 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrune and Repaint: Content-Aware Image Retargeting for any Ratio
Oct 30, 2024



Image retargeting is the task of adjusting the aspect ratio of images to suit different display devices or presentation environments. However, existing retargeting methods often struggle to balance the preservation of key semantics and image quality, resulting in either deformation or loss of important objects, or the introduction of local artifacts such as discontinuous pixels and inconsistent regenerated content. To address these issues, we propose a content-aware retargeting method called PruneRepaint. It incorporates semantic importance for each pixel to guide the identification of regions that need to be pruned or preserved in order to maintain key semantics. Additionally, we introduce an adaptive repainting module that selects image regions for repainting based on the distribution of pruned pixels and the proportion between foreground size and target aspect ratio, thus achieving local smoothness after pruning. By focusing on the content and structure of the foreground, our PruneRepaint approach adaptively avoids key content loss and deformation, while effectively mitigating artifacts with local repainting. We conduct experiments on the public RetargetMe benchmark and demonstrate through objective experimental results and subjective user studies that our method outperforms previous approaches in terms of preserving semantics and aesthetics, as well as better generalization across diverse aspect ratios. Codes will be available at https://github.com/fhshen2022/PruneRepaint.
EventAug: Multifaceted Spatio-Temporal Data Augmentation Methods for Event-based Learning
Sep 18, 2024



The event camera has demonstrated significant success across a wide range of areas due to its low time latency and high dynamic range. However, the community faces challenges such as data deficiency and limited diversity, often resulting in over-fitting and inadequate feature learning. Notably, the exploration of data augmentation techniques in the event community remains scarce. This work aims to address this gap by introducing a systematic augmentation scheme named EventAug to enrich spatial-temporal diversity. In particular, we first propose Multi-scale Temporal Integration (MSTI) to diversify the motion speed of objects, then introduce Spatial-salient Event Mask (SSEM) and Temporal-salient Event Mask (TSEM) to enrich object variants. Our EventAug can facilitate models learning with richer motion patterns, object variants and local spatio-temporal relations, thus improving model robustness to varied moving speeds, occlusions, and action disruptions. Experiment results show that our augmentation method consistently yields significant improvements across different tasks and backbones (e.g., a 4.87% accuracy gain on DVS128 Gesture). Our code will be publicly available for this community.
YOLOrtho -- A Unified Framework for Teeth Enumeration and Dental Disease Detection
Aug 11, 2023


Detecting dental diseases through panoramic X-rays images is a standard procedure for dentists. Normally, a dentist need to identify diseases and find the infected teeth. While numerous machine learning models adopting this two-step procedure have been developed, there has not been an end-to-end model that can identify teeth and their associated diseases at the same time. To fill the gap, we develop YOLOrtho, a unified framework for teeth enumeration and dental disease detection. We develop our model on Dentex Challenge 2023 data, which consists of three distinct types of annotated data. The first part is labeled with quadrant, and the second part is labeled with quadrant and enumeration and the third part is labeled with quadrant, enumeration and disease. To further improve detection, we make use of Tufts Dental public dataset. To fully utilize the data and learn both teeth detection and disease identification simultaneously, we formulate diseases as attributes attached to their corresponding teeth. Due to the nature of position relation in teeth enumeration, We replace convolution layer with CoordConv in our model to provide more position information for the model. We also adjust the model architecture and insert one more upsampling layer in FPN in favor of large object detection. Finally, we propose a post-process strategy for teeth layout that corrects teeth enumeration based on linear sum assignment. Results from experiments show that our model exceeds large Diffusion-based model.
Hierarchical Cross-modal Transformer for RGB-D Salient Object Detection
Feb 16, 2023

