 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Differentially Private Cross-camera Person Re-identification
Jun 05, 2023
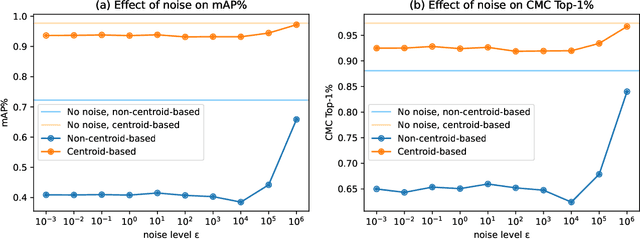
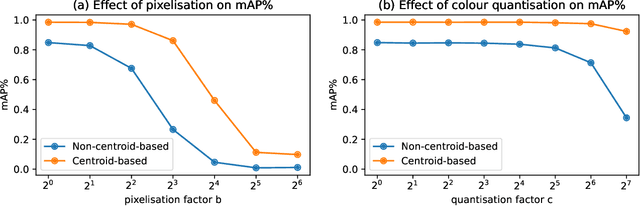
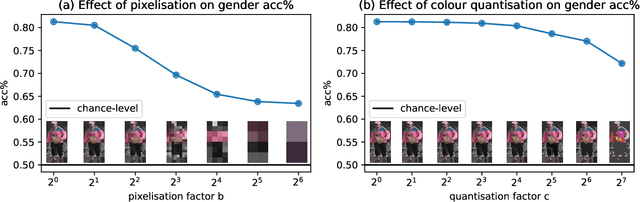
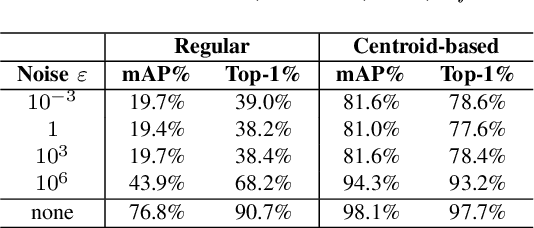
Camera-based person re-identification is a heavily privacy-invading task by design, benefiting from rich visual data to match together person representations across different cameras. This high-dimensional data can then easily be used for other, perhaps less desirable, applications. We here investigate the possibility of protecting such image data against uses outside of the intended re-identification task, and introduce a differential privacy mechanism leveraging both pixelisation and colour quantisation for this purpose. We show its ability to distort images in such a way that adverse task performances are significantly reduced, while retaining high re-identification performances.
Exploring Semantic Variations in GAN Latent Spaces via Matrix Factorization
May 23, 2023



Controlled data generation with GANs is desirable but challenging due to the nonlinearity and high dimensionality of their latent spaces. In this work, we explore image manipulations learned by GANSpace, a state-of-the-art method based on PCA. Through quantitative and qualitative assessments we show: (a) GANSpace produces a wide range of high-quality image manipulations, but they can be highly entangled, limiting potential use cases; (b) Replacing PCA with ICA improves the quality and disentanglement of manipulations; (c) The quality of the generated images can be sensitive to the size of GANs, but regardless of their complexity, fundamental controlling directions can be observed in their latent spaces.
