 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Simple, Effective and General: A New Backbone for Cross-view Image Geo-localization
Feb 03, 2023
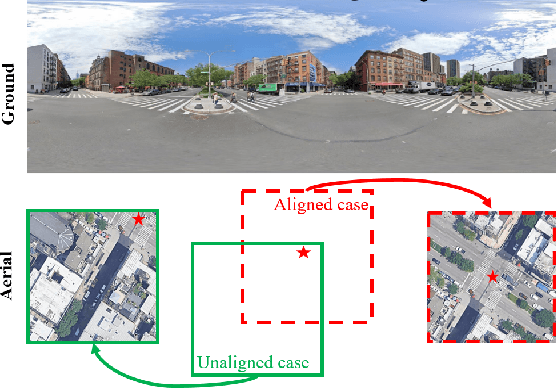
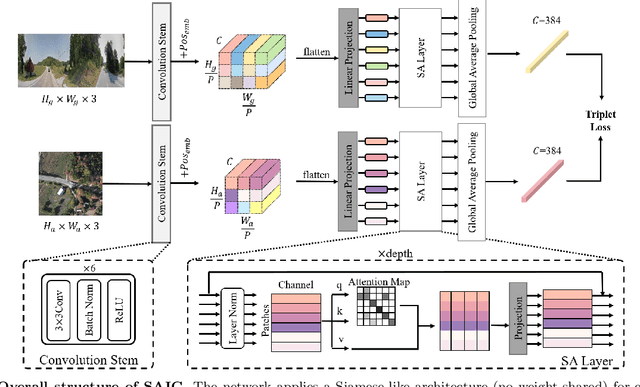
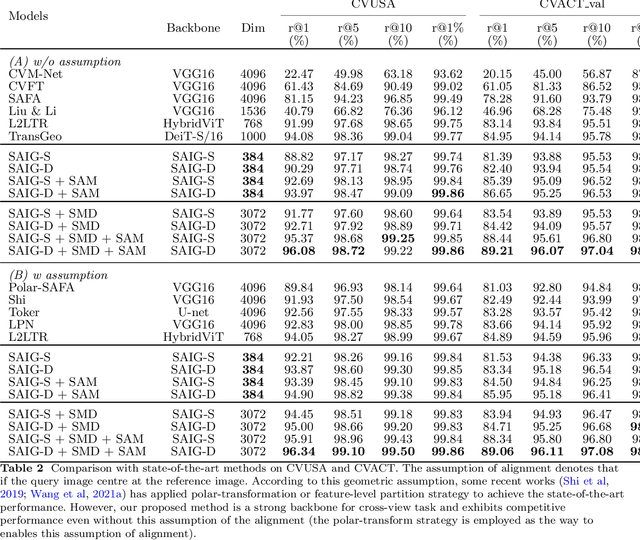
In this work, we aim at an important but less explored problem of a simple yet effective backbone specific for cross-view geo-localization task. Existing methods for cross-view geo-localization tasks are frequently characterized by 1) complicated methodologies, 2) GPU-consuming computations, and 3) a stringent assumption that aerial and ground images are centrally or orientation aligned. To address the above three challenges for cross-view image matching, we propose a new backbone network, named Simple Attention-based Image Geo-localization network (SAIG). The proposed SAIG effectively represents long-range interactions among patches as well as cross-view correspondence with multi-head self-attention layers. The "narrow-deep" architecture of our SAIG improves the feature richness without degradation in performance, while its shallow and effective convolutional stem preserves the locality, eliminating the loss of patchify boundary information. Our SAIG achieves state-of-the-art results on cross-view geo-localization, while being far simpler than previous works. Furthermore, with only 15.9% of the model parameters and half of the output dimension compared to the state-of-the-art, the SAIG adapts well across multiple cross-view datasets without employing any well-designed feature aggregation modules or feature alignment algorithms. In addition, our SAIG attains competitive scores on image retrieval benchmarks, further demonstrating its generalizability. As a backbone network, our SAIG is both easy to follow and computationally lightweight, which is meaningful in practical scenario. Moreover, we propose a simple Spatial-Mixed feature aggregation moDule (SMD) that can mix and project spatial information into a low-dimensional space to generate feature descriptors... (The code is available at https://github.com/yanghongji2007/SAIG)
