 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
Feb 03, 2023
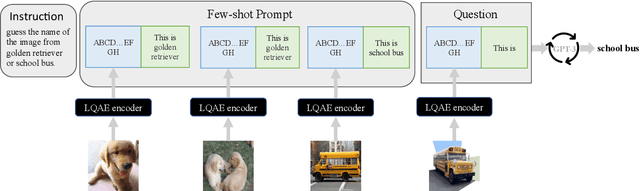
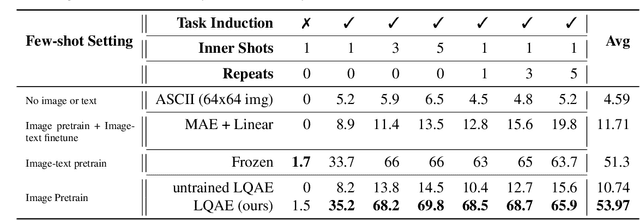
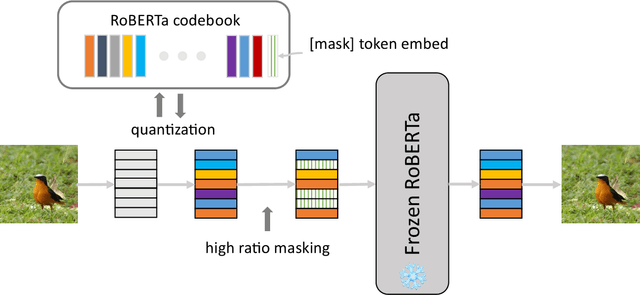
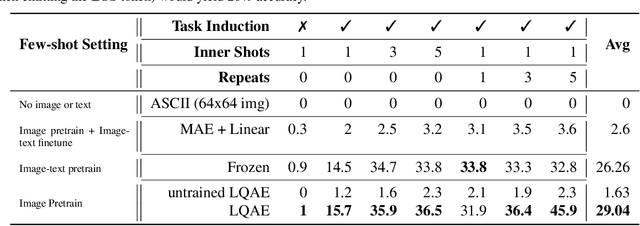
Recent progress in scaling up large language models has shown impressive capabilities in performing few-shot learning across a wide range of text-based tasks. However, a key limitation is that these language models fundamentally lack visual perception - a crucial attribute needed to extend these models to be able to interact with the real world and solve vision tasks, such as in visual-question answering and robotics. Prior works have largely connected image to text through pretraining and/or fine-tuning on curated image-text datasets, which can be a costly and expensive process. In order to resolve this limitation, we propose a simple yet effective approach called Language-Quantized AutoEncoder (LQAE), a modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa). Our main idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained language codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings. By doing so, LQAE learns to represent similar images with similar clusters of text tokens, thereby aligning these two modalities without the use of aligned text-image pairs. This enables few-shot image classification with large language models (e.g., GPT-3) as well as linear classification of images based on BERT text features. To the best of our knowledge, our work is the first work that uses unaligned images for multimodal tasks by leveraging the power of pretrained language models.
