 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing What You Say: Expressive Image Generation from Speech
Nov 05, 2025



This paper proposes VoxStudio, the first unified and end-to-end speech-to-image model that generates expressive images directly from spoken descriptions by jointly aligning linguistic and paralinguistic information. At its core is a speech information bottleneck (SIB) module, which compresses raw speech into compact semantic tokens, preserving prosody and emotional nuance. By operating directly on these tokens, VoxStudio eliminates the need for an additional speech-to-text system, which often ignores the hidden details beyond text, e.g., tone or emotion. We also release VoxEmoset, a large-scale paired emotional speech-image dataset built via an advanced TTS engine to affordably generate richly expressive utterances. Comprehensive experiments on the SpokenCOCO, Flickr8kAudio, and VoxEmoset benchmarks demonstrate the feasibility of our method and highlight key challenges, including emotional consistency and linguistic ambiguity, paving the way for future research.
DNNs May Determine Major Properties of Their Outputs Early, with Timing Possibly Driven by Bias
Feb 12, 2025This paper argues that deep neural networks (DNNs) mostly determine their outputs during the early stages of inference, where biases inherent in the model play a crucial role in shaping this process. We draw a parallel between this phenomenon and human decision-making, which often relies on fast, intuitive heuristics. Using diffusion models (DMs) as a case study, we demonstrate that DNNs often make early-stage decision-making influenced by the type and extent of bias in their design and training. Our findings offer a new perspective on bias mitigation, efficient inference, and the interpretation of machine learning systems. By identifying the temporal dynamics of decision-making in DNNs, this paper aims to inspire further discussion and research within the machine learning community.
MaskRIS: Semantic Distortion-aware Data Augmentation for Referring Image Segmentation
Nov 28, 2024Referring Image Segmentation (RIS) is an advanced vision-language task that involves identifying and segmenting objects within an image as described by free-form text descriptions. While previous studies focused on aligning visual and language features, exploring training techniques, such as data augmentation, remains underexplored. In this work, we explore effective data augmentation for RIS and propose a novel training framework called Masked Referring Image Segmentation (MaskRIS). We observe that the conventional image augmentations fall short of RIS, leading to performance degradation, while simple random masking significantly enhances the performance of RIS. MaskRIS uses both image and text masking, followed by Distortion-aware Contextual Learning (DCL) to fully exploit the benefits of the masking strategy. This approach can improve the model's robustness to occlusions, incomplete information, and various linguistic complexities, resulting in a significant performance improvement. Experiments demonstrate that MaskRIS can easily be applied to various RIS models, outperforming existing methods in both fully supervised and weakly supervised settings. Finally, MaskRIS achieves new state-of-the-art performance on RefCOCO, RefCOCO+, and RefCOCOg datasets. Code is available at https://github.com/naver-ai/maskris.
Probabilistic Language-Image Pre-Training
Oct 24, 2024



Vision-language models (VLMs) embed aligned image-text pairs into a joint space but often rely on deterministic embeddings, assuming a one-to-one correspondence between images and texts. This oversimplifies real-world relationships, which are inherently many-to-many, with multiple captions describing a single image and vice versa. We introduce Probabilistic Language-Image Pre-training (ProLIP), the first probabilistic VLM pre-trained on a billion-scale image-text dataset using only probabilistic objectives, achieving a strong zero-shot capability (e.g., 74.6% ImageNet zero-shot accuracy with ViT-B/16). ProLIP efficiently estimates uncertainty by an "uncertainty token" without extra parameters. We also introduce a novel inclusion loss that enforces distributional inclusion relationships between image-text pairs and between original and masked inputs. Experiments demonstrate that, by leveraging uncertainty estimates, ProLIP benefits downstream tasks and aligns with intuitive notions of uncertainty, e.g., shorter texts being more uncertain and more general inputs including specific ones. Utilizing text uncertainties, we further improve ImageNet accuracy from 74.6% to 75.8% (under a few-shot setting), supporting the practical advantages of our probabilistic approach. The code is available at https://github.com/naver-ai/prolip
Rotary Position Embedding for Vision Transformer
Mar 20, 2024Rotary Position Embedding (RoPE) performs remarkably on language models, especially for length extrapolation of Transformers. However, the impacts of RoPE on computer vision domains have been underexplored, even though RoPE appears capable of enhancing Vision Transformer (ViT) performance in a way similar to the language domain. This study provides a comprehensive analysis of RoPE when applied to ViTs, utilizing practical implementations of RoPE for 2D vision data. The analysis reveals that RoPE demonstrates impressive extrapolation performance, i.e., maintaining precision while increasing image resolution at inference. It eventually leads to performance improvement for ImageNet-1k, COCO detection, and ADE-20k segmentation. We believe this study provides thorough guidelines to apply RoPE into ViT, promising improved backbone performance with minimal extra computational overhead. Our code and pre-trained models are available at https://github.com/naver-ai/rope-vit
Forging Tokens for Improved Storage-efficient Training
Dec 15, 2023Recent advancements in Deep Neural Network (DNN) models have significantly improved performance across computer vision tasks. However, achieving highly generalizable and high-performing vision models requires extensive datasets, leading to large storage requirements. This storage challenge poses a critical bottleneck for scaling up vision models. Motivated by the success of discrete representations, SeiT proposes to use Vector-Quantized (VQ) feature vectors (i.e., tokens) as network inputs for vision classification. However, applying traditional data augmentations to tokens faces challenges due to input domain shift. To address this issue, we introduce TokenAdapt and ColorAdapt, simple yet effective token-based augmentation strategies. TokenAdapt realigns token embedding space for compatibility with spatial augmentations, preserving the model's efficiency without requiring fine-tuning. Additionally, ColorAdapt addresses color-based augmentations for tokens inspired by Adaptive Instance Normalization (AdaIN). We evaluate our approach across various scenarios, including storage-efficient ImageNet-1k classification, fine-grained classification, robustness benchmarks, and ADE-20k semantic segmentation. Experimental results demonstrate consistent performance improvement in diverse experiments. Code is available at https://github.com/naver-ai/tokenadapt.
SeiT: Storage-Efficient Vision Training with Tokens Using 1% of Pixel Storage
Mar 20, 2023



