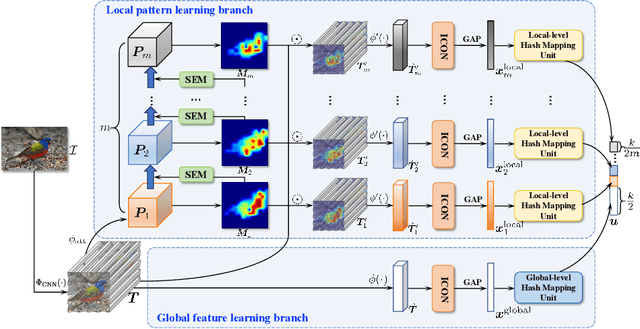
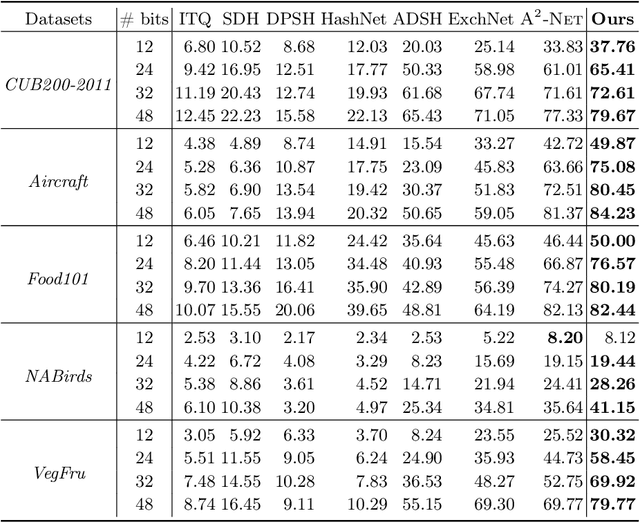
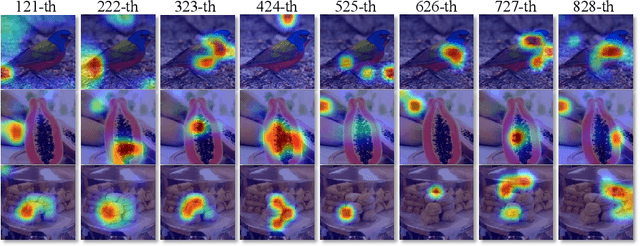
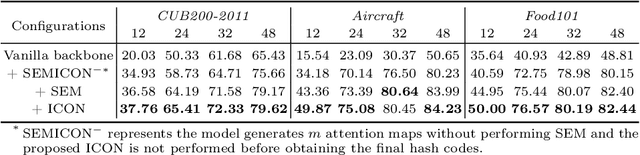
In this paper, we propose Suppression-Enhancing Mask based attention and Interactive Channel transformatiON (SEMICON) to learn binary hash codes for dealing with large-scale fine-grained image retrieval tasks. In SEMICON, we first develop a suppression-enhancing mask (SEM) based attention to dynamically localize discriminative image regions. More importantly, different from existing attention mechanism simply erasing previous discriminative regions, our SEM is developed to restrain such regions and then discover other complementary regions by considering the relation between activated regions in a stage-by-stage fashion. In each stage, the interactive channel transformation (ICON) module is afterwards designed to exploit correlations across channels of attended activation tensors. Since channels could generally correspond to the parts of fine-grained objects, the part correlation can be also modeled accordingly, which further improves fine-grained retrieval accuracy. Moreover, to be computational economy, ICON is realized by an efficient two-step process. Finally, the hash learning of our SEMICON consists of both global- and local-level branches for better representing fine-grained objects and then generating binary hash codes explicitly corresponding to multiple levels. Experiments on five benchmark fine-grained datasets show our superiority over competing methods.
