 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Diverse Tone Styles for Image Retouching
Jul 12, 2022



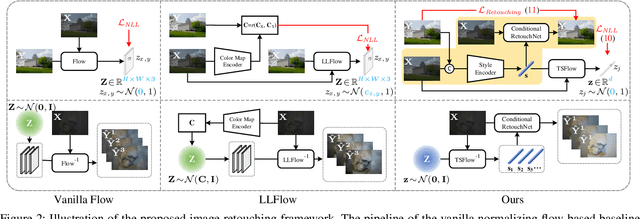
Image retouching, aiming to regenerate the visually pleasing renditions of given images, is a subjective task where the users are with different aesthetic sensations. Most existing methods deploy a deterministic model to learn the retouching style from a specific expert, making it less flexible to meet diverse subjective preferences. Besides, the intrinsic diversity of an expert due to the targeted processing on different images is also deficiently described. To circumvent such issues, we propose to learn diverse image retouching with normalizing flow-based architectures. Unlike current flow-based methods which directly generate the output image, we argue that learning in a style domain could (i) disentangle the retouching styles from the image content, (ii) lead to a stable style presentation form, and (iii) avoid the spatial disharmony effects. For obtaining meaningful image tone style representations, a joint-training pipeline is delicately designed, which is composed of a style encoder, a conditional RetouchNet, and the image tone style normalizing flow (TSFlow) module. In particular, the style encoder predicts the target style representation of an input image, which serves as the conditional information in the RetouchNet for retouching, while the TSFlow maps the style representation vector into a Gaussian distribution in the forward pass. After training, the TSFlow can generate diverse image tone style vectors by sampling from the Gaussian distribution. Extensive experiments on MIT-Adobe FiveK and PPR10K datasets show that our proposed method performs favorably against state-of-the-art methods and is effective in generating diverse results to satisfy different human aesthetic preferences. Source code and pre-trained models are publicly available at https://github.com/SSRHeart/TSFlow.
Differentially Private Kernel Inducing Points (DP-KIP) for Privacy-preserving Data Distillation
Jan 31, 2023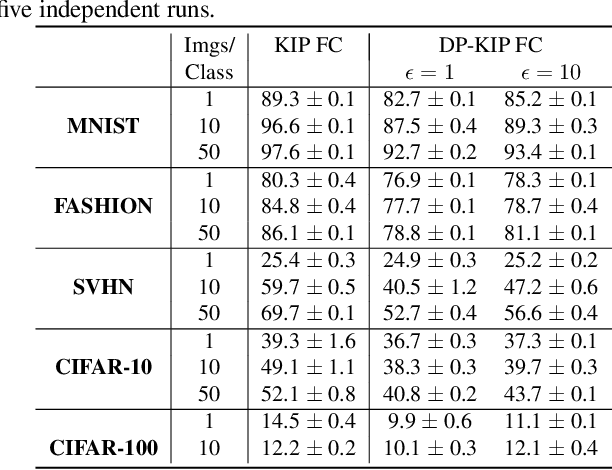

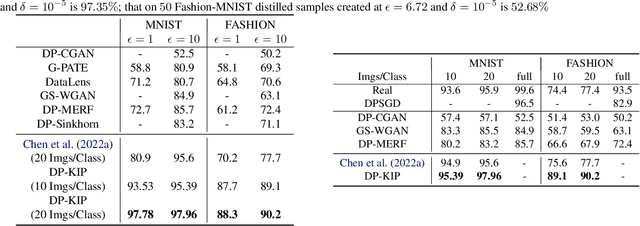
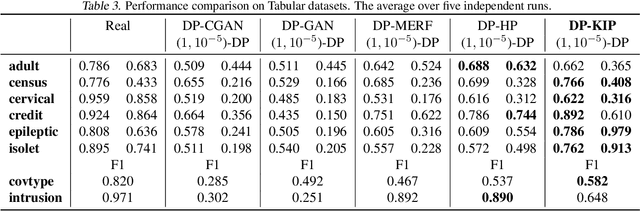
While it is tempting to believe that data distillation preserves privacy, distilled data's empirical robustness against known attacks does not imply a provable privacy guarantee. Here, we develop a provably privacy-preserving data distillation algorithm, called differentially private kernel inducing points (DP-KIP). DP-KIP is an instantiation of DP-SGD on kernel ridge regression (KRR). Following a recent work, we use neural tangent kernels and minimize the KRR loss to estimate the distilled datapoints (i.e., kernel inducing points). We provide a computationally efficient JAX implementation of DP-KIP, which we test on several popular image and tabular datasets to show its efficacy in data distillation with differential privacy guarantees.
