 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HARD: Hard Augmentations for Robust Distillation
May 25, 2023
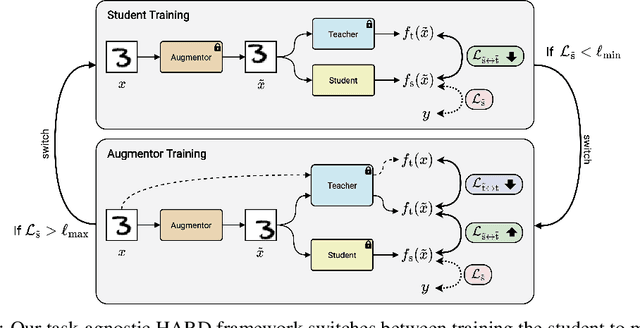
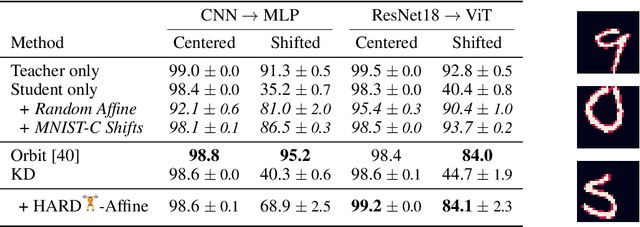
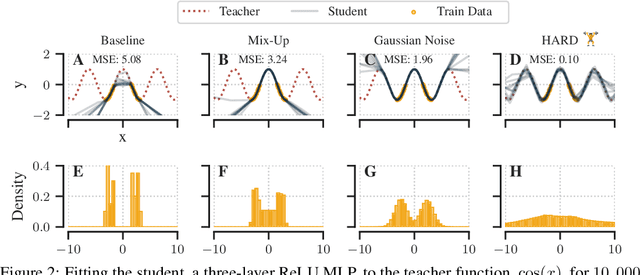
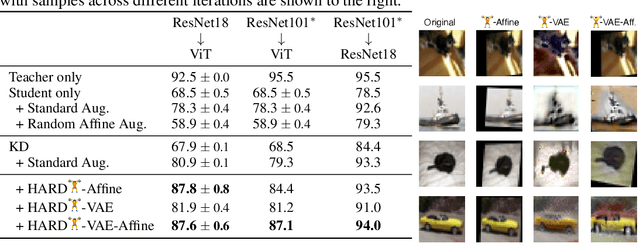
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.
FIT: Far-reaching Interleaved Transformers
May 25, 2023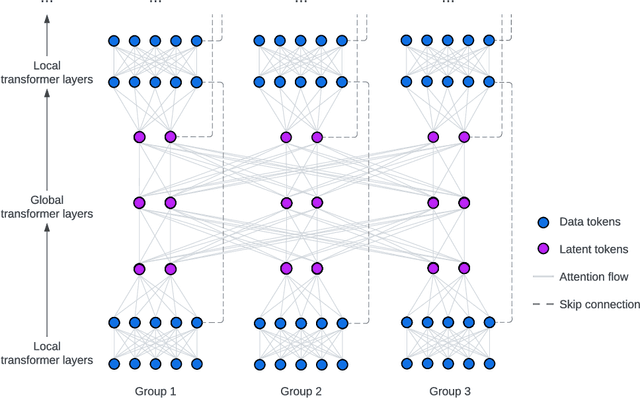
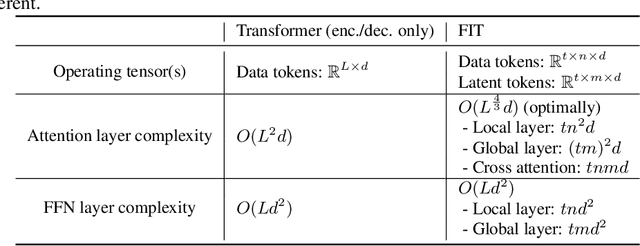
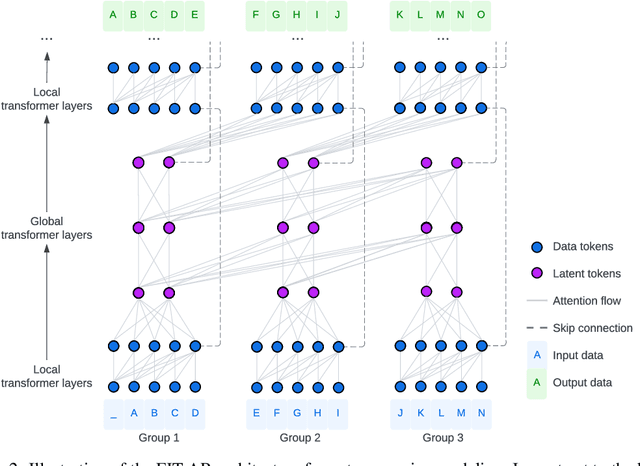
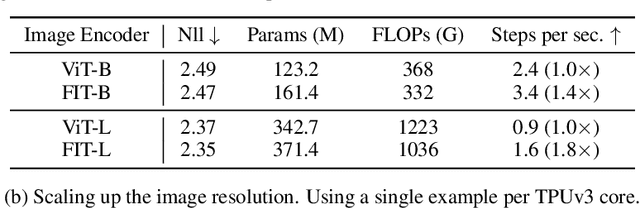
We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, or 160K tokens (after patch tokenization), within a memory capacity of 16GB, without requiring specific optimizations or model parallelism.
