 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Reference Entropy Model for Learned Image Compression
Nov 14, 2022
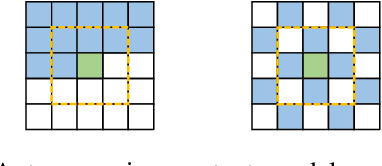

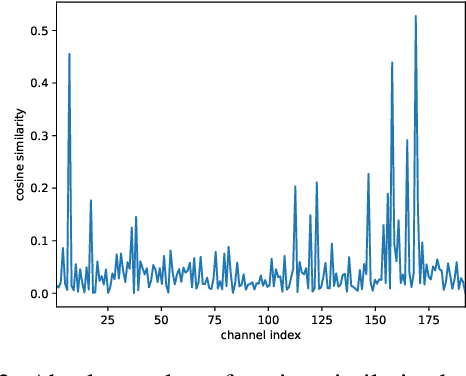
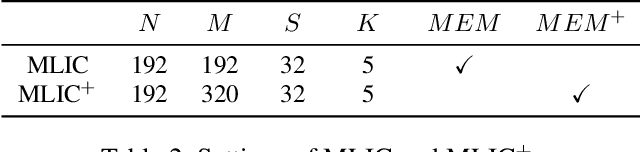
Recently, learned image compression has achieved remarkable performance. Entropy model, which accurately estimates the distribution of latent representation, plays an important role in boosting rate distortion performance. Most entropy models capture correlations in one dimension. However, there are channel-wise, local and global spatial correlations in latent representation. To address this issue, we propose multi-reference entropy models MEM and MEM+ to capture channel, local and global spatial contexts. We divide latent representation into slices. When decoding current slice, we use previously decoded slices as contexts and use attention map of previously decoded slice to predict global correlations in current slice. To capture local contexts, we propose enhanced checkerboard context capturing to avoid performance degradation while retaining two-pass decoding. Based on MEM and MEM+, we propose image compression models MLIC and MLIC+. Extensive experimental evaluations have shown that our MLIC and MLIC+ achieve state-of-the-art performance and they reduce BD-rate by 9.77% and 13.09% on Kodak dataset over VVC when measured in PSNR.
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022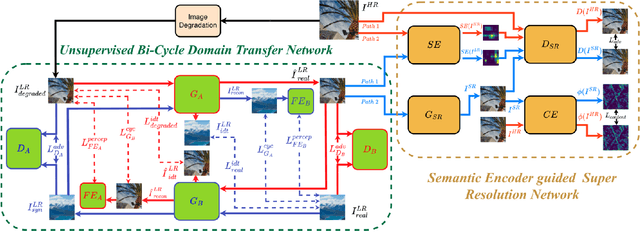
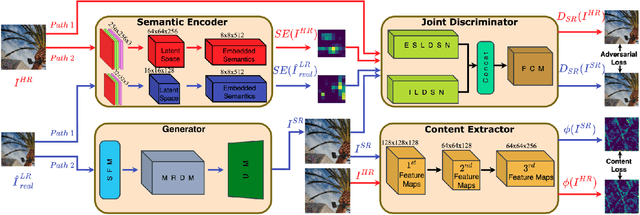
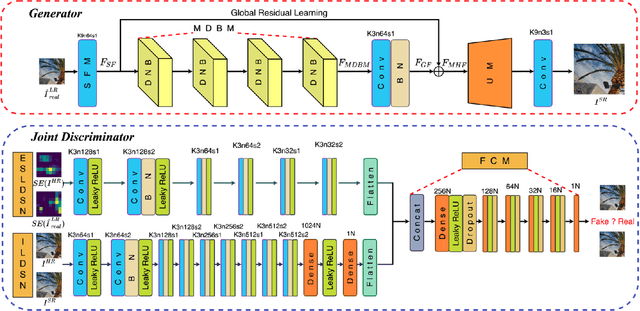

Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.