An Image Processing approach to identify solar plages observed at 393.37 nm by Kodaikanal Solar Observatory
Oct 03, 2022



Solar Plages are bright chromospheric features observed in Ca II K photographic observations of the sun. These are regions of high magnetic field concentration thus tracer of magnetic activity of the Sun and are one of the most important features to study long term variability of the Sun as Ca II K spectroheliograms are recorded for more than a century. . However, detection of the plages from century-long databases is a non-trivial task and need significant human resources for doing it manually. Hence, in this study we propose an image processing algorithm which can identify solar plages from Ca II K photographic observations. The proposed study has been implemented on archival data from Kodaikanal Solar Observatory. To ensure that the algorithm works, irrespective of noise level, brightness and other image properties, we randomly draw a samples of images from data archive to test our algorithm.
UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models
Feb 09, 2023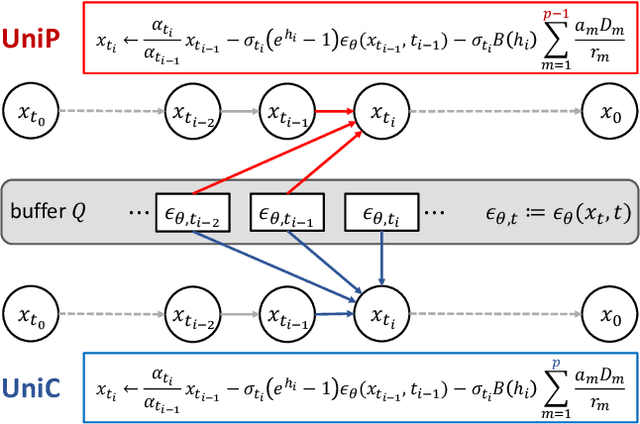
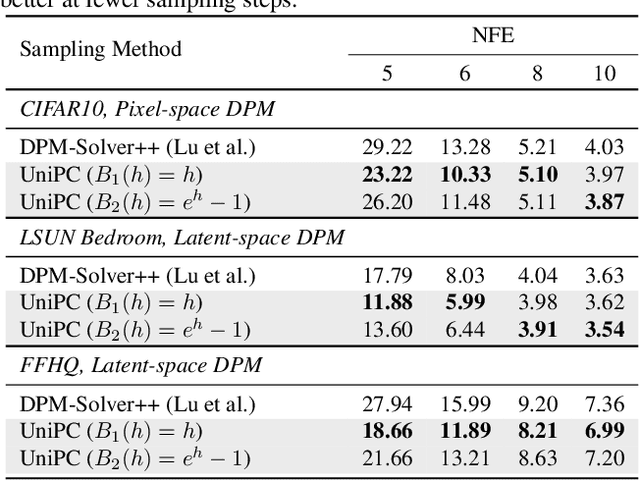

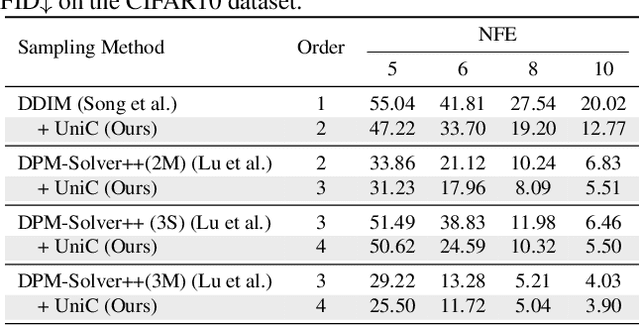
