 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structured Kernel Estimation for Photon-Limited Deconvolution
Mar 06, 2023

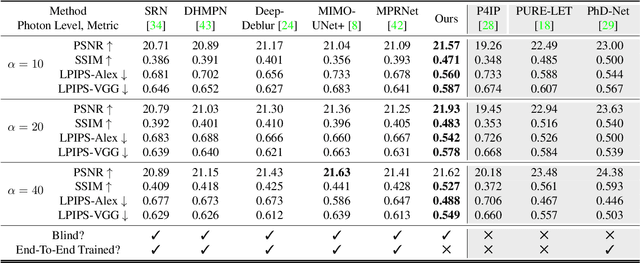
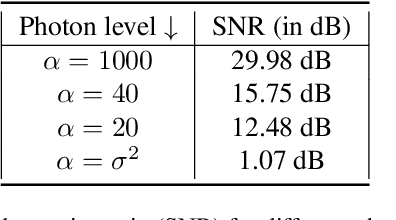

Images taken in a low light condition with the presence of camera shake suffer from motion blur and photon shot noise. While state-of-the-art image restoration networks show promising results, they are largely limited to well-illuminated scenes and their performance drops significantly when photon shot noise is strong. In this paper, we propose a new blur estimation technique customized for photon-limited conditions. The proposed method employs a gradient-based backpropagation method to estimate the blur kernel. By modeling the blur kernel using a low-dimensional representation with the key points on the motion trajectory, we significantly reduce the search space and improve the regularity of the kernel estimation problem. When plugged into an iterative framework, our novel low-dimensional representation provides improved kernel estimates and hence significantly better deconvolution performance when compared to end-to-end trained neural networks. The source code and pretrained models are available at \url{https://github.com/sanghviyashiitb/structured-kernel-cvpr23}
Scaling Laws For Deep Learning Based Image Reconstruction
Sep 27, 2022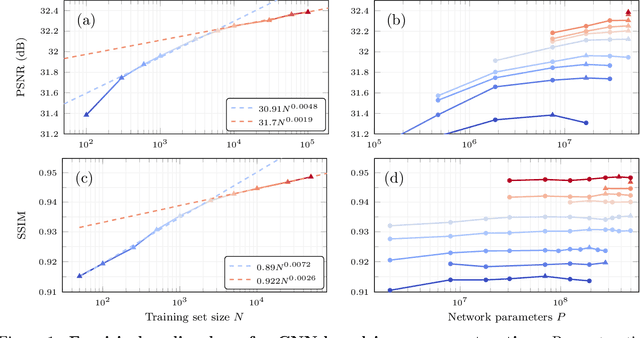
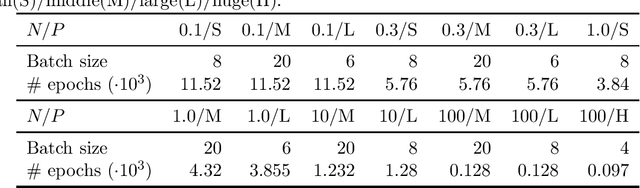
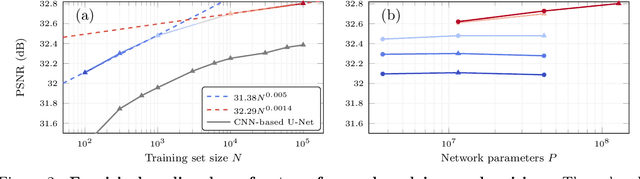

Deep neural networks trained end-to-end to map a measurement of a (noisy) image to a clean image perform excellent for a variety of linear inverse problems. Current methods are only trained on a few hundreds or thousands of images as opposed to the millions of examples deep networks are trained on in other domains. In this work, we study whether major performance gains are expected from scaling up the training set size. We consider image denoising, accelerated magnetic resonance imaging, and super-resolution and empirically determine the reconstruction quality as a function of training set size, while optimally scaling the network size. For all three tasks we find that an initially steep power-law scaling slows significantly already at moderate training set sizes. Interpolating those scaling laws suggests that even training on millions of images would not significantly improve performance. To understand the expected behavior, we analytically characterize the performance of a linear estimator learned with early stopped gradient descent. The result formalizes the intuition that once the error induced by learning the signal model is small relative to the error floor, more training examples do not improve performance.
