 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Personalized 3D Human Pose and Shape Refinement
Mar 18, 2024




Recently, regression-based methods have dominated the field of 3D human pose and shape estimation. Despite their promising results, a common issue is the misalignment between predictions and image observations, often caused by minor joint rotation errors that accumulate along the kinematic chain. To address this issue, we propose to construct dense correspondences between initial human model estimates and the corresponding images that can be used to refine the initial predictions. To this end, we utilize renderings of the 3D models to predict per-pixel 2D displacements between the synthetic renderings and the RGB images. This allows us to effectively integrate and exploit appearance information of the persons. Our per-pixel displacements can be efficiently transformed to per-visible-vertex displacements and then used for 3D model refinement by minimizing a reprojection loss. To demonstrate the effectiveness of our approach, we refine the initial 3D human mesh predictions of multiple models using different refinement procedures on 3DPW and RICH. We show that our approach not only consistently leads to better image-model alignment, but also to improved 3D accuracy.
* Accepted to 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
Better (pseudo-)labels for semi-supervised instance segmentation
Mar 18, 2024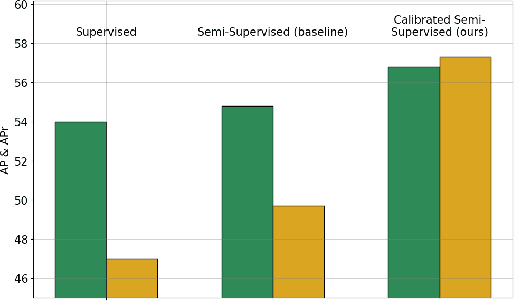
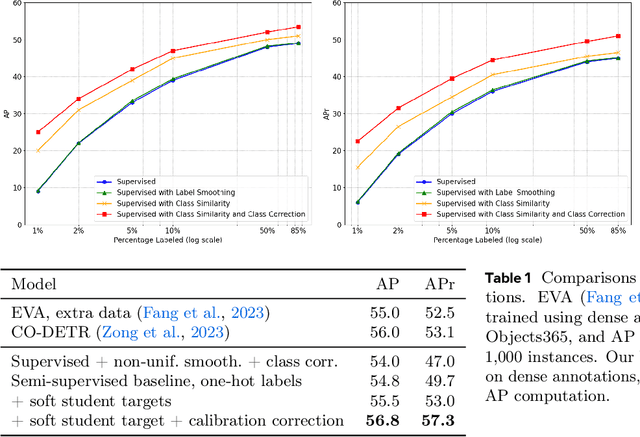
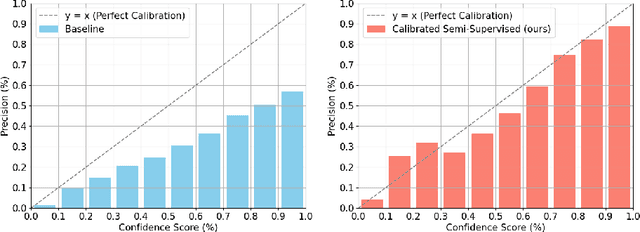
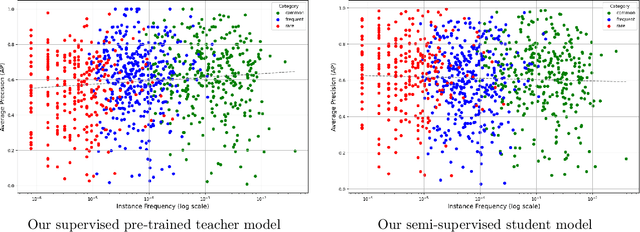
Despite the availability of large datasets for tasks like image classification and image-text alignment, labeled data for more complex recognition tasks, such as detection and segmentation, is less abundant. In particular, for instance segmentation annotations are time-consuming to produce, and the distribution of instances is often highly skewed across classes. While semi-supervised teacher-student distillation methods show promise in leveraging vast amounts of unlabeled data, they suffer from miscalibration, resulting in overconfidence in frequently represented classes and underconfidence in rarer ones. Additionally, these methods encounter difficulties in efficiently learning from a limited set of examples. We introduce a dual-strategy to enhance the teacher model's training process, substantially improving the performance on few-shot learning. Secondly, we propose a calibration correction mechanism that that enables the student model to correct the teacher's calibration errors. Using our approach, we observed marked improvements over a state-of-the-art supervised baseline performance on the LVIS dataset, with an increase of 2.8% in average precision (AP) and 10.3% gain in AP for rare classes.