Diffusion probabilistic models (DPMs) have demonstrated a very promising ability in high-resolution image synthesis. However, sampling from a pre-trained DPM usually requires hundreds of model evaluations, which is computationally expensive. Despite recent progress in designing high-order solvers for DPMs, there still exists room for further speedup, especially in extremely few steps (e.g., 5~10 steps). Inspired by the predictor-corrector for ODE solvers, we develop a unified corrector (UniC) that can be applied after any existing DPM sampler to increase the order of accuracy without extra model evaluations, and derive a unified predictor (UniP) that supports arbitrary order as a byproduct. Combining UniP and UniC, we propose a unified predictor-corrector framework called UniPC for the fast sampling of DPMs, which has a unified analytical form for any order and can significantly improve the sampling quality over previous methods. We evaluate our methods through extensive experiments including both unconditional and conditional sampling using pixel-space and latent-space DPMs. Our UniPC can achieve 3.87 FID on CIFAR10 (unconditional) and 7.51 FID on ImageNet 256$\times$256 (conditional) with only 10 function evaluations. Code is available at https://github.com/wl-zhao/UniPC
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 09, 2023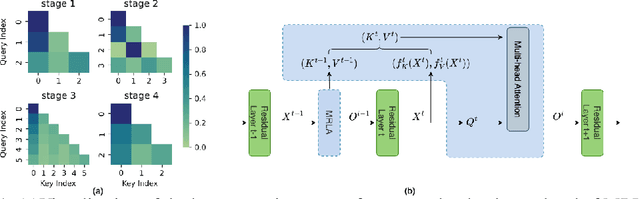
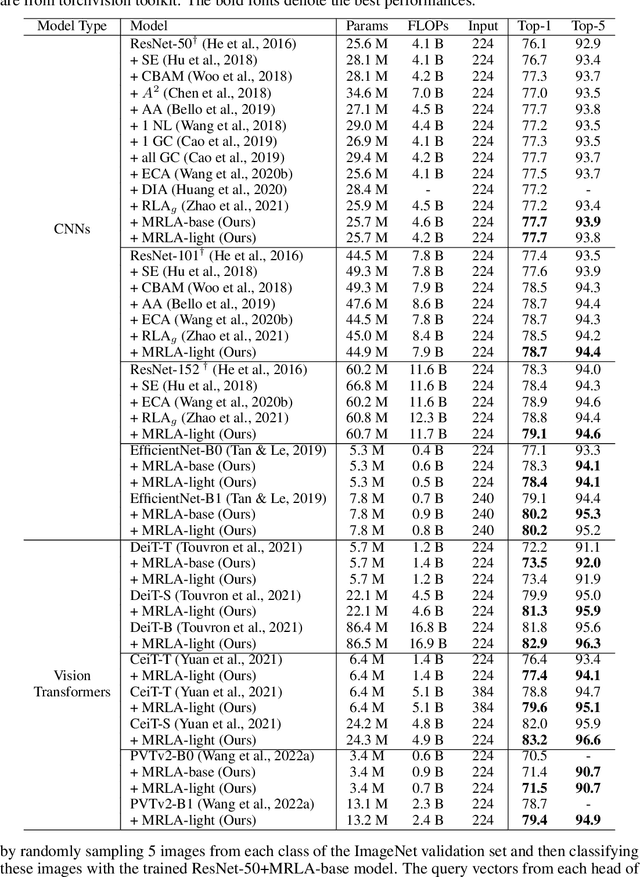
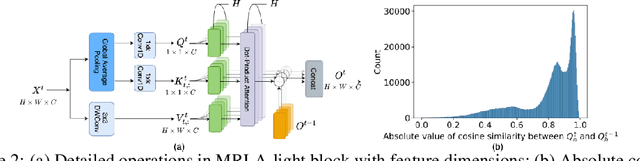
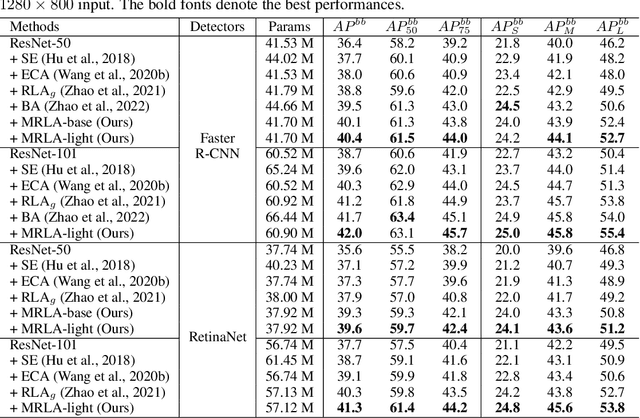
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6\% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4\% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Benchmarks for Automated Commonsense Reasoning: A Survey