The Image of the Process Interpretation of Regular Expressions is Not Closed under Bisimulation Collapse
Mar 15, 2023Axiomatization and expressibility problems for Milner's process semantics (1984) of regular expressions modulo bisimilarity have turned out to be difficult for the full class of expressions with deadlock 0 and empty step~1. We report on a phenomenon that arises from the added presence of 1 when 0 is available, and that brings a crucial reason for this difficulty into focus. To wit, while interpretations of 1-free regular expressions are closed under bisimulation collapse, this is not the case for the interpretations of arbitrary regular expressions. Process graph interpretations of 1-free regular expressions satisfy the loop existence and elimination property LEE, which is preserved under bisimulation collapse. These features of LEE were applied for showing that an equational proof system for 1-free regular expressions modulo bisimilarity is complete, and that it is decidable in polynomial time whether a process graph is bisimilar to the interpretation of a 1-free regular expression. While interpretations of regular expressions do not satisfy the property LEE in general, we show that LEE can be recovered by refined interpretations as graphs with 1-transitions refined interpretations with 1-transitions (which are similar to silent steps for automata). This suggests that LEE can be expedient also for the general axiomatization and expressibility problems. But a new phenomenon emerges that needs to be addressed: the property of a process graph `to can be refined into a process graph with 1-transitions and