 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Sim-to-Real Gap & Think Like a Scientist
May 20, 2026Suppose a planner has a pre-trained simulator of a sequential decision problem and the option to run real experiments in the field. The simulator is cheap to query but inherits confounding and drift from its calibration data. Experimentation is unbiased but consumes one real unit per trial. We study when, and how, the planner should supplement the simulator with experiments. We give three results. First, an extended simulation lemma decomposes the simulator's value error into a calibration--deployment shift that randomization can identify and a parametric residual that no further interaction can reduce. Second, the value gap between the simulator-optimal policy and the optimum splits into a local component, on states the deployed policy already visits, and a reachability component, on states it does not. The reachability component stays bounded away from zero at any horizon under purely passive learning. Third, we propose Fisher-SEP, a simulation-aided experimental policy (SEP) that minimizes the posterior predictive variance of a target policy's value, with reward-only and transition-only specializations. Two case studies illustrate the regimes. In a vending-machine supply chain, front-loaded experimentation overtakes posterior updating once the horizon is long enough to amortize the pilot. In an HIV mobile-testing example with a corridor that separates a well-surveilled region from a poorly-surveilled one, only designed exploration reaches the poorly-surveilled region.
DARTS: Targeting Prognostic Covariates in Budget-Constrained Sequential Experiments
May 07, 2026Randomized controlled trials typically assume that prognostic covariates are known and available at no cost. In practice, obtaining high-dimensional pretreatment data is costly, forcing a trade-off between covariate-adaptive precision and a measurement budget. We introduce Dynamic Adaptive Rerandomization via Thompson Sampling (DARTS), which treats covariate acquisition as a sequential optimization problem embedded within a design-based causal inference task. A budgeted combinatorial Thompson sampler learns which covariates are most prognostic across successive batches; selected covariates then drive rerandomization and regression adjustment to reduce batch-level average treatment effect variance. Our primary theoretical contribution is a decoupling result: adaptive covariate selection based on past batches preserves batch-level randomization validity, and the cumulative inverse-variance weighted estimator achieves at least nominal asymptotic coverage. We further derive a Bayes risk bound for the acquisition layer that matches the minimax lower bound up to logarithmic factors. Empirically, DARTS systematically concentrates the budget on informative features, significantly closing the efficiency gap to oracle designs while maintaining strict inferential validity.
Data Fusion for Partial Identification of Causal Effects
May 30, 2025Data fusion techniques integrate information from heterogeneous data sources to improve learning, generalization, and decision making across data sciences. In causal inference, these methods leverage rich observational data to improve causal effect estimation, while maintaining the trustworthiness of randomized controlled trials. Existing approaches often relax the strong no unobserved confounding assumption by instead assuming exchangeability of counterfactual outcomes across data sources. However, when both assumptions simultaneously fail - a common scenario in practice - current methods cannot identify or estimate causal effects. We address this limitation by proposing a novel partial identification framework that enables researchers to answer key questions such as: Is the causal effect positive or negative? and How severe must assumption violations be to overturn this conclusion? Our approach introduces interpretable sensitivity parameters that quantify assumption violations and derives corresponding causal effect bounds. We develop doubly robust estimators for these bounds and operationalize breakdown frontier analysis to understand how causal conclusions change as assumption violations increase. We apply our framework to the Project STAR study, which investigates the effect of classroom size on students' third-grade standardized test performance. Our analysis reveals that the Project STAR results are robust to simultaneous violations of key assumptions, both on average and across various subgroups of interest. This strengthens confidence in the study's conclusions despite potential unmeasured biases in the data.