Language-Guided 3D Object Detection in Point Cloud for Autonomous Driving
May 25, 2023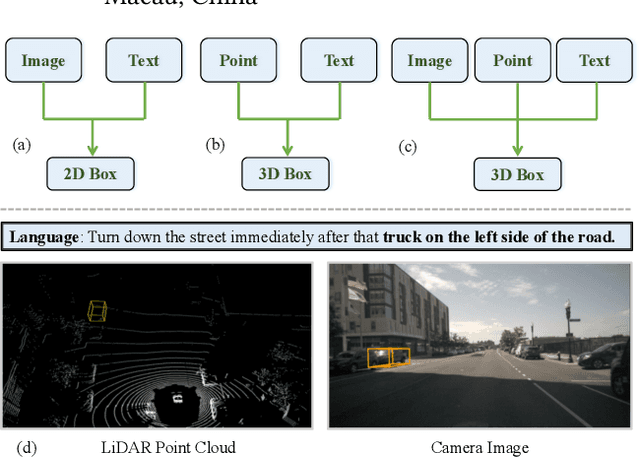
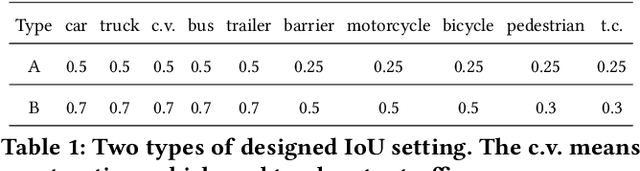
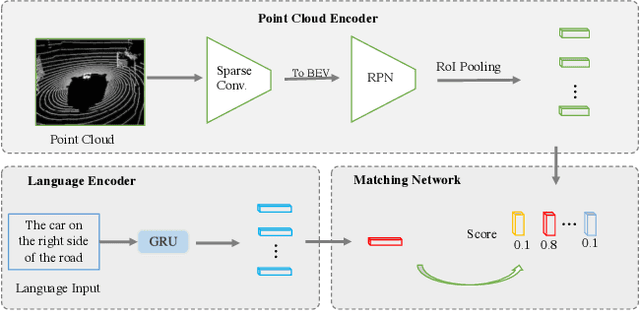
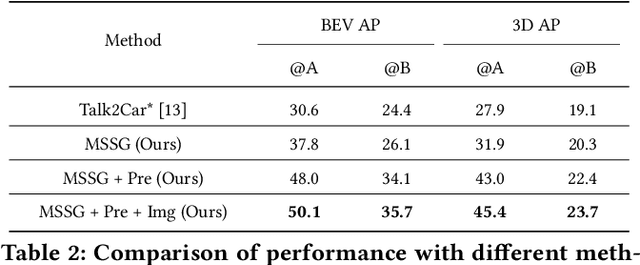
This paper addresses the problem of 3D referring expression comprehension (REC) in autonomous driving scenario, which aims to ground a natural language to the targeted region in LiDAR point clouds. Previous approaches for REC usually focus on the 2D or 3D-indoor domain, which is not suitable for accurately predicting the location of the queried 3D region in an autonomous driving scene. In addition, the upper-bound limitation and the heavy computation cost motivate us to explore a better solution. In this work, we propose a new multi-modal visual grounding task, termed LiDAR Grounding. Then we devise a Multi-modal Single Shot Grounding (MSSG) approach with an effective token fusion strategy. It jointly learns the LiDAR-based object detector with the language features and predicts the targeted region directly from the detector without any post-processing. Moreover, the image feature can be flexibly integrated into our approach to provide rich texture and color information. The cross-modal learning enforces the detector to concentrate on important regions in the point cloud by considering the informative language expressions, thus leading to much better accuracy and efficiency. Extensive experiments on the Talk2Car dataset demonstrate the effectiveness of the proposed methods. Our work offers a deeper insight into the LiDAR-based grounding task and we expect it presents a promising direction for the autonomous driving community.
