 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distributed Black-box Attack against Image Classification Cloud Services
Nov 02, 2022


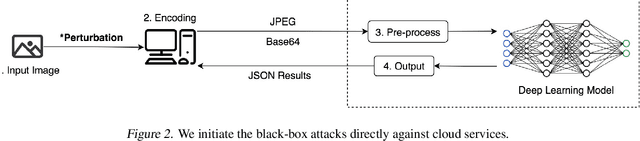

Black-box adversarial attacks can fool image classifiers into misclassifying images without requiring access to model structure and weights. Recently proposed black-box attacks can achieve a success rate of more than 95% after less than 1,000 queries. The question then arises of whether black-box attacks have become a real threat against IoT devices that rely on cloud APIs to achieve image classification. To shed some light on this, note that prior research has primarily focused on increasing the success rate and reducing the number of required queries. However, another crucial factor for black-box attacks against cloud APIs is the time required to perform the attack. This paper applies black-box attacks directly to cloud APIs rather than to local models, thereby avoiding multiple mistakes made in prior research. Further, we exploit load balancing to enable distributed black-box attacks that can reduce the attack time by a factor of about five for both local search and gradient estimation methods.
Consistency Models
Mar 02, 2023
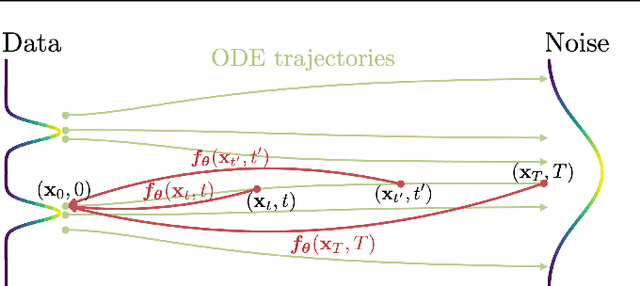
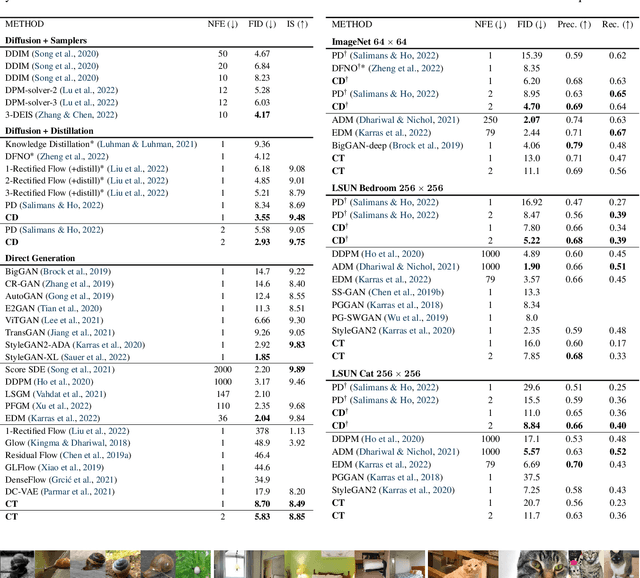
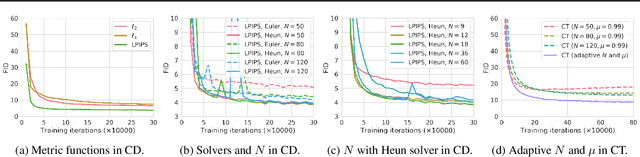
Diffusion models have made significant breakthroughs in image, audio, and video generation, but they depend on an iterative generation process that causes slow sampling speed and caps their potential for real-time applications. To overcome this limitation, we propose consistency models, a new family of generative models that achieve high sample quality without adversarial training. They support fast one-step generation by design, while still allowing for few-step sampling to trade compute for sample quality. They also support zero-shot data editing, like image inpainting, colorization, and super-resolution, without requiring explicit training on these tasks. Consistency models can be trained either as a way to distill pre-trained diffusion models, or as standalone generative models. Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step generation. For example, we achieve the new state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64x64 for one-step generation. When trained as standalone generative models, consistency models also outperform single-step, non-adversarial generative models on standard benchmarks like CIFAR-10, ImageNet 64x64 and LSUN 256x256.
Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors
Feb 28, 2023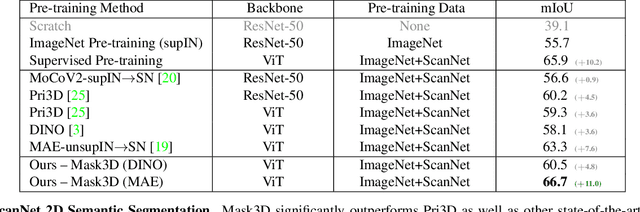
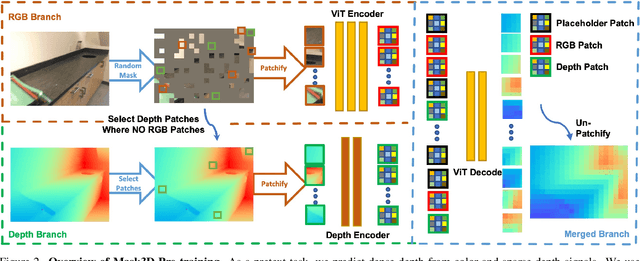
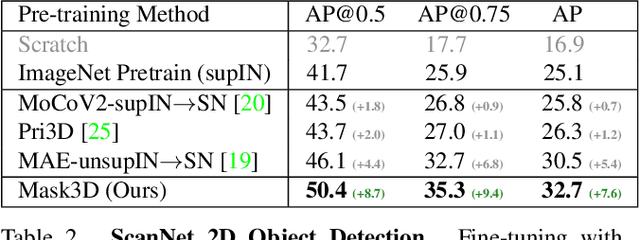
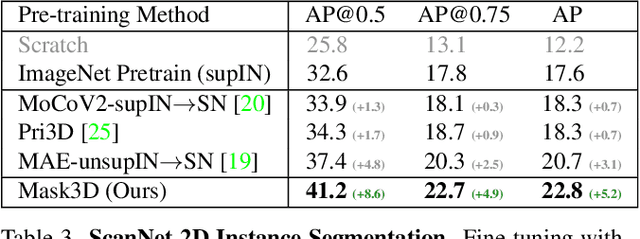
Current popular backbones in computer vision, such as Vision Transformers (ViT) and ResNets are trained to perceive the world from 2D images. However, to more effectively understand 3D structural priors in 2D backbones, we propose Mask3D to leverage existing large-scale RGB-D data in a self-supervised pre-training to embed these 3D priors into 2D learned feature representations. In contrast to traditional 3D contrastive learning paradigms requiring 3D reconstructions or multi-view correspondences, our approach is simple: we formulate a pre-text reconstruction task by masking RGB and depth patches in individual RGB-D frames. We demonstrate the Mask3D is particularly effective in embedding 3D priors into the powerful 2D ViT backbone, enabling improved representation learning for various scene understanding tasks, such as semantic segmentation, instance segmentation and object detection. Experiments show that Mask3D notably outperforms existing self-supervised 3D pre-training approaches on ScanNet, NYUv2, and Cityscapes image understanding tasks, with an improvement of +6.5% mIoU against the state-of-the-art Pri3D on ScanNet image semantic segmentation.