BayeSeg: Bayesian Modeling for Medical Image Segmentation with Interpretable Generalizability
Mar 03, 2023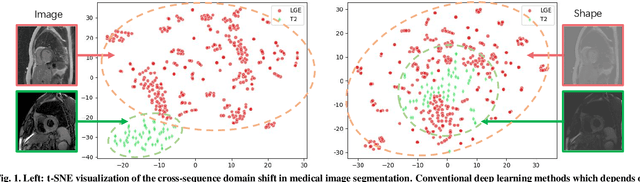
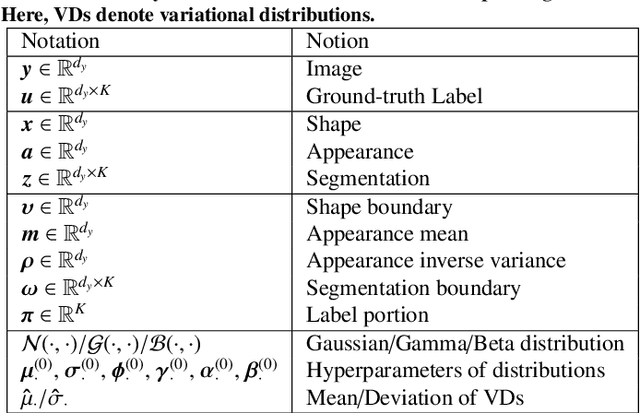
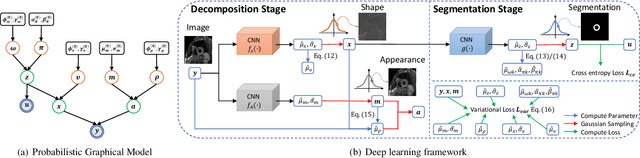

Due to the cross-domain distribution shift aroused from diverse medical imaging systems, many deep learning segmentation methods fail to perform well on unseen data, which limits their real-world applicability. Recent works have shown the benefits of extracting domain-invariant representations on domain generalization. However, the interpretability of domain-invariant features remains a great challenge. To address this problem, we propose an interpretable Bayesian framework (BayeSeg) through Bayesian modeling of image and label statistics to enhance model generalizability for medical image segmentation. Specifically, we first decompose an image into a spatial-correlated variable and a spatial-variant variable, assigning hierarchical Bayesian priors to explicitly force them to model the domain-stable shape and domain-specific appearance information respectively. Then, we model the segmentation as a locally smooth variable only related to the shape. Finally, we develop a variational Bayesian framework to infer the posterior distributions of these explainable variables. The framework is implemented with neural networks, and thus is referred to as deep Bayesian segmentation. Quantitative and qualitative experimental results on prostate segmentation and cardiac segmentation tasks have shown the effectiveness of our proposed method. Moreover, we investigated the interpretability of BayeSeg by explaining the posteriors and analyzed certain factors that affect the generalization ability through further ablation studies. Our code will be released via https://zmiclab.github.io/projects.html, once the manuscript is accepted for publication.
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023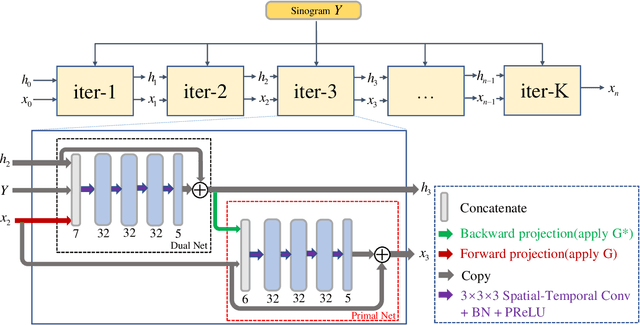
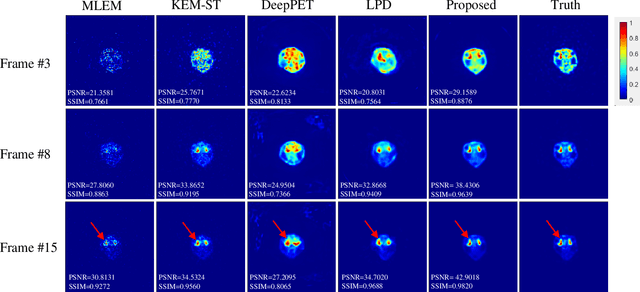