We need billion-scale images to achieve more generalizable and ground-breaking vision models, as well as massive dataset storage to ship the images (e.g., the LAION-4B dataset needs 240TB storage space). However, it has become challenging to deal with unlimited dataset storage with limited storage infrastructure. A number of storage-efficient training methods have been proposed to tackle the problem, but they are rarely scalable or suffer from severe damage to performance. In this paper, we propose a storage-efficient training strategy for vision classifiers for large-scale datasets (e.g., ImageNet) that only uses 1024 tokens per instance without using the raw level pixels; our token storage only needs <1% of the original JPEG-compressed raw pixels. We also propose token augmentations and a Stem-adaptor module to make our approach able to use the same architecture as pixel-based approaches with only minimal modifications on the stem layer and the carefully tuned optimization settings. Our experimental results on ImageNet-1k show that our method significantly outperforms other storage-efficient training methods with a large gap. We further show the effectiveness of our method in other practical scenarios, storage-efficient pre-training, and continual learning. Code is available at https://github.com/naver-ai/seit
Similarity of Neural Architectures Based on Input Gradient Transferability
Oct 20, 2022
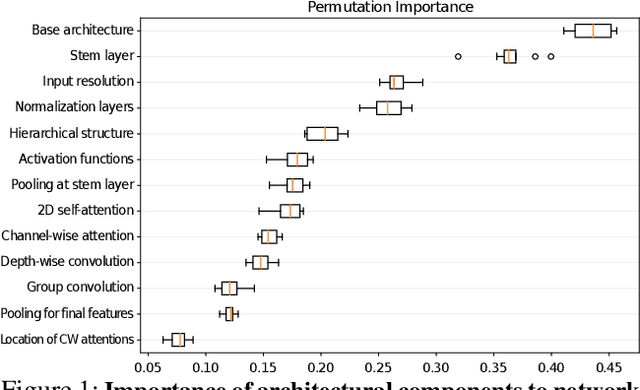
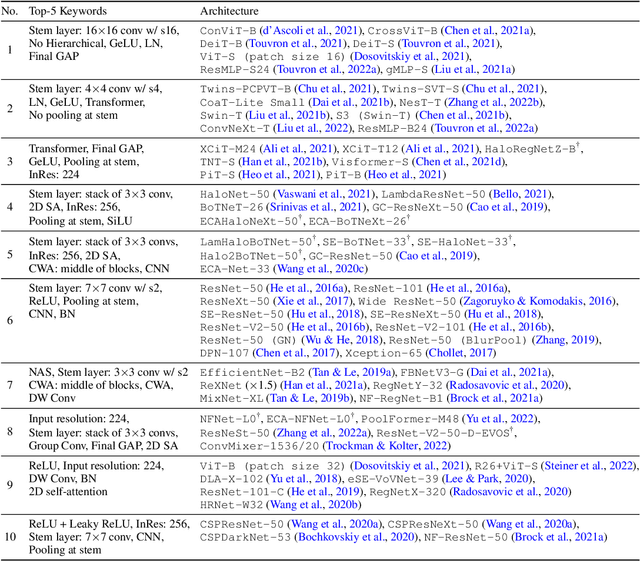
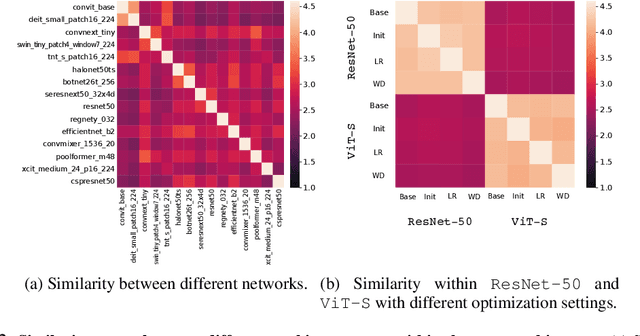
In this paper, we aim to design a quantitative similarity function between two neural architectures. Specifically, we define a model similarity using input gradient transferability. We generate adversarial samples of two networks and measure the average accuracy of the networks on adversarial samples of each other. If two networks are highly correlated, then the attack transferability will be high, resulting in high similarity. Using the similarity score, we investigate two topics: (1) Which network component contributes to the model diversity? (2) How does model diversity affect practical scenarios? We answer the first question by providing feature importance analysis and clustering analysis. The second question is validated by two different scenarios: model ensemble and knowledge distillation. Our findings show that model diversity takes a key role when interacting with different neural architectures. For example, we found that more diversity leads to better ensemble performance. We also observe that the relationship between teacher and student networks and distillation performance depends on the choice of the base architecture of the teacher and student networks. We expect our analysis tool helps a high-level understanding of differences between various neural architectures as well as practical guidance when using multiple architectures.
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO
Apr 14, 2022



