 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineMarkNet: Line Landmark Detection for Valet Parking
Sep 25, 2023



We aim for accurate and efficient line landmark detection for valet parking, which is a long-standing yet unsolved problem in autonomous driving. To this end, we present a deep line landmark detection system where we carefully design the modules to be lightweight. Specifically, we first empirically design four general line landmarks including three physical lines and one novel mental line. The four line landmarks are effective for valet parking. We then develop a deep network (LineMarkNet) to detect line landmarks from surround-view cameras where we, via the pre-calibrated homography, fuse context from four separate cameras into the unified bird-eye-view (BEV) space, specifically we fuse the surroundview features and BEV features, then employ the multi-task decoder to detect multiple line landmarks where we apply the center-based strategy for object detection task, and design our graph transformer to enhance the vision transformer with hierarchical level graph reasoning for semantic segmentation task. At last, we further parameterize the detected line landmarks (e.g., intercept-slope form) whereby a novel filtering backend incorporates temporal and multi-view consistency to achieve smooth and stable detection. Moreover, we annotate a large-scale dataset to validate our method. Experimental results show that our framework achieves the enhanced performance compared with several line detection methods and validate the multi-task network's efficiency about the real-time line landmark detection on the Qualcomm 820A platform while meantime keeps superior accuracy, with our deep line landmark detection system.
PPD: A New Valet Parking Pedestrian Fisheye Dataset for Autonomous Driving
Sep 25, 2023



Pedestrian detection under valet parking scenarios is fundamental for autonomous driving. However, the presence of pedestrians can be manifested in a variety of ways and postures under imperfect ambient conditions, which can adversely affect detection performance. Furthermore, models trained on publicdatasets that include pedestrians generally provide suboptimal outcomes for these valet parking scenarios. In this paper, wepresent the Parking Pedestrian Dataset (PPD), a large-scale fisheye dataset to support research dealing with real-world pedestrians, especially with occlusions and diverse postures. PPD consists of several distinctive types of pedestrians captured with fisheye cameras. Additionally, we present a pedestrian detection baseline on PPD dataset, and introduce two data augmentation techniques to improve the baseline by enhancing the diversity ofthe original dataset. Extensive experiments validate the effectiveness of our novel data augmentation approaches over baselinesand the dataset's exceptional generalizability.
Graph-Segmenter: Graph Transformer with Boundary-aware Attention for Semantic Segmentation
Aug 15, 2023The transformer-based semantic segmentation approaches, which divide the image into different regions by sliding windows and model the relation inside each window, have achieved outstanding success. However, since the relation modeling between windows was not the primary emphasis of previous work, it was not fully utilized. To address this issue, we propose a Graph-Segmenter, including a Graph Transformer and a Boundary-aware Attention module, which is an effective network for simultaneously modeling the more profound relation between windows in a global view and various pixels inside each window as a local one, and for substantial low-cost boundary adjustment. Specifically, we treat every window and pixel inside the window as nodes to construct graphs for both views and devise the Graph Transformer. The introduced boundary-aware attention module optimizes the edge information of the target objects by modeling the relationship between the pixel on the object's edge. Extensive experiments on three widely used semantic segmentation datasets (Cityscapes, ADE-20k and PASCAL Context) demonstrate that our proposed network, a Graph Transformer with Boundary-aware Attention, can achieve state-of-the-art segmentation performance.
Learning Monocular Depth in Dynamic Environment via Context-aware Temporal Attention
May 12, 2023



The monocular depth estimation task has recently revealed encouraging prospects, especially for the autonomous driving task. To tackle the ill-posed problem of 3D geometric reasoning from 2D monocular images, multi-frame monocular methods are developed to leverage the perspective correlation information from sequential temporal frames. However, moving objects such as cars and trains usually violate the static scene assumption, leading to feature inconsistency deviation and misaligned cost values, which would mislead the optimization algorithm. In this work, we present CTA-Depth, a Context-aware Temporal Attention guided network for multi-frame monocular Depth estimation. Specifically, we first apply a multi-level attention enhancement module to integrate multi-level image features to obtain an initial depth and pose estimation. Then the proposed CTA-Refiner is adopted to alternatively optimize the depth and pose. During the refinement process, context-aware temporal attention (CTA) is developed to capture the global temporal-context correlations to maintain the feature consistency and estimation integrity of moving objects. In particular, we propose a long-range geometry embedding (LGE) module to produce a long-range temporal geometry prior. Our approach achieves significant improvements over state-of-the-art approaches on three benchmark datasets.
MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
Feb 21, 2023