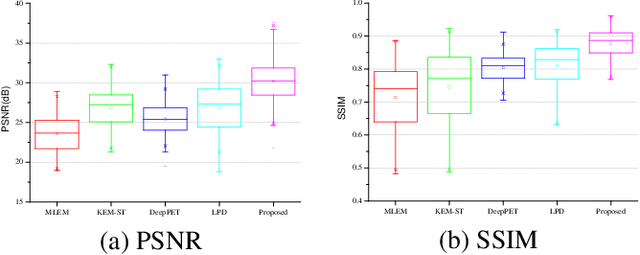
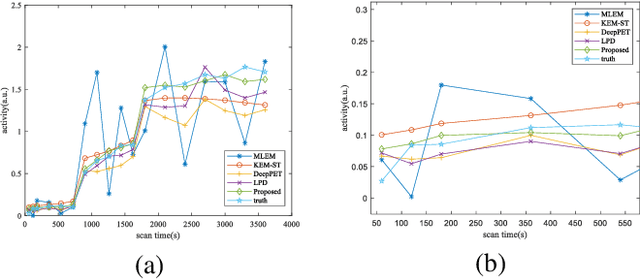
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
Toward DNN of LUTs: Learning Efficient Image Restoration with Multiple Look-Up Tables
Mar 25, 2023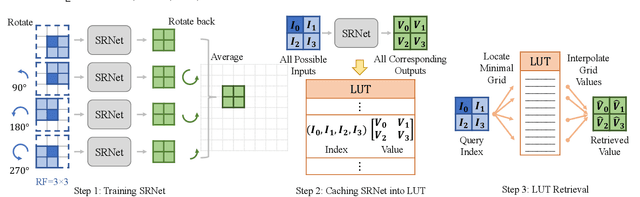

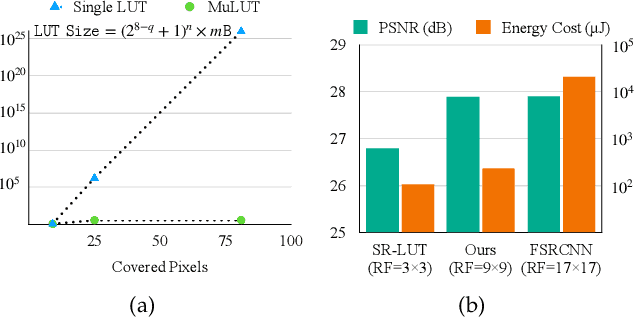
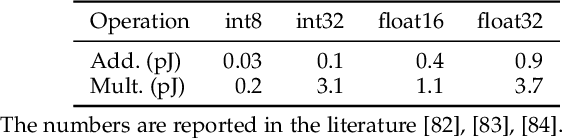
The widespread usage of high-definition screens on edge devices stimulates a strong demand for efficient image restoration algorithms. The way of caching deep learning models in a look-up table (LUT) is recently introduced to respond to this demand. However, the size of a single LUT grows exponentially with the increase of its indexing capacity, which restricts its receptive field and thus the performance. To overcome this intrinsic limitation of the single-LUT solution, we propose a universal method to construct multiple LUTs like a neural network, termed MuLUT. Firstly, we devise novel complementary indexing patterns, as well as a general implementation for arbitrary patterns, to construct multiple LUTs in parallel. Secondly, we propose a re-indexing mechanism to enable hierarchical indexing between cascaded LUTs. Finally, we introduce channel indexing to allow cross-channel interaction, enabling LUTs to process color channels jointly. In these principled ways, the total size of MuLUT is linear to its indexing capacity, yielding a practical solution to obtain superior performance with the enlarged receptive field. We examine the advantage of MuLUT on various image restoration tasks, including super-resolution, demosaicing, denoising, and deblocking. MuLUT achieves a significant improvement over the single-LUT solution, e.g., up to 1.1dB PSNR for super-resolution and up to 2.8dB PSNR for grayscale denoising, while preserving its efficiency, which is 100$\times$ less in energy cost compared with lightweight deep neural networks. Our code and trained models are publicly available at https://github.com/ddlee-cn/MuLUT.
Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling
May 26, 2023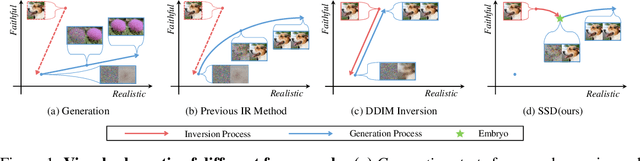
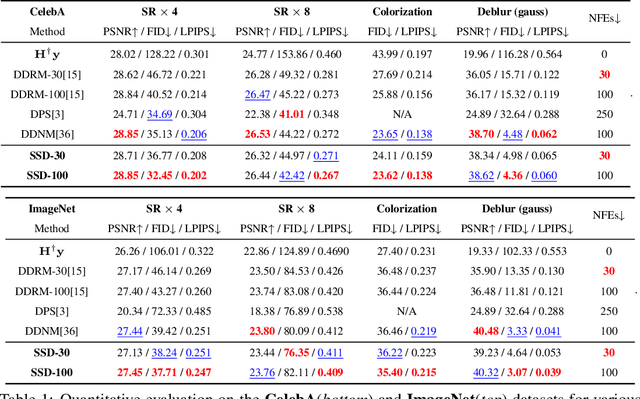
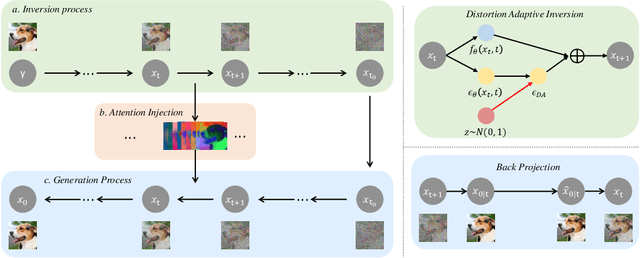

Recently, diffusion models have demonstrated a remarkable ability to solve inverse problems in an unsupervised manner. Existing methods mainly focus on modifying the posterior sampling process while neglecting the potential of the forward process. In this work, we propose Shortcut Sampling for Diffusion (SSD), a novel pipeline for solving inverse problems. Instead of initiating from random noise, the key concept of SSD is to find the "Embryo", a transitional state that bridges the measurement image y and the restored image x. By utilizing the "shortcut" path of "input-Embryo-output", SSD can achieve precise and fast restoration. To obtain the Embryo in the forward process, We propose Distortion Adaptive Inversion (DA Inversion). Moreover, we apply back projection and attention injection as additional consistency constraints during the generation process. Experimentally, we demonstrate the effectiveness of SSD on several representative tasks, including super-resolution, deblurring, and colorization. Compared to state-of-the-art zero-shot methods, our method achieves competitive results with only 30 NFEs. Moreover, SSD with 100 NFEs can outperform state-of-the-art zero-shot methods in certain tasks.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023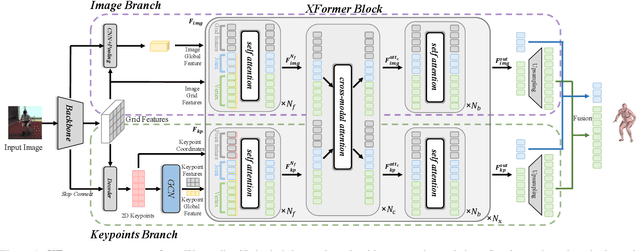
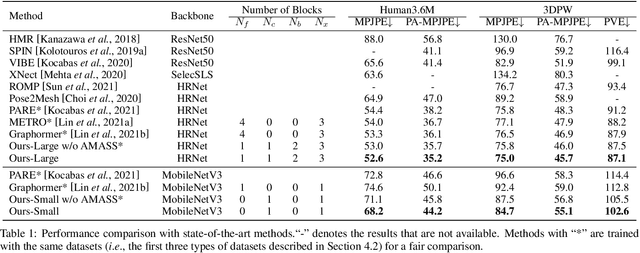
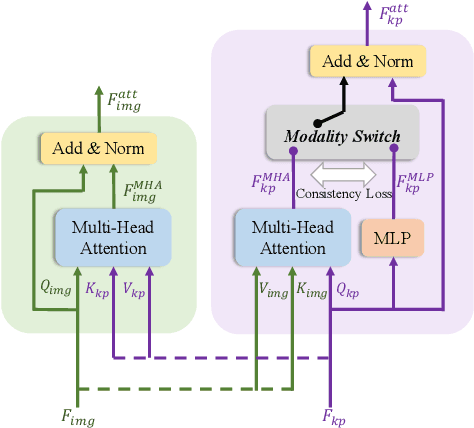
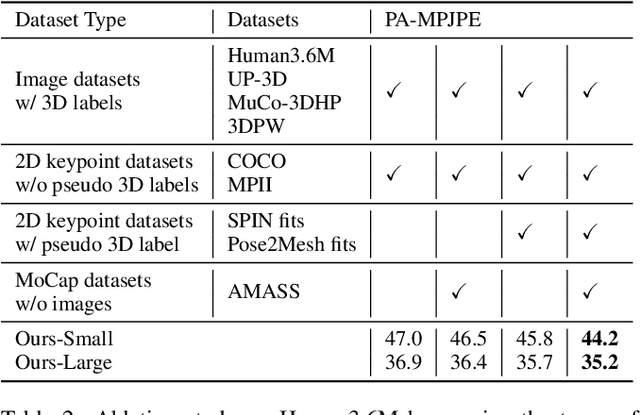