GenFlow: Generalizable Recurrent Flow for 6D Pose Refinement of Novel Objects
Mar 18, 2024
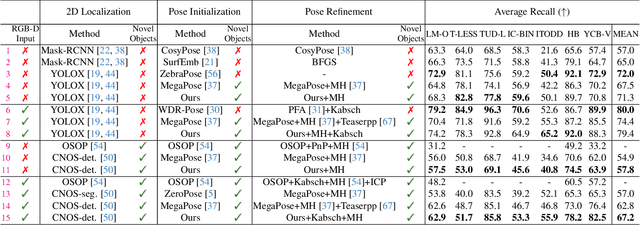
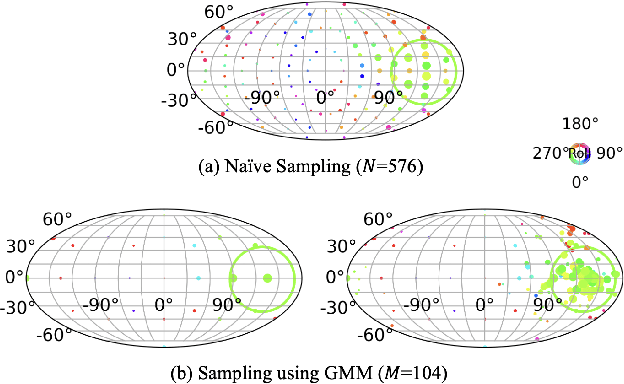
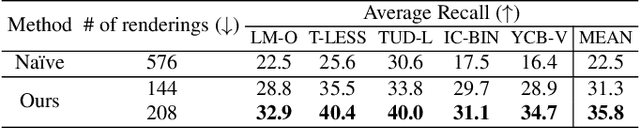
Despite the progress of learning-based methods for 6D object pose estimation, the trade-off between accuracy and scalability for novel objects still exists. Specifically, previous methods for novel objects do not make good use of the target object's 3D shape information since they focus on generalization by processing the shape indirectly, making them less effective. We present GenFlow, an approach that enables both accuracy and generalization to novel objects with the guidance of the target object's shape. Our method predicts optical flow between the rendered image and the observed image and refines the 6D pose iteratively. It boosts the performance by a constraint of the 3D shape and the generalizable geometric knowledge learned from an end-to-end differentiable system. We further improve our model by designing a cascade network architecture to exploit the multi-scale correlations and coarse-to-fine refinement. GenFlow ranked first on the unseen object pose estimation benchmarks in both the RGB and RGB-D cases. It also achieves performance competitive with existing state-of-the-art methods for the seen object pose estimation without any fine-tuning.
Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning
Mar 05, 2024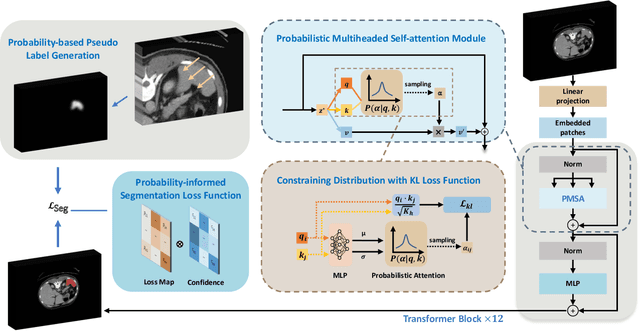
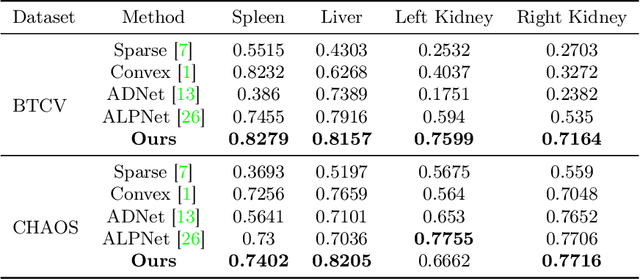
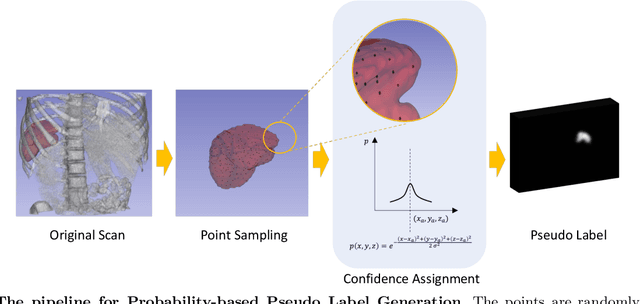
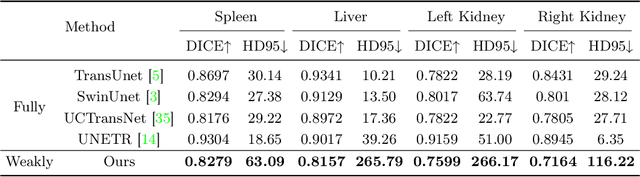
3D medical image segmentation is a challenging task with crucial implications for disease diagnosis and treatment planning. Recent advances in deep learning have significantly enhanced fully supervised medical image segmentation. However, this approach heavily relies on labor-intensive and time-consuming fully annotated ground-truth labels, particularly for 3D volumes. To overcome this limitation, we propose a novel probabilistic-aware weakly supervised learning pipeline, specifically designed for 3D medical imaging. Our pipeline integrates three innovative components: a probability-based pseudo-label generation technique for synthesizing dense segmentation masks from sparse annotations, a Probabilistic Multi-head Self-Attention network for robust feature extraction within our Probabilistic Transformer Network, and a Probability-informed Segmentation Loss Function to enhance training with annotation confidence. Demonstrating significant advances, our approach not only rivals the performance of fully supervised methods but also surpasses existing weakly supervised methods in CT and MRI datasets, achieving up to 18.1% improvement in Dice scores for certain organs. The code is available at https://github.com/runminjiang/PW4MedSeg.
Entity-Aware Multimodal Alignment Framework for News Image Captioning
Feb 29, 2024News image captioning task is a variant of image captioning task which requires model to generate a more informative caption with news image and the associated news article. Multimodal Large Language models have developed rapidly in recent years and is promising in news image captioning task. However, according to our experiments, common MLLMs are not good at generating the entities in zero-shot setting. Their abilities to deal with the entities information are still limited after simply fine-tuned on news image captioning dataset. To obtain a more powerful model to handle the multimodal entity information, we design two multimodal entity-aware alignment tasks and an alignment framework to align the model and generate the news image captions. Our method achieves better results than previous state-of-the-art models in CIDEr score (72.33 -> 86.29) on GoodNews dataset and (70.83 -> 85.61) on NYTimes800k dataset.