NLIP: Noise-robust Language-Image Pre-training
Jan 04, 2023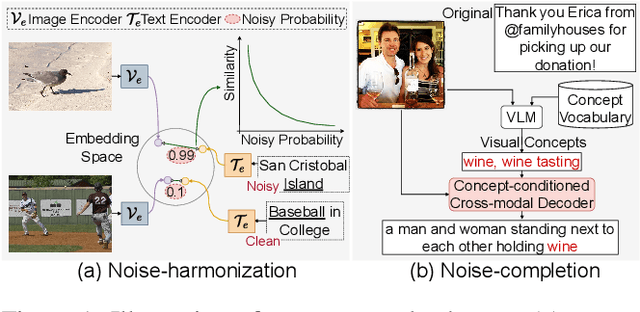
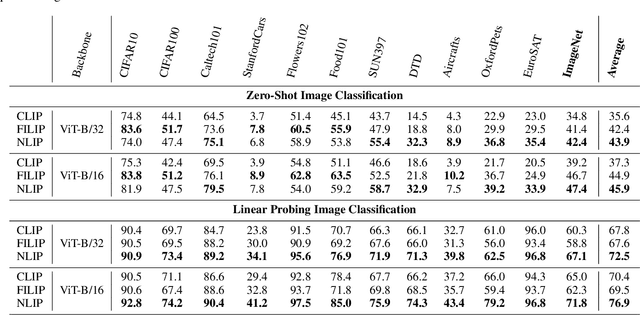
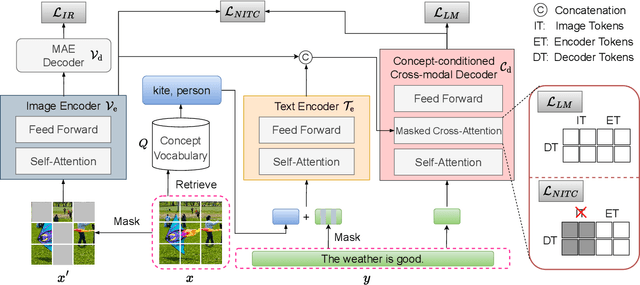
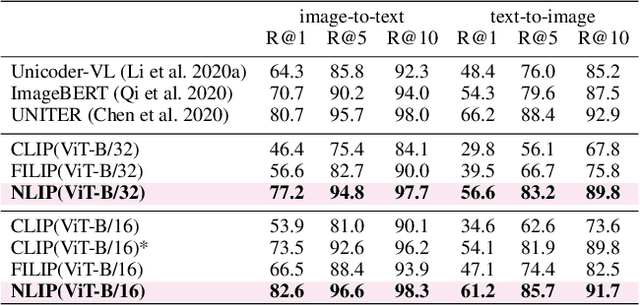
Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
Dual Diffusion Architecture for Fisheye Image Rectification: Synthetic-to-Real Generalization
Jan 26, 2023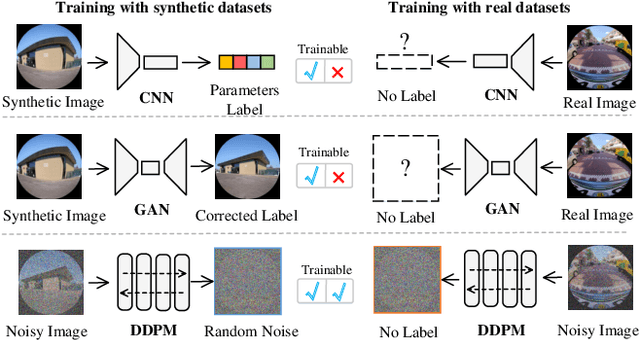
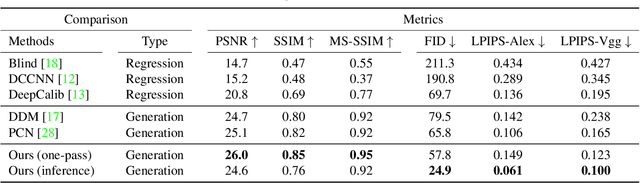
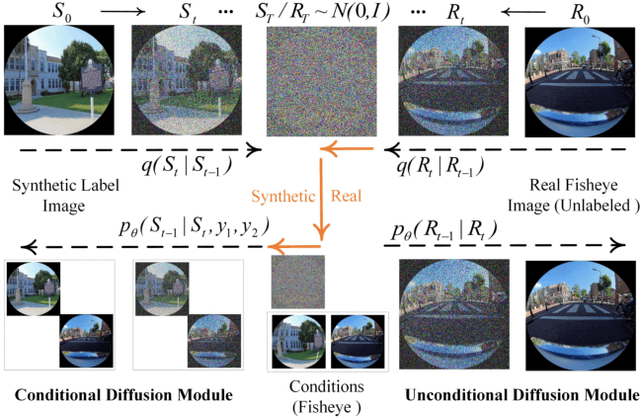
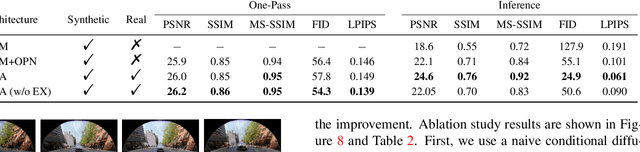
Fisheye image rectification has a long-term unresolved issue with synthetic-to-real generalization. In most previous works, the model trained on the synthetic images obtains unsatisfactory performance on the real-world fisheye image. To this end, we propose a Dual Diffusion Architecture (DDA) for the fisheye rectification with a better generalization ability. The proposed DDA is simultaneously trained with paired synthetic fisheye images and unlabeled real fisheye images. By gradually introducing noises, the synthetic and real fisheye images can eventually develop into a consistent noise distribution, improving the generalization and achieving unlabeled real fisheye correction. The original image serves as the prior guidance in existing DDPMs (Denoising Diffusion Probabilistic Models). However, the non-negligible indeterminate relationship between the prior condition and the target affects the generation performance. Especially in the rectification task, the radial