Multi-view radar-camera fused 3D object detection provides a farther detection range and more helpful features for autonomous driving, especially under adverse weather. The current radar-camera fusion methods deliver kinds of designs to fuse radar information with camera data. However, these fusion approaches usually adopt the straightforward concatenation operation between multi-modal features, which ignores the semantic alignment with radar features and sufficient correlations across modals. In this paper, we present MVFusion, a novel Multi-View radar-camera Fusion method to achieve semantic-aligned radar features and enhance the cross-modal information interaction. To achieve so, we inject the semantic alignment into the radar features via the semantic-aligned radar encoder (SARE) to produce image-guided radar features. Then, we propose the radar-guided fusion transformer (RGFT) to fuse our radar and image features to strengthen the two modals' correlation from the global scope via the cross-attention mechanism. Extensive experiments show that MVFusion achieves state-of-the-art performance (51.7% NDS and 45.3% mAP) on the nuScenes dataset. We shall release our code and trained networks upon publication.
MonoPGC: Monocular 3D Object Detection with Pixel Geometry Contexts
Feb 21, 2023Monocular 3D object detection reveals an economical but challenging task in autonomous driving. Recently center-based monocular methods have developed rapidly with a great trade-off between speed and accuracy, where they usually depend on the object center's depth estimation via 2D features. However, the visual semantic features without sufficient pixel geometry information, may affect the performance of clues for spatial 3D detection tasks. To alleviate this, we propose MonoPGC, a novel end-to-end Monocular 3D object detection framework with rich Pixel Geometry Contexts. We introduce the pixel depth estimation as our auxiliary task and design depth cross-attention pyramid module (DCPM) to inject local and global depth geometry knowledge into visual features. In addition, we present the depth-space-aware transformer (DSAT) to integrate 3D space position and depth-aware features efficiently. Besides, we design a novel depth-gradient positional encoding (DGPE) to bring more distinct pixel geometry contexts into the transformer for better object detection. Extensive experiments demonstrate that our method achieves the state-of-the-art performance on the KITTI dataset.
Surround-view Fisheye BEV-Perception for Valet Parking: Dataset, Baseline and Distortion-insensitive Multi-task Framework
Dec 08, 2022



Surround-view fisheye perception under valet parking scenes is fundamental and crucial in autonomous driving. Environmental conditions in parking lots perform differently from the common public datasets, such as imperfect light and opacity, which substantially impacts on perception performance. Most existing networks based on public datasets may generalize suboptimal results on these valet parking scenes, also affected by the fisheye distortion. In this article, we introduce a new large-scale fisheye dataset called Fisheye Parking Dataset(FPD) to promote the research in dealing with diverse real-world surround-view parking cases. Notably, our compiled FPD exhibits excellent characteristics for different surround-view perception tasks. In addition, we also propose our real-time distortion-insensitive multi-task framework Fisheye Perception Network (FPNet), which improves the surround-view fisheye BEV perception by enhancing the fisheye distortion operation and multi-task lightweight designs. Extensive experiments validate the effectiveness of our approach and the dataset's exceptional generalizability.
* 12 pages, 11 figures
OCR-RTPS: An OCR-based real-time positioning system for the valet parking
Dec 08, 2022Obtaining the position of ego-vehicle is a crucial prerequisite for automatic control and path planning in the field of autonomous driving. Most existing positioning systems rely on GPS, RTK, or wireless signals, which are arduous to provide effective localization under weak signal conditions. This paper proposes a real-time positioning system based on the detection of the parking numbers as they are unique positioning marks in the parking lot scene. It does not only can help with the positioning with open area, but also run independently under isolation environment. The result tested on both public datasets and self-collected dataset show that the system outperforms others in both performances and applies in practice. In addition, the code and dataset will release later.
* 25 pages, 9 figures
Disentangling and Vectorization: A 3D Visual Perception Approach for Autonomous Driving Based on Surround-View Fisheye Cameras
Jul 19, 2021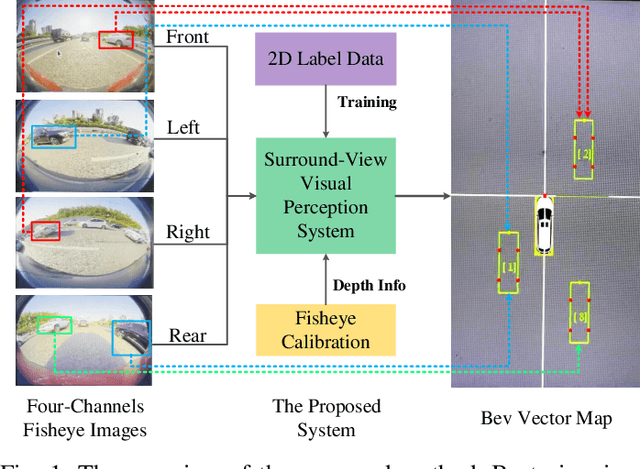
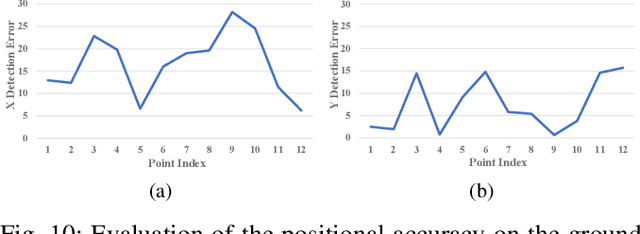

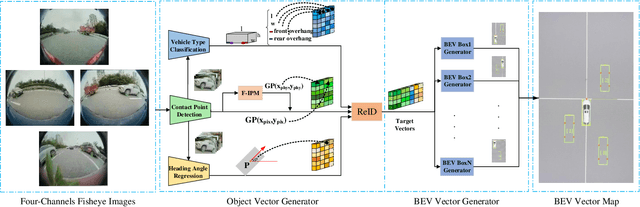
The 3D visual perception for vehicles with the surround-view fisheye camera system is a critical and challenging task for low-cost urban autonomous driving. While existing monocular 3D object detection methods perform not well enough on the fisheye images for mass production, partly due to the lack of 3D datasets of such images. In this paper, we manage to overcome and avoid the difficulty of acquiring the large scale of accurate 3D labeled truth data, by breaking down the 3D object detection task into some sub-tasks, such as vehicle's contact point detection, type classification, re-identification and unit assembling, etc. Particularly, we propose the concept of Multidimensional Vector to include the utilizable information generated in different dimensions and stages, instead of the descriptive approach for the bird's eye view (BEV) or a cube of eight points. The experiments of real fisheye images demonstrate that our solution achieves state-of-the-art accuracy while being real-time in practice.