Improved Segmentation of Deep Sulci in Cortical Gray Matter Using a Deep Learning Framework Incorporating Laplace's Equation
Mar 01, 2023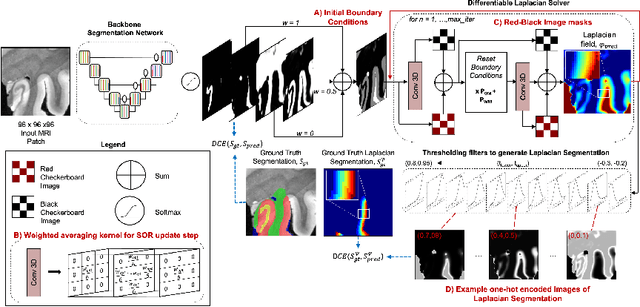
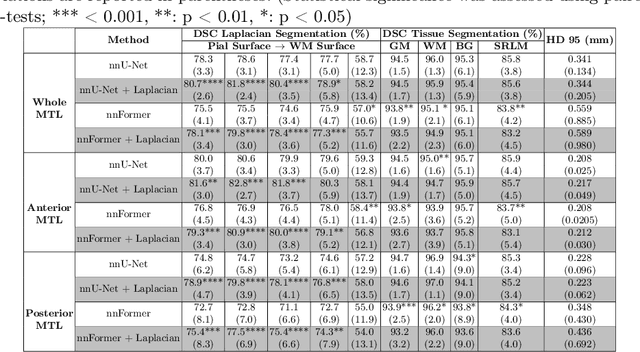
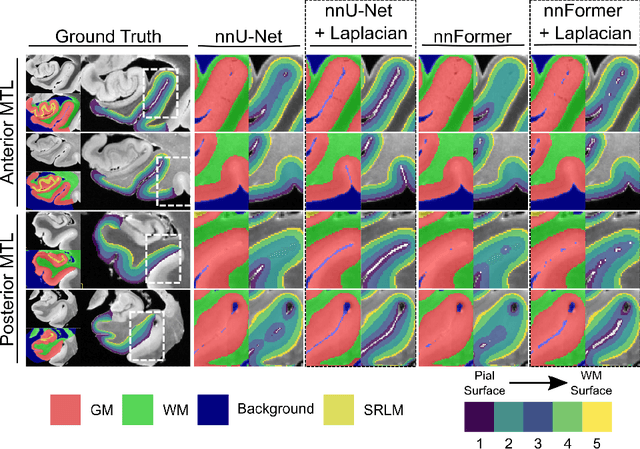
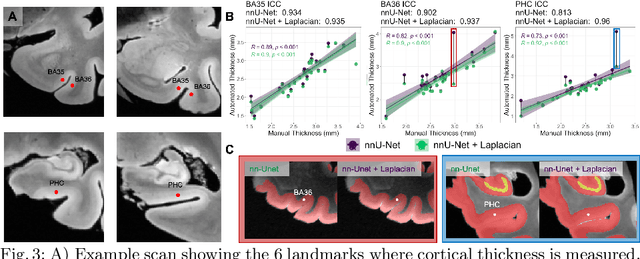
When developing tools for automated cortical segmentation, the ability to produce topologically correct segmentations is important in order to compute geometrically valid morphometry measures. In practice, accurate cortical segmentation is challenged by image artifacts and the highly convoluted anatomy of the cortex itself. To address this, we propose a novel deep learning-based cortical segmentation method in which prior knowledge about the geometry of the cortex is incorporated into the network during the training process. We design a loss function which uses the theory of Laplace's equation applied to the cortex to locally penalize unresolved boundaries between tightly folded sulci. Using an ex vivo MRI dataset of human medial temporal lobe specimens, we demonstrate that our approach outperforms baseline segmentation networks, both quantitatively and qualitatively.