Learning to Incorporate Texture Saliency Adaptive Attention to Image Cartoonization
Aug 02, 2022
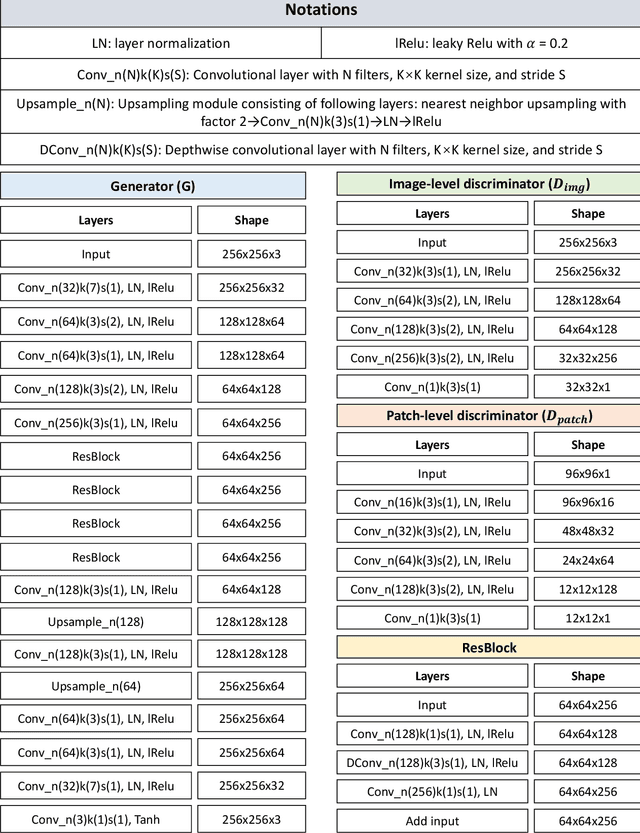
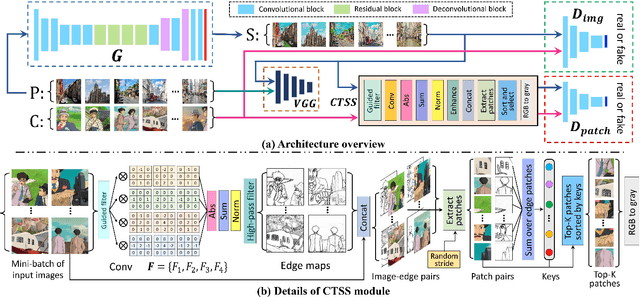
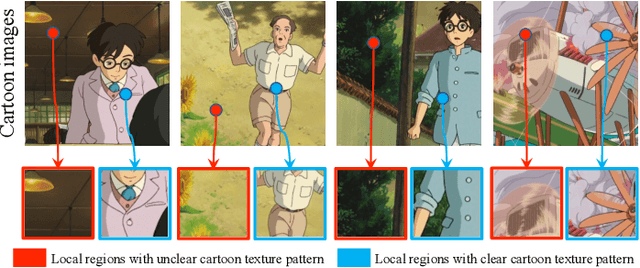
Image cartoonization is recently dominated by generative adversarial networks (GANs) from the perspective of unsupervised image-to-image translation, in which an inherent challenge is to precisely capture and sufficiently transfer characteristic cartoon styles (e.g., clear edges, smooth color shading, abstract fine structures, etc.). Existing advanced models try to enhance cartoonization effect by learning to promote edges adversarially, introducing style transfer loss, or learning to align style from multiple representation space. This paper demonstrates that more distinct and vivid cartoonization effect could be easily achieved with only basic adversarial loss. Observing that cartoon style is more evident in cartoon-texture-salient local image regions, we build a region-level adversarial learning branch in parallel with the normal image-level one, which constrains adversarial learning on cartoon-texture-salient local patches for better perceiving and transferring cartoon texture features. To this end, a novel cartoon-texture-saliency-sampler (CTSS) module is proposed to dynamically sample cartoon-texture-salient patches from training data. With extensive experiments, we demonstrate that texture saliency adaptive attention in adversarial learning, as a missing ingredient of related methods in image cartoonization, is of significant importance in facilitating and enhancing image cartoon stylization, especially for high-resolution input pictures.