distortion can cause significant artifacts. Therefore, we provide an unsupervised one-pass network that produces a plausible new condition to strengthen guidance. This network can be regarded as an alternate scheme for fast producing reliable results without iterative inference. Compared with the state-of-the-art methods, our approach can reach superior performance in both synthetic and real fisheye image corrections.
Evaluating LeNet Algorithms in Classification Lung Cancer from Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases
May 19, 2023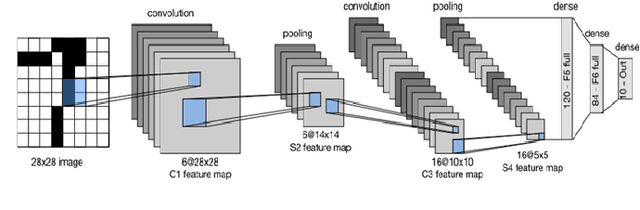
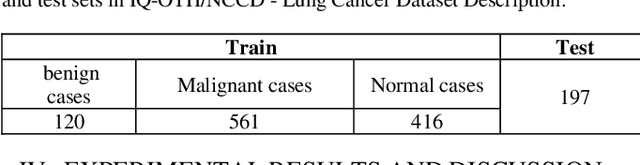
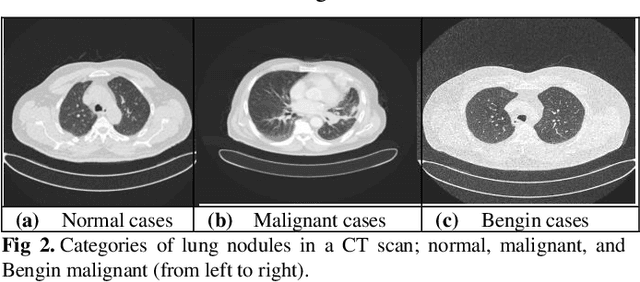
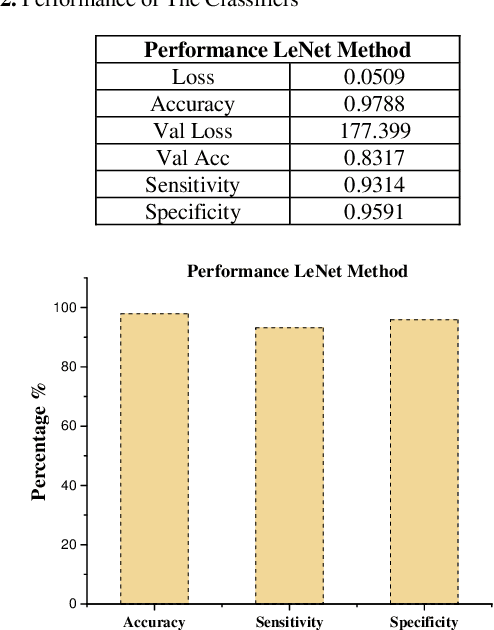
The advancement of computer-aided detection systems had a significant impact on clinical analysis and decision-making on human disease. Lung cancer requires more attention among the numerous diseases being examined because it affects both men and women, increasing the mortality rate. LeNet, a deep learning model, is used in this study to detect lung tumors. The studies were run on a publicly available dataset made up of CT image data (IQ-OTH/NCCD). Convolutional neural networks (CNNs) were employed in the experiment for feature extraction and classification. The proposed system was evaluated on Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases datasets the success percentage was calculated as 99.51%, sensitivity (93%) and specificity (95%), and better results were obtained compared to the existing