Self-supervised Multi-view Disentanglement for Expansion of Visual Collections
Feb 04, 2023

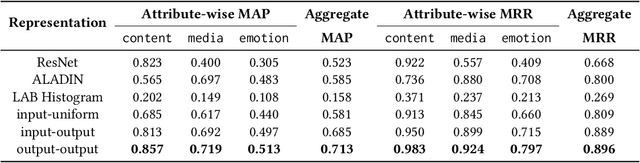
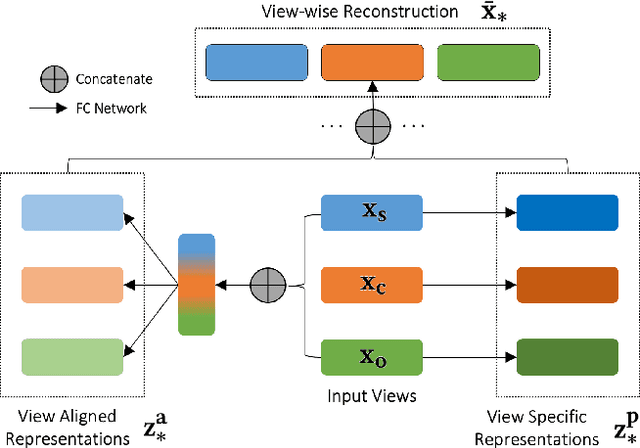
Image search engines enable the retrieval of images relevant to a query image. In this work, we consider the setting where a query for similar images is derived from a collection of images. For visual search, the similarity measurements may be made along multiple axes, or views, such as style and color. We assume access to a set of feature extractors, each of which computes representations for a specific view. Our objective is to design a retrieval algorithm that effectively combines similarities computed over representations from multiple views. To this end, we propose a self-supervised learning method for extracting disentangled view-specific representations for images such that the inter-view overlap is minimized. We show how this allows us to compute the intent of a collection as a distribution over views. We show how effective retrieval can be performed by prioritizing candidate expansion images that match the intent of a query collection. Finally, we present a new querying mechanism for image search enabled by composing multiple collections and perform retrieval under this setting using the techniques presented in this paper.
EHRDiff: Exploring Realistic EHR Synthesis with Diffusion Models
Mar 10, 2023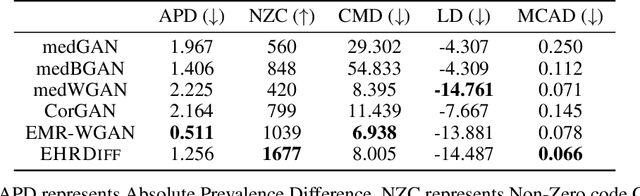
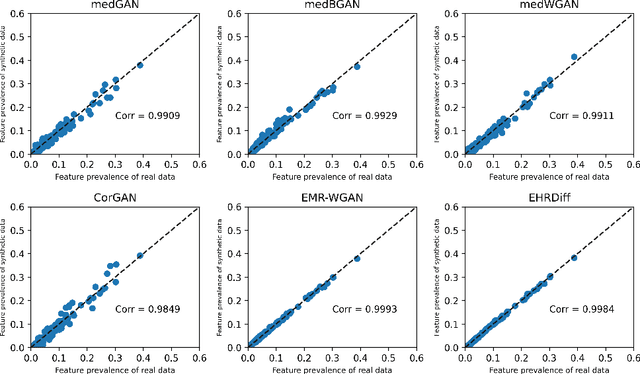
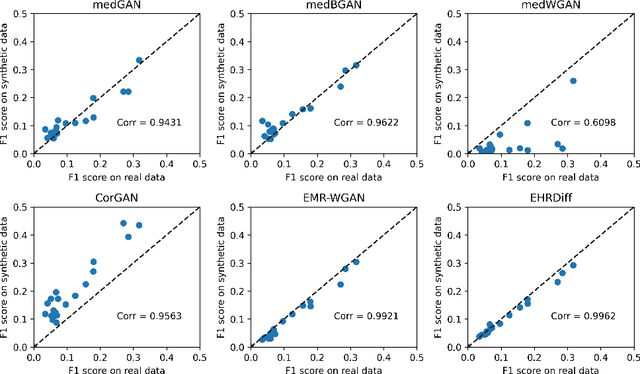
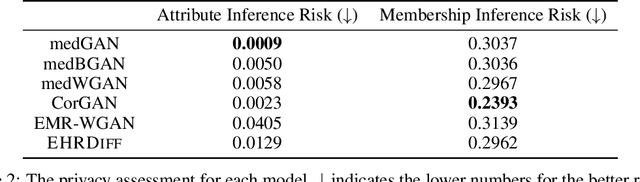
Electronic health records (EHR) contain vast biomedical knowledge and are rich resources for developing precise medicine systems. However, due to privacy concerns, there are limited high-quality EHR data accessible to researchers hence hindering the advancement of methodologies. Recent research has explored using generative modelling methods to synthesize realistic EHR data, and most proposed methods are based on the generative adversarial network (GAN) and its variants for EHR synthesis. Although GAN-style methods achieved state-of-the-art performance in generating high-quality EHR data, such methods are hard to train and prone to mode collapse. Diffusion models are recently proposed generative modelling methods and set cutting-edge performance in image generation. The performance of diffusion models in realistic EHR synthesis is rarely explored. In this work, we explore whether the superior performance of diffusion models can translate to the domain of EHR synthesis and propose a novel EHR synthesis method named EHRDiff. Through comprehensive experiments, EHRDiff achieves new state-of-the-art performance for the quality of synthetic EHR data and can better protect private information in real training EHRs in the meanwhile.