with LEE' is not preserved under bisimulation collapse. We provide a 10-vertex graph with two 1-transitions that satisfies LEE, and in which a pair of bisimilar vertices cannot be collapsed on to each other while preserving the refinement property. This implies that the image of the process interpretation of regular expressions is not closed under bisimulation collapse.
Learning Monocular Depth in Dynamic Environment via Context-aware Temporal Attention
May 12, 2023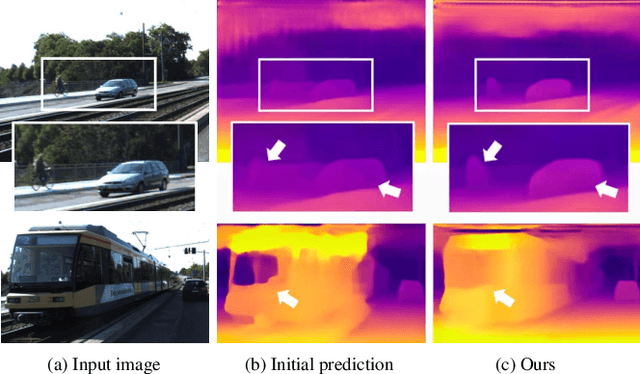

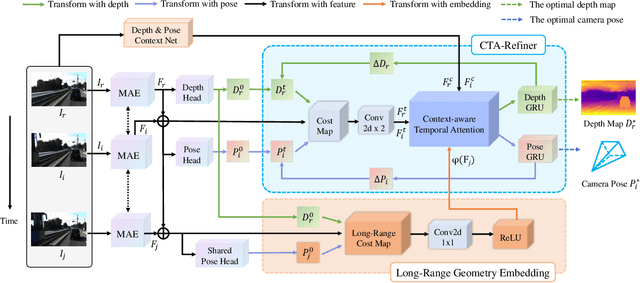
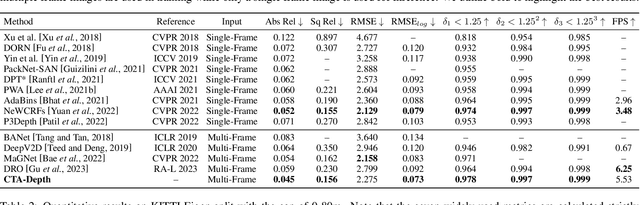
The monocular depth estimation task has recently revealed encouraging prospects, especially for the autonomous driving task. To tackle the ill-posed problem of 3D geometric reasoning from 2D monocular images, multi-frame monocular methods are developed to leverage the perspective correlation information from sequential temporal frames. However, moving objects such as cars and trains usually violate the static scene assumption, leading to feature inconsistency deviation and misaligned cost values, which would mislead the optimization algorithm. In this work, we present CTA-Depth, a Context-aware Temporal Attention guided network for multi-frame monocular Depth estimation. Specifically, we first apply a multi-level attention enhancement module to integrate multi-level image features to obtain an initial depth and pose estimation. Then the proposed CTA-Refiner is adopted to alternatively optimize the depth and pose. During the refinement process, context-aware temporal attention (CTA) is developed to capture the global temporal-context correlations to maintain the feature consistency and estimation integrity of moving objects. In particular, we propose a long-range geometry embedding (LGE) module to produce a long-range temporal geometry prior. Our approach achieves significant improvements over state-of-the-art approaches on three benchmark datasets.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