Effective black box adversarial attack with handcrafted kernels
Mar 24, 2023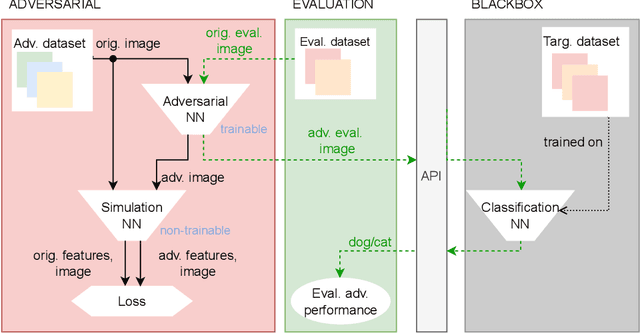
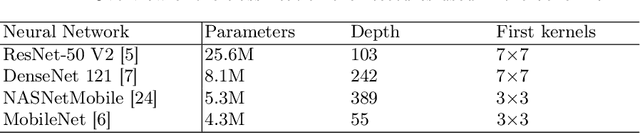


We propose a new, simple framework for crafting adversarial examples for black box attacks. The idea is to simulate the substitution model with a non-trainable model compounded of just one layer of handcrafted convolutional kernels and then train the generator neural network to maximize the distance of the outputs for the original and generated adversarial image. We show that fooling the prediction of the first layer causes the whole network to be fooled and decreases its accuracy on adversarial inputs. Moreover, we do not train the neural network to obtain the first convolutional layer kernels, but we create them using the technique of F-transform. Therefore, our method is very time and resource effective.
MrSARP: A Hierarchical Deep Generative Prior for SAR Image Super-resolution
Nov 30, 2022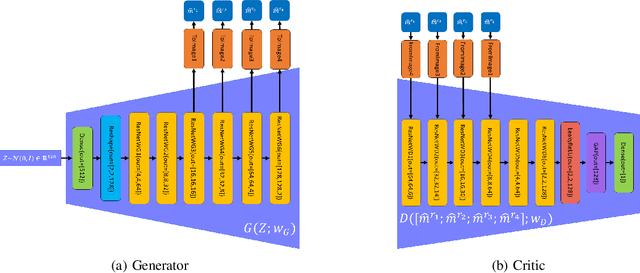
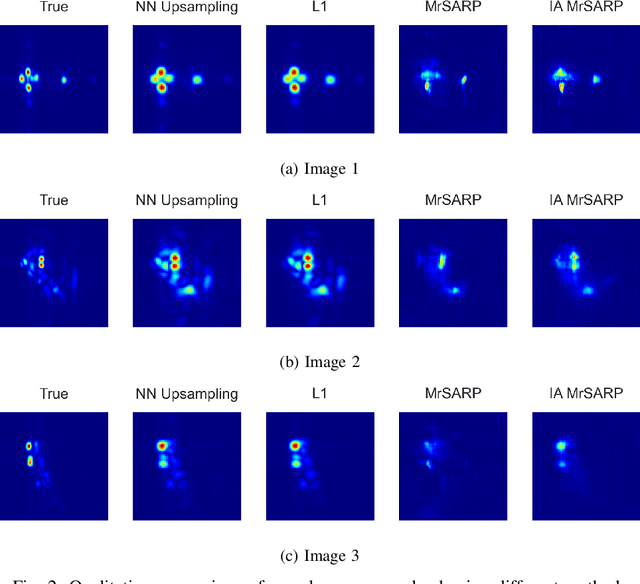
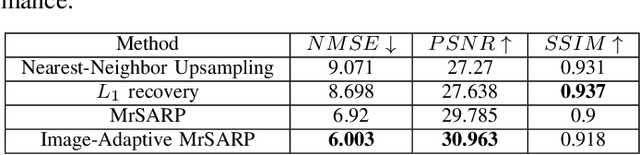
Generative models learned from training using deep learning methods can be used as priors in inverse under-determined inverse problems, including imaging from sparse set of measurements. In this paper, we present a novel hierarchical deep-generative model MrSARP for SAR imagery that can synthesize SAR images of a target at different resolutions jointly. MrSARP is trained in conjunction with a critic that scores multi resolution images jointly to decide if they are realistic images of a target at different resolutions. We show how this deep generative model can be used to retrieve the high spatial resolution image from low resolution images of the same target. The cost function of the generator is modified to improve its capability to retrieve the input parameters for a given set of resolution images. We evaluate the model's performance using the three standard error metrics used for evaluating super-resolution performance on simulated data and compare it to upsampling and sparsity based image sharpening approaches.
