 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023

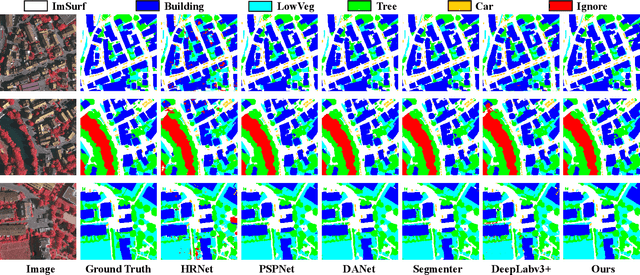
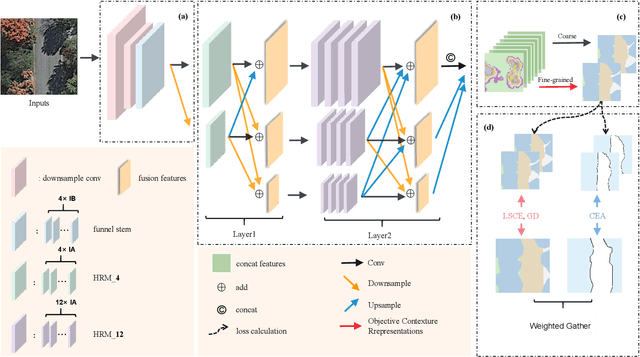
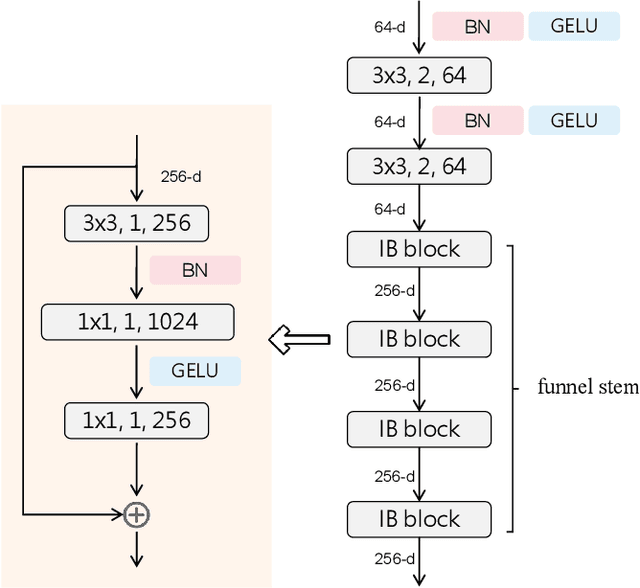
High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.
MassNet: A Deep Learning Approach for Body Weight Extraction from A Single Pressure Image
Mar 17, 2023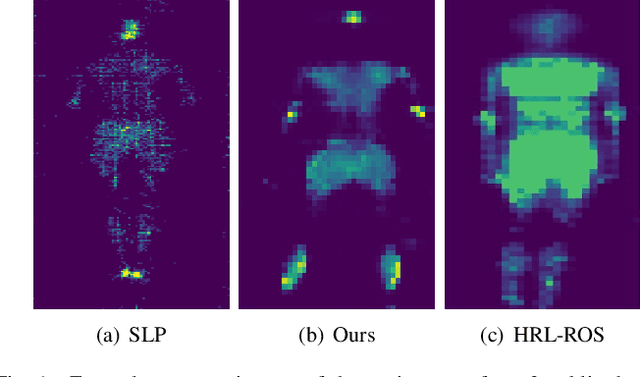

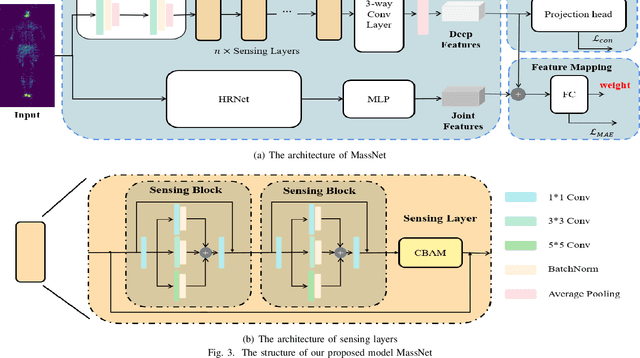
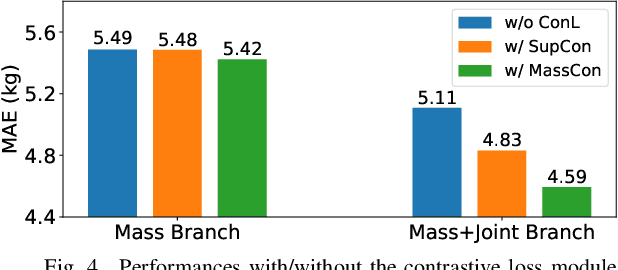
Body weight, as an essential physiological trait, is of considerable significance in many applications like body management, rehabilitation, and drug dosing for patient-specific treatments. Previous works on the body weight estimation task are mainly vision-based, using 2D/3D, depth, or infrared images, facing problems in illumination, occlusions, and especially privacy issues. The pressure mapping mattress is a non-invasive and privacy-preserving tool to obtain the pressure distribution image over the bed surface, which strongly correlates with the body weight of the lying person. To extract the body weight from this image, we propose a deep learning-based model, including a dual-branch network to extract the deep features and pose features respectively. A contrastive learning module is also combined with the deep-feature branch to help mine the mutual factors across different postures of every single subject. The two groups of features are then concatenated for the body weight regression task. To test the model's performance over different