 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Images to Features: Unbiased Morphology Classification via Variational Auto-Encoders and Domain Adaptation
Mar 15, 2023

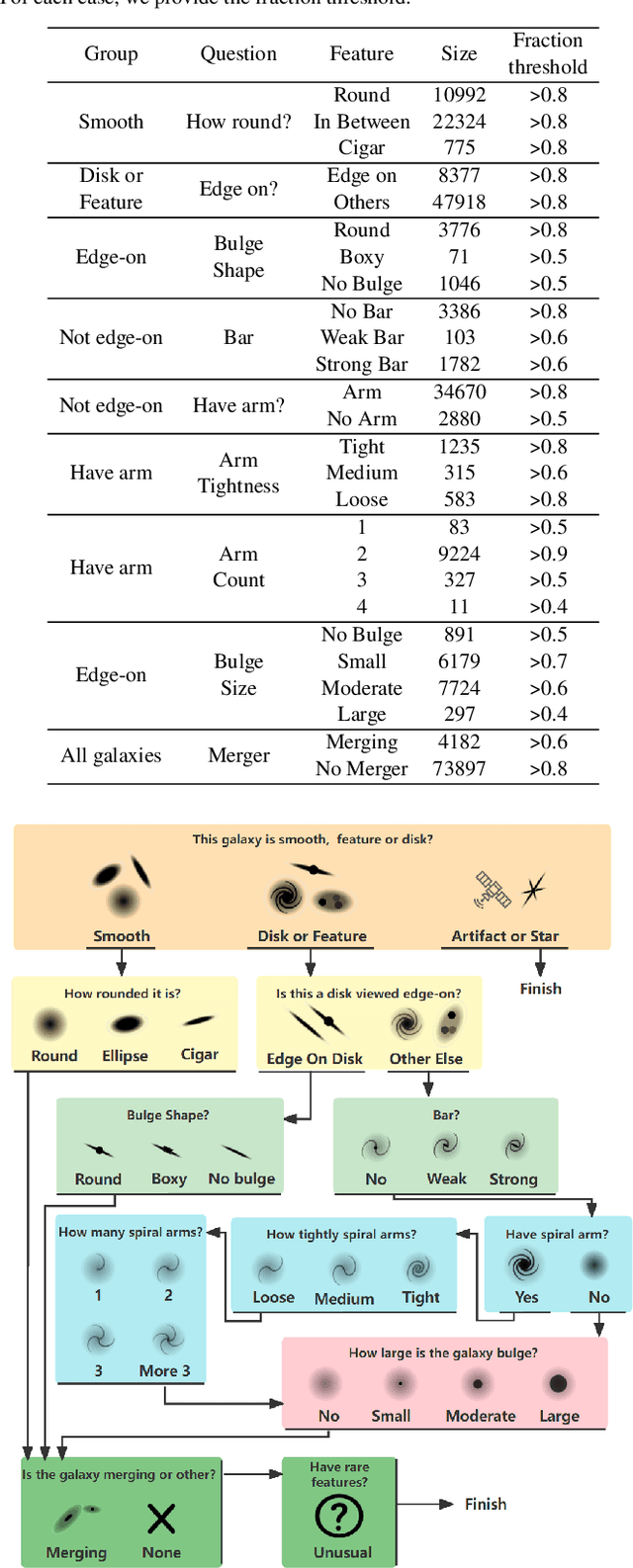
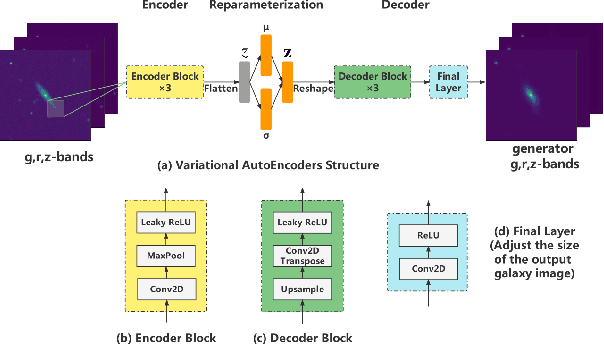
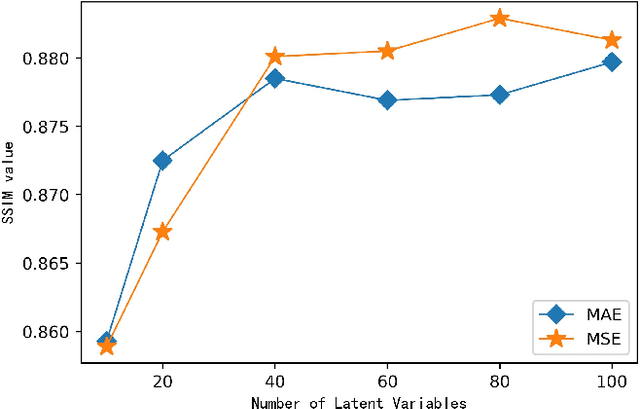
We present a novel approach for the dimensionality reduction of galaxy images by leveraging a combination of variational auto-encoders (VAE) and domain adaptation (DA). We demonstrate the effectiveness of this approach using a sample of low redshift galaxies with detailed morphological type labels from the Galaxy-Zoo DECaLS project. We show that 40-dimensional latent variables can effectively reproduce most morphological features in galaxy images. To further validate the effectiveness of our approach, we utilised a classical random forest (RF) classifier on the 40-dimensional latent variables to make detailed morphology feature classifications. This approach performs similarly to a direct neural network application on galaxy images. We further enhance our model by tuning the VAE network via DA using galaxies in the overlapping footprint of DECaLS and BASS+MzLS, enabling the unbiased application of our model to galaxy images in both surveys. We observed that noise suppression during DA led to even better morphological feature extraction and classification performance. Overall, this combination of VAE and DA can be applied to achieve image dimensionality reduction, defect image identification, and morphology classification in large optical surveys.
DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
Mar 15, 2023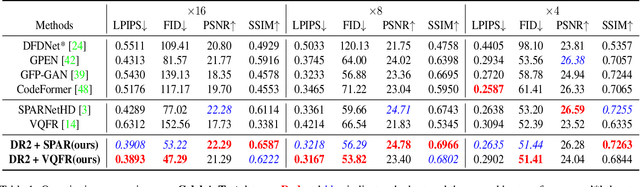
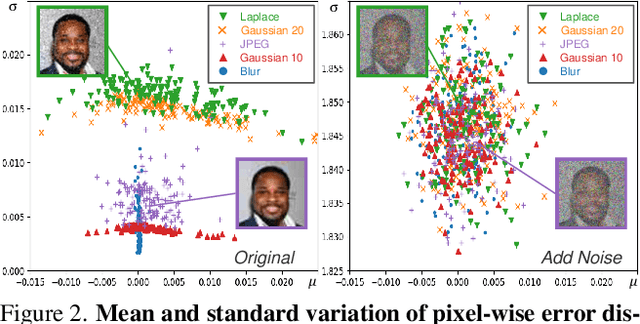
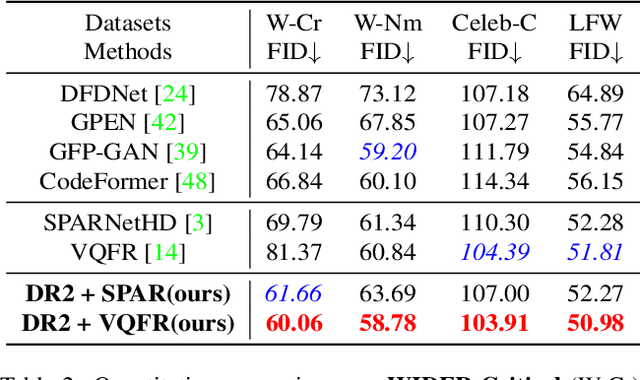
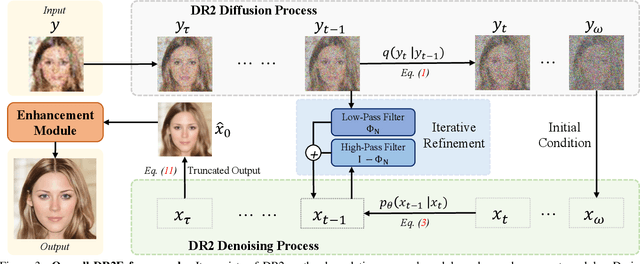
Blind face restoration usually synthesizes degraded low-quality data with a pre-defined degradation model for training, while more complex cases could happen in the real world. This gap between the assumed and actual degradation hurts the restoration performance where artifacts are often observed in the output. However, it is expensive and infeasible to include every type of degradation to cover real-world cases in the training data. To tackle this robustness issue, we propose Diffusion-based Robust Degradation Remover (DR2) to first transform the degraded image to a coarse but degradation-invariant prediction, then employ an enhancement module to restore the coarse prediction to a high-quality image. By leveraging a well-performing denoising diffusion probabilistic model, our DR2 diffuses input images to a noisy status where various types of degradation give way to Gaussian noise, and then captures semantic information through iterative denoising steps. As a result, DR2 is robust against common degradation (e.g. blur, resize, noise and compression) and compatible with different designs of enhancement modules. Experiments in various settings show that our framework outperforms state-of-the-art methods on heavily degraded synthetic and real-world datasets.
DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
Apr 03, 2023
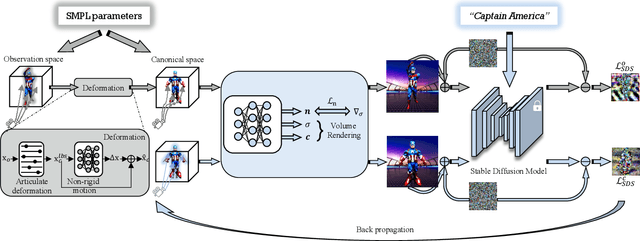


We present DreamAvatar, a text-and-shape guided framework for generating high-quality 3D human avatars with controllable poses. While encouraging results have been produced by recent methods on text-guided 3D common object generation, generating high-quality human avatars remains an open challenge due to the complexity of the human body's shape, pose, and appearance. We propose DreamAvatar to tackle this challenge, which utilizes a trainable NeRF for predicting density and color features for 3D points and a pre-trained text-to-image diffusion model for providing 2D self-supervision. Specifically, we leverage SMPL models to provide rough pose and shape guidance for the generation. We introduce a dual space design that comprises a canonical space and an observation space, which are related by a learnable deformation field through the NeRF, allowing for the transfer of well-optimized texture and geometry from the canonical space to the target posed avatar. Additionally, we exploit a normal-consistency regularization to allow for more vivid generation with detailed geometry and texture. Through extensive evaluations, we demonstrate that DreamAvatar significantly outperforms existing methods, establishing a new state-of-the-art for text-and-shape guided 3D human generation.