ISTA-Inspired Network for Image Super-Resolution
Oct 14, 2022
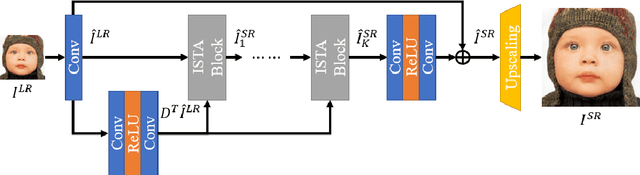
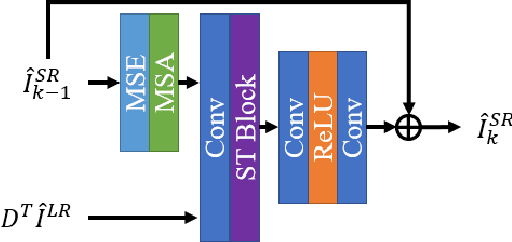
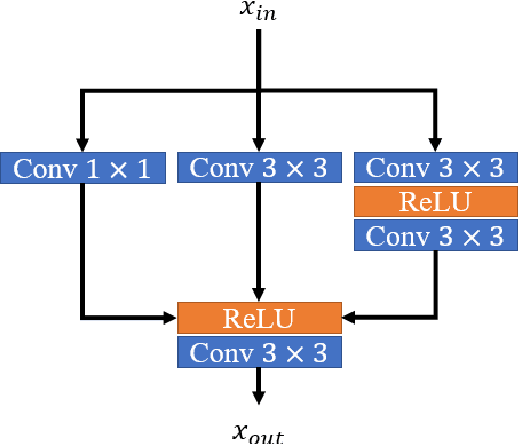
Deep learning for image super-resolution (SR) has been investigated by numerous researchers in recent years. Most of the works concentrate on effective block designs and improve the network representation but lack interpretation. There are also iterative optimization-inspired networks for image SR, which take the solution step as a whole without giving an explicit optimization step. This paper proposes an unfolding iterative shrinkage thresholding algorithm (ISTA) inspired network for interpretable image SR. Specifically, we analyze the problem of image SR and propose a solution based on the ISTA method. Inspired by the mathematical analysis, the ISTA block is developed to conduct the optimization in an end-to-end manner. To make the exploration more effective, a multi-scale exploitation block and multi-scale attention mechanism are devised to build the ISTA block. Experimental results show the proposed ISTA-inspired restoration network (ISTAR) achieves competitive or better performances than other optimization-inspired works with fewer parameters and lower computation complexity.