Image-Text matching (ITM) is a common task for evaluating the quality of Vision and Language (VL) models. However, existing ITM benchmarks have a significant limitation. They have many missing correspondences, originating from the data construction process itself. For example, a caption is only matched with one image although the caption can be matched with other similar images, and vice versa. To correct the massive false negatives, we construct the Extended COCO Validation (ECCV) Caption dataset by supplying the missing associations with machine and human annotators. We employ five state-of-the-art ITM models with diverse properties for our annotation process. Our dataset provides x3.6 positive image-to-caption associations and x8.5 caption-to-image associations compared to the original MS-COCO. We also propose to use an informative ranking-based metric, rather than the popular Recall@K(R@K). We re-evaluate the existing 25 VL models on existing and proposed benchmarks. Our findings are that the existing benchmarks, such as COCO 1K R@K, COCO 5K R@K, CxC R@1 are highly correlated with each other, while the rankings change when we shift to the ECCV mAP. Lastly, we delve into the effect of the bias introduced by the choice of machine annotator. Source code and dataset are available at https://github.com/naver-ai/eccv-caption
Few-shot Font Generation with Weakly Supervised Localized Representations
Dec 22, 2021

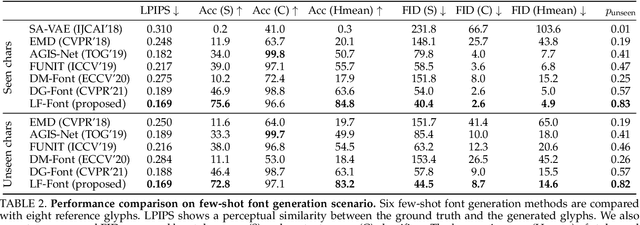
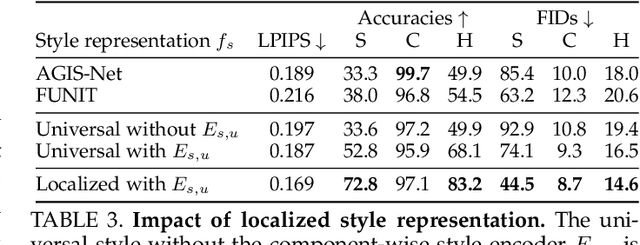
Automatic few-shot font generation aims to solve a well-defined, real-world problem because manual font designs are expensive and sensitive to the expertise of designers. Existing methods learn to disentangle style and content elements by developing a universal style representation for each font style. However, this approach limits the model in representing diverse local styles, because it is unsuitable for complicated letter systems, for example, Chinese, whose characters consist of a varying number of components (often called "radical") -- with a highly complex structure. In this paper, we propose a novel font generation method that learns localized styles, namely component-wise style representations, instead of universal styles. The proposed style representations enable the synthesis of complex local details in text designs. However, learning component-wise styles solely from a few reference glyphs is infeasible when a target script has a large number of components, for example, over 200 for Chinese. To reduce the number of required reference glyphs, we represent component-wise styles by a product of component and style factors, inspired by low-rank matrix factorization. Owing to the combination of strong representation and a compact factorization strategy, our method shows remarkably better few-shot font generation results (with only eight reference glyphs) than other state-of-the-art methods. Moreover, strong locality supervision, for example, location of each component, skeleton, or strokes, was not utilized. The source code is available at https://github.com/clovaai/lffont and https://github.com/clovaai/fewshot-font-generation.