* Proceedings of the 39th International Conference on Machine Learning, PMLR 162:7183-7207, 2022
PyMIC: A deep learning toolkit for annotation-efficient medical image segmentation
Aug 19, 2022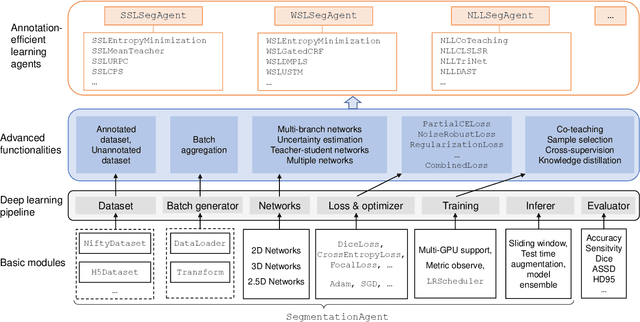
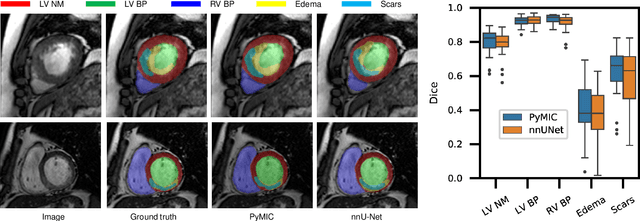
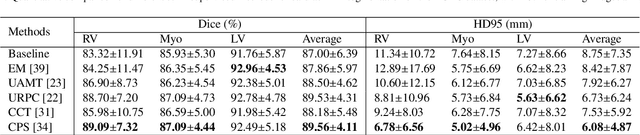
Background and Objective: Existing deep learning platforms for medical image segmentation mainly focus on fully supervised segmentation that assumes full and accurate pixel-level annotations are available. We aim to develop a new deep learning toolkit to support annotation-efficient learning for medical image segmentation, which can accelerate and simply the development of deep learning models with limited annotation budget, e.g., learning from partial, sparse or noisy annotations. Methods: Our proposed toolkit named PyMIC is a modular deep learning platform for medical image segmentation tasks. In addition to basic components that support development of high-performance models for fully supervised segmentation, it contains several advanced components that are tailored for learning from imperfect annotations, such as loading annotated and unannounced images, loss functions for unannotated, partially or inaccurately annotated images, and training procedures for co-learning between multiple networks, etc. PyMIC is built on the PyTorch framework and supports development of semi-supervised, weakly supervised and noise-robust learning methods for medical image segmentation. Results: We present four illustrative medical image segmentation tasks based on PyMIC: (1) Achieving competitive performance on fully supervised learning; (2) Semi-supervised cardiac structure segmentation with only 10% training images annotated; (3) Weakly supervised segmentation using scribble annotations; and (4) Learning from noisy labels for chest radiograph segmentation. Conclusions: The PyMIC toolkit is easy to use and facilitates efficient development of medical image segmentation models with imperfect annotations. It is modular and flexible, which enables researchers to develop high-performance models with low annotation cost. The source code is available at: https://github.com/HiLab-git/PyMIC.
