 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Double Machine Learning Approach to Combining Experimental and Observational Data
Jul 04, 2023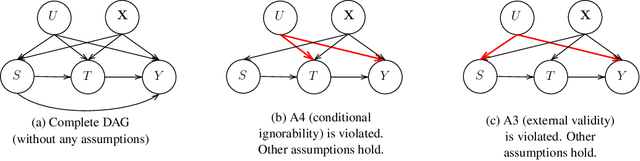

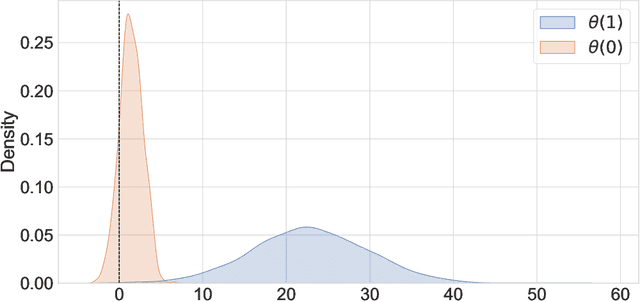
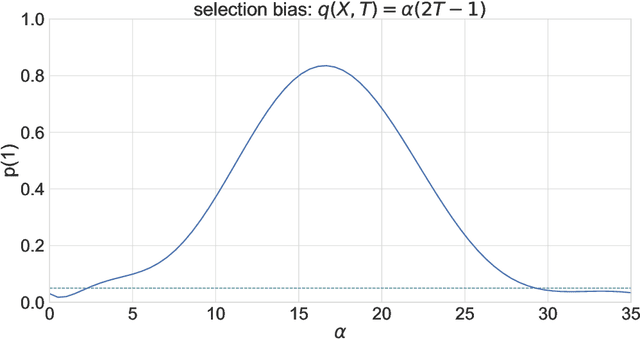
Experimental and observational studies often lack validity due to untestable assumptions. We propose a double machine learning approach to combine experimental and observational studies, allowing practitioners to test for assumption violations and estimate treatment effects consistently. Our framework tests for violations of external validity and ignorability under milder assumptions. When only one assumption is violated, we provide semi-parametrically efficient treatment effect estimators. However, our no-free-lunch theorem highlights the necessity of accurately identifying the violated assumption for consistent treatment effect estimation. We demonstrate the applicability of our approach in three real-world case studies, highlighting its relevance for practical settings.
Multi-Task Learning Improves Performance In Deep Argument Mining Models
Jul 03, 2023The successful analysis of argumentative techniques from user-generated text is central to many downstream tasks such as political and market analysis. Recent argument mining tools use state-of-the-art deep learning methods to extract and annotate argumentative techniques from various online text corpora, however each task is treated as separate and different bespoke models are fine-tuned for each dataset. We show that different argument mining tasks share common semantic and logical structure by implementing a multi-task approach to argument mining that achieves better performance than state-of-the-art methods for the same problems. Our model builds a shared representation of the input text that is common to all tasks and exploits similarities between tasks in order to further boost performance via parameter-sharing. Our results are important for argument mining as they show that different tasks share substantial similarities and suggest a holistic approach to the extraction of argumentative techniques from text.
Matched Machine Learning: A Generalized Framework for Treatment Effect Inference With Learned Metrics
Apr 03, 2023