methods. Development and validation of algorithms such as ours are important initial steps in the development of software suites that could be adopted in routine pathological practices and potentially help reduce the burden on pathologists.
PyTorch Hyperparameter Tuning -- A Tutorial for spotPython
May 19, 2023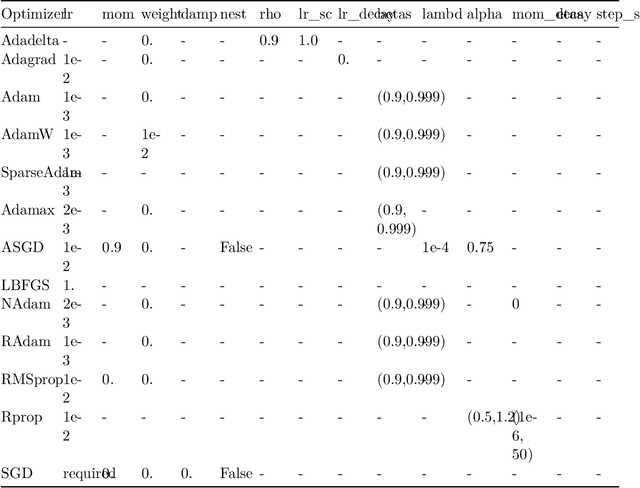
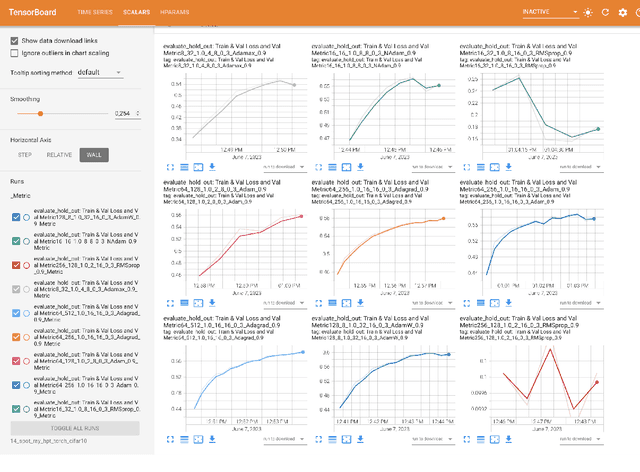

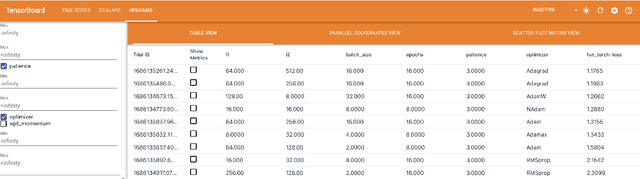
The goal of hyperparameter tuning (or hyperparameter optimization) is to optimize the hyperparameters to improve the performance of the machine or deep learning model. spotPython (``Sequential Parameter Optimization Toolbox in Python'') is the Python version of the well-known hyperparameter tuner SPOT, which has been developed in the R programming environment for statistical analysis for over a decade. PyTorch is an optimized tensor library for deep learning using GPUs and CPUs. This document shows how to integrate the spotPython hyperparameter tuner into the PyTorch training workflow. As an example, the results of the CIFAR10 image classifier are used. In addition to an introduction to spotPython, this tutorial also includes a brief comparison with Ray Tune, a Python library for running experiments and tuning hyperparameters. This comparison is based on the PyTorch hyperparameter tuning tutorial. The advantages and disadvantages of both approaches are discussed. We show that spotPython achieves similar or even better results while being more flexible and transparent than Ray Tune.