User-defined Event Sampling and Uncertainty Quantification in Diffusion Models for Physical Dynamical Systems
Jun 13, 2023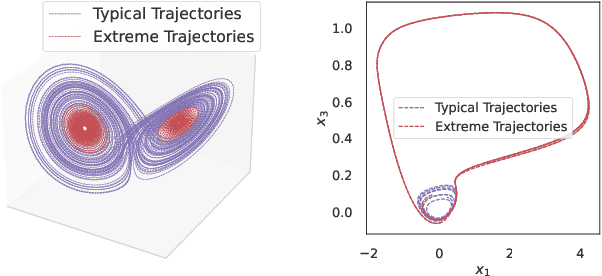
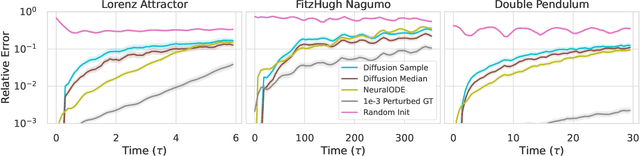
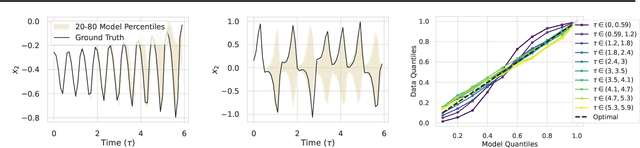
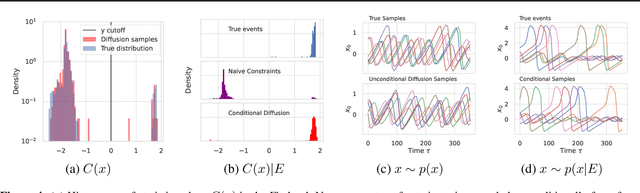
Diffusion models are a class of probabilistic generative models that have been widely used as a prior for image processing tasks like text conditional generation and inpainting. We demonstrate that these models can be adapted to make predictions and provide uncertainty quantification for chaotic dynamical systems. In these applications, diffusion models can implicitly represent knowledge about outliers and extreme events; however, querying that knowledge through conditional sampling or measuring probabilities is surprisingly difficult. Existing methods for conditional sampling at inference time seek mainly to enforce the constraints, which is insufficient to match the statistics of the distribution or compute the probability of the chosen events. To achieve these ends, optimally one would use the conditional score function, but its computation is typically intractable. In this work, we develop a probabilistic approximation scheme for the conditional score function which provably converges to the true distribution as the noise level decreases. With this scheme we are able to sample conditionally on nonlinear userdefined events at inference time, and matches data statistics even when sampling from the tails of the distribution.
Deep Learning Methods for Retinal Blood Vessel Segmentation: Evaluation on Images with Retinopathy of Prematurity
Jun 20, 2023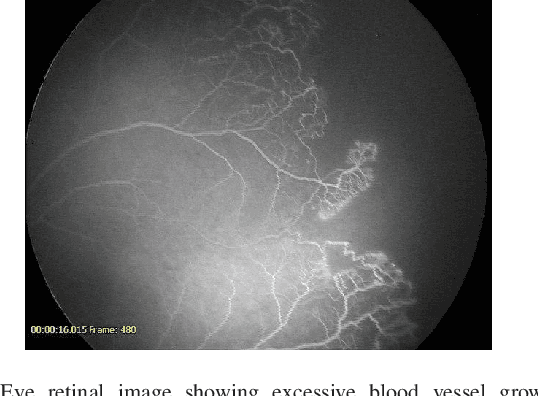
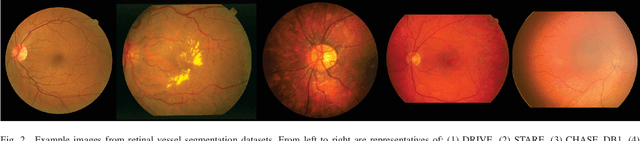
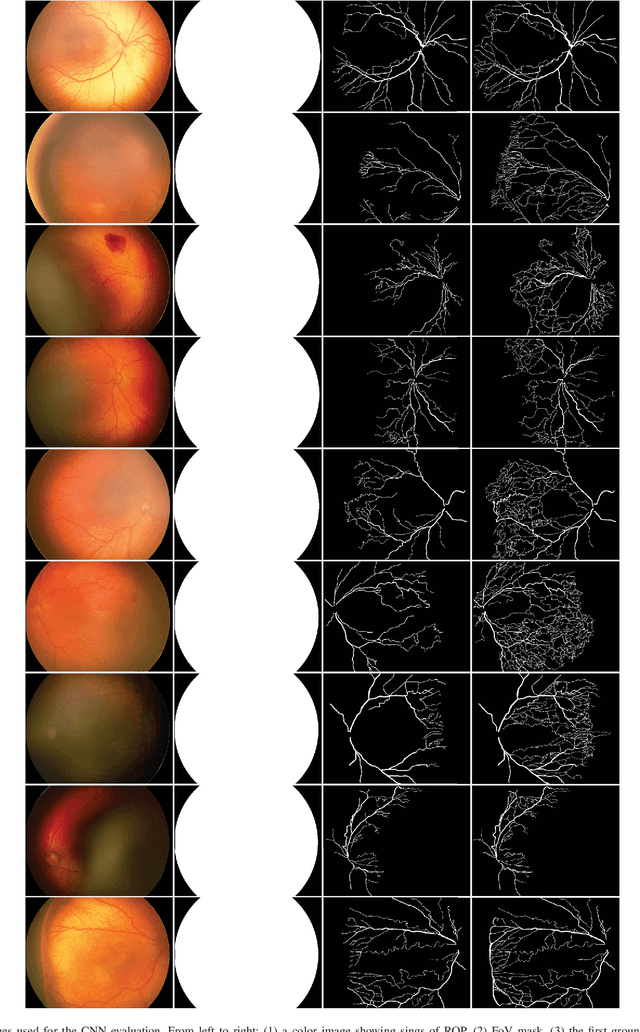
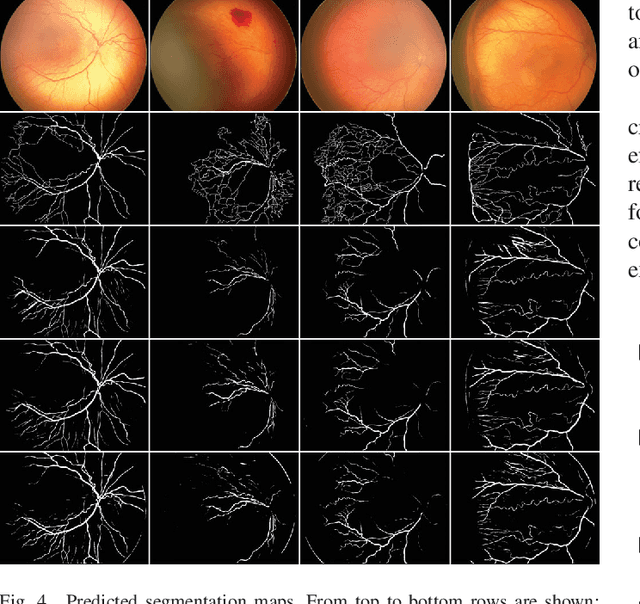