Spiking Synaptic Penalty: Appropriate Penalty Term for Energy-Efficient Spiking Neural Networks
Feb 03, 2023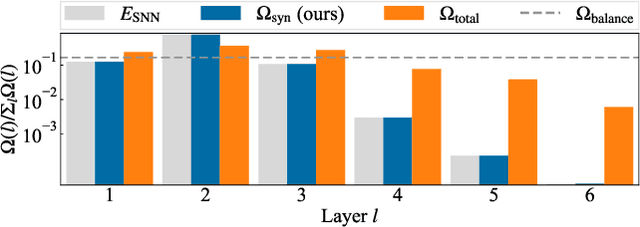

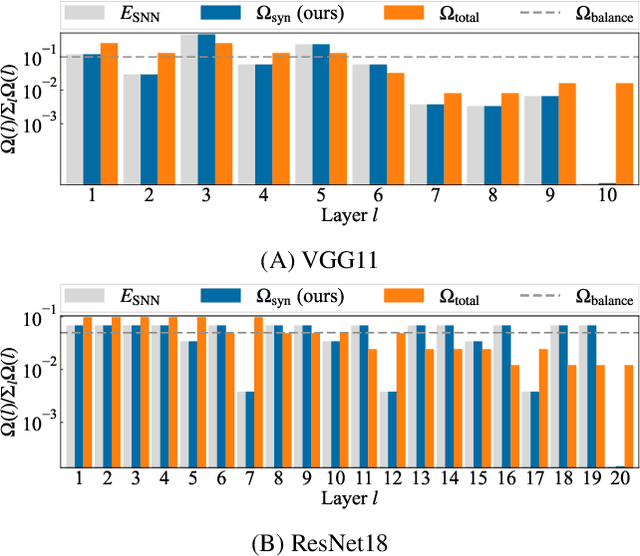
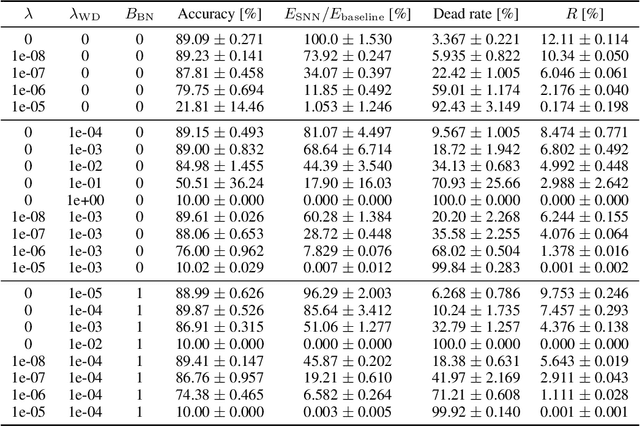
Spiking neural networks (SNNs) are energy-efficient neural networks because of their spiking nature. However, as the spike firing rate of SNNs increases, the energy consumption does as well, and thus, the advantage of SNNs diminishes. Here, we tackle this problem by introducing a novel penalty term for the spiking activity into the objective function in the training phase. Our method is designed so as to optimize the energy consumption metric directly without modifying the network architecture. Therefore, the proposed method can reduce the energy consumption more than other methods while maintaining the accuracy. We conducted experiments for image classification tasks, and the results indicate the effectiveness of the proposed method, which mitigates the dilemma of the energy--accuracy trade-off.
Frequency-domain Learning for Volumetric-based 3D Data Perception
Feb 20, 2023

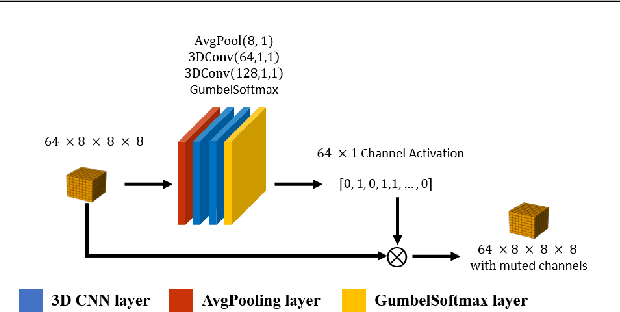
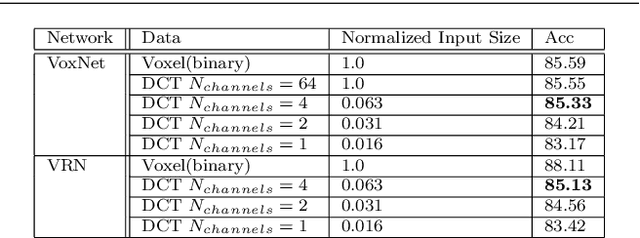
Frequency-domain learning draws attention due to its superior tradeoff between inference accuracy and input data size. Frequency-domain learning in 2D computer vision tasks has shown that 2D convolutional neural networks (CNN) have a stationary spectral bias towards low-frequency channels so that high-frequency channels can be pruned with no or little accuracy degradation. However, frequency-domain learning has not been studied in the context of 3D CNNs with 3D volumetric data. In this paper, we study frequency-domain learning for volumetric-based 3D data perception to reveal the spectral bias and the accuracy-input-data-size tradeoff of 3D CNNs. Our study finds that 3D CNNs are sensitive to a limited number of critical frequency channels, especially low-frequency channels. Experiment results show that frequency-domain learning can significantly reduce the size of volumetric-based 3D inputs (based on spectral bias) while achieving comparable accuracy with conventional spatial-domain learning approaches. Specifically, frequency-domain learning is able to