 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Controlled Training Data Generation with Diffusion Models
Mar 22, 2024
In this work, we present a method to control a text-to-image generative model to produce training data specifically "useful" for supervised learning. Unlike previous works that employ an open-loop approach and pre-define prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system which involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model and finds adversarial prompts that result in image generations that maximize the model loss. While these adversarial prompts result in diverse data informed by the model, they are not informed of the target distribution, which can be inefficient. Therefore, we introduce the second feedback mechanism that guides the generation process towards a certain target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. We perform our evaluations on different tasks, datasets and architectures, with different types of distribution shifts (spuriously correlated data, unseen domains) and demonstrate the efficiency of the proposed feedback mechanisms compared to open-loop approaches.
Spectrum Translation for Refinement of Image Generation (STIG) Based on Contrastive Learning and Spectral Filter Profile
Mar 08, 2024

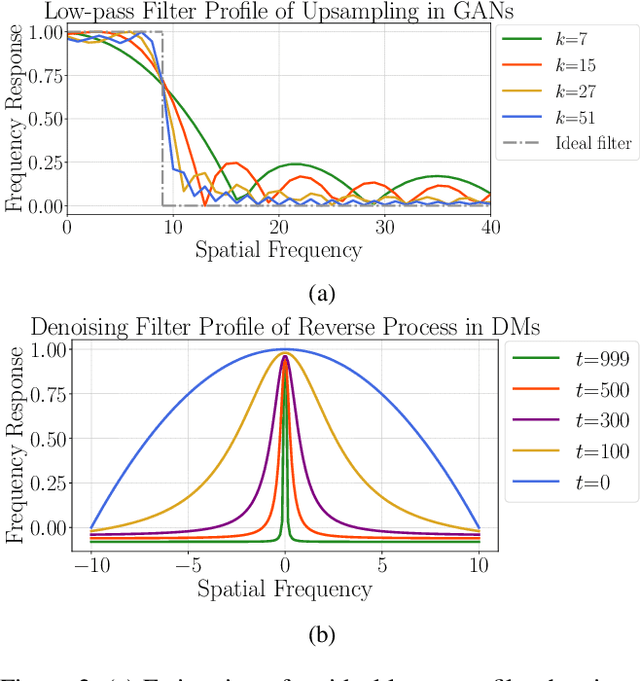

Currently, image generation and synthesis have remarkably progressed with generative models. Despite photo-realistic results, intrinsic discrepancies are still observed in the frequency domain. The spectral discrepancy appeared not only in generative adversarial networks but in diffusion models. In this study, we propose a framework to effectively mitigate the disparity in frequency domain of the generated images to improve generative performance of both GAN and diffusion models. This is realized by spectrum translation for the refinement of image generation (STIG) based on contrastive learning. We adopt theoretical logic of frequency components in various generative networks. The key idea, here, is to refine the spectrum of the generated image via the concept of image-to-image translation and contrastive learning in terms of digital signal processing. We evaluate our framework across eight fake image datasets and various cutting-edge models to demonstrate the effectiveness of STIG. Our framework outperforms other cutting-edges showing significant decreases in FID and log frequency distance of spectrum. We further emphasize that STIG improves image quality by decreasing the spectral anomaly. Additionally, validation results present that the frequency-based deepfake detector confuses more in the case where fake spectrums are manipulated by STIG.