Automatic blood vessel segmentation from retinal images plays an important role in the diagnosis of many systemic and eye diseases, including retinopathy of prematurity. Current state-of-the-art research in blood vessel segmentation from retinal images is based on convolutional neural networks. The solutions proposed so far are trained and tested on images from a few available retinal blood vessel segmentation datasets, which might limit their performance when given an image with retinopathy of prematurity signs. In this paper, we evaluate the performance of three high-performing convolutional neural networks for retinal blood vessel segmentation in the context of blood vessel segmentation on retinopathy of prematurity retinal images. The main motive behind the study is to test if existing public datasets suffice to develop a high-performing predictor that could assist an ophthalmologist in retinopathy of prematurity diagnosis. To do so, we create a dataset consisting solely of retinopathy of prematurity images with retinal blood vessel annotations manually labeled by two observers, where one is the ophthalmologist experienced in retinopathy of prematurity treatment. Experimental results show that all three solutions have difficulties in detecting the retinal blood vessels of infants due to a lower contrast compared to images from public datasets as demonstrated by a significant drop in classification sensitivity. All three solutions segment alongside retinal also choroidal blood vessels which are not used to diagnose retinopathy of prematurity, but instead represent noise and are confused with retinal blood vessels. By visual and numerical observations, we observe that existing solutions for retinal blood vessel segmentation need improvement toward more detailed datasets or deeper models in order to assist the ophthalmologist in retinopathy of prematurity diagnosis.