Image-Text Retrieval with Binary and Continuous Label Supervision
Oct 20, 2022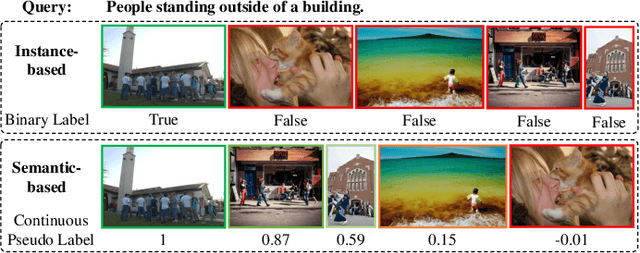
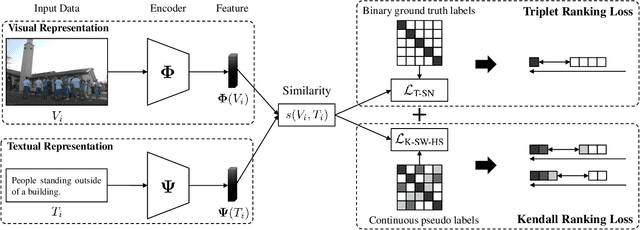
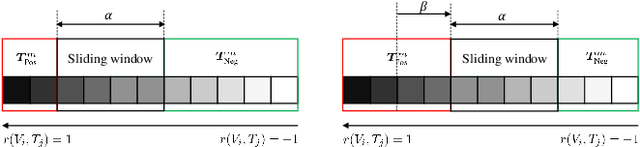
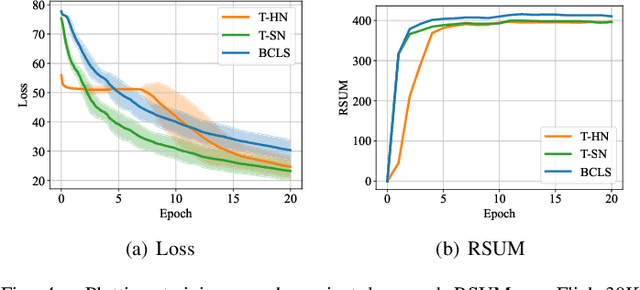
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.
Scene-centric vs. Object-centric Image-Text Cross-modal Retrieval: A Reproducibility Study
Jan 12, 2023
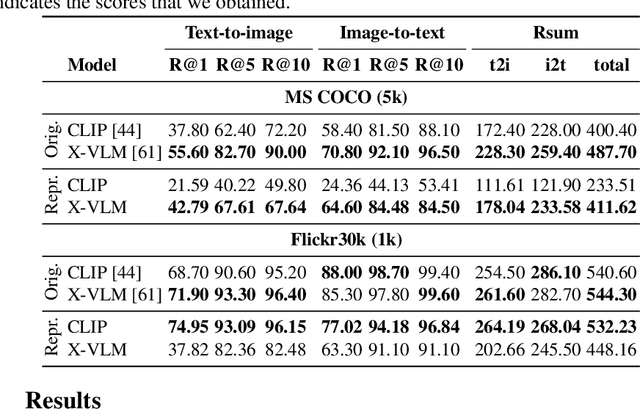
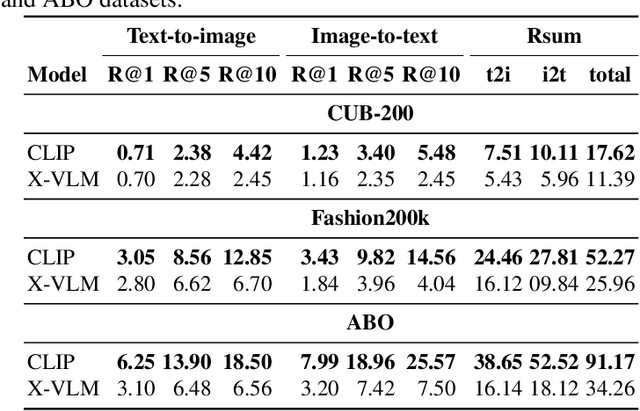
Most approaches to cross-modal retrieval (CMR) focus either on object-centric datasets, meaning that each document depicts or describes a single object, or on scene-centric datasets, meaning that each image depicts or describes a complex scene that involves multiple objects and relations between them. We posit that a robust CMR model should generalize well across both dataset types. Despite recent advances in CMR, the reproducibility of the results and their generalizability across different dataset types has not been studied before. We address this gap and focus on the reproducibility of the state-of-the-art CMR results when evaluated on object-centric and scene-centric datasets. We select two state-of-the-art CMR models with different architectures: (i) CLIP; and (ii) X-VLM. Additionally, we select two scene-centric datasets, and three object-centric datasets, and determine the relative performance of the selected models on these datasets. We focus on reproducibility, replicability, and generalizability of the outcomes of previously published CMR experiments. We discover that the experiments are not fully reproducible and replicable. Besides, the relative performance results partially generalize across object-centric and scene-centric datasets. On top of that, the scores obtained on object-centric datasets are much lower than the scores obtained on scene-centric datasets. For reproducibility and transparency we make our source code and the trained models publicly available.