We introduce Matched Machine Learning, a framework that combines the flexibility of machine learning black boxes with the interpretability of matching, a longstanding tool in observational causal inference. Interpretability is paramount in many high-stakes application of causal inference. Current tools for nonparametric estimation of both average and individualized treatment effects are black-boxes that do not allow for human auditing of estimates. Our framework uses machine learning to learn an optimal metric for matching units and estimating outcomes, thus achieving the performance of machine learning black-boxes, while being interpretable. Our general framework encompasses several published works as special cases. We provide asymptotic inference theory for our proposed framework, enabling users to construct approximate confidence intervals around estimates of both individualized and average treatment effects. We show empirically that instances of Matched Machine Learning perform on par with black-box machine learning methods and better than existing matching methods for similar problems. Finally, in our application we show how Matched Machine Learning can be used to perform causal inference even when covariate data are highly complex: we study an image dataset, and produce high quality matches and estimates of treatment effects.
dame-flame: A Python Library Providing Fast Interpretable Matching for Causal Inference
Jan 14, 2021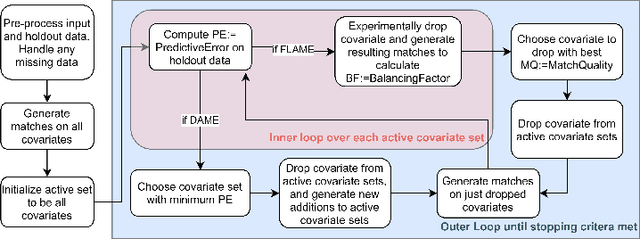
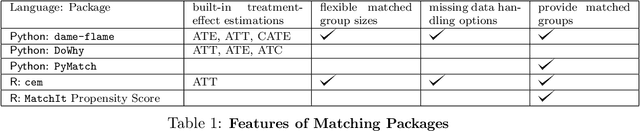
dame-flame is a Python package for performing matching for observational causal inference on datasets containing discrete covariates. This package implements the Dynamic Almost Matching Exactly (DAME) and Fast Large-Scale Almost Matching Exactly (FLAME) algorithms, which match treatment and control units on subsets of the covariates. The resulting matched groups are interpretable, because the matches are made on covariates (rather than, for instance, propensity scores), and high-quality, because machine learning is used to determine which covariates are important to match on. DAME solves an optimization problem that matches units on as many covariates as possible, prioritizing matches on important covariates. FLAME approximates the solution found by DAME via a much faster backward feature selection procedure. The package provides several adjustable parameters to adapt the algorithms to specific applications, and can calculate treatment effects after matching. Descriptions of these parameters, details on estimating treatment effects, and further examples, can be found in the documentation at https://almost-matching-exactly.github.io/DAME-FLAME-Python-Package/
Adaptive Hyper-box Matching for Interpretable Individualized Treatment Effect Estimation
Mar 03, 2020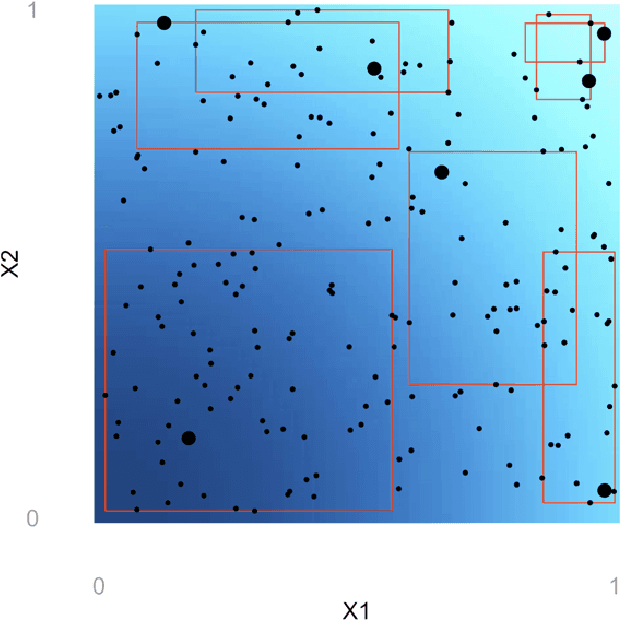

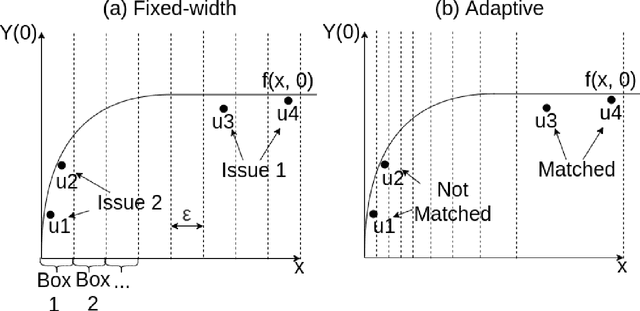
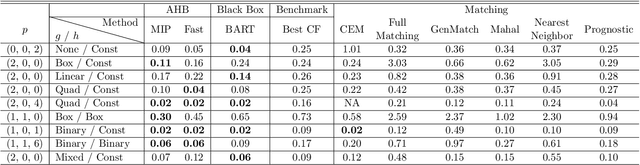
We propose a matching method for observational data that matches units with others in unit-specific, hyper-box-shaped regions of the covariate space. These regions are large enough that many matches are created for each unit and small enough that the treatment effect is roughly constant throughout. The regions are found as either the solution to a mixed integer program, or using a (fast) approximation algorithm. The result is an interpretable and tailored estimate of a causal effect for each unit.
Almost-Matching-Exactly for Treatment Effect Estimation under Network Interference
Mar 02, 2020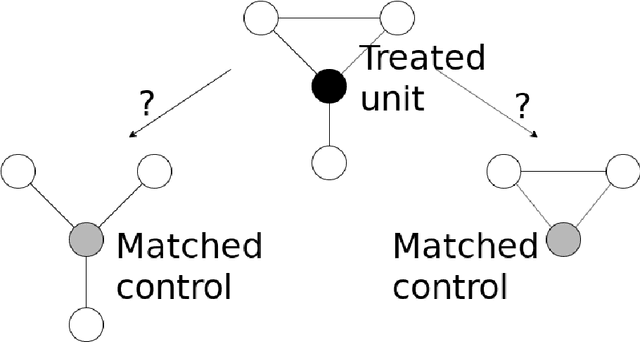