ToothInpaintor: Tooth Inpainting from Partial 3D Dental Model and 2D Panoramic Image
Nov 25, 2022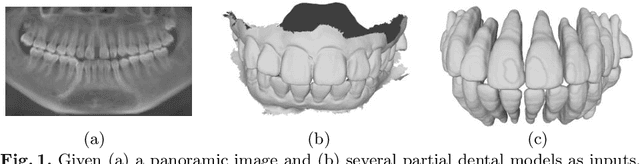
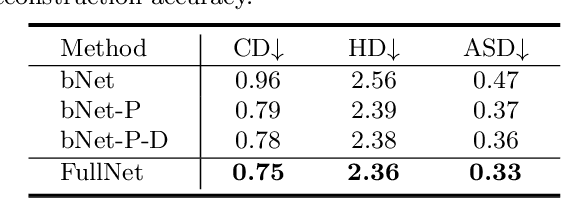
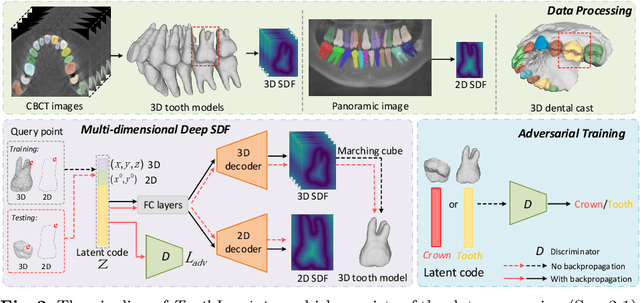
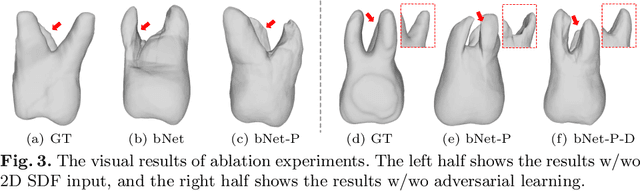
In orthodontic treatment, a full tooth model consisting of both the crown and root is indispensable in making the treatment plan. However, acquiring tooth root information to obtain the full tooth model from CBCT images is sometimes restricted due to the massive radiation of CBCT scanning. Thus, reconstructing the full tooth shape from the ready-to-use input, e.g., the partial intra-oral scan and the 2D panoramic image, is an applicable and valuable solution. In this paper, we propose a neural network, called ToothInpaintor, that takes as input a partial 3D dental model and a 2D panoramic image and reconstructs the full tooth model with high-quality root(s). Technically, we utilize the implicit representation for both the 3D and 2D inputs, and learn a latent space of the full tooth shapes. At test time, given an input, we successfully project it to the learned latent space via neural optimization to obtain the full tooth model conditioned on the input. To help find the robust projection, a novel adversarial learning module is exploited in our pipeline. We extensively evaluate our method on a dataset collected from real-world clinics. The evaluation, comparison, and comprehensive ablation studies demonstrate that our approach produces accurate complete tooth models robustly and outperforms the state-of-the-art methods.
HCGMNET: A Hierarchical Change Guiding Map Network For Change Detection
Mar 13, 2023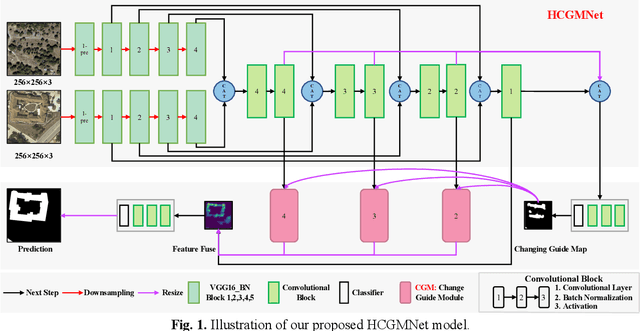
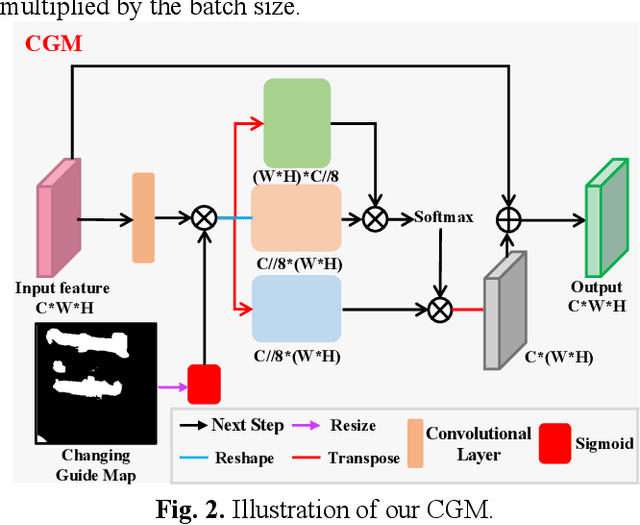

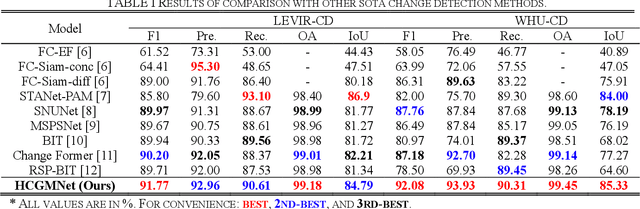
Very-high-resolution (VHR) remote sensing (RS) image change detection (CD) has been a challenging task for its very rich spatial information and sample imbalance problem. In this paper, we have proposed a hierarchical change guiding map network (HCGMNet) for change detection. The model uses hierarchical convolution operations to extract multiscale features, continuously merges multi-scale features layer by layer to improve the expression of global and local information, and guides the model to gradually refine edge features and comprehensive performance by a change guide module (CGM), which is a self-attention with changing guide map. Extensive experiments on two CD datasets show that the proposed HCGMNet architecture achieves better CD performance than existing state-of-the-art (SOTA) CD methods.
Cutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022
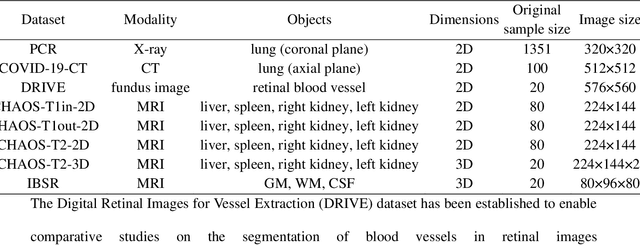
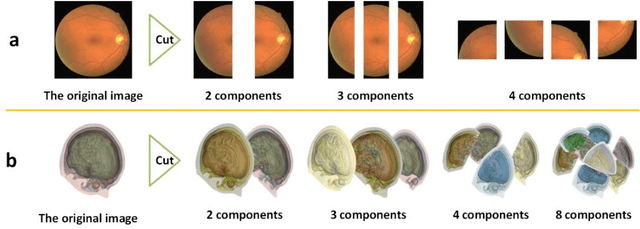
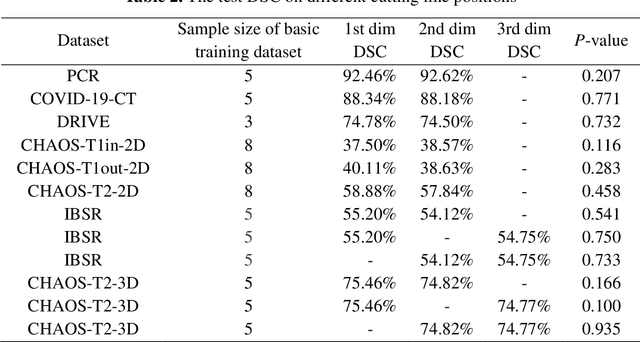
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.