hardware and posture settings, we create a pressure image dataset of 10 subjects and 23 postures, using a self-made pressure-sensing bedsheet. This dataset, which is made public together with this paper, together with a public dataset, are used for the validation. The results show that our model outperforms the state-of-the-art algorithms over both 2 datasets. Our research constitutes an important step toward fully automatic weight estimation in both clinical and at-home practice. Our dataset is available for research purposes at: https://github.com/USTCWzy/MassEstimation.
Cluster-Guided Semi-Supervised Domain Adaptation for Imbalanced Medical Image Classification
Mar 02, 2023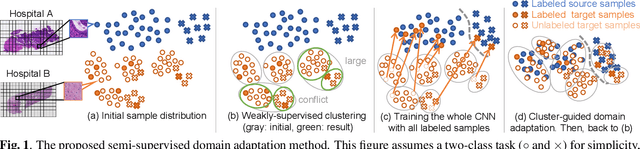
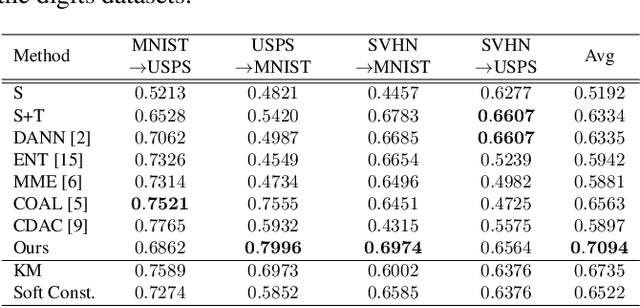
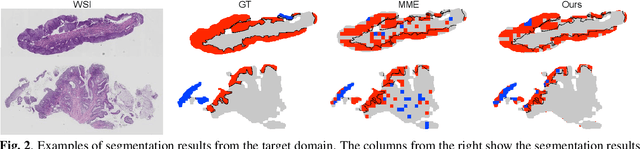
Semi-supervised domain adaptation is a technique to build a classifier for a target domain by modifying a classifier in another (source) domain using many unlabeled samples and a small number of labeled samples from the target domain. In this paper, we develop a semi-supervised domain adaptation method, which has robustness to class-imbalanced situations, which are common in medical image classification tasks. For robustness, we propose a weakly-supervised clustering pipeline to obtain high-purity clusters and utilize the clusters in representation learning for domain adaptation. The proposed method showed state-of-the-art performance in the experiment using severely class-imbalanced pathological image patches.