Helping Visually Impaired People Take Better Quality Pictures
May 14, 2023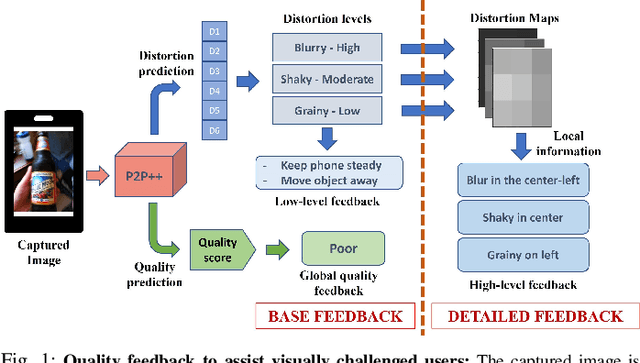
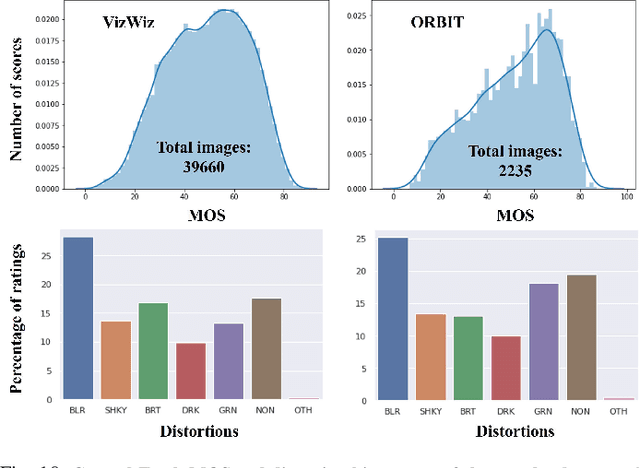
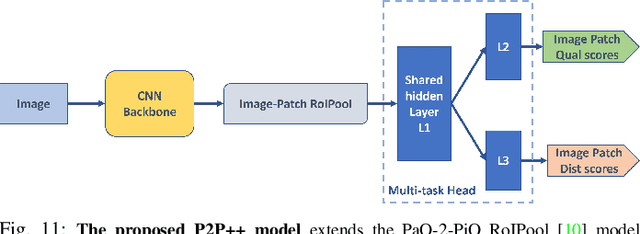
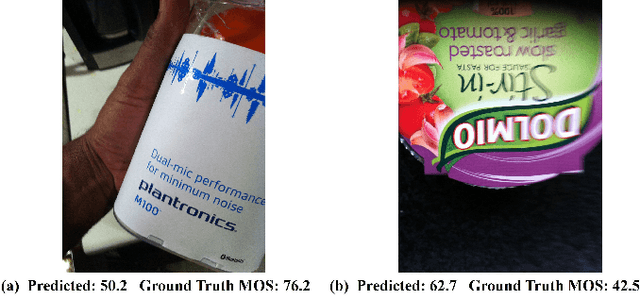
Perception-based image analysis technologies can be used to help visually impaired people take better quality pictures by providing automated guidance, thereby empowering them to interact more confidently on social media. The photographs taken by visually impaired users often suffer from one or both of two kinds of quality issues: technical quality (distortions), and semantic quality, such as framing and aesthetic composition. Here we develop tools to help them minimize occurrences of common technical distortions, such as blur, poor exposure, and noise. We do not address the complementary problems of semantic quality, leaving that aspect for future work. The problem of assessing and providing actionable feedback on the technical quality of pictures captured by visually impaired users is hard enough, owing to the severe, commingled distortions that often occur. To advance progress on the problem of analyzing and measuring the technical quality of visually impaired user-generated content (VI-UGC), we built a very large and unique subjective image quality and distortion dataset. This new perceptual resource, which we call the LIVE-Meta VI-UGC Database, contains $40$K real-world distorted VI-UGC images and $40$K patches, on which we recorded $2.7$M human perceptual quality judgments and $2.7$M distortion labels. Using this psychometric resource we also created an automatic blind picture quality and distortion predictor that learns local-to-global spatial quality relationships, achieving state-of-the-art prediction performance on VI-UGC pictures, significantly outperforming existing picture quality models on this unique class of distorted picture data. We also created a prototype feedback system that helps to guide users to mitigate quality issues and take better quality pictures, by creating a multi-task learning framework.