Guided Depth Map Super-resolution: A Survey
Mar 07, 2023

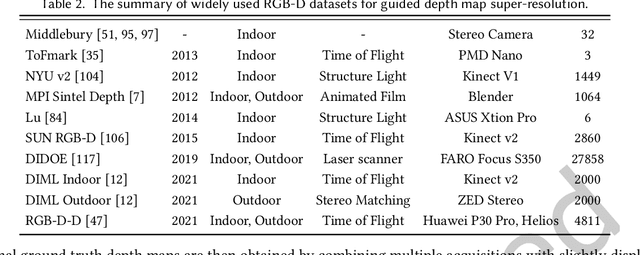
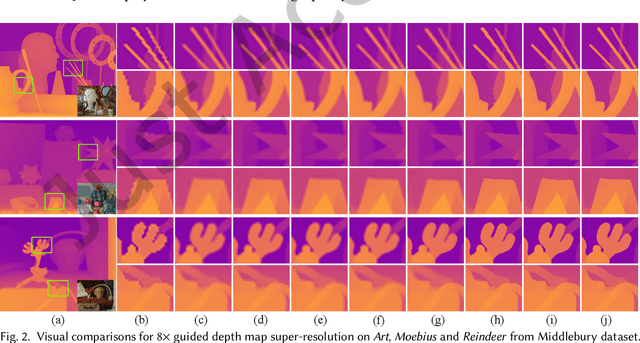
Guided depth map super-resolution (GDSR), which aims to reconstruct a high-resolution (HR) depth map from a low-resolution (LR) observation with the help of a paired HR color image, is a longstanding and fundamental problem, it has attracted considerable attention from computer vision and image processing communities. A myriad of novel and effective approaches have been proposed recently, especially with powerful deep learning techniques. This survey is an effort to present a comprehensive survey of recent progress in GDSR. We start by summarizing the problem of GDSR and explaining why it is challenging. Next, we introduce some commonly used datasets and image quality assessment methods. In addition, we roughly classify existing GDSR methods into three categories, i.e., filtering-based methods, prior-based methods, and learning-based methods. In each category, we introduce the general description of the published algorithms and design principles, summarize the representative methods, and discuss their highlights and limitations. Moreover, the depth related applications are introduced. Furthermore, we conduct experiments to evaluate the performance of some representative methods based on unified experimental configurations, so as to offer a systematic and fair performance evaluation to readers. Finally, we conclude this survey with possible directions and open problems for further research. All the related materials can be found at \url{https://github.com/zhwzhong/Guided-Depth-Map-Super-resolution-A-Survey}.