Feb 09, 2023

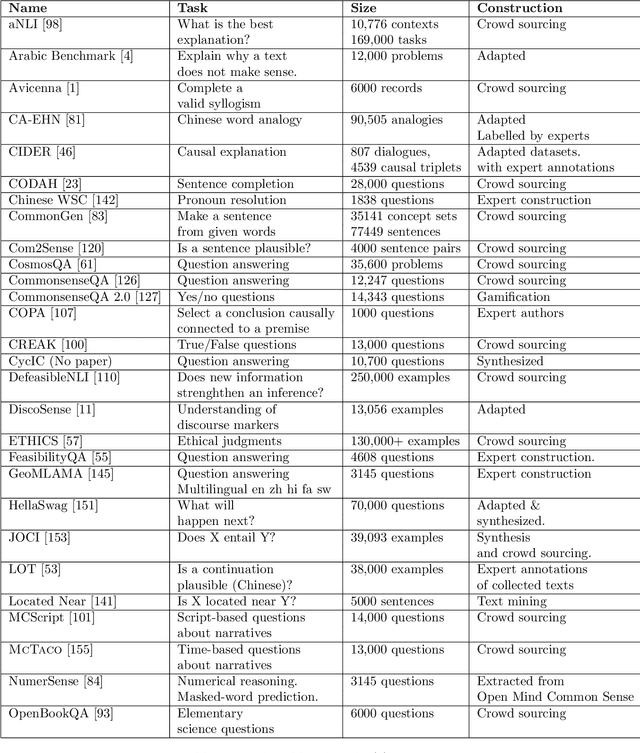

More than one hundred benchmarks have been developed to test the commonsense knowledge and commonsense reasoning abilities of artificial intelligence (AI) systems. However, these benchmarks are often flawed and many aspects of common sense remain untested. Consequently, we do not currently have any reliable way of measuring to what extent existing AI systems have achieved these abilities. This paper surveys the development and uses of AI commonsense benchmarks. We discuss the nature of common sense; the role of common sense in AI; the goals served by constructing commonsense benchmarks; and desirable features of commonsense benchmarks. We analyze the common flaws in benchmarks, and we argue that it is worthwhile to invest the work needed ensure that benchmark examples are consistently high quality. We survey the various methods of constructing commonsense benchmarks. We enumerate 139 commonsense benchmarks that have been developed: 102 text-based, 18 image-based, 12 video based, and 7 simulated physical environments. We discuss the gaps in the existing benchmarks and aspects of commonsense reasoning that are not addressed in any existing benchmark. We conclude with a number of recommendations for future development of commonsense AI benchmarks.