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024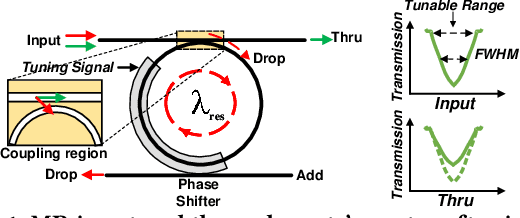
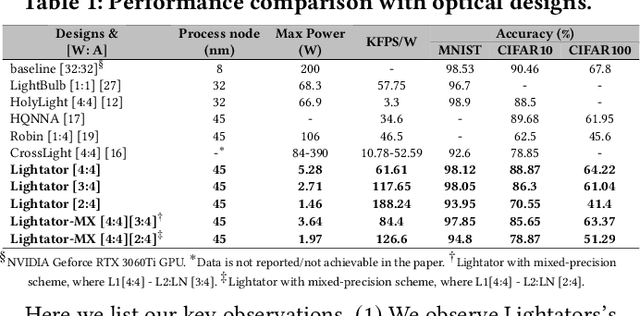
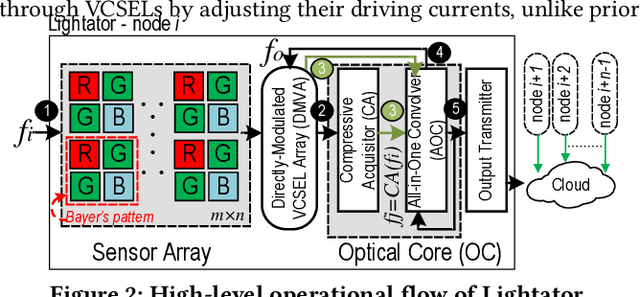
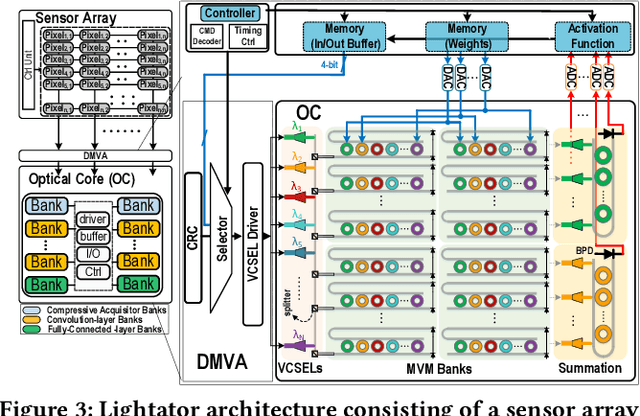
This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
SemanticHuman-HD: High-Resolution Semantic Disentangled 3D Human Generation
Mar 15, 2024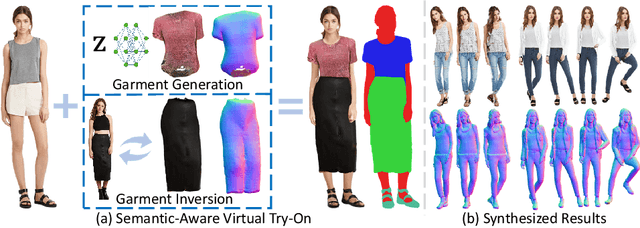
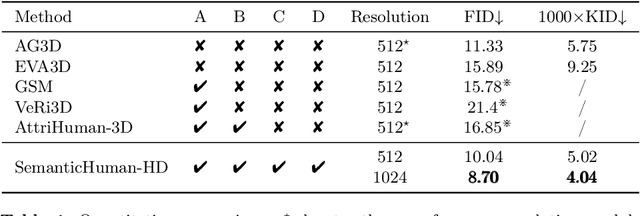
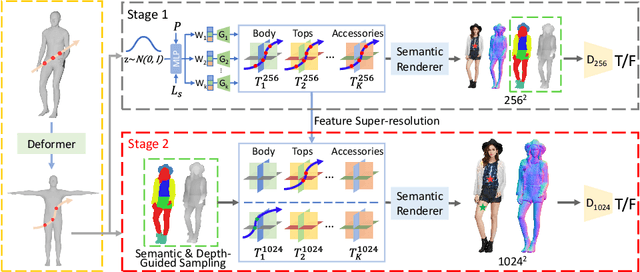

With the development of neural radiance fields and generative models, numerous methods have been proposed for learning 3D human generation from 2D images. These methods allow control over the pose of the generated 3D human and enable rendering from different viewpoints. However, none of these methods explore semantic disentanglement in human image synthesis, i.e., they can not disentangle the generation of different semantic parts, such as the body, tops, and bottoms. Furthermore, existing methods are limited to synthesize images at $512^2$ resolution due to the high computational cost of neural radiance fields. To address these limitations, we introduce SemanticHuman-HD, the first method to achieve semantic disentangled human image synthesis. Notably, SemanticHuman-HD is also the first method to achieve 3D-aware image synthesis at $1024^2$ resolution, benefiting from our proposed 3D-aware super-resolution module. By leveraging the depth maps and semantic masks as guidance for the 3D-aware super-resolution, we significantly reduce the number of sampling points during volume rendering, thereby reducing the computational cost. Our comparative experiments demonstrate the superiority of our method. The effectiveness of each proposed component is also verified through ablation studies. Moreover, our method opens up exciting possibilities for various applications, including 3D garment generation, semantic-aware image synthesis, controllable image synthesis, and out-of-domain image synthesis.