Uncertainty-Aware Multi-Parametric Magnetic Resonance Image Information Fusion for 3D Object Segmentation
Nov 16, 2022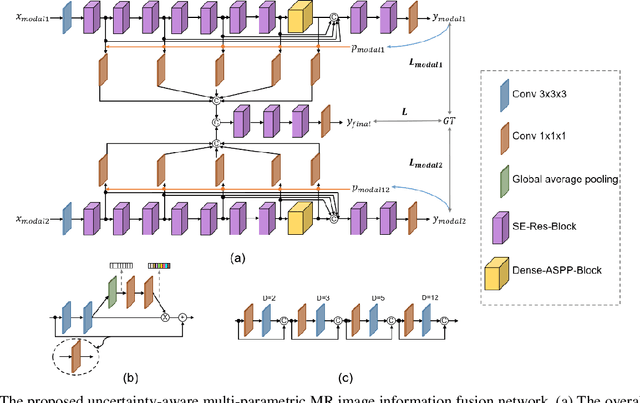
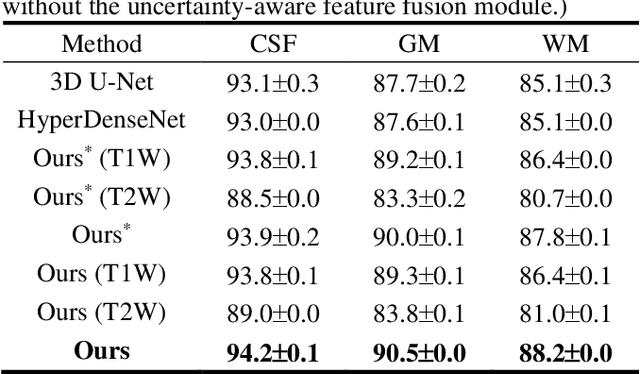
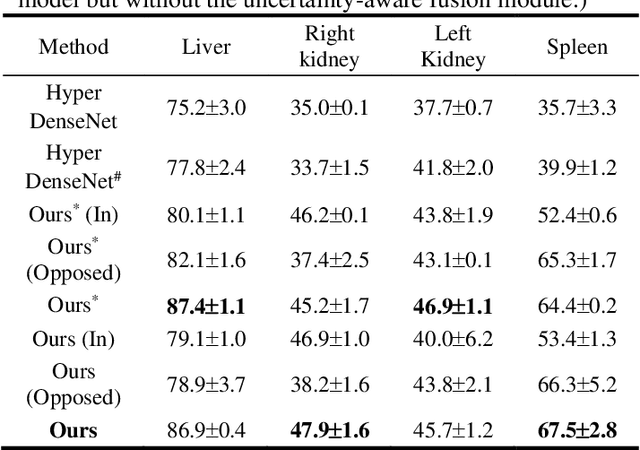
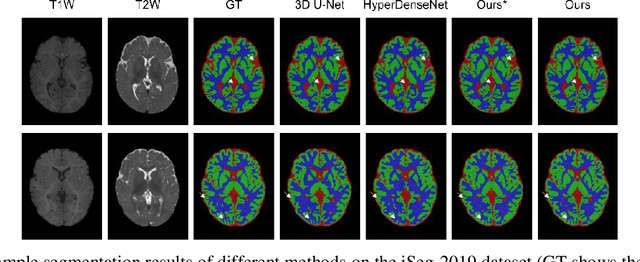
Multi-parametric magnetic resonance (MR) imaging is an indispensable tool in the clinic. Consequently, automatic volume-of-interest segmentation based on multi-parametric MR imaging is crucial for computer-aided disease diagnosis, treatment planning, and prognosis monitoring. Despite the extensive studies conducted in deep learning-based medical image analysis, further investigations are still required to effectively exploit the information provided by different imaging parameters. How to fuse the information is a key question in this field. Here, we propose an uncertainty-aware multi-parametric MR image feature fusion method to fully exploit the information for enhanced 3D image segmentation. Uncertainties in the independent predictions of individual modalities are utilized to guide the fusion of multi-modal image features. Extensive experiments on two datasets, one for brain tissue segmentation and the other for abdominal multi-organ segmentation, have been conducted, and our proposed method achieves better segmentation performance when compared to existing models.