D-Net: Dynamic Large Kernel with Dynamic Feature Fusion for Volumetric Medical Image Segmentation
Mar 15, 2024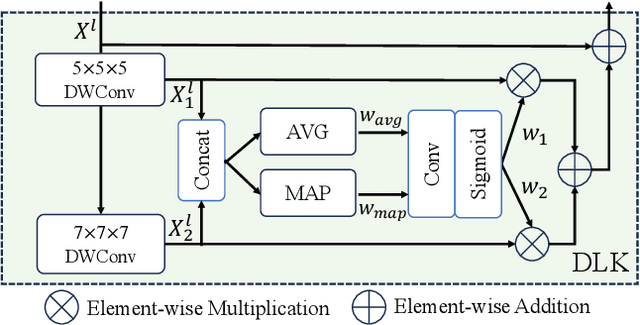
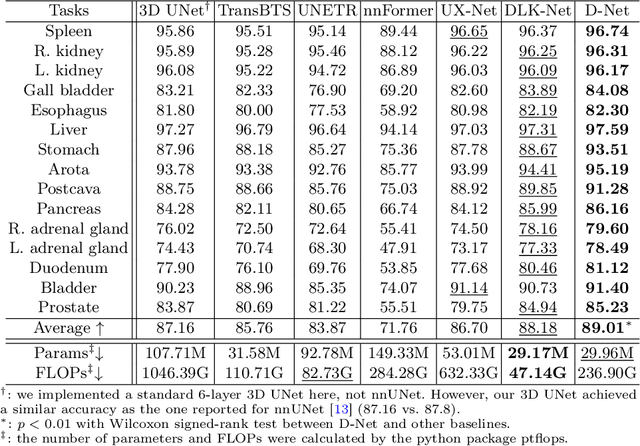
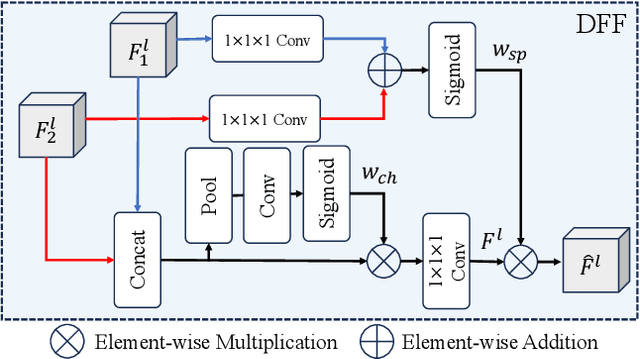
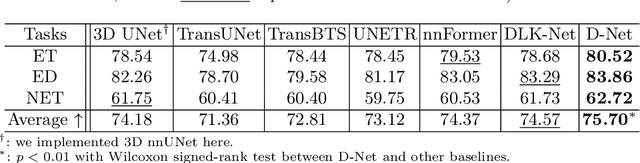
Hierarchical transformers have achieved significant success in medical image segmentation due to their large receptive field and capabilities of effectively leveraging global long-range contextual information. Convolutional neural networks (CNNs) can also deliver a large receptive field by using large kernels, enabling them to achieve competitive performance with fewer model parameters. However, CNNs incorporated with large convolutional kernels remain constrained in adaptively capturing multi-scale features from organs with large variations in shape and size due to the employment of fixed-sized kernels. Additionally, they are unable to utilize global contextual information efficiently. To address these limitations, we propose Dynamic Large Kernel (DLK) and Dynamic Feature Fusion (DFF) modules. The DLK module employs multiple large kernels with varying kernel sizes and dilation rates to capture multi-scale features. Subsequently, a dynamic selection mechanism is utilized to adaptively highlight the most important spatial features based on global information. Additionally, the DFF module is proposed to adaptively fuse multi-scale local feature maps based on their global information. We integrate DLK and DFF in a hierarchical transformer architecture to develop a novel architecture, termed D-Net. D-Net is able to effectively utilize a multi-scale large receptive field and adaptively harness global contextual information. Extensive experimental results demonstrate that D-Net outperforms other state-of-the-art models in the two volumetric segmentation tasks, including abdominal multi-organ segmentation and multi-modality brain tumor segmentation. Our code is available at https://github.com/sotiraslab/DLK.