Unlocking the Potential of Medical Imaging with ChatGPT's Intelligent Diagnostics
May 12, 2023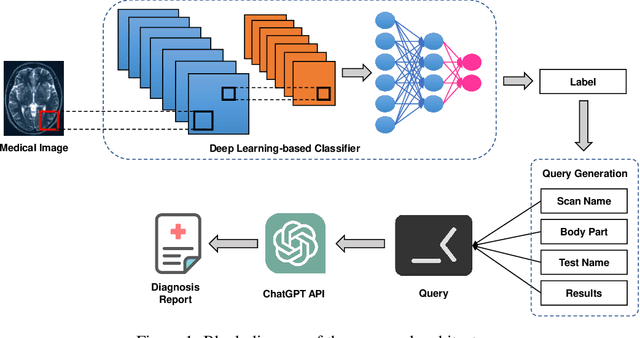
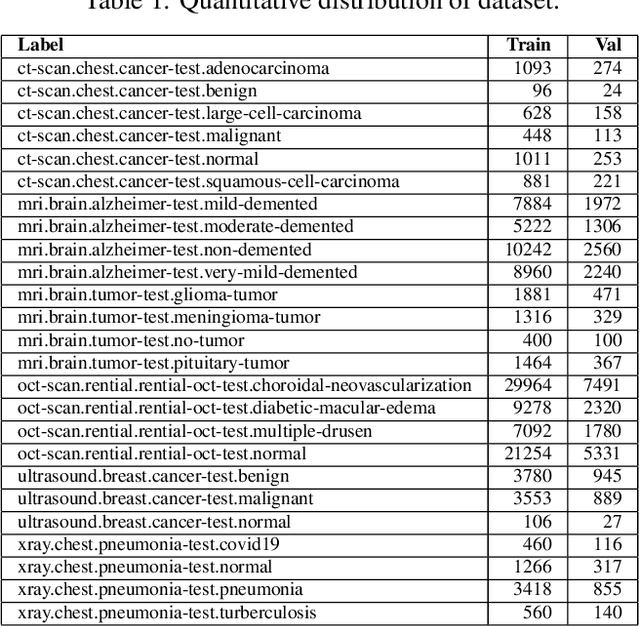
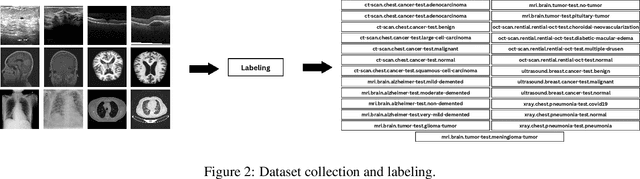
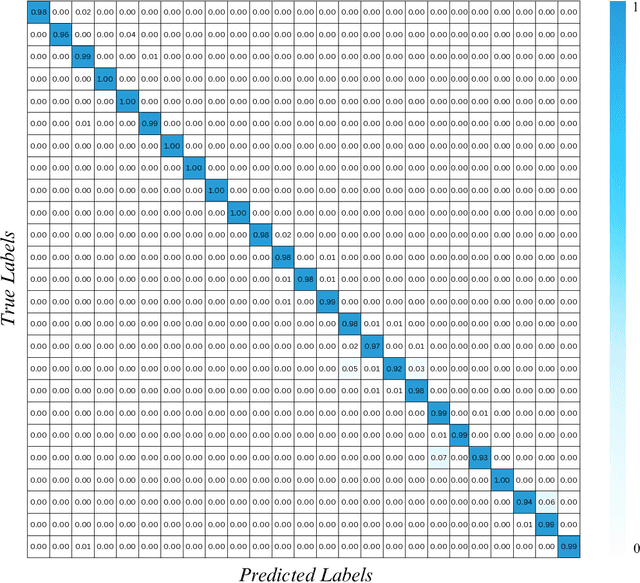
Medical imaging is an essential tool for diagnosing various healthcare diseases and conditions. However, analyzing medical images is a complex and time-consuming task that requires expertise and experience. This article aims to design a decision support system to assist healthcare providers and patients in making decisions about diagnosing, treating, and managing health conditions. The proposed architecture contains three stages: 1) data collection and labeling, 2) model training, and 3) diagnosis report generation. The key idea is to train a deep learning model on a medical image dataset to extract four types of information: the type of image scan, the body part, the test image, and the results. This information is then fed into ChatGPT to generate automatic diagnostics. The proposed system has the potential to enhance decision-making, reduce costs, and improve the capabilities of healthcare providers. The efficacy of the proposed system is analyzed by conducting extensive experiments on a large medical image dataset. The experimental outcomes exhibited promising performance for automatic diagnosis through medical images.