reduce the input data size by 98% in 3D shape classification while limiting the average accuracy drop within 2%, and by 98% in the 3D point cloud semantic segmentation with a 1.48% mean-class accuracy improvement while limiting the mean-class IoU loss within 1.55%. Moreover, by learning from higher-resolution 3D data (i.e., 2x of the original image in the spatial domain), frequency-domain learning improves the mean-class accuracy and mean-class IoU by 3.04% and 0.63%, respectively, while achieving an 87.5% input data size reduction in 3D point cloud semantic segmentation.
RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
Jan 04, 2023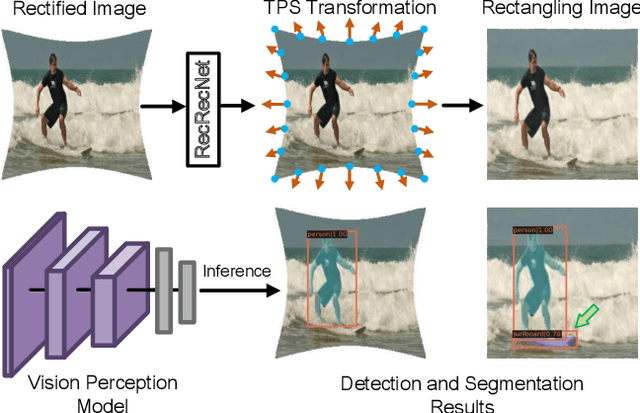
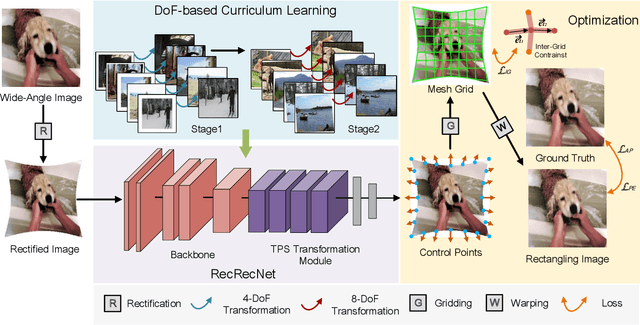


The wide-angle lens shows appealing applications in VR technologies, but it introduces severe radial distortion into its captured image. To recover the realistic scene, previous works devote to rectifying the content of the wide-angle image. However, such a rectification solution inevitably distorts the image boundary, which potentially changes related geometric distributions and misleads the current vision perception models. In this work, we explore constructing a win-win representation on both content and boundary by contributing a new learning model, i.e., Rectangling Rectification Network (RecRecNet). In particular, we propose a thin-plate spline (TPS) module to formulate the non-linear and non-rigid transformation for rectangling images. By learning the control points on the rectified image, our model can flexibly warp the source structure to the target domain and achieves an end-to-end unsupervised deformation. To relieve the complexity of structure approximation, we then inspire our RecRecNet to learn the gradual deformation rules with a DoF (Degree of Freedom)-based curriculum learning. By increasing the DoF in each curriculum stage, namely, from similarity transformation (4-DoF) to homography transformation (8-DoF), the network is capable of investigating more detailed deformations, offering fast convergence on the final rectangling task. Experiments show the superiority of our solution over the compared methods on both quantitative and qualitative evaluations. The code and dataset will be made available.