Scalable Policy Maximization Under Network Interference
May 23, 2025Many interventions, such as vaccines in clinical trials or coupons in online marketplaces, must be assigned sequentially without full knowledge of their effects. Multi-armed bandit algorithms have proven successful in such settings. However, standard independence assumptions fail when the treatment status of one individual impacts the outcomes of others, a phenomenon known as interference. We study optimal-policy learning under interference on a dynamic network. Existing approaches to this problem require repeated observations of the same fixed network and struggle to scale in sample size beyond as few as fifteen connected units -- both limit applications. We show that under common assumptions on the structure of interference, rewards become linear. This enables us to develop a scalable Thompson sampling algorithm that maximizes policy impact when a new $n$-node network is observed each round. We prove a Bayesian regret bound that is sublinear in $n$ and the number of rounds. Simulation experiments show that our algorithm learns quickly and outperforms existing methods. The results close a key scalability gap between causal inference methods for interference and practical bandit algorithms, enabling policy optimization in large-scale networked systems.
Interpretable Causal Inference for Analyzing Wearable, Sensor, and Distributional Data
Dec 17, 2023Many modern causal questions ask how treatments affect complex outcomes that are measured using wearable devices and sensors. Current analysis approaches require summarizing these data into scalar statistics (e.g., the mean), but these summaries can be misleading. For example, disparate distributions can have the same means, variances, and other statistics. Researchers can overcome the loss of information by instead representing the data as distributions. We develop an interpretable method for distributional data analysis that ensures trustworthy and robust decision-making: Analyzing Distributional Data via Matching After Learning to Stretch (ADD MALTS). We (i) provide analytical guarantees of the correctness of our estimation strategy, (ii) demonstrate via simulation that ADD MALTS outperforms other distributional data analysis methods at estimating treatment effects, and (iii) illustrate ADD MALTS' ability to verify whether there is enough cohesion between treatment and control units within subpopulations to trustworthily estimate treatment effects. We demonstrate ADD MALTS' utility by studying the effectiveness of continuous glucose monitors in mitigating diabetes risks.
Estimating Trustworthy and Safe Optimal Treatment Regimes
Oct 23, 2023



Recent statistical and reinforcement learning methods have significantly advanced patient care strategies. However, these approaches face substantial challenges in high-stakes contexts, including missing data, inherent stochasticity, and the critical requirements for interpretability and patient safety. Our work operationalizes a safe and interpretable framework to identify optimal treatment regimes. This approach involves matching patients with similar medical and pharmacological characteristics, allowing us to construct an optimal policy via interpolation. We perform a comprehensive simulation study to demonstrate the framework's ability to identify optimal policies even in complex settings. Ultimately, we operationalize our approach to study regimes for treating seizures in critically ill patients. Our findings strongly support personalized treatment strategies based on a patient's medical history and pharmacological features. Notably, we identify that reducing medication doses for patients with mild and brief seizure episodes while adopting aggressive treatment for patients in intensive care unit experiencing intense seizures leads to more favorable outcomes.
A Double Machine Learning Approach to Combining Experimental and Observational Data
Jul 04, 2023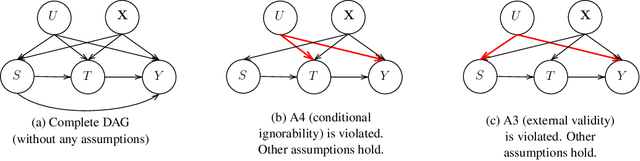

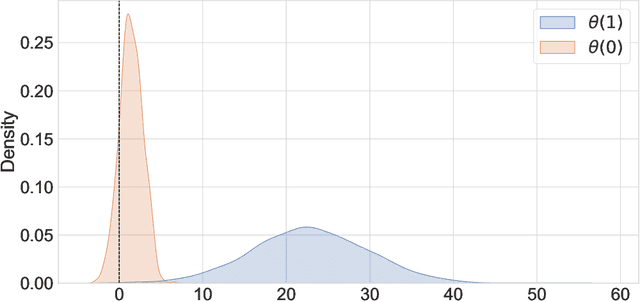
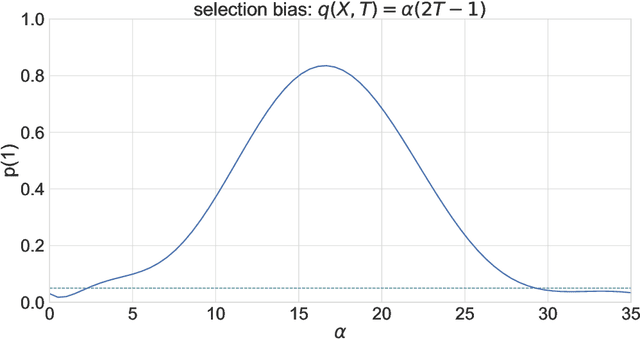
Experimental and observational studies often lack validity due to untestable assumptions. We propose a double machine learning approach to combine experimental and observational studies, allowing practitioners to test for assumption violations and estimate treatment effects consistently. Our framework tests for violations of external validity and ignorability under milder assumptions. When only one assumption is violated, we provide semi-parametrically efficient treatment effect estimators. However, our no-free-lunch theorem highlights the necessity of accurately identifying the violated assumption for consistent treatment effect estimation. We demonstrate the applicability of our approach in three real-world case studies, highlighting its relevance for practical settings.