One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer
Mar 28, 2023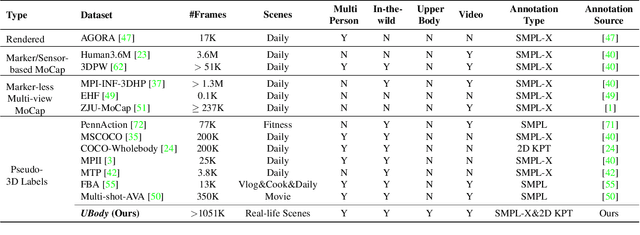

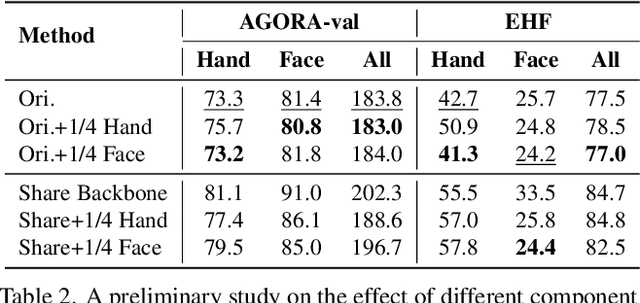
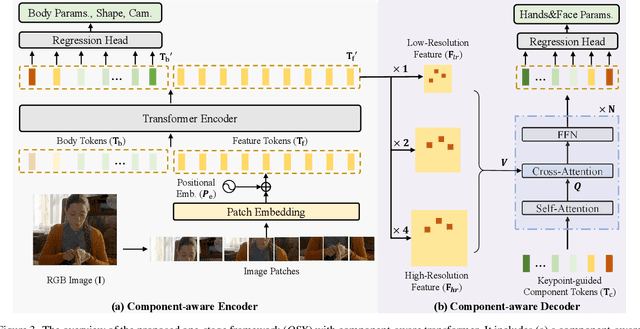
Whole-body mesh recovery aims to estimate the 3D human body, face, and hands parameters from a single image. It is challenging to perform this task with a single network due to resolution issues, i.e., the face and hands are usually located in extremely small regions. Existing works usually detect hands and faces, enlarge their resolution to feed in a specific network to predict the parameter, and finally fuse the results. While this copy-paste pipeline can capture the fine-grained details of the face and hands, the connections between different parts cannot be easily recovered in late fusion, leading to implausible 3D rotation and unnatural pose. In this work, we propose a one-stage pipeline for expressive whole-body mesh recovery, named OSX, without separate networks for each part. Specifically, we design a Component Aware Transformer (CAT) composed of a global body encoder and a local face/hand decoder. The encoder predicts the body parameters and provides a high-quality feature map for the decoder, which performs a feature-level upsample-crop scheme to extract high-resolution part-specific features and adopt keypoint-guided deformable attention to estimate hand and face precisely. The whole pipeline is simple yet effective without any manual post-processing and naturally avoids implausible prediction. Comprehensive experiments demonstrate the effectiveness of OSX. Lastly, we build a large-scale Upper-Body dataset (UBody) with high-quality 2D and 3D whole-body annotations. It contains persons with partially visible bodies in diverse real-life scenarios to bridge the gap between the basic task and downstream applications.