Apr 27, 2023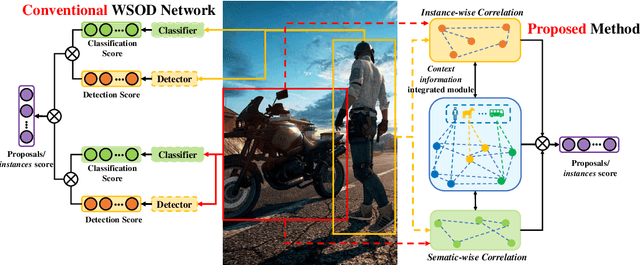
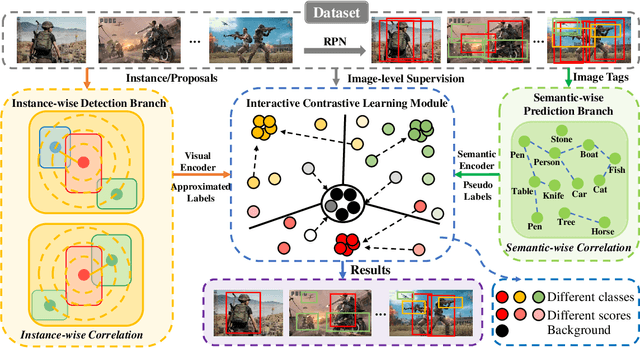
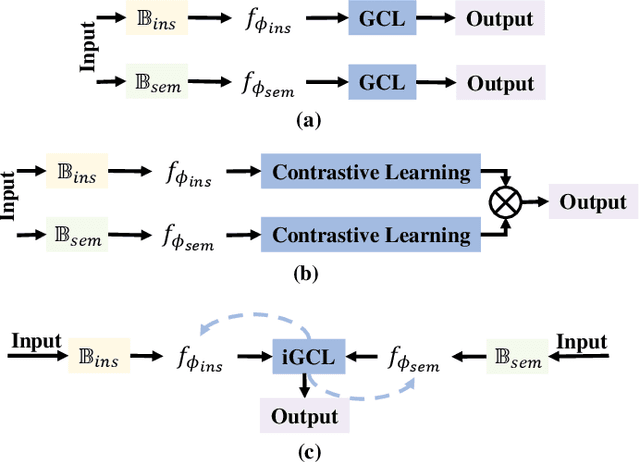

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
Self-Supervised Learning from Non-Object Centric Images with a Geometric Transformation Sensitive Architecture
Apr 27, 2023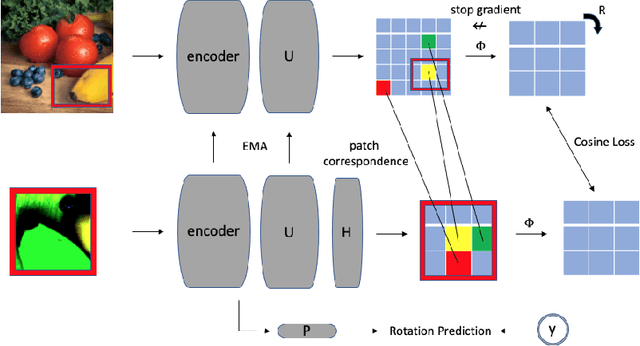
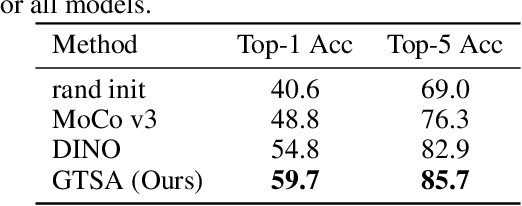
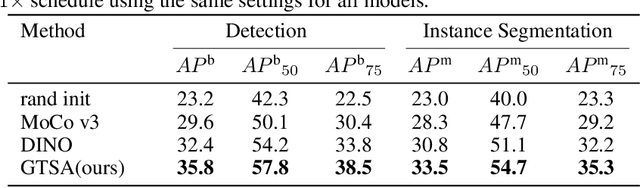
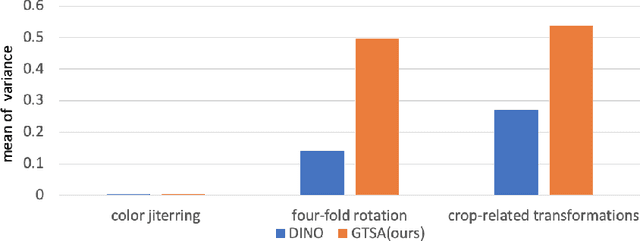
Most invariance-based self-supervised methods rely on single object-centric images (e.g., ImageNet images) for pretraining, learning invariant representations from geometric transformations. However, when images are not object-centric, the semantics of the image can be significantly altered due to cropping. Furthermore, as the model learns geometrically insensitive features, it may struggle to capture location information. For this reason, we propose a Geometric Transformation Sensitive Architecture that learns features sensitive to geometric transformations, specifically four-fold rotation, random crop, and multi-crop. Our method encourages the student to learn sensitive features by using targets that are sensitive to those transforms via pooling and rotating of the teacher feature map and predicting rotation. Additionally, since training insensitively to multi-crop can capture long-term dependencies, we use patch correspondence loss to train the model sensitively while capturing long-term dependencies. Our approach demonstrates improved performance when using non-object-centric images as pretraining data compared to other methods that learn geometric transformation-insensitive representations. We surpass the DINO[\citet{caron2021emerging}] baseline in tasks including image classification, semantic segmentation, detection, and instance segmentation with improvements of 6.1 $Acc$, 3.3 $mIoU$, 3.4 $AP^b$, and 2.7 $AP^m$. Code and pretrained models are publicly available at:
OrthoGAN:High-Precision Image Generation for Teeth Orthodontic Visualization
Dec 29, 2022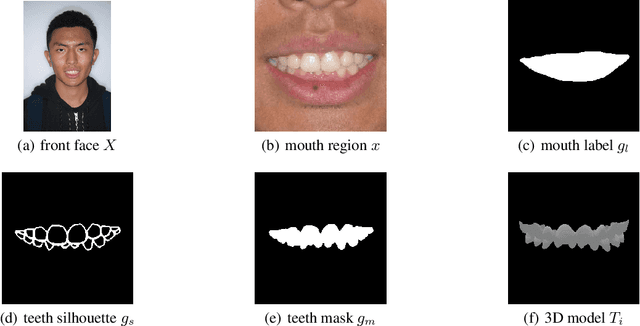
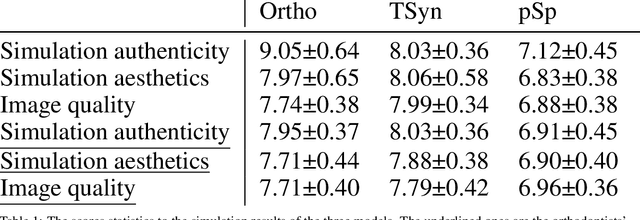
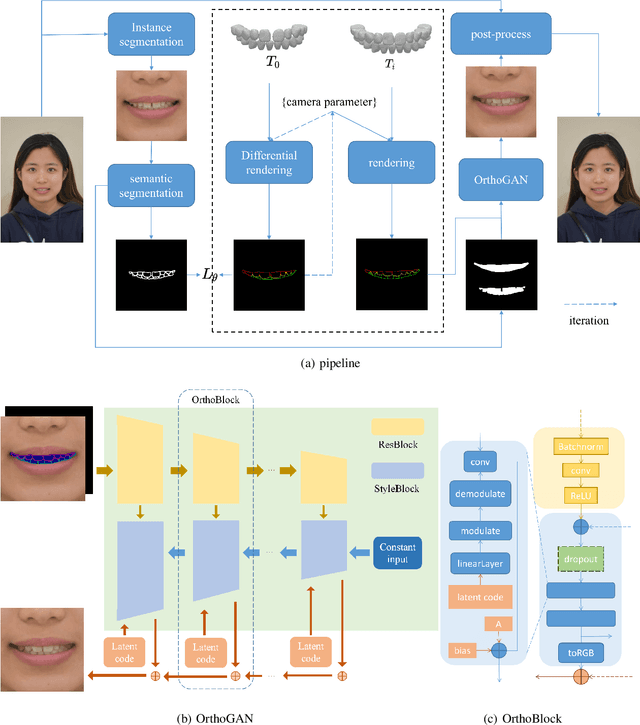
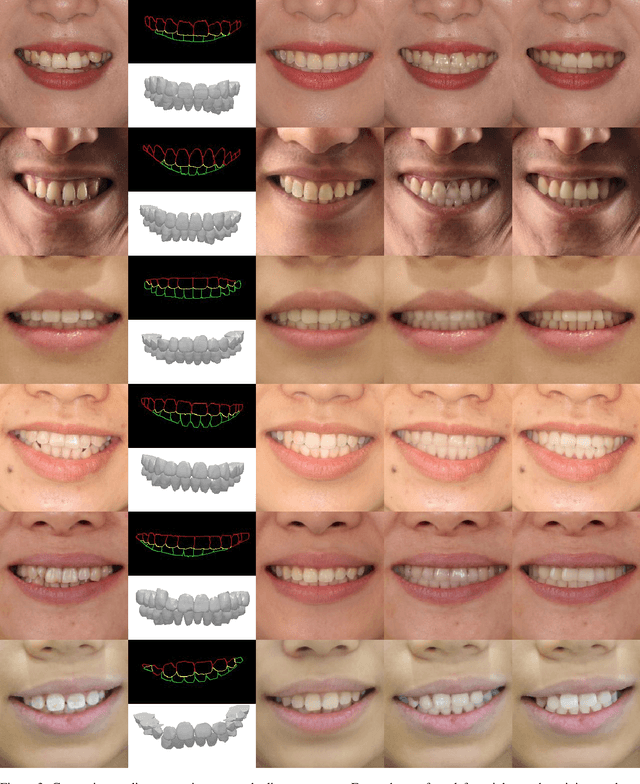
Patients take care of what their teeth will be like after the orthodontics. Orthodontists usually describe the expectation movement based on the original smile images, which is unconvincing. The growth of deep-learning generative models change this situation. It can visualize the outcome of orthodontic treatment and help patients foresee their future teeth and facial appearance. While previous studies mainly focus on 2D or 3D virtual treatment outcome (VTO) at a profile level, the problem of simulating treatment outcome at a frontal facial image is poorly explored. In this paper, we build an efficient and accurate system for simulating virtual teeth alignment effects in a frontal facial image. Our system takes a frontal face image of a patient with visible malpositioned teeth and the patient's 3D scanned teeth model as input, and progressively generates the visual results of the patient's teeth given the specific orthodontics planning steps from the doctor (i.e., the specification of translations and rotations of individual tooth). We design a multi-modal encoder-decoder based generative model to synthesize identity-preserving frontal facial images with aligned teeth. In addition, the original image color information is used to optimize the orthodontic outcomes, making the results more natural. We conduct extensive qualitative and clinical experiments and also a pilot study to validate our method.