SuSana Distancia is all you need: Enforcing class separability in metric learning via two novel distance-based loss functions for few-shot image classification
May 18, 2023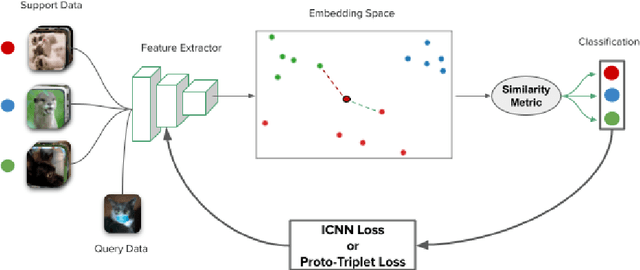
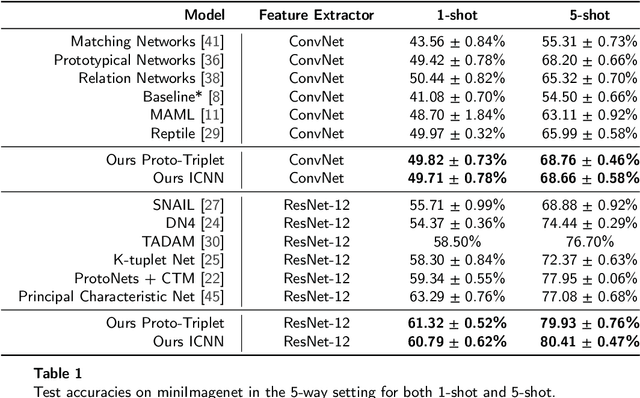
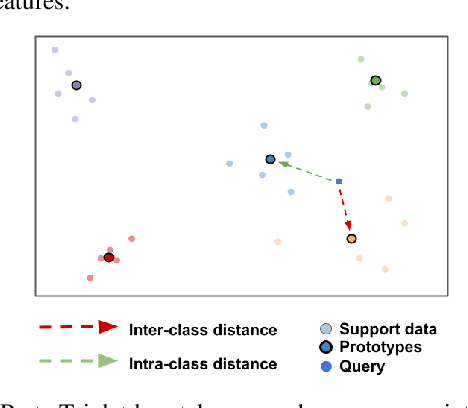
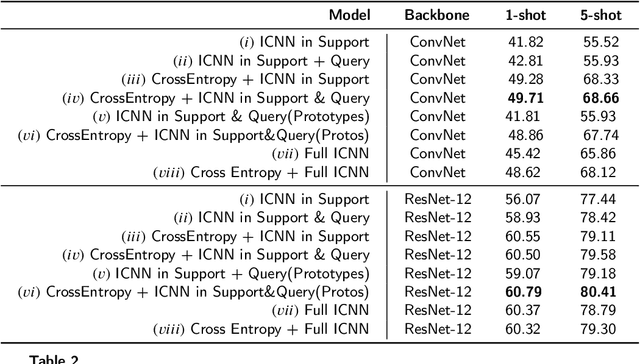
Few-shot learning is a challenging area of research that aims to learn new concepts with only a few labeled samples of data. Recent works based on metric-learning approaches leverage the meta-learning approach, which is encompassed by episodic tasks that make use a support (training) and query set (test) with the objective of learning a similarity comparison metric between those sets. Due to the lack of data, the learning process of the embedding network becomes an important part of the few-shot task. Previous works have addressed this problem using metric learning approaches, but the properties of the underlying latent space and the separability of the difference classes on it was not entirely enforced. In this work, we propose two different loss functions which consider the importance of the embedding vectors by looking at the intra-class and inter-class distance between the few data. The first loss function is the Proto-Triplet Loss, which is based on the original triplet loss with the modifications needed to better work on few-shot scenarios. The second loss function, which we dub ICNN loss is based on an inter and intra class nearest neighbors score, which help us to assess the quality of embeddings obtained from the trained network. Our results, obtained from a extensive experimental setup show a significant improvement in accuracy in the miniImagenNet benchmark compared to other metric-based few-shot learning methods by a margin of 2%, demonstrating the capability of these loss functions to allow the network to generalize better to previously unseen classes. In our experiments, we demonstrate competitive generalization capabilities to other domains, such as the Caltech CUB, Dogs and Cars datasets compared with the state of the art.