We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Weakly Supervised Visual Question Answer Generation
Jun 11, 2023
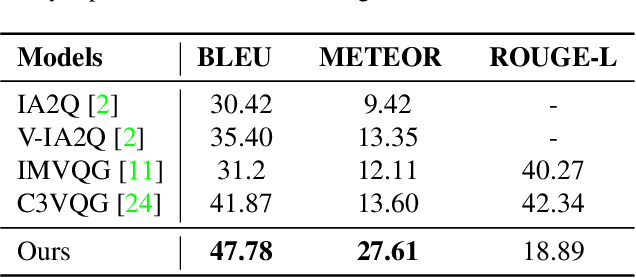
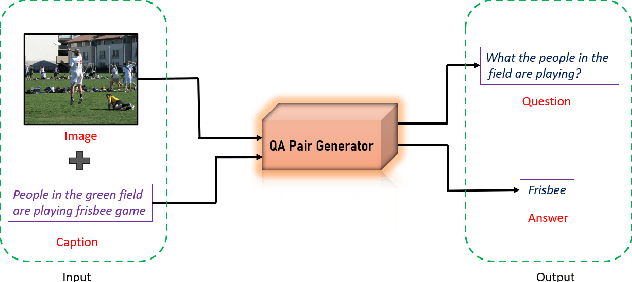

Growing interest in conversational agents promote twoway human-computer communications involving asking and answering visual questions have become an active area of research in AI. Thus, generation of visual questionanswer pair(s) becomes an important and challenging task. To address this issue, we propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. Most of the prior works are supervised and depend on the annotated question-answer datasets. In our work, we present a weakly supervised method that synthetically generates question-answer pairs procedurally from visual information and captions. The proposed method initially extracts list of answer words, then does nearest question generation that uses the caption and answer word to generate synthetic question. Next, the relevant question generator converts the nearest question to relevant language question by dependency parsing and in-order tree traversal, finally, fine-tune a ViLBERT model with the question-answer pair(s) generated at end. We perform an exhaustive experimental analysis on VQA dataset and see that our model significantly outperform SOTA methods on BLEU scores. We also show the results wrt baseline models and ablation study.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
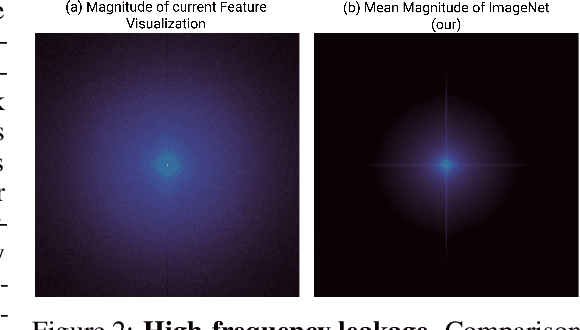
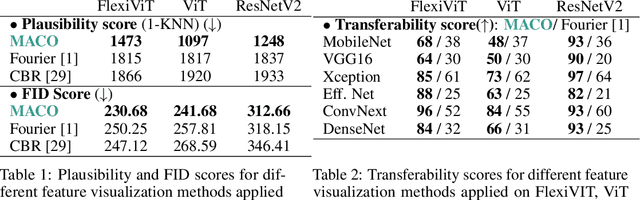
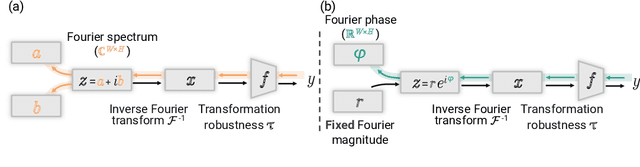