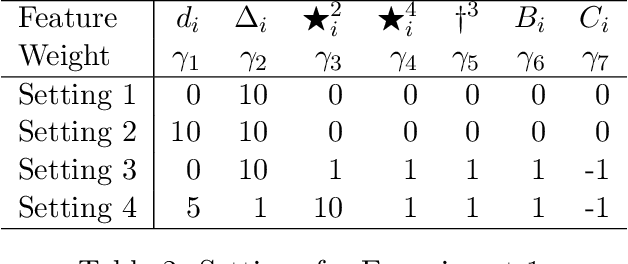
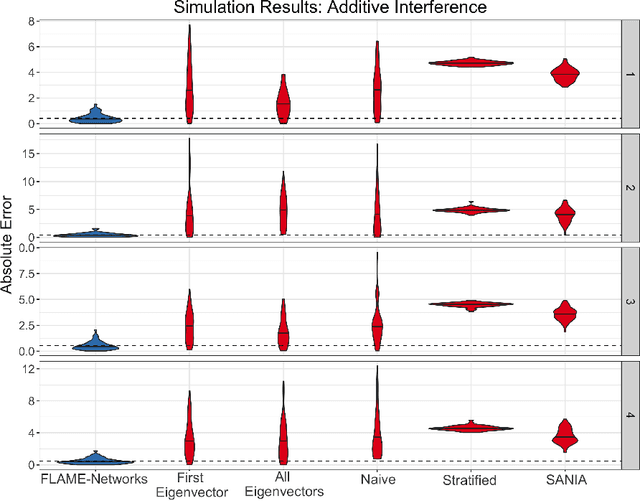
We propose a matching method that recovers direct treatment effects from randomized experiments where units are connected in an observed network, and units that share edges can potentially influence each others' outcomes. Traditional treatment effect estimators for randomized experiments are biased and error prone in this setting. Our method matches units almost exactly on counts of unique subgraphs within their neighborhood graphs. The matches that we construct are interpretable and high-quality. Our method can be extended easily to accommodate additional unit-level covariate information. We show empirically that our method performs better than other existing methodologies for this problem, while producing meaningful, interpretable results.
Interpretable Almost-Matching-Exactly With Instrumental Variables
Jul 28, 2019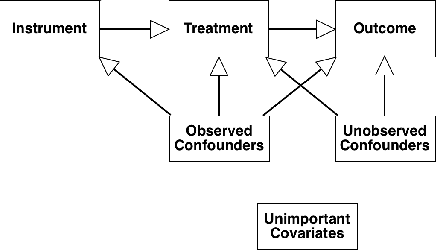

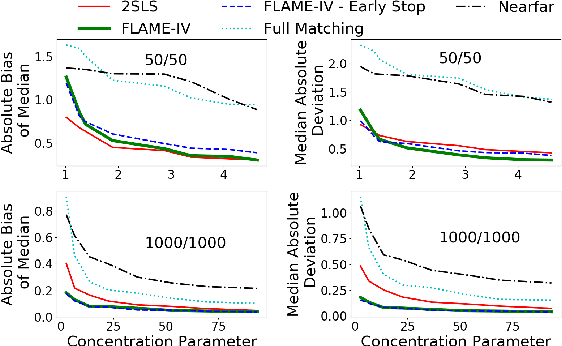
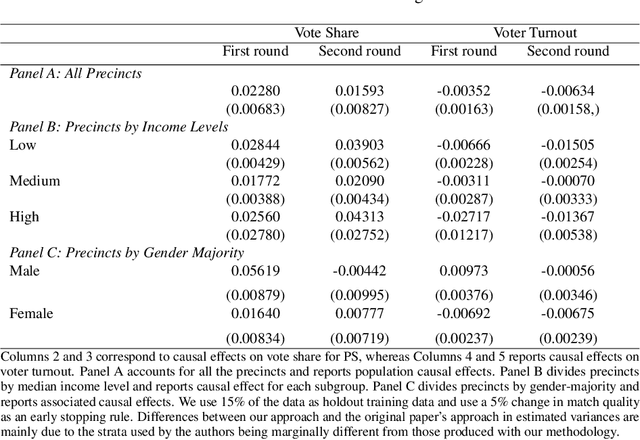
Uncertainty in the estimation of the causal effect in observational studies is often due to unmeasured confounding, i.e., the presence of unobserved covariates linking treatments and outcomes. Instrumental Variables (IV) are commonly used to reduce the effects of unmeasured confounding. Existing methods for IV estimation either require strong parametric assumptions, use arbitrary distance metrics, or do not scale well to large datasets. We propose a matching framework for IV in the presence of observed categorical confounders that addresses these weaknesses. Our method first matches units exactly, and then consecutively drops variables to approximately match the remaining units on as many variables as possible. We show that our algorithm constructs better matches than other existing methods on simulated datasets, and we produce interesting results in an application to political canvassing.