Enhancing Image Rescaling using Dual Latent Variables in Invertible Neural Network
Jul 24, 2022
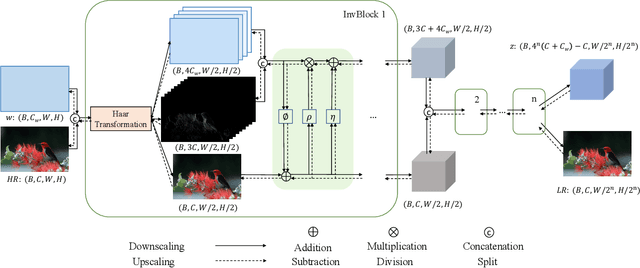
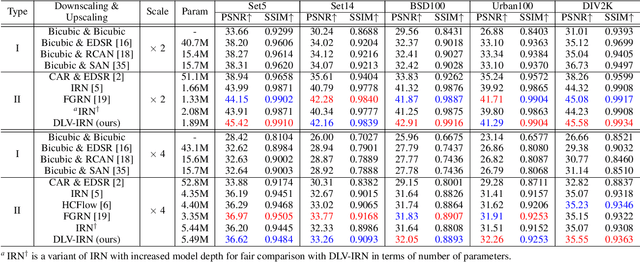
Normalizing flow models have been used successfully for generative image super-resolution (SR) by approximating complex distribution of natural images to simple tractable distribution in latent space through Invertible Neural Networks (INN). These models can generate multiple realistic SR images from one low-resolution (LR) input using randomly sampled points in the latent space, simulating the ill-posed nature of image upscaling where multiple high-resolution (HR) images correspond to the same LR. Lately, the invertible process in INN has also been used successfully by bidirectional image rescaling models like IRN and HCFlow for joint optimization of downscaling and inverse upscaling, resulting in significant improvements in upscaled image quality. While they are optimized for image downscaling too, the ill-posed nature of image downscaling, where one HR image could be downsized to multiple LR images depending on different interpolation kernels and resampling methods, is not considered. A new downscaling latent variable, in addition to the original one representing uncertainties in image upscaling, is introduced to model variations in the image downscaling process. This dual latent variable enhancement is applicable to different image rescaling models and it is shown in extensive experiments that it can improve image upscaling accuracy consistently without sacrificing image quality in downscaled LR images. It is also shown to be effective in enhancing other INN-based models for image restoration applications like image hiding.
Information-Theoretic Diffusion
Feb 07, 2023
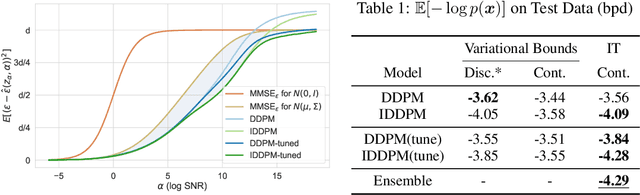
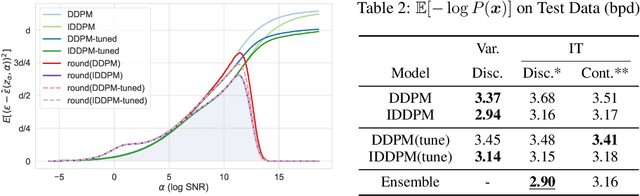
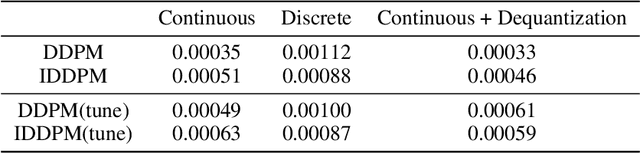
Denoising diffusion models have spurred significant gains in density modeling and image generation, precipitating an industrial revolution in text-guided AI art generation. We introduce a new mathematical foundation for diffusion models inspired by classic results in information theory that connect Information with Minimum Mean Square Error regression, the so-called I-MMSE relations. We generalize the I-MMSE relations to exactly relate the data distribution to an optimal denoising regression problem, leading to an elegant refinement of existing diffusion bounds. This new insight leads to several improvements for probability distribution estimation, including theoretical justification for diffusion model ensembling. Remarkably, our framework shows how continuous and discrete probabilities can be learned with the same regression objective, avoiding domain-specific generative models used in variational methods. Code to reproduce experiments is provided at http://github.com/kxh001/ITdiffusion and simplified demonstration code is at http://github.com/gregversteeg/InfoDiffusionSimple.