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
Multi-modal Representation Learning for Social Post Location Inference
Jun 11, 2023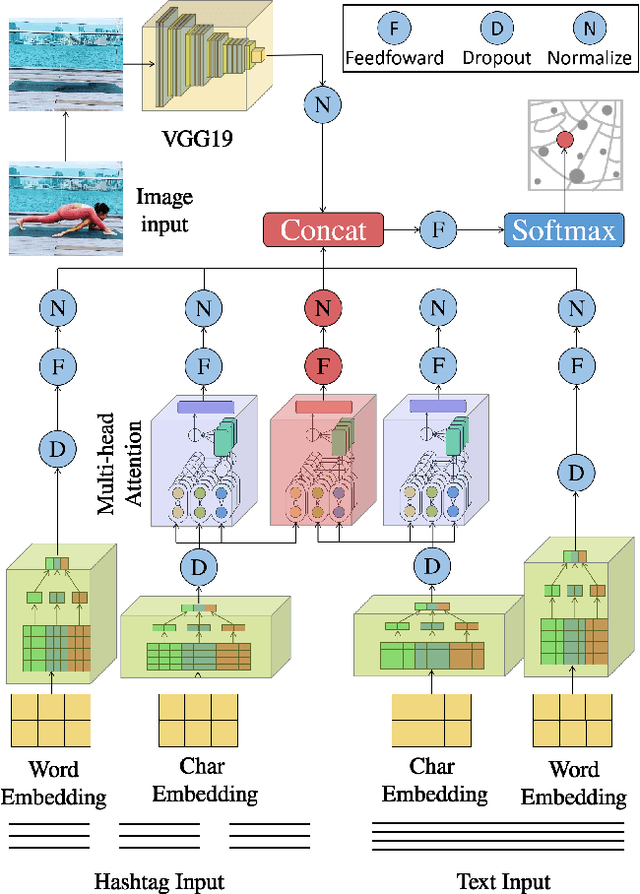
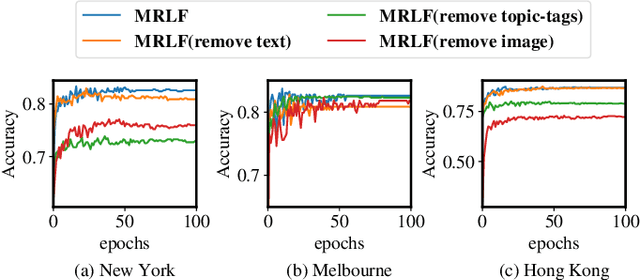
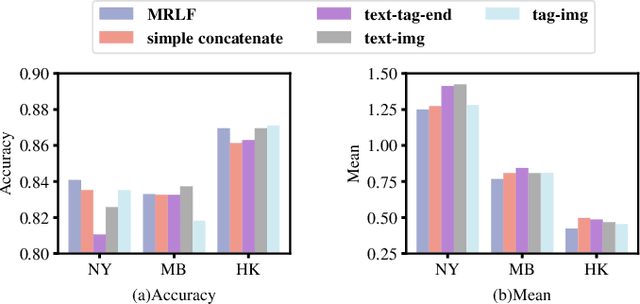
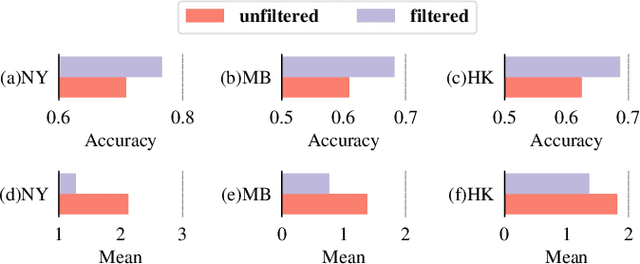
Inferring geographic locations via social posts is essential for many practical location-based applications such as product marketing, point-of-interest recommendation, and infector tracking for COVID-19. Unlike image-based location retrieval or social-post text embedding-based location inference, the combined effect of multi-modal information (i.e., post images, text, and hashtags) for social post positioning receives less attention. In this work, we collect real datasets of social posts with images, texts, and hashtags from Instagram and propose a novel Multi-modal Representation Learning Framework (MRLF) capable of fusing different modalities of social posts for location inference. MRLF integrates a multi-head attention mechanism to enhance location-salient information extraction while significantly improving location inference compared with single domain-based methods. To overcome the noisy user-generated textual content, we introduce a novel attention-based character-aware module that considers the relative dependencies between characters of social post texts and hashtags for flexible multi-model information fusion. The experimental results show that MRLF can make accurate location predictions and open a new door to understanding the multi-modal data of social posts for online inference tasks.