Low Latency Video Denoising for Online Conferencing Using CNN Architectures
Feb 17, 2023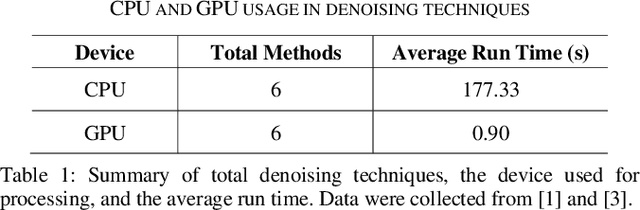
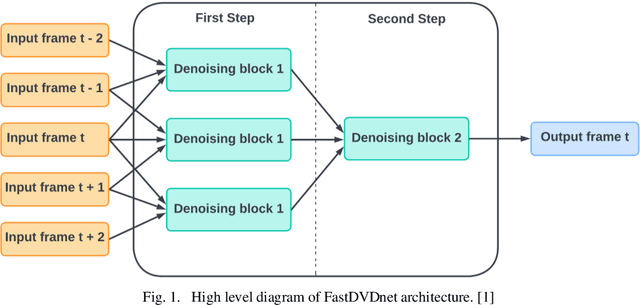
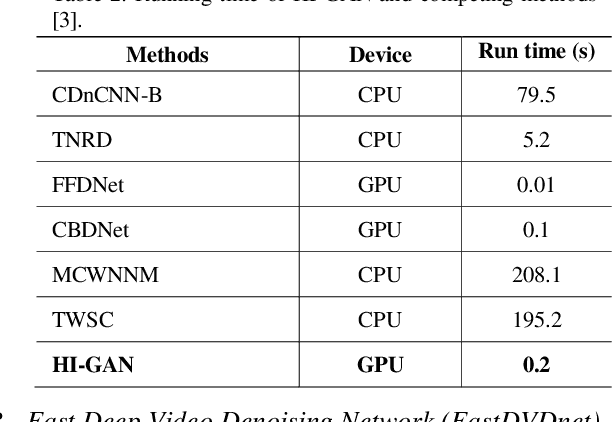
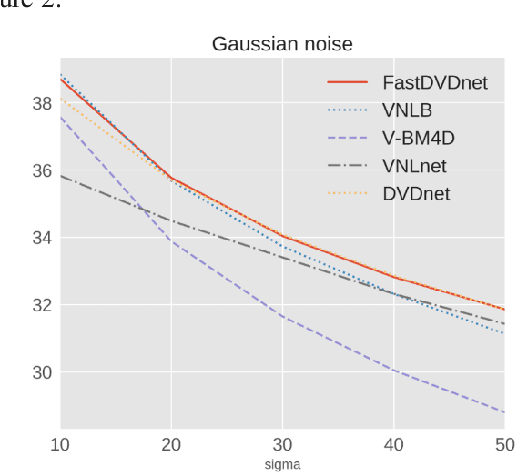
In this paper, we propose a pipeline for real-time video denoising with low runtime cost and high perceptual quality. The vast majority of denoising studies focus on image denoising. However, a minority of research works focusing on video denoising do so with higher performance costs to obtain higher quality while maintaining temporal coherence. The approach we introduce in this paper leverages the advantages of both image and video-denoising architectures. Our pipeline first denoises the keyframes or one-fifth of the frames using HI-GAN blind image denoising architecture. Then, the remaining four-fifths of the noisy frames and the denoised keyframe data are fed into the FastDVDnet video denoising model. The final output is rendered in the user's display in real-time. The combination of these low-latency neural network architectures produces real-time denoising with high perceptual quality with applications in video conferencing and other real-time media streaming systems. A custom noise detector analyzer provides real-time feedback to adapt the weights and improve the models' output.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Mar 25, 2023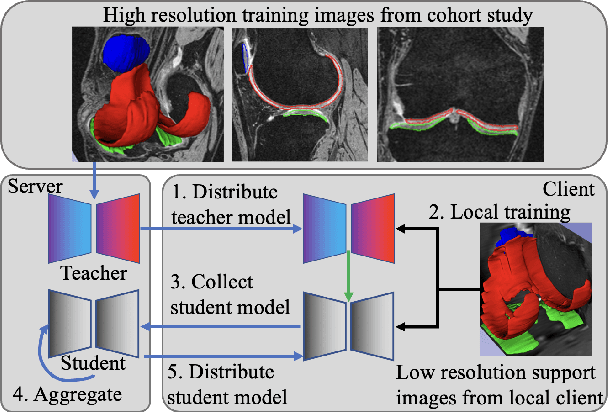

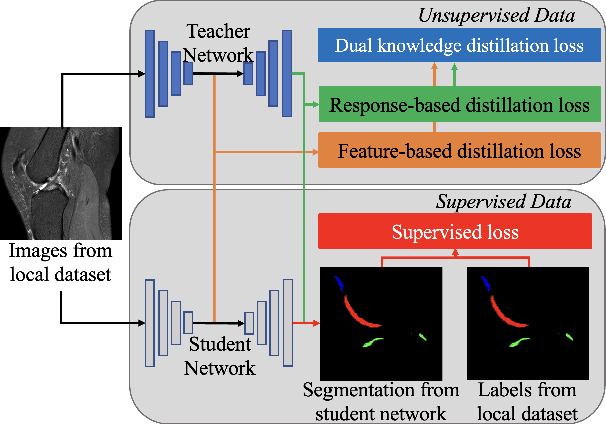
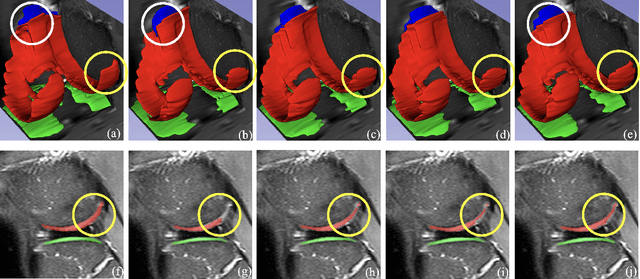
Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Shapley-based Explainable AI for Clustering Applications in Fault Diagnosis and Prognosis
Mar 25, 2023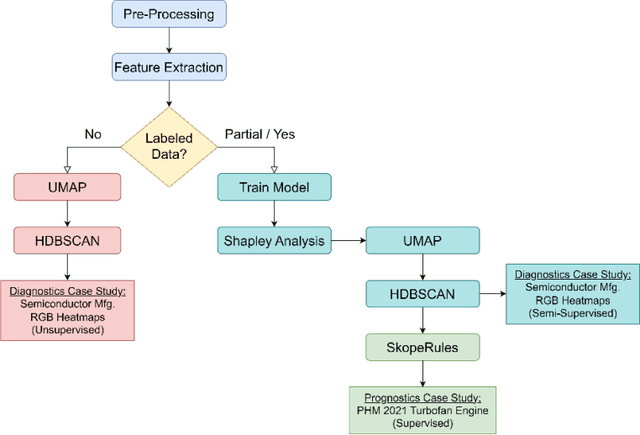