Matched Machine Learning: A Generalized Framework for Treatment Effect Inference With Learned Metrics
Apr 03, 2023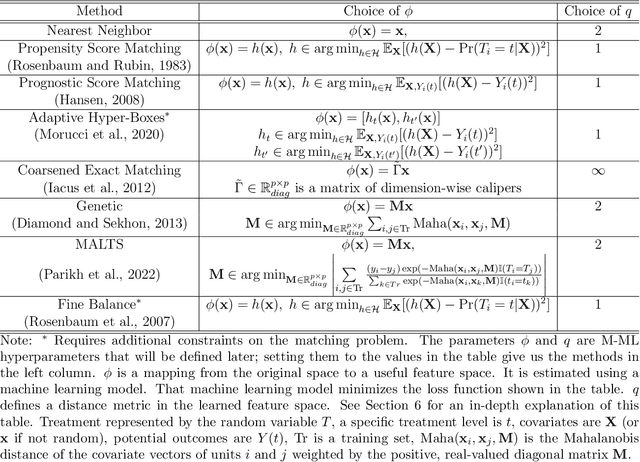
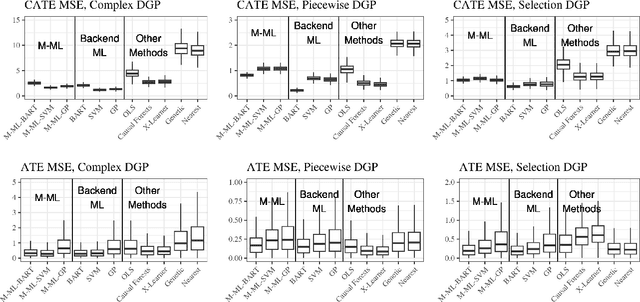
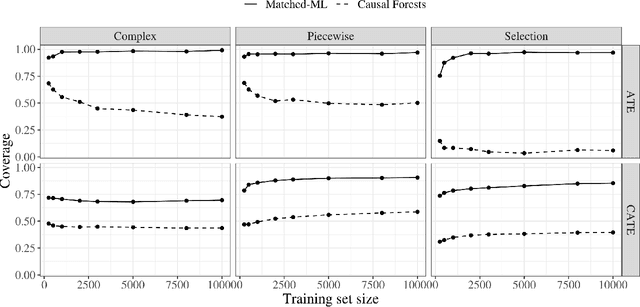

We introduce Matched Machine Learning, a framework that combines the flexibility of machine learning black boxes with the interpretability of matching, a longstanding tool in observational causal inference. Interpretability is paramount in many high-stakes application of causal inference. Current tools for nonparametric estimation of both average and individualized treatment effects are black-boxes that do not allow for human auditing of estimates. Our framework uses machine learning to learn an optimal metric for matching units and estimating outcomes, thus achieving the performance of machine learning black-boxes, while being interpretable. Our general framework encompasses several published works as special cases. We provide asymptotic inference theory for our proposed framework, enabling users to construct approximate confidence intervals around estimates of both individualized and average treatment effects. We show empirically that instances of Matched Machine Learning perform on par with black-box machine learning methods and better than existing matching methods for similar problems. Finally, in our application we show how Matched Machine Learning can be used to perform causal inference even when covariate data are highly complex: we study an image dataset, and produce high quality matches and estimates of treatment effects.
Semi-Automated Computer Vision based Tracking of Multiple Industrial Entities -- A Framework and Dataset Creation Approach