DeepCAM: A Fully CAM-based Inference Accelerator with Variable Hash Lengths for Energy-efficient Deep Neural Networks
Feb 09, 2023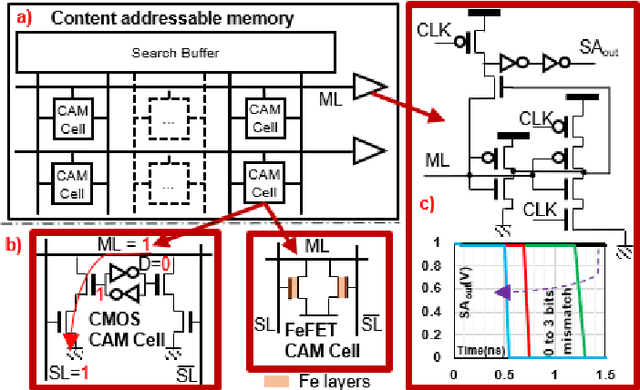
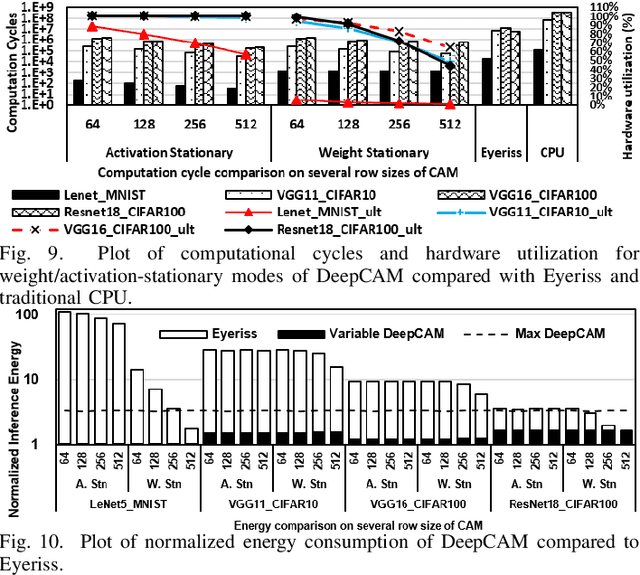
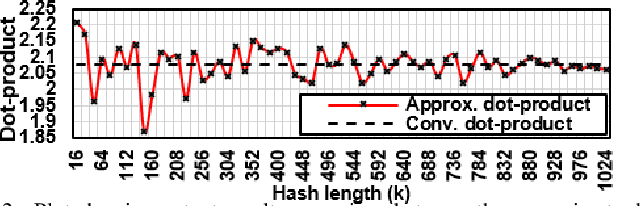
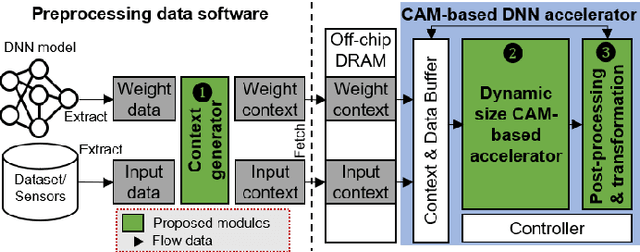
With ever increasing depth and width in deep neural networks to achieve state-of-the-art performance, deep learning computation has significantly grown, and dot-products remain dominant in overall computation time. Most prior works are built on conventional dot-product where weighted input summation is used to represent the neuron operation. However, another implementation of dot-product based on the notion of angles and magnitudes in the Euclidean space has attracted limited attention. This paper proposes DeepCAM, an inference accelerator built on two critical innovations to alleviate the computation time bottleneck of convolutional neural networks. The first innovation is an approximate dot-product built on computations in the Euclidean space that can replace addition and multiplication with simple bit-wise operations. The second innovation is a dynamic size content addressable memory-based (CAM-based) accelerator to perform bit-wise operations and accelerate the CNNs with a lower computation time. Our experiments on benchmark image recognition datasets demonstrate that DeepCAM is up to 523x and 3498x faster than Eyeriss and traditional CPUs like Intel Skylake, respectively. Furthermore, the energy consumed by our DeepCAM approach is 2.16x to 109x less compared to Eyeriss.