$PC^2$: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction
Feb 21, 2023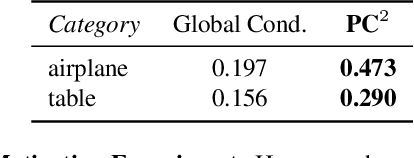
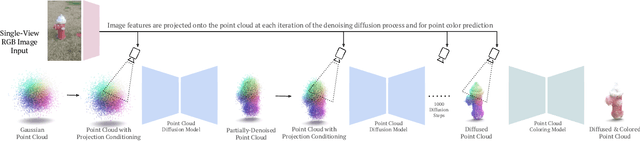
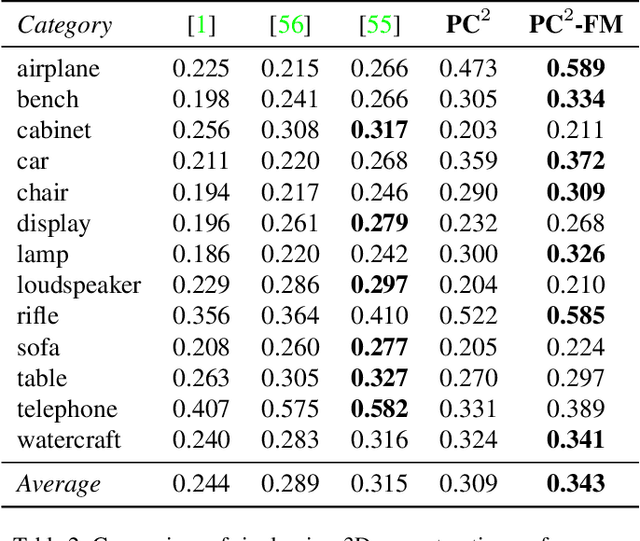
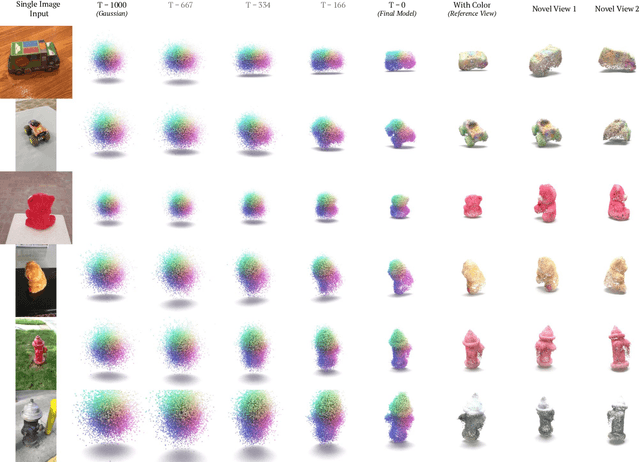
Reconstructing the 3D shape of an object from a single RGB image is a long-standing and highly challenging problem in computer vision. In this paper, we propose a novel method for single-image 3D reconstruction which generates a sparse point cloud via a conditional denoising diffusion process. Our method takes as input a single RGB image along with its camera pose and gradually denoises a set of 3D points, whose positions are initially sampled randomly from a three-dimensional Gaussian distribution, into the shape of an object. The key to our method is a geometrically-consistent conditioning process which we call projection conditioning: at each step in the diffusion process, we project local image features onto the partially-denoised point cloud from the given camera pose. This projection conditioning process enables us to generate high-resolution sparse geometries that are well-aligned with the input image, and can additionally be used to predict point colors after shape reconstruction. Moreover, due to the probabilistic nature of the diffusion process, our method is naturally capable of generating multiple different shapes consistent with a single input image. In contrast to prior work, our approach not only performs well on synthetic benchmarks, but also gives large qualitative improvements on complex real-world data.