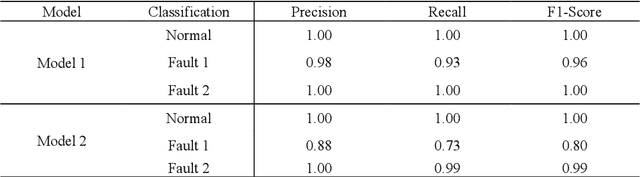
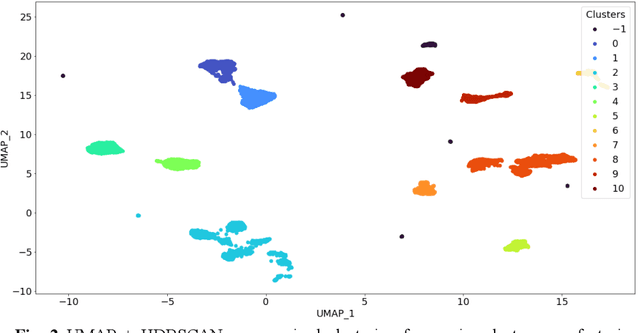
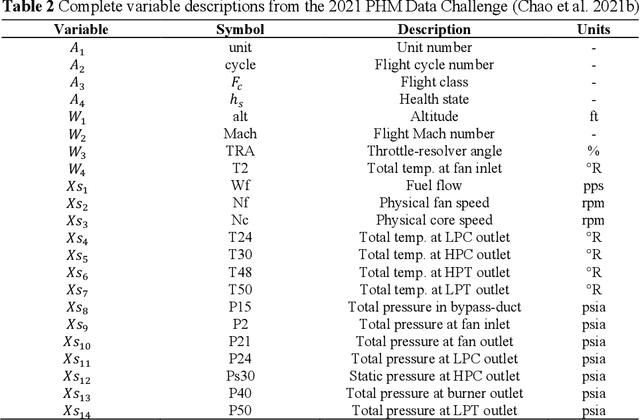
Data-driven artificial intelligence models require explainability in intelligent manufacturing to streamline adoption and trust in modern industry. However, recently developed explainable artificial intelligence (XAI) techniques that estimate feature contributions on a model-agnostic level such as SHapley Additive exPlanations (SHAP) have not yet been evaluated for semi-supervised fault diagnosis and prognosis problems characterized by class imbalance and weakly labeled datasets. This paper explores the potential of utilizing Shapley values for a new clustering framework compatible with semi-supervised learning problems, loosening the strict supervision requirement of current XAI techniques. This broad methodology is validated on two case studies: a heatmap image dataset obtained from a semiconductor manufacturing process featuring class imbalance, and a benchmark dataset utilized in the 2021 Prognostics and Health Management (PHM) Data Challenge. Semi-supervised clustering based on Shapley values significantly improves upon clustering quality compared to the fully unsupervised case, deriving information-dense and meaningful clusters that relate to underlying fault diagnosis model predictions. These clusters can also be characterized by high-precision decision rules in terms of original feature values, as demonstrated in the second case study. The rules, limited to 1-2 terms utilizing original feature scales, describe 12 out of the 16 derived equipment failure clusters with precision exceeding 0.85, showcasing the promising utility of the explainable clustering framework for intelligent manufacturing applications.