Designing an Encoder for Fast Personalization of Text-to-Image Models
Feb 23, 2023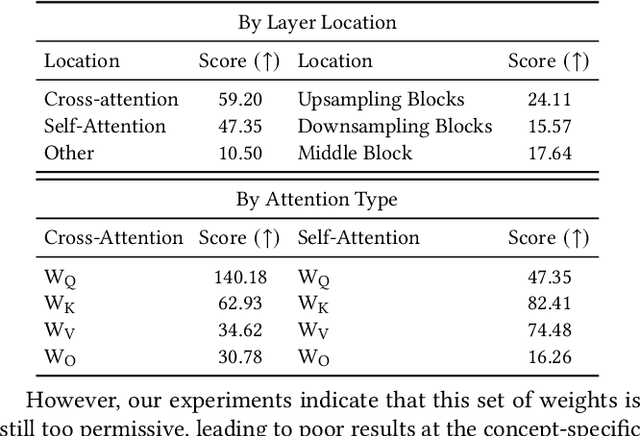
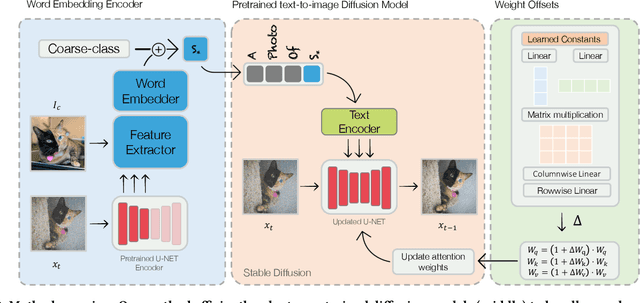

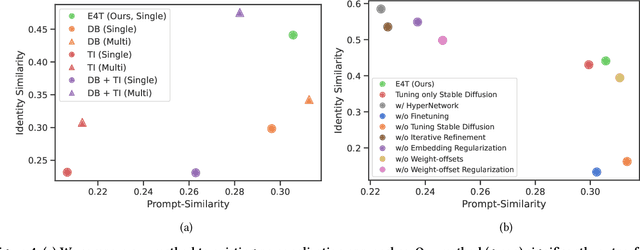
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst
May 25, 2023
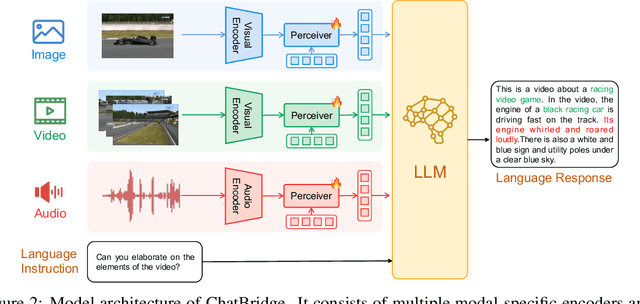
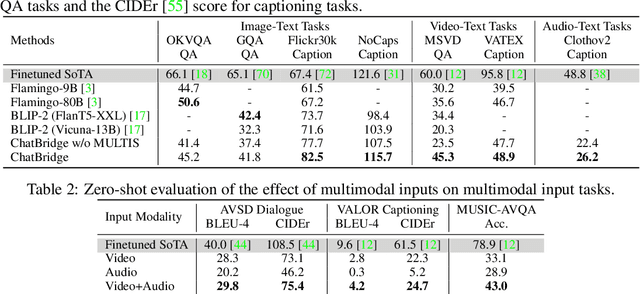
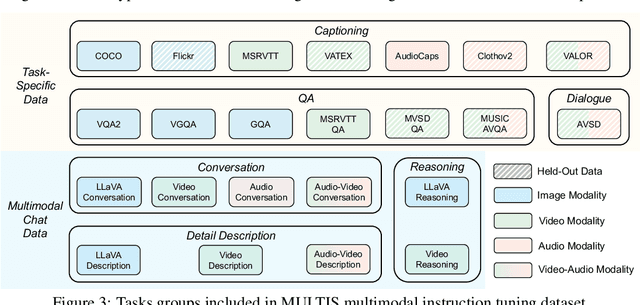
Building general-purpose models that can perceive diverse real-world modalities and solve various tasks is an appealing target in artificial intelligence. In this paper, we present ChatBridge, a novel multimodal language model that leverages the expressive capabilities of language as the catalyst to bridge the gap between various modalities. We show that only language-paired two-modality data is sufficient to connect all modalities. ChatBridge leverages recent large language models (LLM) and extends their zero-shot capabilities to incorporate diverse multimodal inputs. ChatBridge undergoes a two-stage training. The first stage aligns each modality with language, which brings emergent multimodal correlation and collaboration abilities. The second stage instruction-finetunes ChatBridge to align it with user intent with our newly proposed multimodal instruction tuning dataset, named MULTIS, which covers a wide range of 16 multimodal tasks of text, image, video, and audio modalities. We show strong quantitative and qualitative results on zero-shot multimodal tasks covering text, image, video, and audio modalities. All codes, data, and models of ChatBridge will be open-sourced.
RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban Environments
May 29, 2023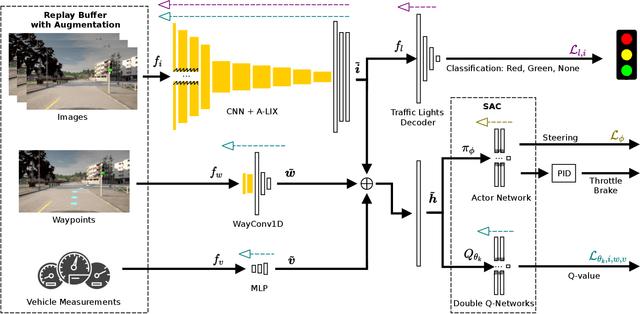
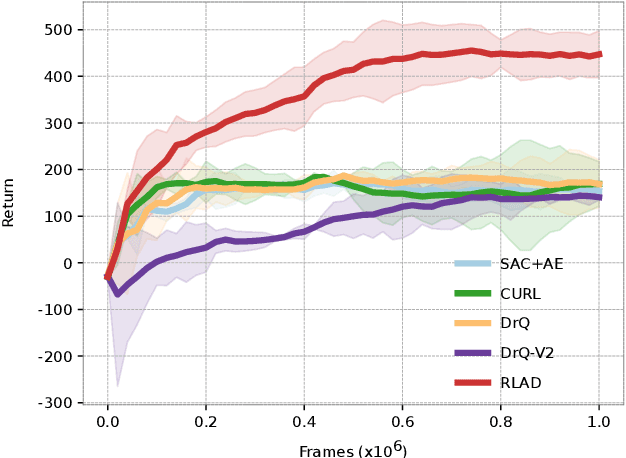
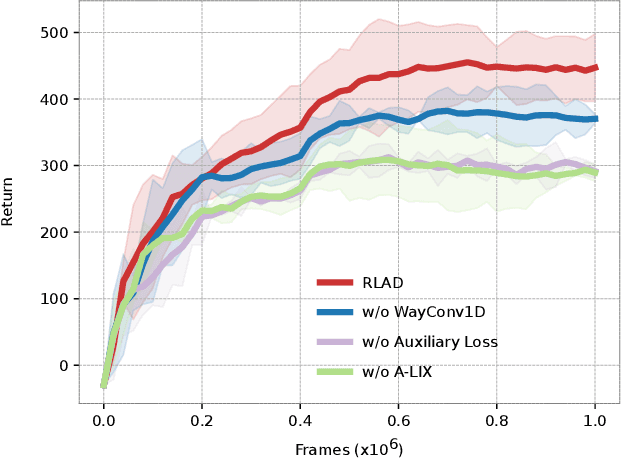
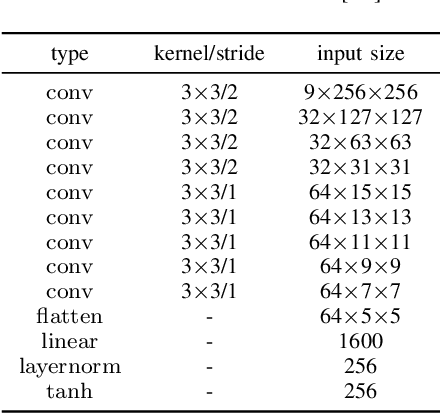
Current approaches of Reinforcement Learning (RL) applied in urban Autonomous Driving (AD) focus on decoupling the perception training from the driving policy training. The main reason is to avoid training a convolution encoder alongside a policy network, which is known to have issues related to sample efficiency, degenerated feature representations, and catastrophic self-overfitting. However, this paradigm can lead to representations of the environment that are not aligned with the downstream task, which may result in suboptimal performances. To address this limitation, this paper proposes RLAD, the first Reinforcement Learning from Pixels (RLfP) method applied in the urban AD domain. We propose several techniques to enhance the performance of an RLfP algorithm in this domain, including: i) an image encoder that leverages both image augmentations and Adaptive Local Signal Mixing (A-LIX) layers; ii) WayConv1D, which is a waypoint encoder that harnesses the 2D geometrical information of the waypoints using 1D convolutions; and iii) an auxiliary loss to increase the significance of the traffic lights in the latent representation of the environment. Experimental results show that RLAD significantly outperforms all state-of-the-art RLfP methods on the NoCrash benchmark. We also present an infraction analysis on the NoCrash-regular benchmark, which indicates that RLAD performs better than all other methods in terms of both collision rate and red light infractions.