DETR with Additional Global Aggregation for Cross-domain Weakly Supervised Object Detection
Apr 14, 2023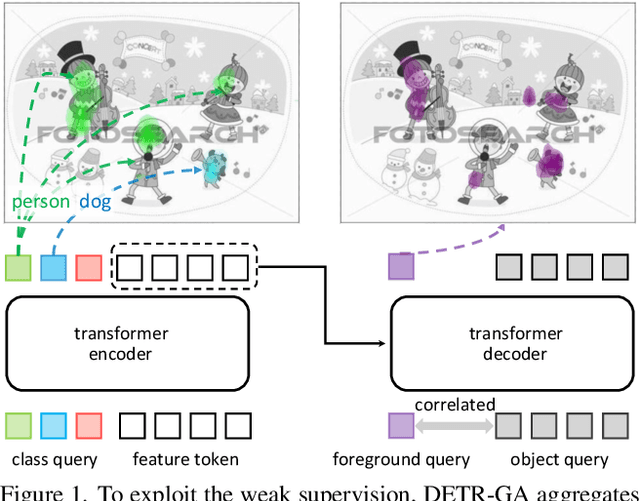
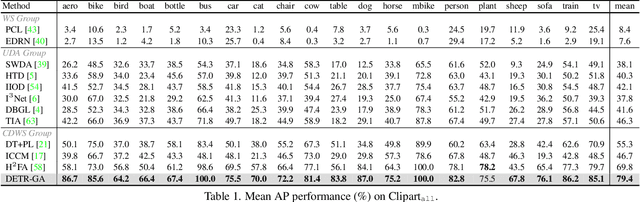
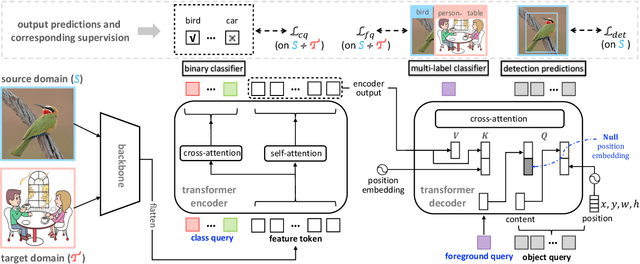
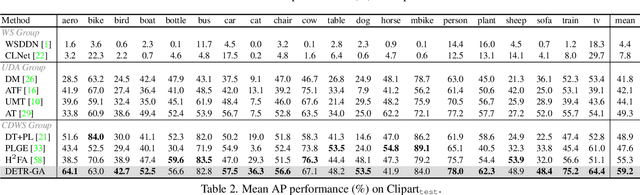
This paper presents a DETR-based method for cross-domain weakly supervised object detection (CDWSOD), aiming at adapting the detector from source to target domain through weak supervision. We think DETR has strong potential for CDWSOD due to an insight: the encoder and the decoder in DETR are both based on the attention mechanism and are thus capable of aggregating semantics across the entire image. The aggregation results, i.e., image-level predictions, can naturally exploit the weak supervision for domain alignment. Such motivated, we propose DETR with additional Global Aggregation (DETR-GA), a CDWSOD detector that simultaneously makes "instance-level + image-level" predictions and utilizes "strong + weak" supervisions. The key point of DETR-GA is very simple: for the encoder / decoder, we respectively add multiple class queries / a foreground query to aggregate the semantics into image-level predictions. Our query-based aggregation has two advantages. First, in the encoder, the weakly-supervised class queries are capable of roughly locating the corresponding positions and excluding the distraction from non-relevant regions. Second, through our design, the object queries and the foreground query in the decoder share consensus on the class semantics, therefore making the strong and weak supervision mutually benefit each other for domain alignment. Extensive experiments on four popular cross-domain benchmarks show that DETR-GA significantly improves CSWSOD and advances the states of the art (e.g., 29.0% --> 79.4% mAP on PASCAL VOC --> Clipart_all dataset).