Progressive Meta-Pooling Learning for Lightweight Image Classification Model
Jan 24, 2023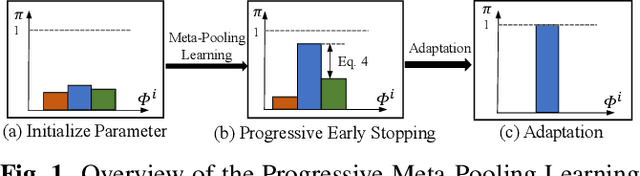
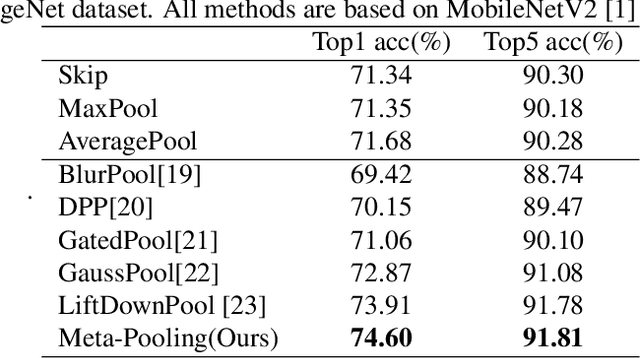
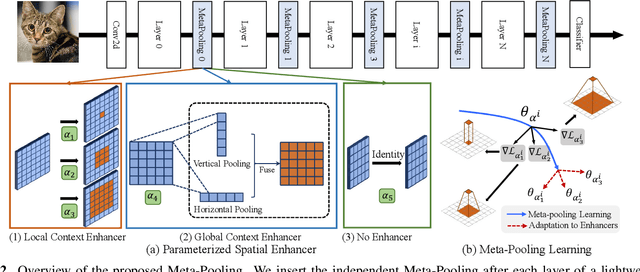
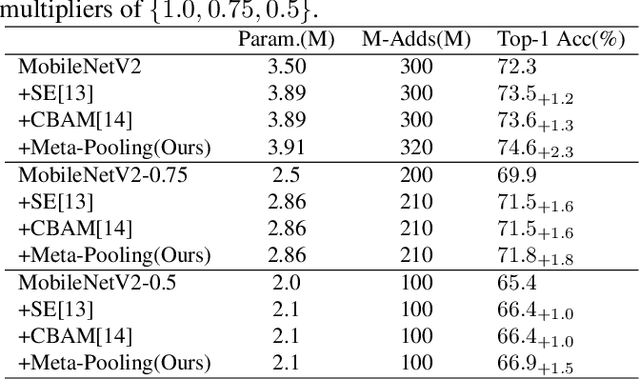
Practical networks for edge devices adopt shallow depth and small convolutional kernels to save memory and computational cost, which leads to a restricted receptive field. Conventional efficient learning methods focus on lightweight convolution designs, ignoring the role of the receptive field in neural network design. In this paper, we propose the Meta-Pooling framework to make the receptive field learnable for a lightweight network, which consists of parameterized pooling-based operations. Specifically, we introduce a parameterized spatial enhancer, which is composed of pooling operations to provide versatile receptive fields for each layer of a lightweight model. Then, we present a Progressive Meta-Pooling Learning (PMPL) strategy for the parameterized spatial enhancer to acquire a suitable receptive field size. The results on the ImageNet dataset demonstrate that MobileNetV2 using Meta-Pooling achieves top1 accuracy of 74.6\%, which outperforms MobileNetV2 by 2.3\%.