Matched Machine Learning: A Generalized Framework for Treatment Effect Inference With Learned Metrics
Apr 03, 2023



We introduce Matched Machine Learning, a framework that combines the flexibility of machine learning black boxes with the interpretability of matching, a longstanding tool in observational causal inference. Interpretability is paramount in many high-stakes application of causal inference. Current tools for nonparametric estimation of both average and individualized treatment effects are black-boxes that do not allow for human auditing of estimates. Our framework uses machine learning to learn an optimal metric for matching units and estimating outcomes, thus achieving the performance of machine learning black-boxes, while being interpretable. Our general framework encompasses several published works as special cases. We provide asymptotic inference theory for our proposed framework, enabling users to construct approximate confidence intervals around estimates of both individualized and average treatment effects. We show empirically that instances of Matched Machine Learning perform on par with black-box machine learning methods and better than existing matching methods for similar problems. Finally, in our application we show how Matched Machine Learning can be used to perform causal inference even when covariate data are highly complex: we study an image dataset, and produce high quality matches and estimates of treatment effects.
From Feature Importance to Distance Metric: An Almost Exact Matching Approach for Causal Inference
Feb 23, 2023



Our goal is to produce methods for observational causal inference that are auditable, easy to troubleshoot, yield accurate treatment effect estimates, and scalable to high-dimensional data. We describe an almost-exact matching approach that achieves these goals by (i) learning a distance metric via outcome modeling, (ii) creating matched groups using the distance metric, and (iii) using the matched groups to estimate treatment effects. Our proposed method uses variable importance measurements to construct a distance metric, making it a flexible method that can be adapted to various applications. Concentrating on the scalability of the problem in the number of potential confounders, we operationalize our approach with LASSO. We derive performance guarantees for settings where LASSO outcome modeling consistently identifies all confounders (importantly without requiring the linear model to be correctly specified). We also provide experimental results demonstrating the auditability of matches, as well as extensions to more general nonparametric outcome modeling.
Neighborhood Adaptive Estimators for Causal Inference under Network Interference
Dec 07, 2022Estimating causal effects has become an integral part of most applied fields. Solving these modern causal questions requires tackling violations of many classical causal assumptions. In this work we consider the violation of the classical no-interference assumption, meaning that the treatment of one individuals might affect the outcomes of another. To make interference tractable, we consider a known network that describes how interference may travel. However, unlike previous work in this area, the radius (and intensity) of the interference experienced by a unit is unknown and can depend on different sub-networks of those treated and untreated that are connected to this unit. We study estimators for the average direct treatment effect on the treated in such a setting. The proposed estimator builds upon a Lepski-like procedure that searches over the possible relevant radii and treatment assignment patterns. In contrast to previous work, the proposed procedure aims to approximate the relevant network interference patterns. We establish oracle inequalities and corresponding adaptive rates for the estimation of the interference function. We leverage such estimates to propose and analyze two estimators for the average direct treatment effect on the treated. We address several challenges steaming from the data-driven creation of the patterns (i.e. feature engineering) and the network dependence. In addition to rates of convergence, under mild regularity conditions, we show that one of the proposed estimators is asymptotically normal and unbiased.