Semantic Segmentation on VSPW Dataset through Contrastive Loss and Multi-dataset Training Approach
Jun 06, 2023
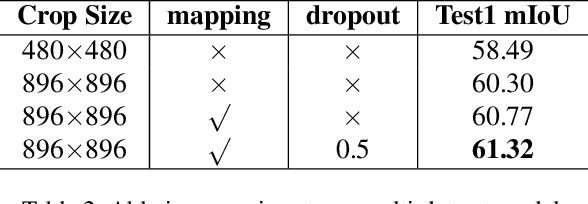
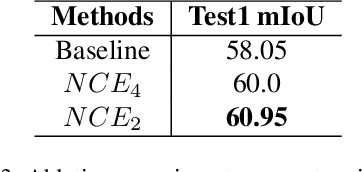
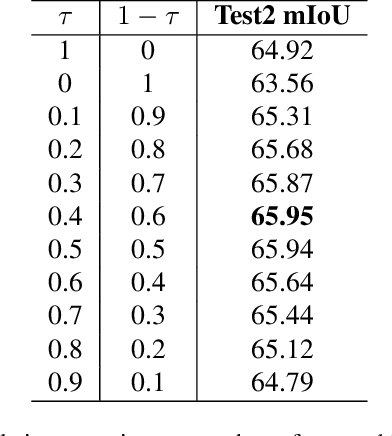
Video scene parsing incorporates temporal information, which can enhance the consistency and accuracy of predictions compared to image scene parsing. The added temporal dimension enables a more comprehensive understanding of the scene, leading to more reliable results. This paper presents the winning solution of the CVPR2023 workshop for video semantic segmentation, focusing on enhancing Spatial-Temporal correlations with contrastive loss. We also explore the influence of multi-dataset training by utilizing a label-mapping technique. And the final result is aggregating the output of the above two models. Our approach achieves 65.95% mIoU performance on the VSPW dataset, ranked 1st place on the VSPW challenge at CVPR 2023.
3rd Place Solution for PVUW2023 VSS Track: A Large Model for Semantic Segmentation on VSPW
Jun 06, 2023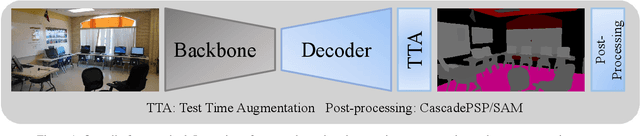
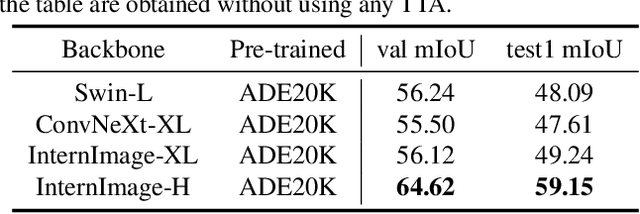


In this paper, we introduce 3rd place solution for PVUW2023 VSS track. Semantic segmentation is a fundamental task in computer vision with numerous real-world applications. We have explored various image-level visual backbones and segmentation heads to tackle the problem of video semantic segmentation. Through our experimentation, we find that InternImage-H as the backbone and Mask2former as the segmentation head achieves the best performance. In addition, we explore two post-precessing methods: CascadePSP and Segment Anything Model (SAM). Ultimately, our approach obtains 62.60\% and 64.84\% mIoU on the VSPW test set1 and final test set, respectively, securing the third position in the PVUW2023 VSS track.