MyVLM: Personalizing VLMs for User-Specific Queries
Mar 21, 2024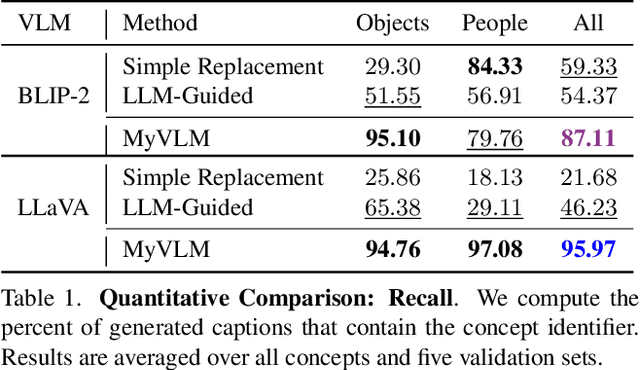
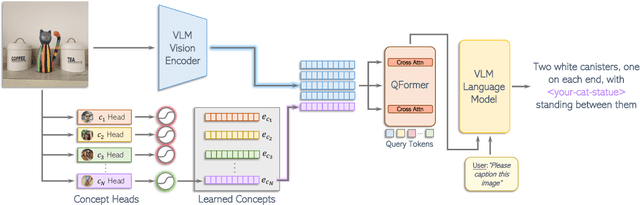
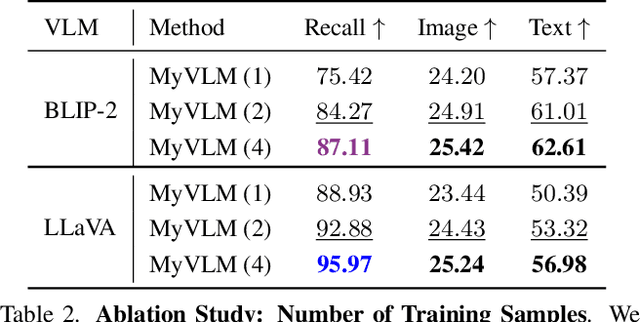

Recent large-scale vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and generating textual descriptions for visual content. However, these models lack an understanding of user-specific concepts. In this work, we take a first step toward the personalization of VLMs, enabling them to learn and reason over user-provided concepts. For example, we explore whether these models can learn to recognize you in an image and communicate what you are doing, tailoring the model to reflect your personal experiences and relationships. To effectively recognize a variety of user-specific concepts, we augment the VLM with external concept heads that function as toggles for the model, enabling the VLM to identify the presence of specific target concepts in a given image. Having recognized the concept, we learn a new concept embedding in the intermediate feature space of the VLM. This embedding is tasked with guiding the language model to naturally integrate the target concept in its generated response. We apply our technique to BLIP-2 and LLaVA for personalized image captioning and further show its applicability for personalized visual question-answering. Our experiments demonstrate our ability to generalize to unseen images of learned concepts while preserving the model behavior on unrelated inputs.
Estimating Physical Information Consistency of Channel Data Augmentation for Remote Sensing Images
Mar 21, 2024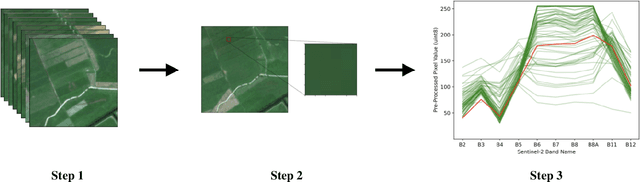
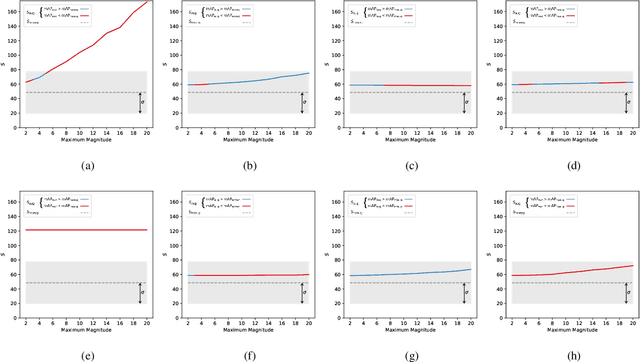
The application of data augmentation for deep learning (DL) methods plays an important role in achieving state-of-the-art results in supervised, semi-supervised, and self-supervised image classification. In particular, channel transformations (e.g., solarize, grayscale, brightness adjustments) are integrated into data augmentation pipelines for remote sensing (RS) image classification tasks. However, contradicting beliefs exist about their proper applications to RS images. A common point of critique is that the application of channel augmentation techniques may lead to physically inconsistent spectral data (i.e., pixel signatures). To shed light on the open debate, we propose an approach to estimate whether a channel augmentation technique affects the physical information of RS images. To this end, the proposed approach estimates a score that measures the alignment of a pixel signature within a time series that can be naturally subject to deviations caused by factors such as acquisition conditions or phenological states of vegetation. We compare the scores associated with original and augmented pixel signatures to evaluate the physical consistency. Experimental results on a multi-label image classification task show that channel augmentations yielding a score that exceeds the expected deviation of original pixel signatures can not improve the performance of a baseline model trained without augmentation.