Grounding Language Models to Images for Multimodal Generation
Jan 31, 2023
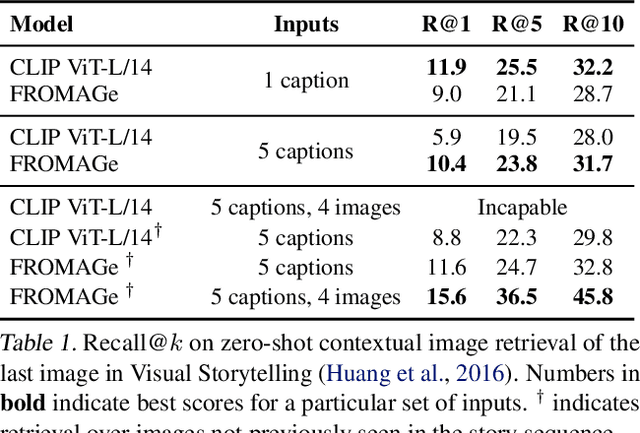
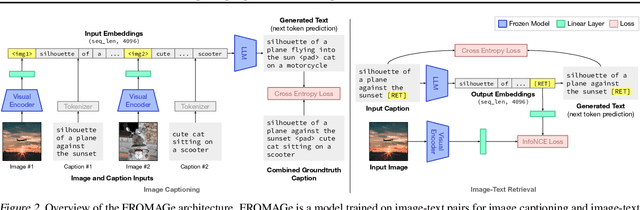
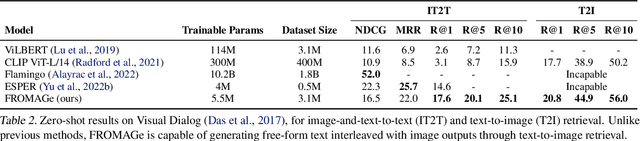
We propose an efficient method to ground pretrained text-only language models to the visual domain, enabling them to process and generate arbitrarily interleaved image-and-text data. Our method leverages the abilities of language models learnt from large scale text-only pretraining, such as in-context learning and free-form text generation. We keep the language model frozen, and finetune input and output linear layers to enable cross-modality interactions. This allows our model to process arbitrarily interleaved image-and-text inputs, and generate free-form text interleaved with retrieved images. We achieve strong zero-shot performance on grounded tasks such as contextual image retrieval and multimodal dialogue, and showcase compelling interactive abilities. Our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pretrained language models in visually grounded settings.
Spherical Space Feature Decomposition for Guided Depth Map Super-Resolution
Mar 15, 2023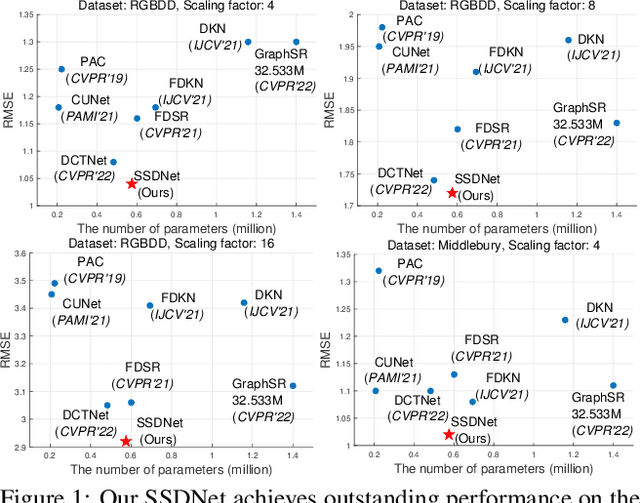
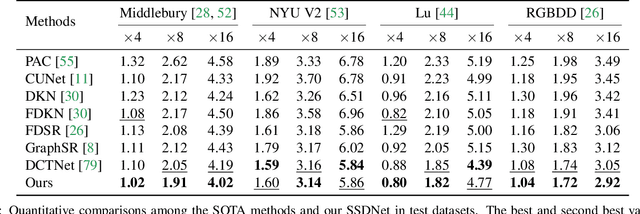
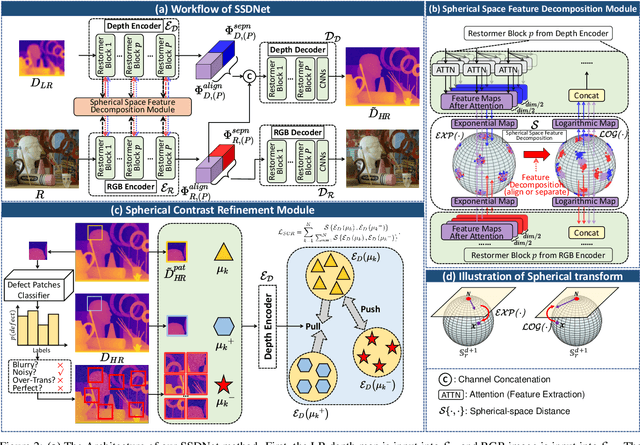

Guided depth map super-resolution (GDSR), as a hot topic in multi-modal image processing, aims to upsample low-resolution (LR) depth maps with additional information involved in high-resolution (HR) RGB images from the same scene. The critical step of this task is to effectively extract