Hyperbolic Active Learning for Semantic Segmentation under Domain Shift
Jun 19, 2023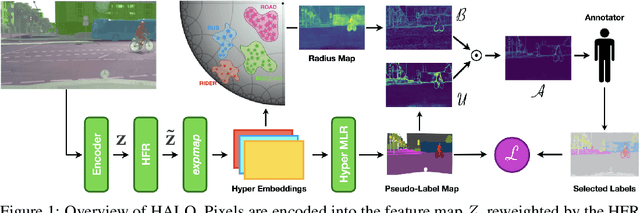
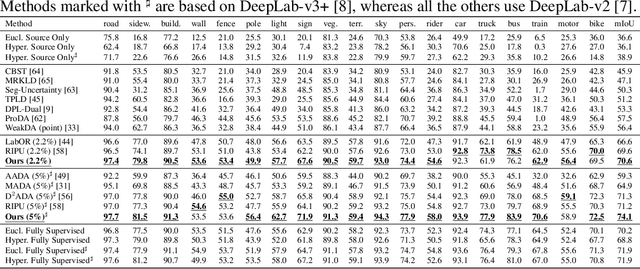
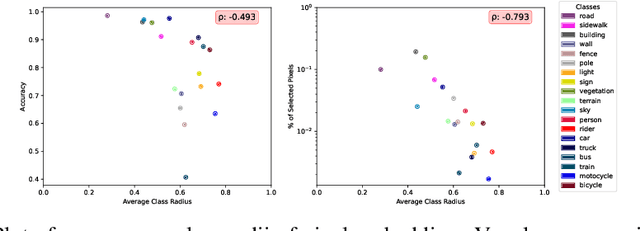

For the task of semantic segmentation (SS) under domain shift, active learning (AL) acquisition strategies based on image regions and pseudo labels are state-of-the-art (SoA). The presence of diverse pseudo-labels within a region identifies pixels between different classes, which is a labeling efficient active learning data acquisition strategy. However, by design, pseudo-label variations are limited to only select the contours of classes, limiting the final AL performance. We approach AL for SS in the Poincar\'e hyperbolic ball model for the first time and leverage the variations of the radii of pixel embeddings within regions as a novel data acquisition strategy. This stems from a novel geometric property of a hyperbolic space trained without enforced hierarchies, which we experimentally prove. Namely, classes are mapped into compact hyperbolic areas with a comparable intra-class radii variance, as the model places classes of increasing explainable difficulty at denser hyperbolic areas, i.e. closer to the Poincar\'e ball edge. The variation of pixel embedding radii identifies well the class contours, but they also select a few intra-class peculiar details, which boosts the final performance. Our proposed HALO (Hyperbolic Active Learning Optimization) surpasses the supervised learning performance for the first time in AL for SS under domain shift, by only using a small portion of labels (i.e., 1%). The extensive experimental analysis is based on two established benchmarks, i.e. GTAV $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes, where we set a new SoA. The code will be released.