DeepMA: End-to-end Deep Multiple Access for Wireless Image Transmission in Semantic Communication
Mar 21, 2023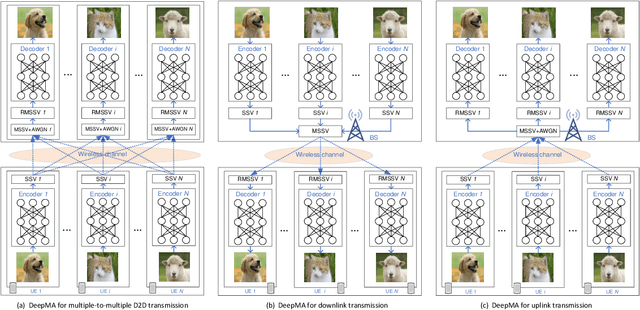
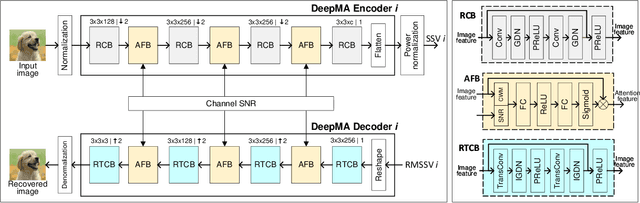

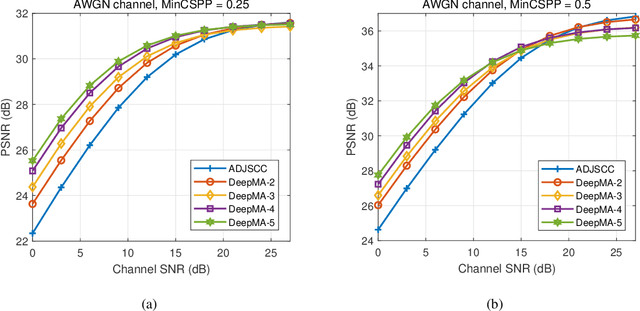
Semantic communication is a new paradigm that exploits deep learning models to enable end-to-end communications processes, and recent studies have shown that it can achieve better noise resiliency compared with traditional communication schemes in a low signal-to-noise (SNR) regime. To achieve multiple access in semantic communication, we propose a deep learning-based multiple access (DeepMA) method by training semantic communication models with the abilities of joint source-channel coding (JSCC) and orthogonal signal modulation. DeepMA is achieved by a DeepMA network (DMANet), which is comprised of several independent encoder-decoder pairs (EDPs), and the DeepMA encoders can encode the input data as mutually orthogonal semantic symbol vectors (SSVs) such that the DeepMA decoders can recover their own target data from a received mixed SSV (MSSV) superposed by multiple SSV components transmitted from different encoders. We describe frameworks of DeepMA in wireless device-to-device (D2D), downlink, and uplink channel multiplexing scenarios, along with the training algorithm. We evaluate the performance of the proposed DeepMA in wireless image transmission tasks and compare its performance with the attention module-based deep JSCC (ADJSCC) method and conventional communication schemes using better portable graphics (BPG) and Low-density parity-check code (LDPC). The results obtained show that the proposed DeepMA can achieve effective, flexible, and privacy-preserving channel multiplexing process, and demonstrate that our proposed DeepMA approach can yield comparable bandwidth efficiency compared with conventional multiple access schemes.