domain-shared and domain-private RGB/depth features. In addition, three detailed issues, namely blurry edges, noisy surfaces, and over-transferred RGB texture, need to be addressed. In this paper, we propose the Spherical Space feature Decomposition Network (SSDNet) to solve the above issues. To better model cross-modality features, Restormer block-based RGB/depth encoders are employed for extracting local-global features. Then, the extracted features are mapped to the spherical space to complete the separation of private features and the alignment of shared features. Shared features of RGB are fused with the depth features to complete the GDSR task. Subsequently, a spherical contrast refinement (SCR) module is proposed to further address the detail issues. Patches that are classified according to imperfect categories are input to the SCR module, where the patch features are pulled closer to the ground truth and pushed away from the corresponding imperfect samples in the spherical feature space via contrastive learning. Extensive experiments demonstrate that our method can achieve state-of-the-art results on four test datasets and can successfully generalize to real-world scenes. Code will be released.
Visual Prompt Based Personalized Federated Learning
Mar 15, 2023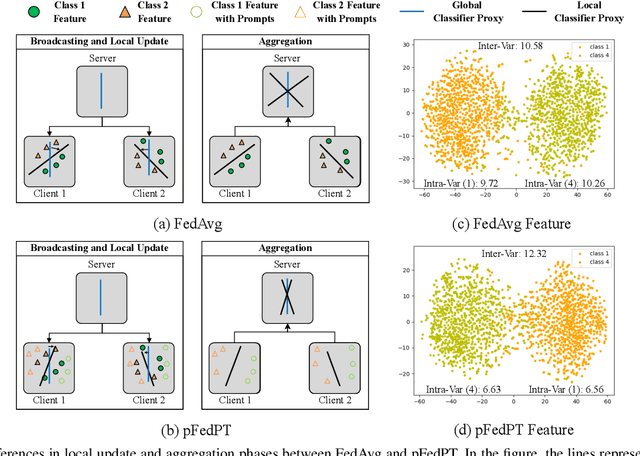
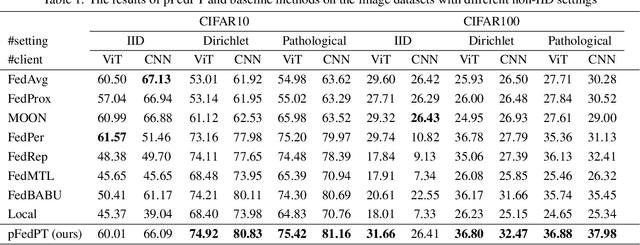
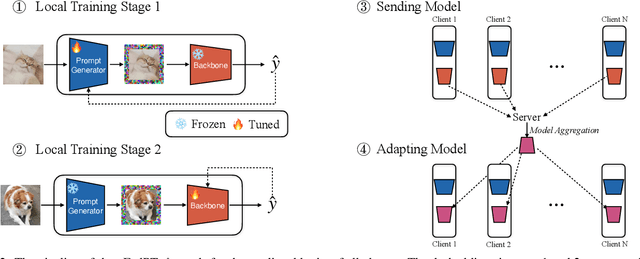
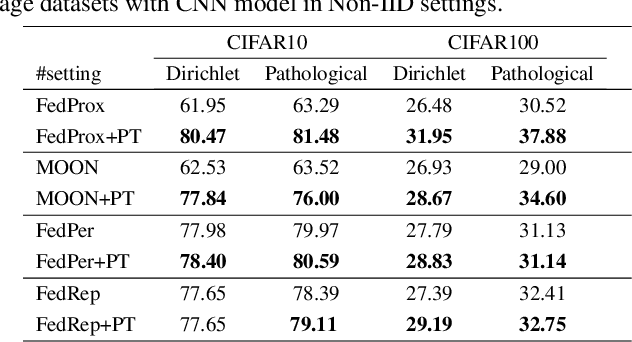
As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains prior knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings.