A Synthetic Hyperspectral Array Video Database with Applications to Cross-Spectral Reconstruction and Hyperspectral Video Coding
Jan 19, 2023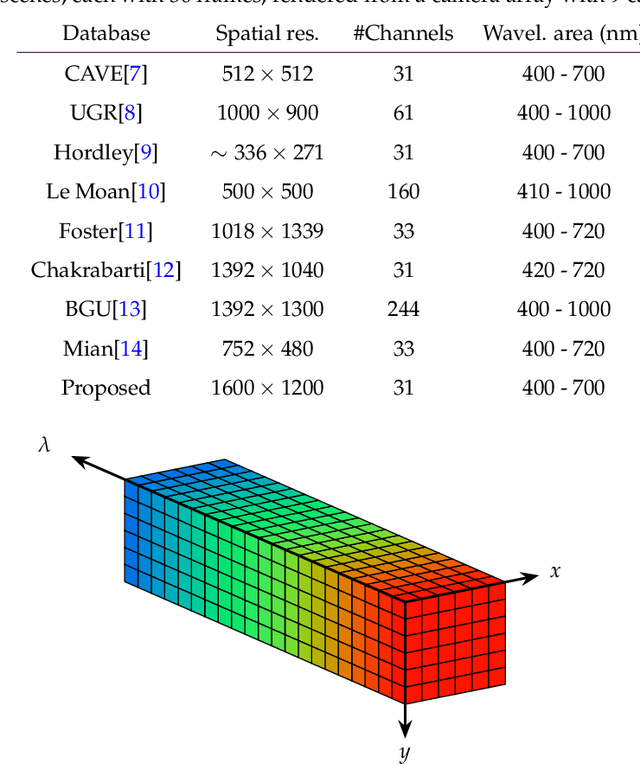

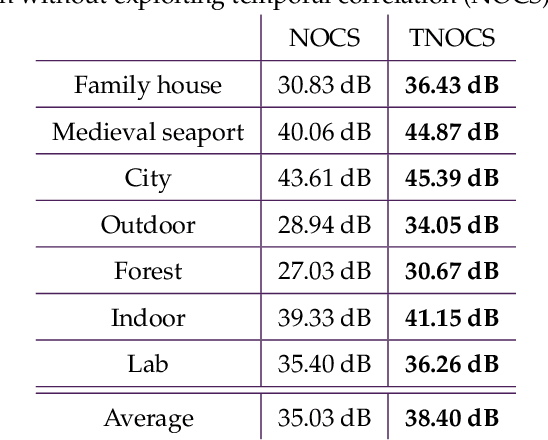
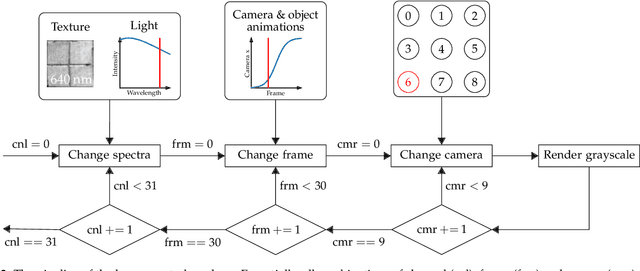
In this paper, a synthetic hyperspectral video database is introduced. Since it is impossible to record ground truth hyperspectral videos, this database offers the possibility to leverage the evaluation of algorithms in diverse applications. For all scenes, depth maps are provided as well to yield the position of a pixel in all spatial dimensions as well as the reflectance in spectral dimension. Two novel algorithms for two different applications are proposed to prove the diversity of applications that can be addressed by this novel database. First, a cross-spectral image reconstruction algorithm is extended to exploit the temporal correlation between two consecutive frames. The evaluation using this hyperspectral database shows an increase in PSNR of up to 5.6 dB dependent on the scene. Second, a hyperspectral video coder is introduced which extends an existing hyperspectral image coder by exploiting temporal correlation. The evaluation shows rate savings of up to 10% depending on the scene. The novel hyperspectral video database and source code is available at https:// github.com/ FAU-LMS/ HyViD for use by the research community.