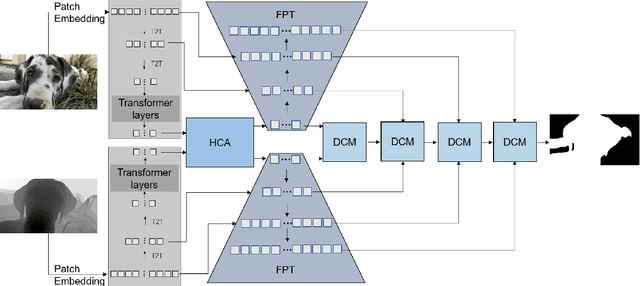
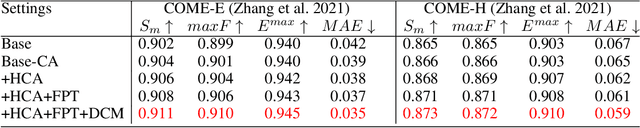
Most of existing RGB-D salient object detection (SOD) methods follow the CNN-based paradigm, which is unable to model long-range dependencies across space and modalities due to the natural locality of CNNs. Here we propose the Hierarchical Cross-modal Transformer (HCT), a new multi-modal transformer, to tackle this problem. Unlike previous multi-modal transformers that directly connecting all patches from two modalities, we explore the cross-modal complementarity hierarchically to respect the modality gap and spatial discrepancy in unaligned regions. Specifically, we propose to use intra-modal self-attention to explore complementary global contexts, and measure spatial-aligned inter-modal attention locally to capture cross-modal correlations. In addition, we present a Feature Pyramid module for Transformer (FPT) to boost informative cross-scale integration as well as a consistency-complementarity module to disentangle the multi-modal integration path and improve the fusion adaptivity. Comprehensive experiments on a large variety of public datasets verify the efficacy of our designs and the consistent improvement over state-of-the-art models.
OrthoGAN:High-Precision Image Generation for Teeth Orthodontic Visualization
Dec 29, 2022