Ship-D: Ship Hull Dataset for Design Optimization using Machine Learning
May 16, 2023


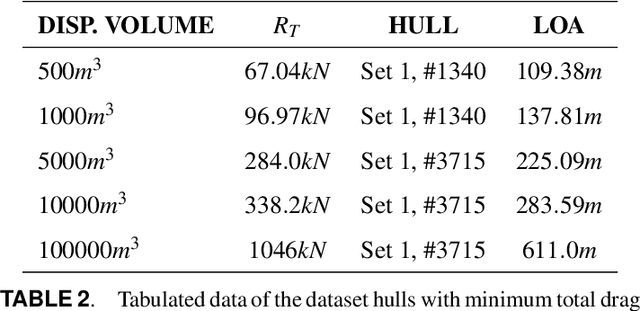
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, tradeoffs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of thirty thousand ship hulls, each with design and functional performance information, including parameterization, mesh, point cloud, and image representations, as well as thirty two hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of twelve ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the thirty two wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by sixty percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data driven ship design.
Structure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022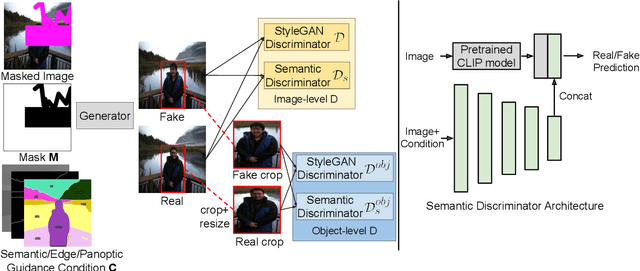
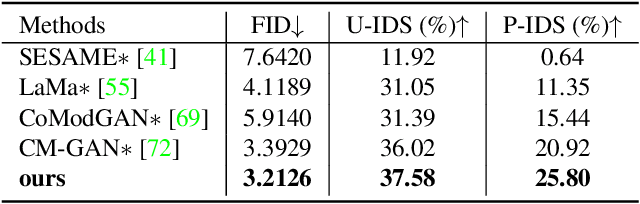


Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
BiTrackGAN: Cascaded CycleGANs to Constraint Face Aging
Apr 22, 2023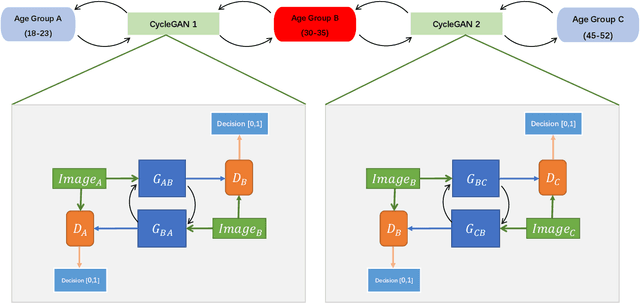


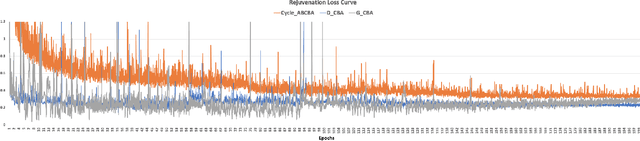
With the increased accuracy of modern computer vision technology, many access control systems are equipped with face recognition functions for faster identification. In order to maintain high recognition accuracy, it is necessary to keep the face database up-to-date. However, it is impractical to collect the latest facial picture of the system's user through human effort. Thus, we propose a bottom-up training method for our proposed network to address this challenge. Essentially, our proposed network is a translation pipeline that cascades two CycleGAN blocks (a widely used unpaired image-to-image translation generative adversarial network) called BiTrackGAN. By bottom-up training, it induces an ideal intermediate state between these two CycleGAN blocks, namely the constraint mechanism. Experimental results show that BiTrackGAN achieves more reasonable and diverse cross-age facial synthesis than other CycleGAN-related methods. As far as we know, it is a novel and effective constraint mechanism for more reason and accurate aging synthesis through the CycleGAN approach.