Learning to Trace and Untangle Semi-planar Knots (TUSK)
Mar 15, 2023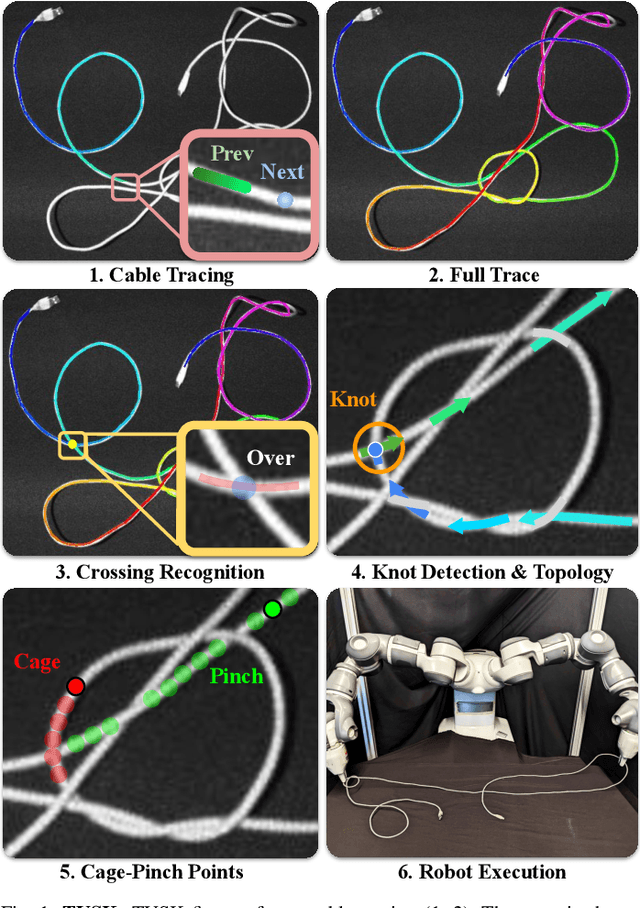


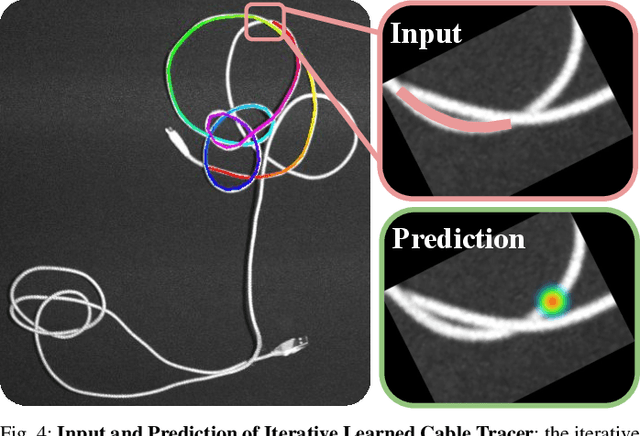
This paper extends prior work on untangling long cables and presents TUSK (Tracing to Untangle Semi-planar Knots), a learned cable-tracing algorithm that resolves over-crossings and undercrossings to recognize the structure of knots and grasp points for untangling from a single RGB image. This work focuses on semi-planar knots, which are knots composed of crossings that each include at most 2 cable segments. We conduct experiments on long cables (3 m in length) with up to 15 semi-planar crossings across 6 different knot types. Crops of crossings from 3 knots (overhand, figure 8, and bowline) of the 6 are seen during training, but none of the full knots are seen during training. This is an improvement from prior work on long cables that can only untangle 2 knot types. Experiments find that in settings with multiple identical cables, TUSK can trace a single cable with 81% accuracy on 7 new knot types. In single-cable images, TUSK can trace and identify the correct knot with 77% success on 3 new knot types. We incorporate TUSK into a bimanual robot system and find that it successfully untangles 64% of cable configurations, including those with new knots unseen during training, across 3 levels of difficulty. Supplementary material, including an annotated dataset of 500 RGB-D images of a knotted cable along with ground-truth traces, can be found at https://sites.google.com/view/tusk-rss.