Apr 03, 2023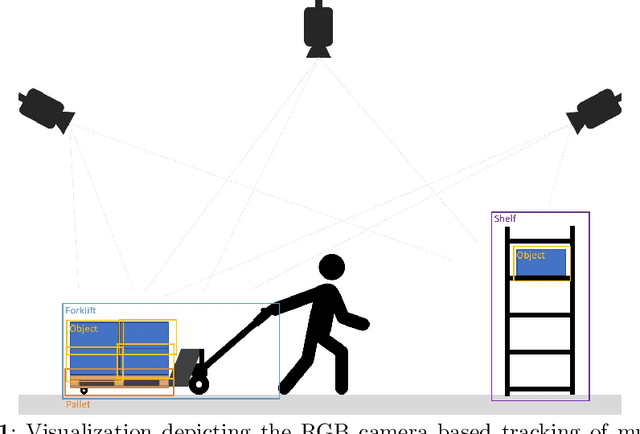
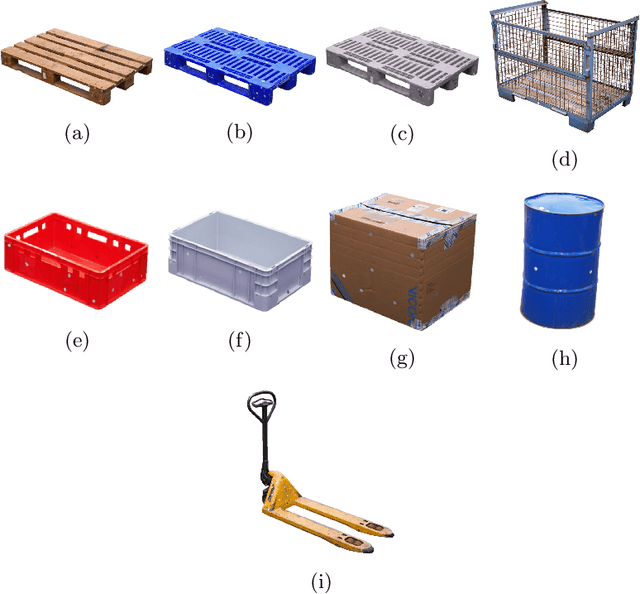

This contribution presents the TOMIE framework (Tracking Of Multiple Industrial Entities), a framework for the continuous tracking of industrial entities (e.g., pallets, crates, barrels) over a network of, in this example, six RGB cameras. This framework, makes use of multiple sensors, data pipelines and data annotation procedures, and is described in detail in this contribution. With the vision of a fully automated tracking system for industrial entities in mind, it enables researchers to efficiently capture high quality data in an industrial setting. Using this framework, an image dataset, the TOMIE dataset, is created, which at the same time is used to gauge the framework's validity. This dataset contains annotation files for 112,860 frames and 640,936 entity instances that are captured from a set of six cameras that perceive a large indoor space. This dataset out-scales comparable datasets by a factor of four and is made up of scenarios, drawn from industrial applications from the sector of warehousing. Three tracking algorithms, namely ByteTrack, Bot-Sort and SiamMOT are applied to this dataset, serving as a proof-of-concept and providing tracking results that are comparable to the state of the art.
Controllable Video Generation by Learning the Underlying Dynamical System with Neural ODE
Mar 09, 2023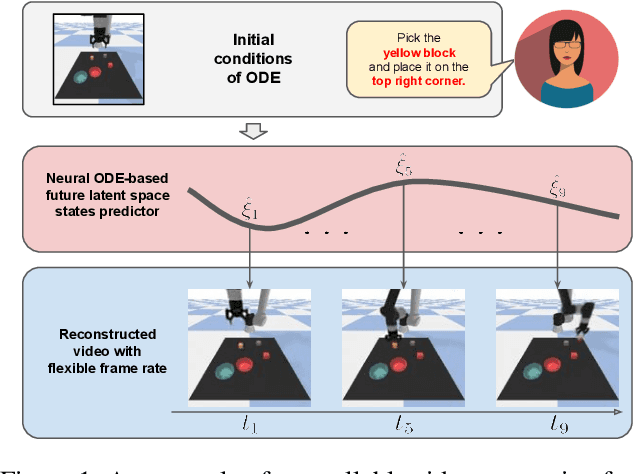
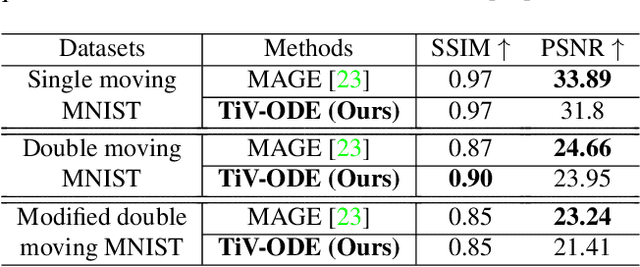
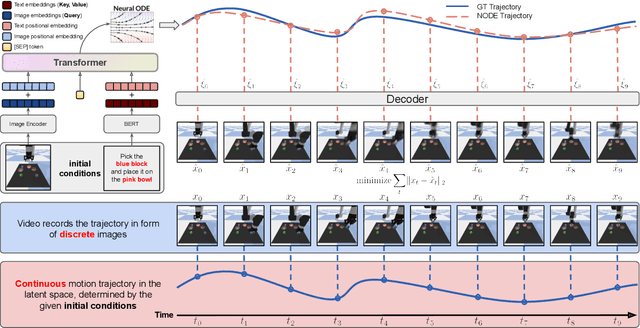
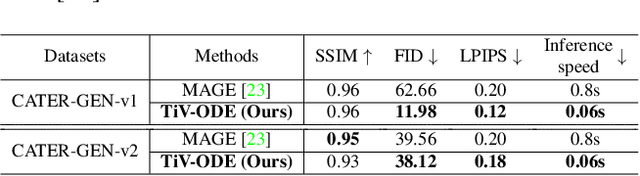