Analysing Diffusion Segmentation for Medical Images
Mar 21, 2024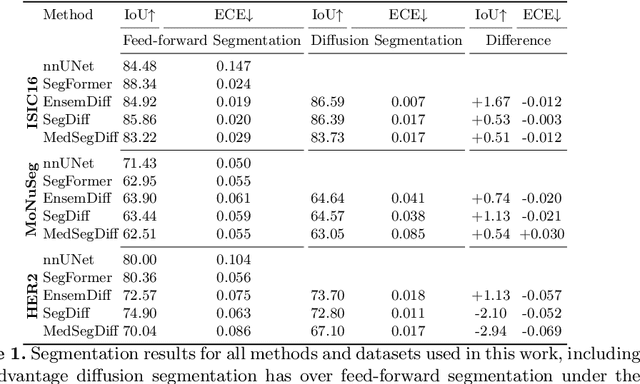
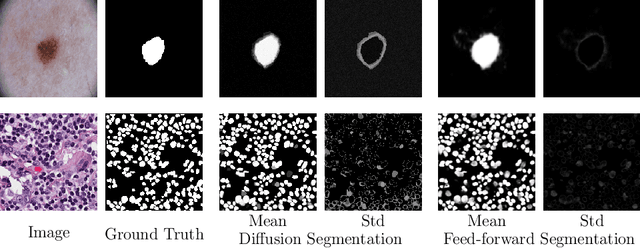
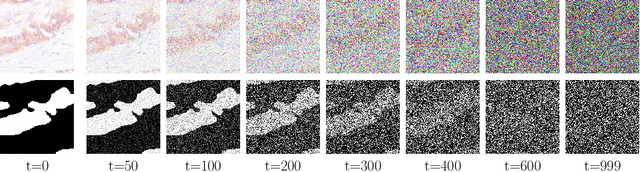
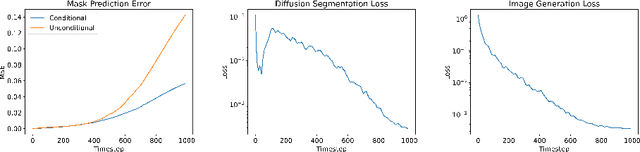
Denoising Diffusion Probabilistic models have become increasingly popular due to their ability to offer probabilistic modeling and generate diverse outputs. This versatility inspired their adaptation for image segmentation, where multiple predictions of the model can produce segmentation results that not only achieve high quality but also capture the uncertainty inherent in the model. Here, powerful architectures were proposed for improving diffusion segmentation performance. However, there is a notable lack of analysis and discussions on the differences between diffusion segmentation and image generation, and thorough evaluations are missing that distinguish the improvements these architectures provide for segmentation in general from their benefit for diffusion segmentation specifically. In this work, we critically analyse and discuss how diffusion segmentation for medical images differs from diffusion image generation, with a particular focus on the training behavior. Furthermore, we conduct an assessment how proposed diffusion segmentation architectures perform when trained directly for segmentation. Lastly, we explore how different medical segmentation tasks influence the diffusion segmentation behavior and the diffusion process could be adapted accordingly. With these analyses, we aim to provide in-depth insights into the behavior of diffusion segmentation that allow for a better design and evaluation of diffusion segmentation methods in the future.
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
Mar 11, 2024
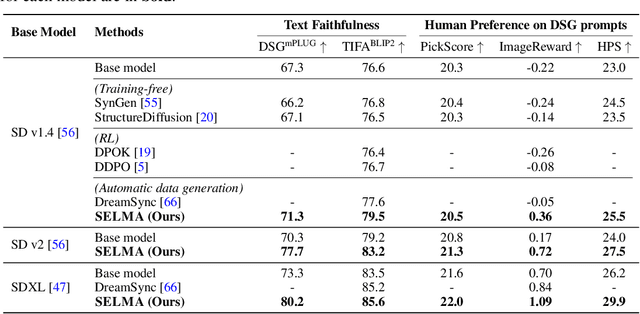
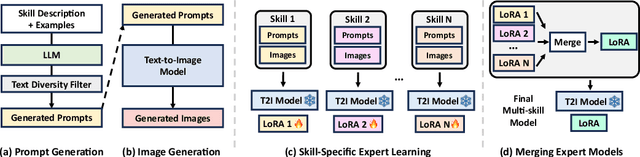
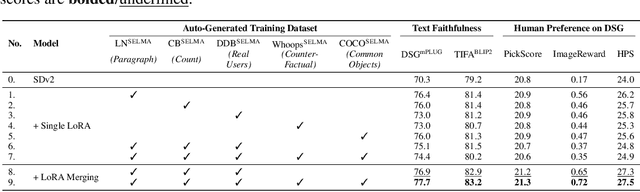
Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fall short of generating images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM's in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models.