Patients take care of what their teeth will be like after the orthodontics. Orthodontists usually describe the expectation movement based on the original smile images, which is unconvincing. The growth of deep-learning generative models change this situation. It can visualize the outcome of orthodontic treatment and help patients foresee their future teeth and facial appearance. While previous studies mainly focus on 2D or 3D virtual treatment outcome (VTO) at a profile level, the problem of simulating treatment outcome at a frontal facial image is poorly explored. In this paper, we build an efficient and accurate system for simulating virtual teeth alignment effects in a frontal facial image. Our system takes a frontal face image of a patient with visible malpositioned teeth and the patient's 3D scanned teeth model as input, and progressively generates the visual results of the patient's teeth given the specific orthodontics planning steps from the doctor (i.e., the specification of translations and rotations of individual tooth). We design a multi-modal encoder-decoder based generative model to synthesize identity-preserving frontal facial images with aligned teeth. In addition, the original image color information is used to optimize the orthodontic outcomes, making the results more natural. We conduct extensive qualitative and clinical experiments and also a pilot study to validate our method.
QFCNN: Quantum Fourier Convolutional Neural Network
Jun 19, 2021
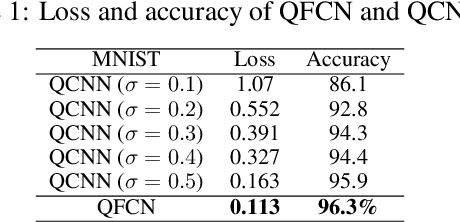
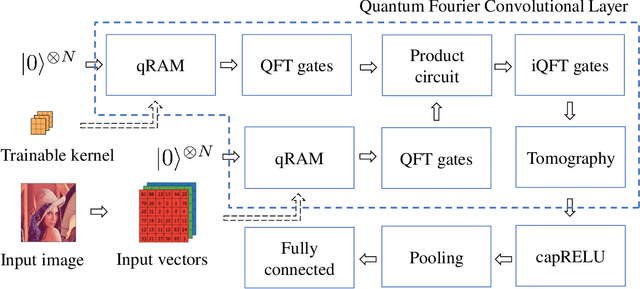
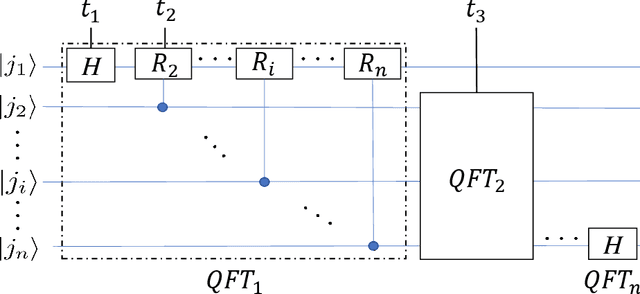
The neural network and quantum computing are both significant and appealing fields, with their interactive disciplines promising for large-scale computing tasks that are untackled by conventional computers. However, both developments are restricted by the scope of the hardware development. Nevertheless, many neural network algorithms had been proposed before GPUs become powerful enough for running very deep models. Similarly, quantum algorithms can also be proposed as knowledge reserves before real quantum computers are easily accessible. Specifically, taking advantage of both the neural networks and quantum computation and designing quantum deep neural networks (QDNNs) for acceleration on Noisy Intermediate-Scale Quantum (NISQ) processors is also an important research problem. As one of the most widely used neural network architectures, convolutional neural network (CNN) remains to be accelerated by quantum mechanisms, with only a few attempts have been demonstrated. In this paper, we propose a new hybrid quantum-classical circuit, namely Quantum Fourier Convolutional Network (QFCN). Our model achieves exponential speed-up compared with classical CNN theoretically and improves over the existing best result of quantum CNN. We demonstrate the potential of this architecture by applying it to different deep learning tasks, including traffic prediction and image classification.
Conterfactual Generative Zero-Shot Semantic Segmentation
Jun 11, 2021
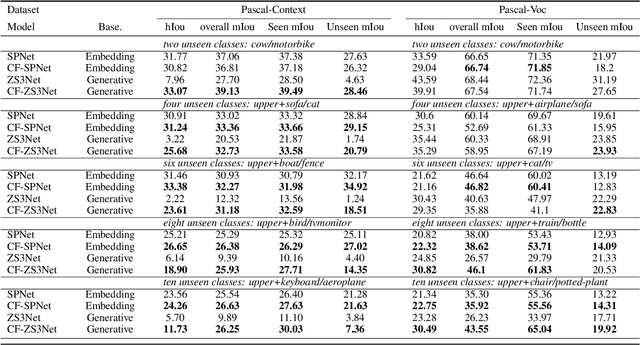
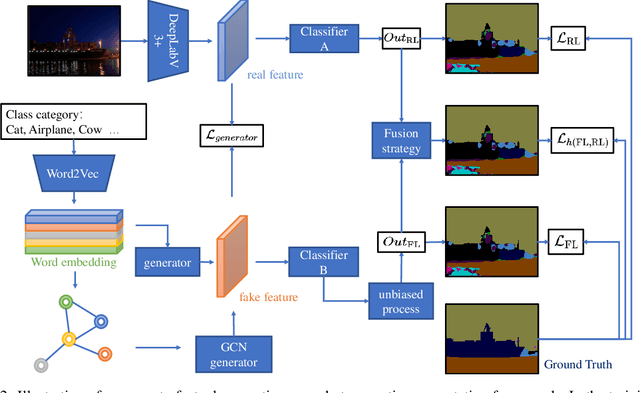
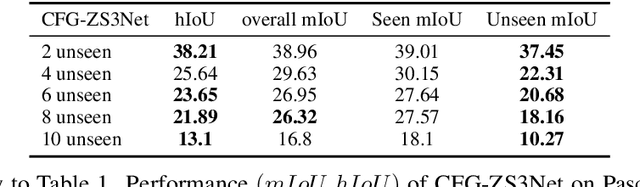
zero-shot learning is an essential part of computer vision. As a classical downstream task, zero-shot semantic segmentation has been studied because of its applicant value. One of the popular zero-shot semantic segmentation methods is based on the generative model Most new proposed works added structures on the same architecture to enhance this model. However, we found that, from the view of causal inference, the result of the original model has been influenced by spurious statistical relationships. Thus the performance of the prediction shows severe bias. In this work, we consider counterfactual methods to avoid the confounder in the original model. Based on this method, we proposed a new framework for zero-shot semantic segmentation. Our model is compared with baseline models on two real-world datasets, Pascal-VOC and Pascal-Context. The experiment results show proposed models can surpass previous confounded models and can still make use of additional structures to improve the performance. We also design a simple structure based on Graph Convolutional Networks (GCN) in this work.