Videos depict the change of complex dynamical systems over time in the form of discrete image sequences. Generating controllable videos by learning the dynamical system is an important yet underexplored topic in the computer vision community. This paper presents a novel framework, TiV-ODE, to generate highly controllable videos from a static image and a text caption. Specifically, our framework leverages the ability of Neural Ordinary Differential Equations~(Neural ODEs) to represent complex dynamical systems as a set of nonlinear ordinary differential equations. The resulting framework is capable of generating videos with both desired dynamics and content. Experiments demonstrate the ability of the proposed method in generating highly controllable and visually consistent videos, and its capability of modeling dynamical systems. Overall, this work is a significant step towards developing advanced controllable video generation models that can handle complex and dynamic scenes.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Nov 08, 2022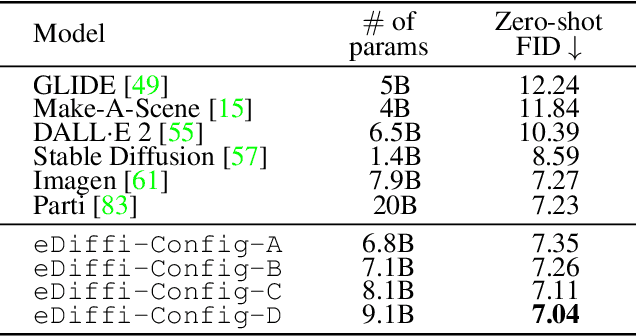
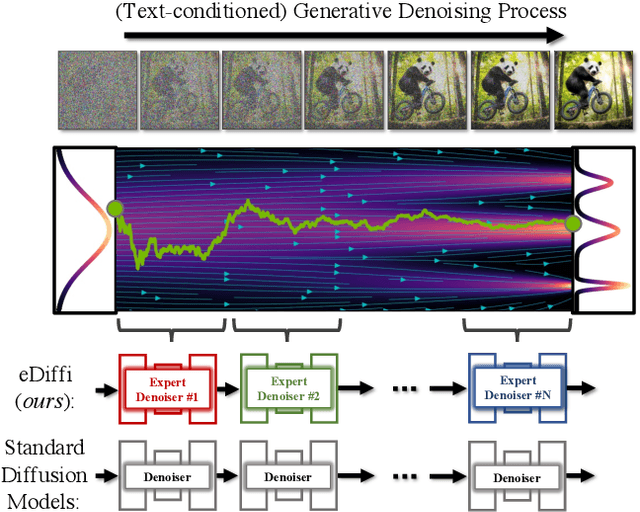

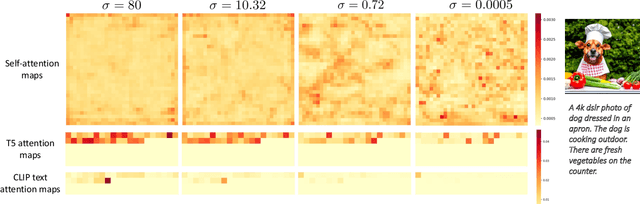
Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/
Amélioration de la qualité d'images avec un algorithme d'optimisation inspirée par la nature
Mar 13, 2023
Reproducible images preprocessing is important in the field of computer vision, for efficient algorithms comparison or for new images corpus preparation. In this paper, we propose a method to obtain an explicit and ordered sequence of transformations that improves a given image: the computation is performed via a nature-inspired optimization algorithm based on quality assessment techniques. Preliminary tests show the impact of the approach on different state-of-the-art data sets. -- L'application de pr\'etraitements explicites et reproductibles est