An Item is Worth a Prompt: Versatile Image Editing with Disentangled Control
Mar 07, 2024Building on the success of text-to-image diffusion models (DPMs), image editing is an important application to enable human interaction with AI-generated content. Among various editing methods, editing within the prompt space gains more attention due to its capacity and simplicity of controlling semantics. However, since diffusion models are commonly pretrained on descriptive text captions, direct editing of words in text prompts usually leads to completely different generated images, violating the requirements for image editing. On the other hand, existing editing methods usually consider introducing spatial masks to preserve the identity of unedited regions, which are usually ignored by DPMs and therefore lead to inharmonic editing results. Targeting these two challenges, in this work, we propose to disentangle the comprehensive image-prompt interaction into several item-prompt interactions, with each item linked to a special learned prompt. The resulting framework, named D-Edit, is based on pretrained diffusion models with cross-attention layers disentangled and adopts a two-step optimization to build item-prompt associations. Versatile image editing can then be applied to specific items by manipulating the corresponding prompts. We demonstrate state-of-the-art results in four types of editing operations including image-based, text-based, mask-based editing, and item removal, covering most types of editing applications, all within a single unified framework. Notably, D-Edit is the first framework that can (1) achieve item editing through mask editing and (2) combine image and text-based editing. We demonstrate the quality and versatility of the editing results for a diverse collection of images through both qualitative and quantitative evaluations.
DDF: A Novel Dual-Domain Image Fusion Strategy for Remote Sensing Image Semantic Segmentation with Unsupervised Domain Adaptation
Mar 05, 2024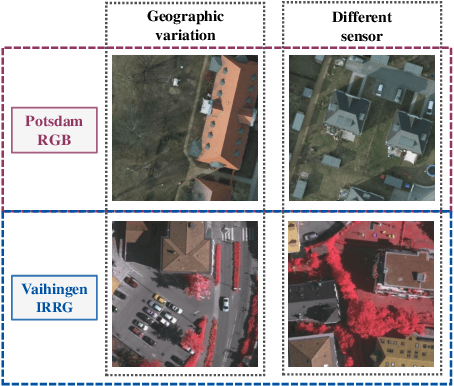
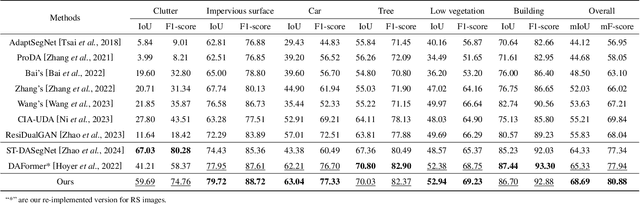
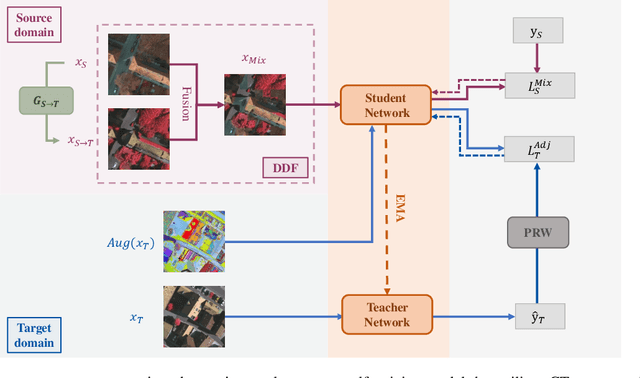
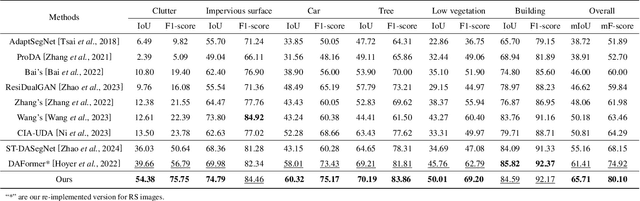
Semantic segmentation of remote sensing images is a challenging and hot issue due to the large amount of unlabeled data. Unsupervised domain adaptation (UDA) has proven to be advantageous in incorporating unclassified information from the target domain. However, independently fine-tuning UDA models on the source and target domains has a limited effect on the outcome. This paper proposes a hybrid training strategy as well as a novel dual-domain image fusion strategy that effectively utilizes the original image, transformation image, and intermediate domain information. Moreover, to enhance the precision of pseudo-labels, we present a pseudo-label region-specific weight strategy. The efficacy of our approach is substantiated by extensive benchmark experiments and ablation studies conducted on the ISPRS Vaihingen and Potsdam datasets.
CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
Mar 08, 2024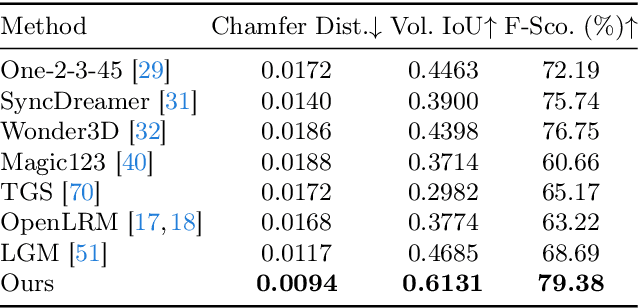
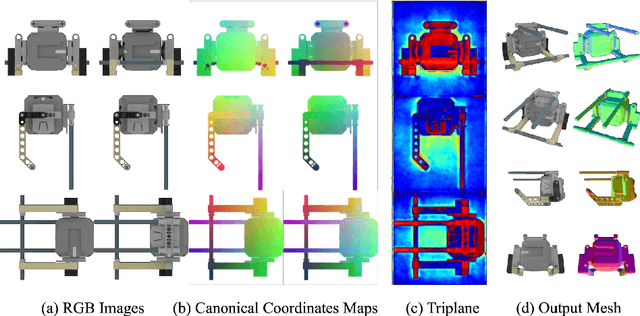
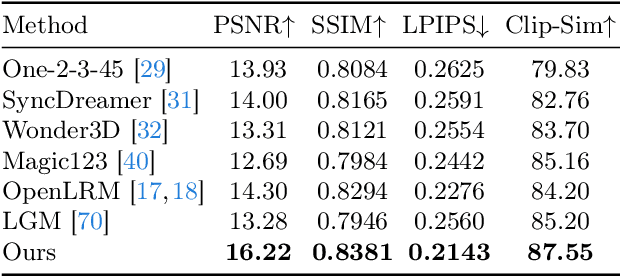
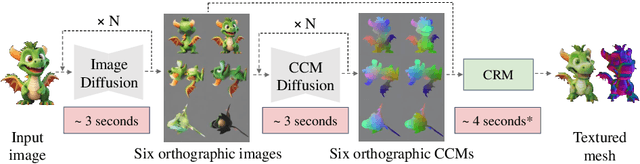
Feed-forward 3D generative models like the Large Reconstruction Model (LRM) have demonstrated exceptional generation speed. However, the transformer-based methods do not leverage the geometric priors of the triplane component in their architecture, often leading to sub-optimal quality given the limited size of 3D data and slow training. In this work, we present the Convolutional Reconstruction Model (CRM), a high-fidelity feed-forward single image-to-3D generative model. Recognizing the limitations posed by sparse 3D data, we highlight the necessity of integrating geometric priors into network design. CRM builds on the key observation that the visualization of triplane exhibits spatial correspondence of six orthographic images. First, it generates six orthographic view images from a single input image, then feeds these images into a convolutional U-Net, leveraging its strong pixel-level alignment capabilities and significant bandwidth to create a high-resolution triplane. CRM further employs Flexicubes as geometric representation, facilitating direct end-to-end optimization on textured meshes. Overall, our model delivers a high-fidelity textured mesh from an image in just 10 seconds, without any test-time optimization.