* Accepted to Design, Automation and Test in Europe (DATE) Conference, 2023
Optimized Hybrid Focal Margin Loss for Crack Segmentation
Feb 09, 2023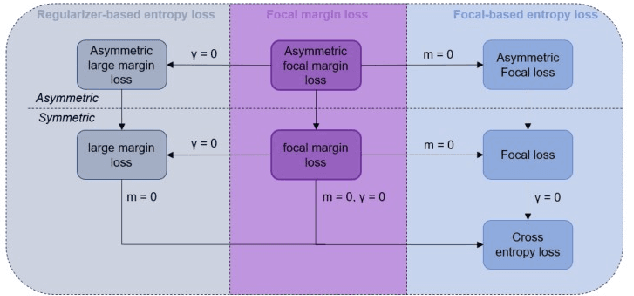
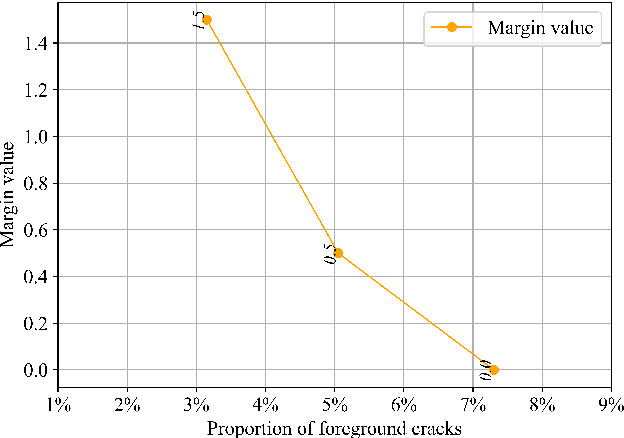

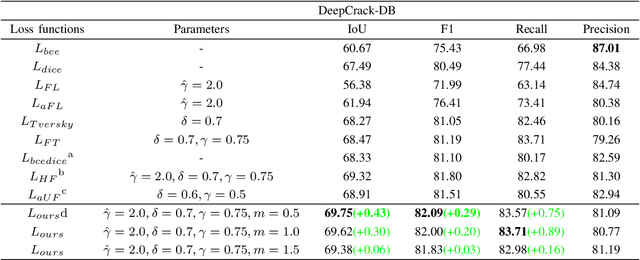
Many loss functions have been derived from cross-entropy loss functions such as large-margin softmax loss and focal loss. The large-margin softmax loss makes the classification more rigorous and prevents overfitting. The focal loss alleviates class imbalance in object detection by down-weighting the loss of well-classified examples. Recent research has shown that these two loss functions derived from cross entropy have valuable applications in the field of image segmentation. However, to the best of our knowledge, there is no unified formulation that combines these two loss functions so that they can not only be transformed mutually, but can also be used to simultaneously address class imbalance and overfitting. To this end, we subdivide the entropy-based loss into the regularizer-based entropy loss and the focal-based entropy loss, and propose a novel optimized hybrid focal loss to handle extreme class imbalance and prevent overfitting for crack segmentation. We have evaluated our proposal in comparison with three crack segmentation datasets (DeepCrack-DB, CRACK500 and our private PanelCrack dataset). Our experiments demonstrate that the focal margin component can significantly increase the IoU of cracks by 0.43 on DeepCrack-DB and 0.44 on our PanelCrack dataset, respectively.