fondamentale dans le domaine de la vision par ordinateur, pour pouvoir comparer efficacement des algorithmes ou pour pr\'eparer un nouveau corpus d'images. Dans cet article, nous proposons une m\'ethode pour obtenir une s\'equence reproductible de transformations qui am\'eliore une image donn\'ee: le calcul est r\'ealis\'e via un algorithme d'optimisation inspir\'ee par la nature et bas\'e sur des techniques d'\'evaluation de la qualit\'e. Des tests montrent l'impact de l'approche sur diff\'erents ensembles d'images de l'\'etat de l'art.
Using simulation to quantify the performance of automotive perception systems
Mar 10, 2023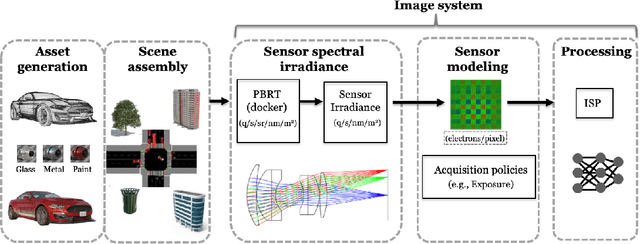

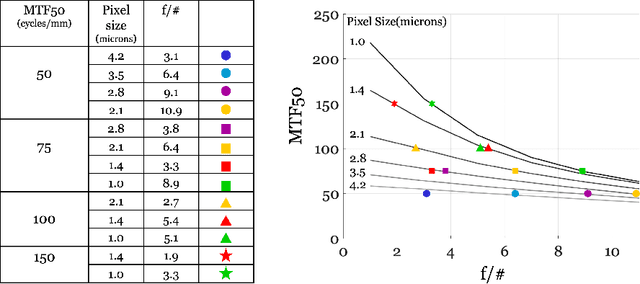
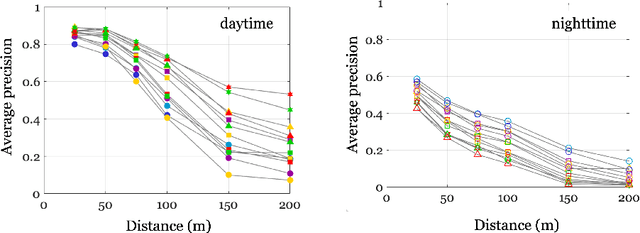
The design and evaluation of complex systems can benefit from a software simulation - sometimes called a digital twin. The simulation can be used to characterize system performance or to test its performance under conditions that are difficult to measure (e.g., nighttime for automotive perception systems). We describe the image system simulation software tools that we use to evaluate the performance of image systems for object (automobile) detection. We describe experiments with 13 different cameras with a variety of optics and pixel sizes. To measure the impact of camera spatial resolution, we designed a collection of driving scenes that had cars at many different distances. We quantified system performance by measuring average precision and we report a trend relating system resolution and object detection performance. We also quantified the large performance degradation under nighttime conditions, compared to daytime, for all cameras and a COCO pre-trained network.