Time-efficient, high-resolution 3T whole-brain relaxometry using Cartesian 3D MR-STAT with CSF suppression
Mar 22, 2024Purpose: Current 3D Magnetic Resonance Spin TomogrAphy in Time-domain (MR-STAT) protocols use transient-state, gradient-spoiled gradient-echo sequences that are prone to cerebrospinal fluid (CSF) pulsation artifacts when applied to the brain. This study aims at developing a 3D MR-STAT protocol for whole-brain relaxometry that overcomes the challenges posed by CSF-induced ghosting artifacts. Method: We optimized the flip-angle train within the Cartesian 3D MR-STAT framework to achieve two objectives: (1) minimization of the noise level in the reconstructed quantitative maps, and (2) reduction of the CSF-to-white-matter signal ratio to suppress CSF signal and the associated pulsation artifacts. The optimized new sequence was tested on a gel/water-phantom to evaluate the accuracy of the quantitative maps, and on healthy volunteers to explore the effectiveness of the CSF artifact suppression and robustness of the new protocol. Results: A new optimized sequence with both high parameter encoding capability and low CSF intensity was proposed and initially validated in the gel/water-phantom experiment. From in-vivo experiments with five volunteers, the proposed CSF-suppressed sequence shows no CSF ghosting artifacts and overall greatly improved image quality for all quantitative maps compared to the baseline sequence. Statistical analysis indicated low inter-subject and inter-scan variability for quantitative parameters in gray matter and white matter (1.6%-2.4% for T1 and 2.0%-4.6% for T2), demonstrating the robustness of the new sequence. Conclusion: We presented a new 3D MR-STAT sequence with CSF suppression that effectively eliminates CSF pulsation artifacts. The new sequence ensures consistently high-quality, 1mm^3 whole-brain relaxometry within a rapid 5.5-minute scan time.
Image-Based Dietary Assessment: A Healthy Eating Plate Estimation System
Mar 02, 2024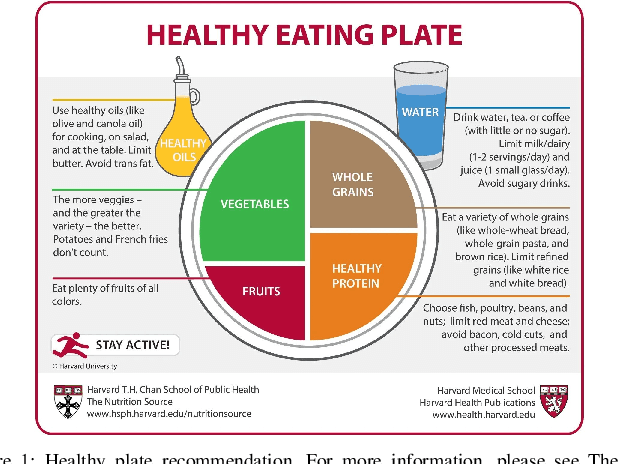
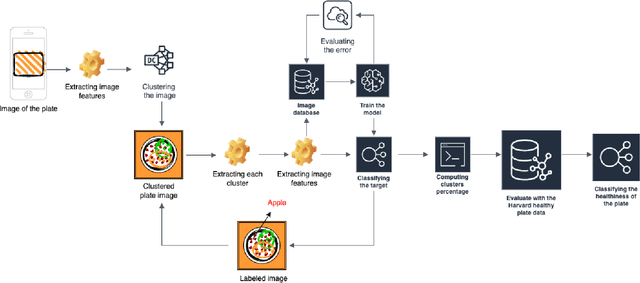

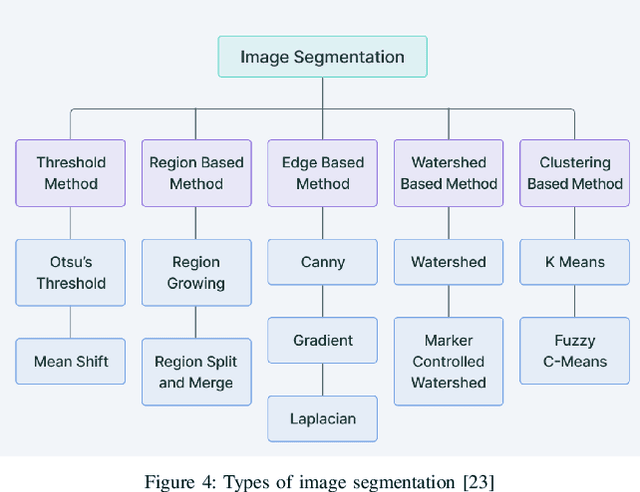