FIT: Frequency-based Image Translation for Domain Adaptive Object Detection
Mar 07, 2023
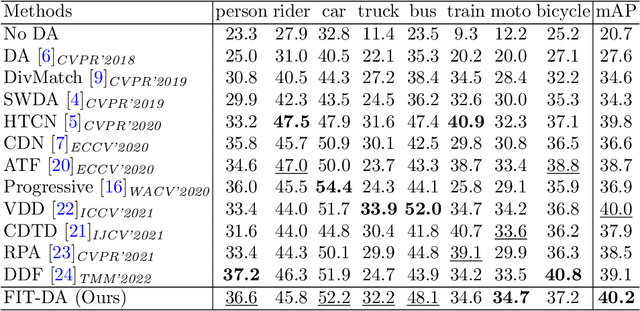
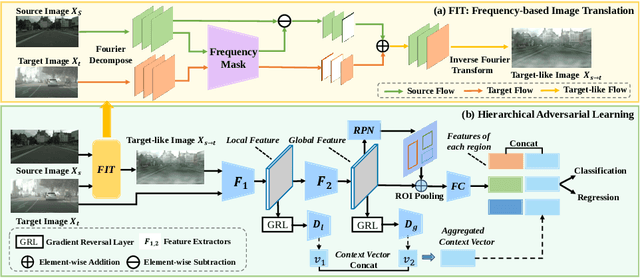

Domain adaptive object detection (DAOD) aims to adapt the detector from a labelled source domain to an unlabelled target domain. In recent years, DAOD has attracted massive attention since it can alleviate performance degradation due to the large shift of data distributions in the wild. To align distributions between domains, adversarial learning is widely used in existing DAOD methods. However, the decision boundary for the adversarial domain discriminator may be inaccurate, causing the model biased towards the source domain. To alleviate this bias, we propose a novel Frequency-based Image Translation (FIT) framework for DAOD. First, by keeping domain-invariant frequency components and swapping domain-specific ones, we conduct image translation to reduce domain shift at the input level. Second, hierarchical adversarial feature learning is utilized to further mitigate the domain gap at the feature level. Finally, we design a joint loss to train the entire network in an end-to-end manner without extra training to obtain translated images. Extensive experiments on three challenging DAOD benchmarks demonstrate the effectiveness of our method.
DDS2M: Self-Supervised Denoising Diffusion Spatio-Spectral Model for Hyperspectral Image Restoration
Mar 19, 2023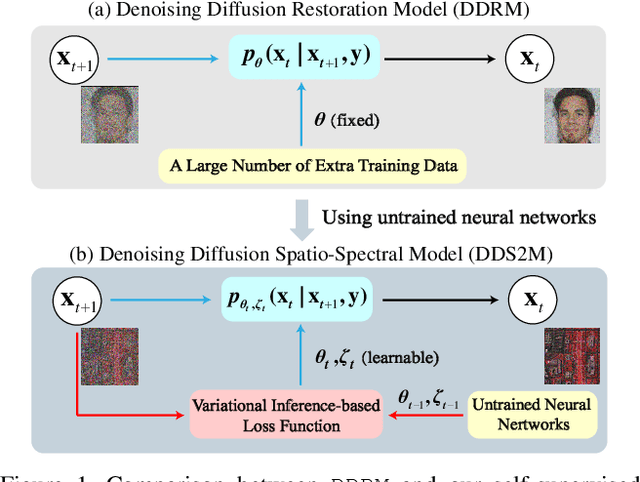
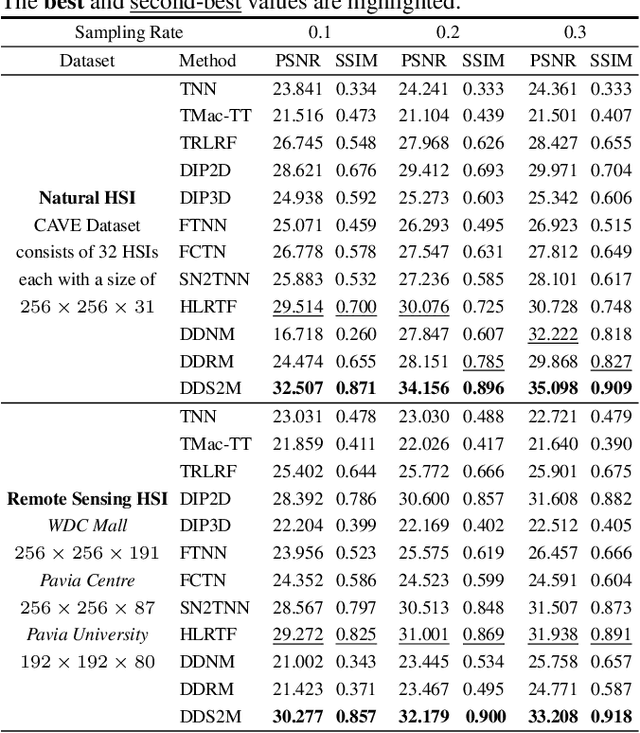
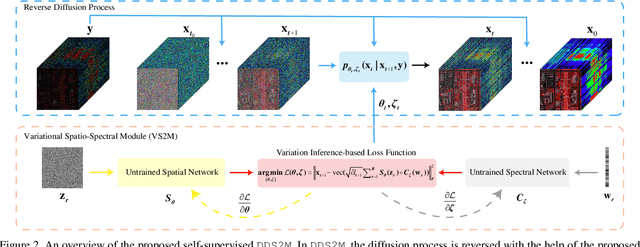