ConvFormer: Combining CNN and Transformer for Medical Image Segmentation
Nov 15, 2022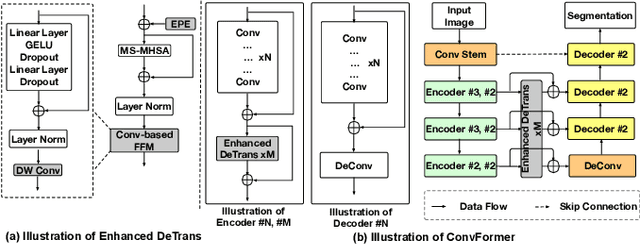
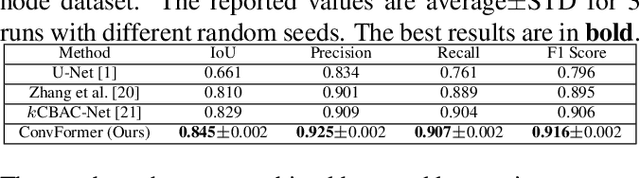
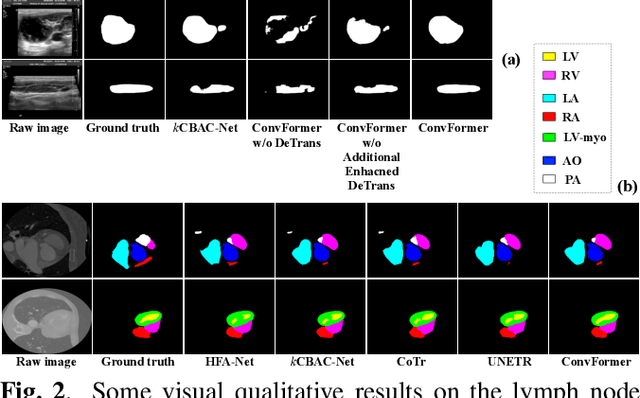
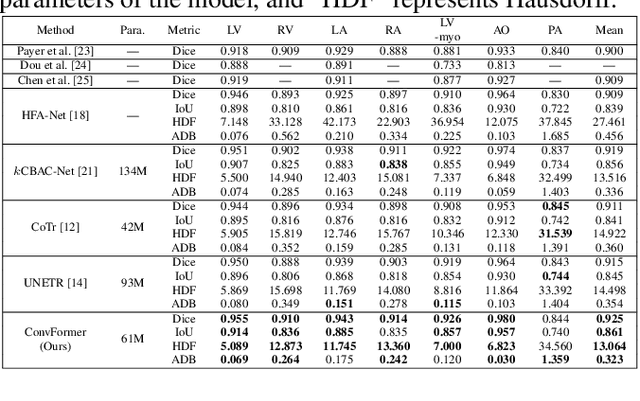
Convolutional neural network (CNN) based methods have achieved great successes in medical image segmentation, but their capability to learn global representations is still limited due to using small effective receptive fields of convolution operations. Transformer based methods are capable of modelling long-range dependencies of information for capturing global representations, yet their ability to model local context is lacking. Integrating CNN and Transformer to learn both local and global representations while exploring multi-scale features is instrumental in further improving medical image segmentation. In this paper, we propose a hierarchical CNN and Transformer hybrid architecture, called ConvFormer, for medical image segmentation. ConvFormer is based on several simple yet effective designs. (1) A feed forward module of Deformable Transformer (DeTrans) is re-designed to introduce local information, called Enhanced DeTrans. (2) A residual-shaped hybrid stem based on a combination of convolutions and Enhanced DeTrans is developed to capture both local and global representations to enhance representation ability. (3) Our encoder utilizes the residual-shaped hybrid stem in a hierarchical manner to generate feature maps in different scales, and an additional Enhanced DeTrans encoder with residual connections is built to exploit multi-scale features with feature maps of different scales as input. Experiments on several datasets show that our ConvFormer, trained from scratch, outperforms various CNN- or Transformer-based architectures, achieving state-of-the-art performance.