A Learned Pixel-by-Pixel Lossless Image Compression Method with 59K Parameters and Parallel Decoding
Dec 02, 2022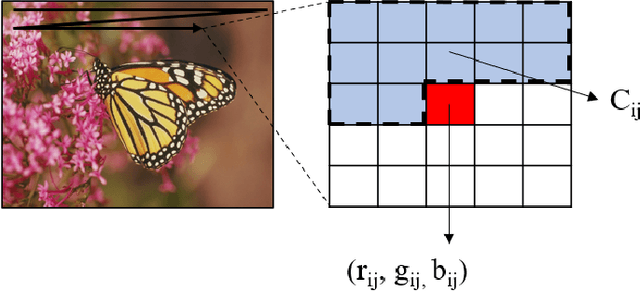
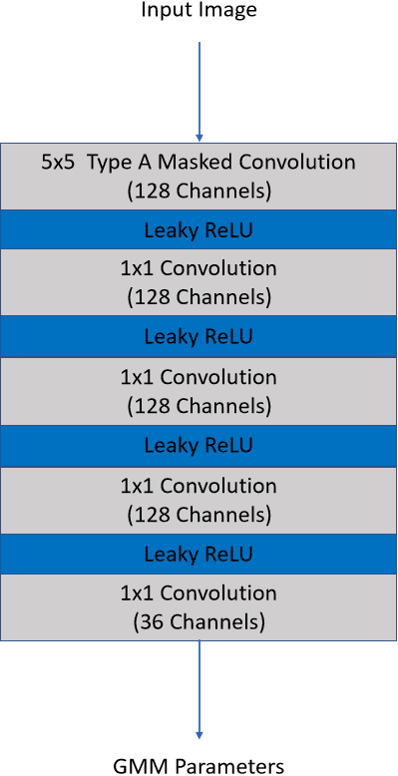
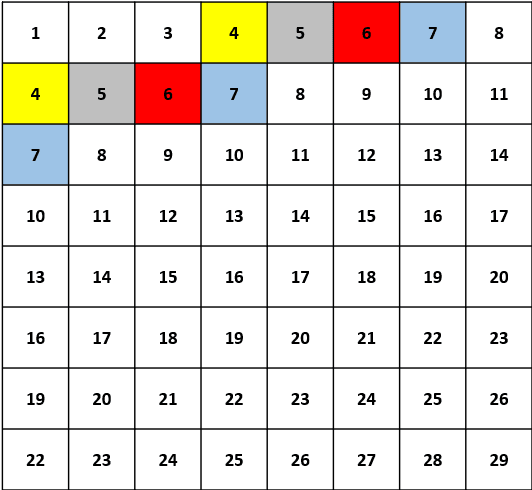
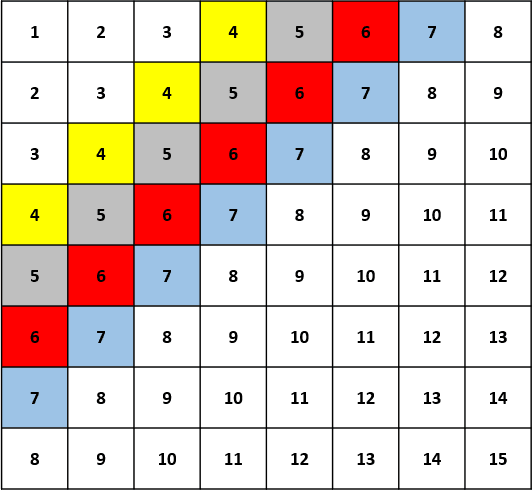
This paper considers lossless image compression and presents a learned compression system that can achieve state-of-the-art lossless compression performance but uses only 59K parameters, which is more than 30x less than other learned systems proposed recently in the literature. The explored system is based on a learned pixel-by-pixel lossless image compression method, where each pixel's probability distribution parameters are obtained by processing the pixel's causal neighborhood (i.e. previously encoded/decoded pixels) with a simple neural network comprising 59K parameters. This causality causes the decoder to operate sequentially, i.e. the neural network has to be evaluated for each pixel sequentially, which increases decoding time significantly with common GPU software and hardware. To reduce the decoding time, parallel decoding algorithms are proposed and implemented. The obtained lossless image compression system is compared to traditional and learned systems in the literature in terms of compression performance, encoding-decoding times and computational complexity.