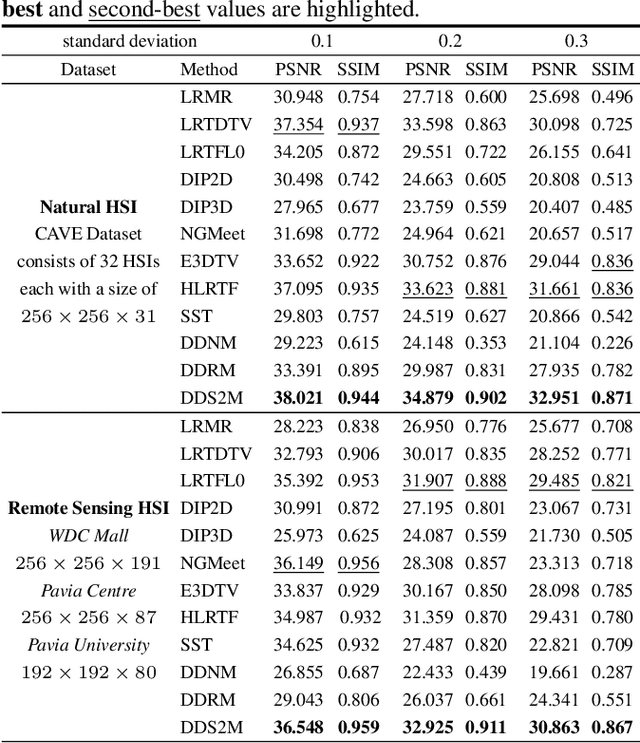
Diffusion models have recently received a surge of interest due to their impressive performance for image restoration, especially in terms of noise robustness. However, existing diffusion-based methods are trained on a large amount of training data and perform very well in-distribution, but can be quite susceptible to distribution shift. This is especially inappropriate for data-starved hyperspectral image (HSI) restoration. To tackle this problem, this work puts forth a self-supervised diffusion model for HSI restoration, namely Denoising Diffusion Spatio-Spectral Model (\texttt{DDS2M}), which works by inferring the parameters of the proposed Variational Spatio-Spectral Module (VS2M) during the reverse diffusion process, solely using the degraded HSI without any extra training data. In VS2M, a variational inference-based loss function is customized to enable the untrained spatial and spectral networks to learn the posterior distribution, which serves as the transitions of the sampling chain to help reverse the diffusion process. Benefiting from its self-supervised nature and the diffusion process, \texttt{DDS2M} enjoys stronger generalization ability to various HSIs compared to existing diffusion-based methods and superior robustness to noise compared to existing HSI restoration methods. Extensive experiments on HSI denoising, noisy HSI completion and super-resolution on a variety of HSIs demonstrate \texttt{DDS2M}'s superiority over the existing task-specific state-of-the-arts.