The nutritional quality of diets has significantly deteriorated over the past two to three decades, a decline often underestimated by the people. This deterioration, coupled with a hectic lifestyle, has contributed to escalating health concerns. Recognizing this issue, researchers at Harvard have advocated for a balanced nutritional plate model to promote health. Inspired by this research, our paper introduces an innovative Image-Based Dietary Assessment system aimed at evaluating the healthiness of meals through image analysis. Our system employs advanced image segmentation and classification techniques to analyze food items on a plate, assess their proportions, and calculate meal adherence to Harvard's healthy eating recommendations. This approach leverages machine learning and nutritional science to empower individuals with actionable insights for healthier eating choices. Our four-step framework involves segmenting the image, classifying the items, conducting a nutritional assessment based on the Harvard Healthy Eating Plate research, and offering tailored recommendations. The prototype system has shown promising results in promoting healthier eating habits by providing an accessible, evidence-based tool for dietary assessment.
Rotary Position Embedding for Vision Transformer
Mar 20, 2024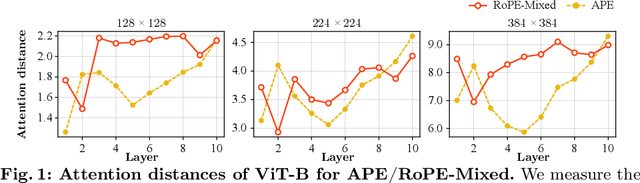
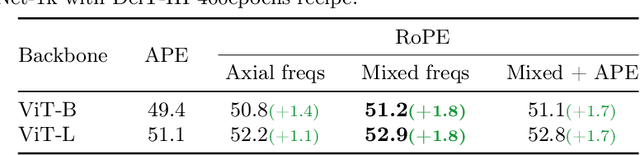
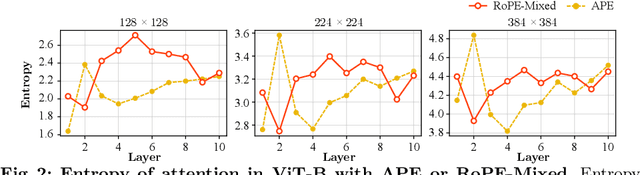
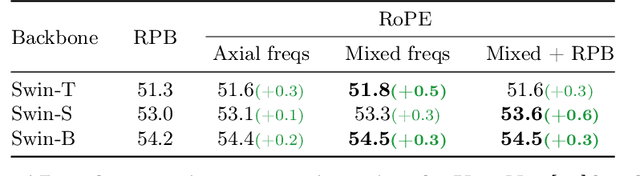
Rotary Position Embedding (RoPE) performs remarkably on language models, especially for length extrapolation of Transformers. However, the impacts of RoPE on computer vision domains have been underexplored, even though RoPE appears capable of enhancing Vision Transformer (ViT) performance in a way similar to the language domain. This study provides a comprehensive analysis of RoPE when applied to ViTs, utilizing practical implementations of RoPE for 2D vision data. The analysis reveals that RoPE demonstrates impressive extrapolation performance, i.e., maintaining precision while increasing image resolution at inference. It eventually leads to performance improvement for ImageNet-1k, COCO detection, and ADE-20k segmentation. We believe this study provides thorough guidelines to apply RoPE into ViT, promising improved backbone performance with minimal extra computational overhead. Our code and pre-trained models are available at https://github.com/naver-ai/rope-vit