PredRecon: A Prediction-boosted Planning Framework for Fast and High-quality Autonomous Aerial Reconstruction
Feb 09, 2023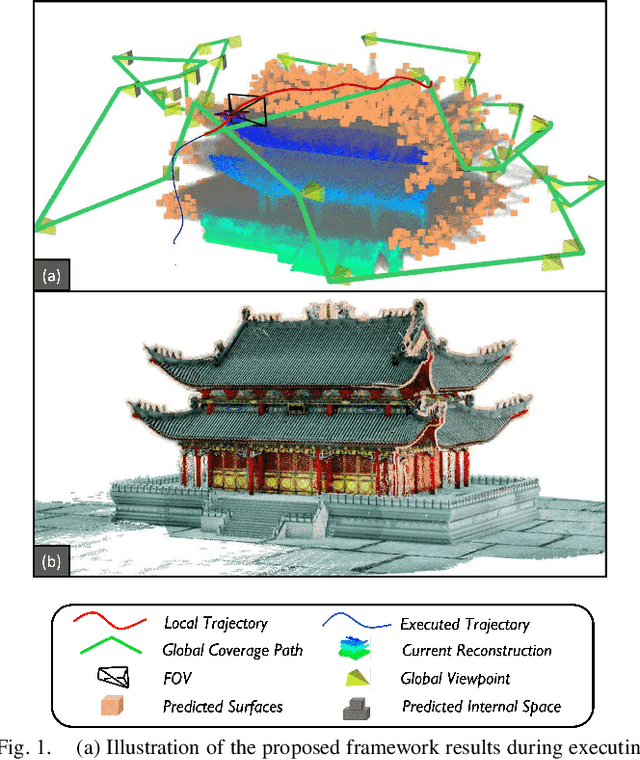
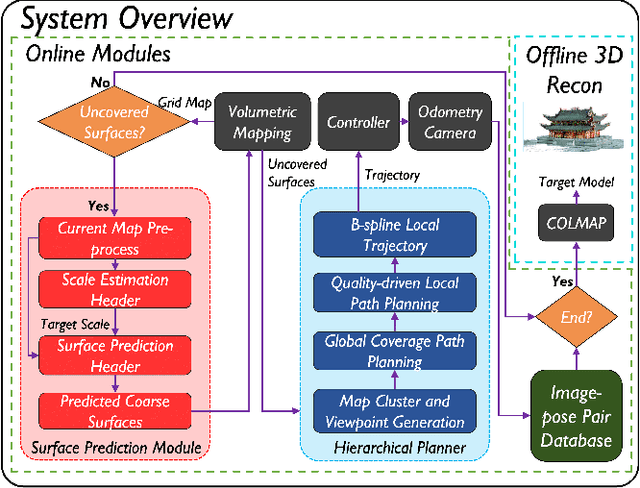
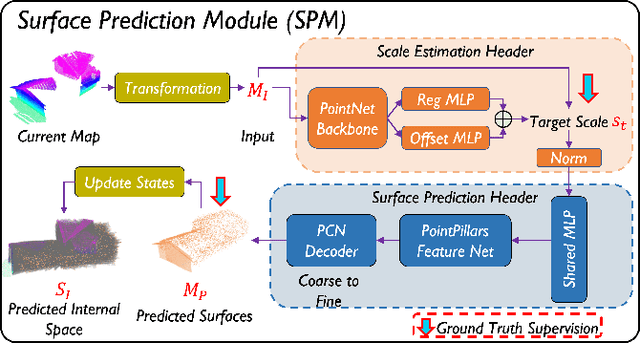
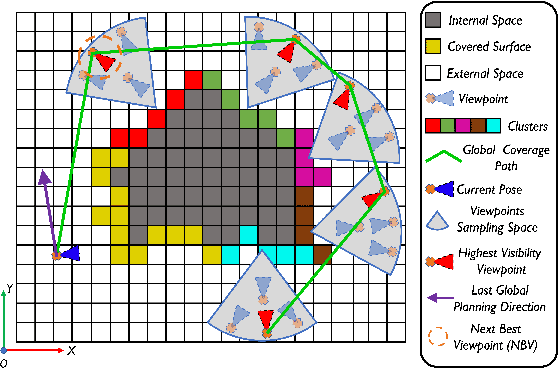
Autonomous UAV path planning for 3D reconstruction has been actively studied in various applications for high-quality 3D models. However, most existing works have adopted explore-then-exploit, prior-based or exploration-based strategies, demonstrating inefficiency with repeated flight and low autonomy. In this paper, we propose PredRecon, a prediction-boosted planning framework that can autonomously generate paths for high 3D reconstruction quality. We obtain inspiration from humans can roughly infer the complete construction structure from partial observation. Hence, we devise a surface prediction module (SPM) to predict the coarse complete surfaces of the target from the current partial reconstruction. Then, the uncovered surfaces are produced by online volumetric mapping waiting for observation by UAV. Lastly, a hierarchical planner plans motions for 3D reconstruction, which sequentially finds efficient global coverage paths, plans local paths for maximizing the performance of Multi-View Stereo (MVS), and generates smooth trajectories for image-pose pairs acquisition. We conduct benchmarks in the realistic simulator, which validates the performance of PredRecon compared with the classical and state-of-the-art methods. The open-source code is released at https://github.com/HKUST-Aerial-Robotics/PredRecon.