ORGAN: Observation-Guided Radiology Report Generation via Tree Reasoning
Jun 10, 2023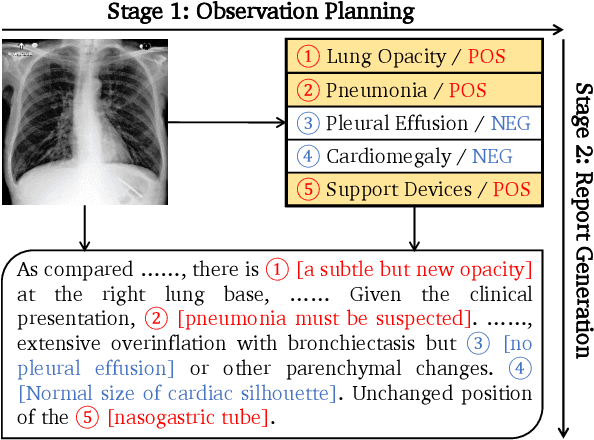
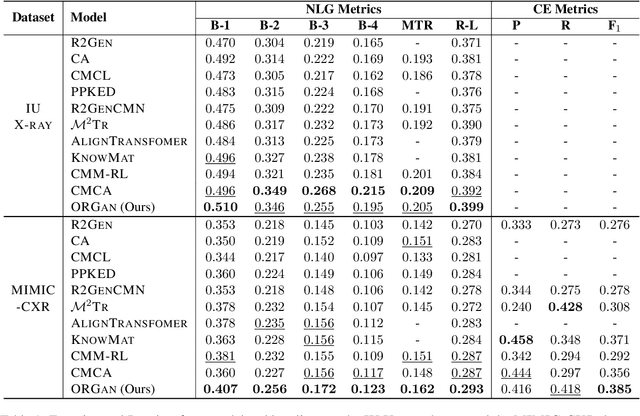
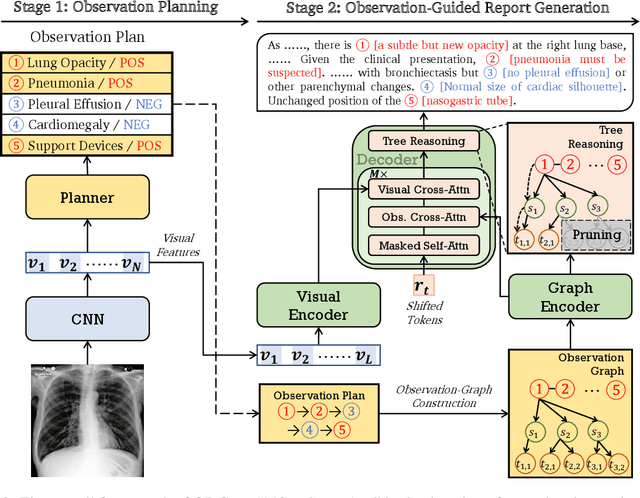
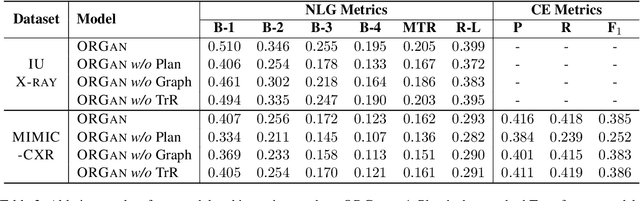
This paper explores the task of radiology report generation, which aims at generating free-text descriptions for a set of radiographs. One significant challenge of this task is how to correctly maintain the consistency between the images and the lengthy report. Previous research explored solving this issue through planning-based methods, which generate reports only based on high-level plans. However, these plans usually only contain the major observations from the radiographs (e.g., lung opacity), lacking much necessary information, such as the observation characteristics and preliminary clinical diagnoses. To address this problem, the system should also take the image information into account together with the textual plan and perform stronger reasoning during the generation process. In this paper, we propose an observation-guided radiology report generation framework (ORGAN). It first produces an observation plan and then feeds both the plan and radiographs for report generation, where an observation graph and a tree reasoning mechanism are adopted to precisely enrich the plan information by capturing the multi-formats of each observation. Experimental results demonstrate that our framework outperforms previous state-of-the-art methods regarding text quality and clinical efficacy