Detailed retinal vessel segmentation without human annotations using simulated optical coherence tomography angiographs
Jun 19, 2023Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that can acquire high-resolution volumes of the retinal vasculature and aid the diagnosis of ocular, neurological and cardiac diseases. Segmentation of the visible blood vessels is a common first step when extracting quantitative biomarkers from these images. Classical segmentation algorithms based on thresholding are strongly affected by image artifacts and limited signal-to-noise ratio. The use of modern, deep learning-based segmentation methods has been inhibited by a lack of large datasets with detailed annotations of the blood vessels. To address this issue, recent work has employed transfer learning, where a segmentation network is trained on synthetic OCTA images and is then applied to real data. However, the previously proposed simulation models are incapable of faithfully modeling the retinal vasculature and do not provide effective domain adaptation. Because of this, current methods are not able to fully segment the retinal vasculature, in particular the smallest capillaries. In this work, we present a lightweight simulation of the retinal vascular network based on space colonization for faster and more realistic OCTA synthesis. Moreover, we introduce three contrast adaptation pipelines to decrease the domain gap between real and artificial images. We demonstrate the superior performance of our approach in extensive quantitative and qualitative experiments on three public datasets that compare our method to traditional computer vision algorithms and supervised training using human annotations. Finally, we make our entire pipeline publicly available, including the source code, pretrained models, and a large dataset of synthetic OCTA images.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023
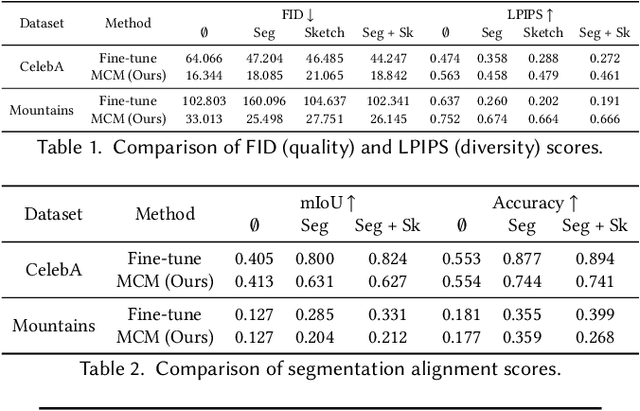
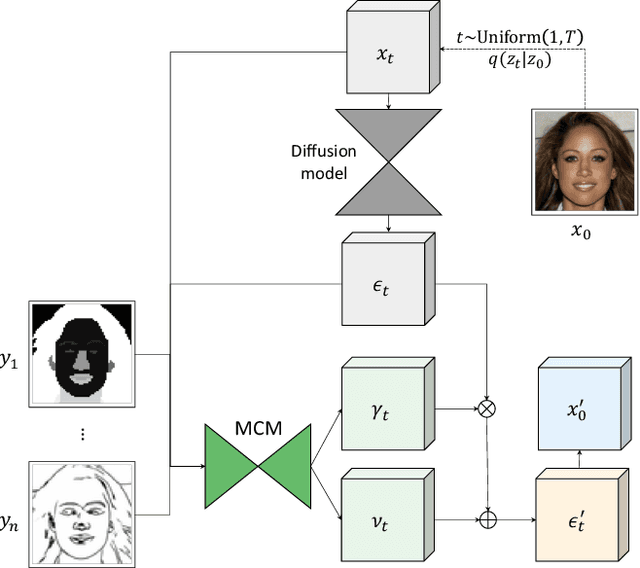
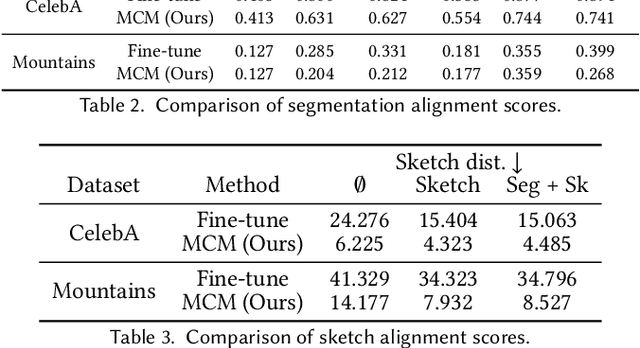
We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
What makes a good data augmentation for few-shot unsupervised image anomaly detection?
Apr 06, 2023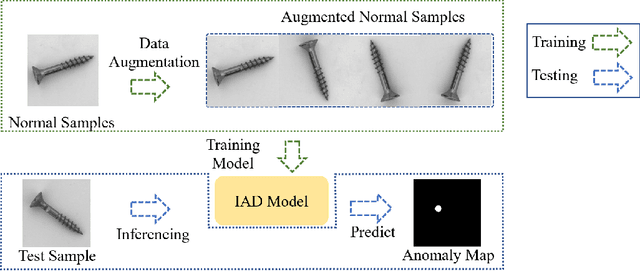

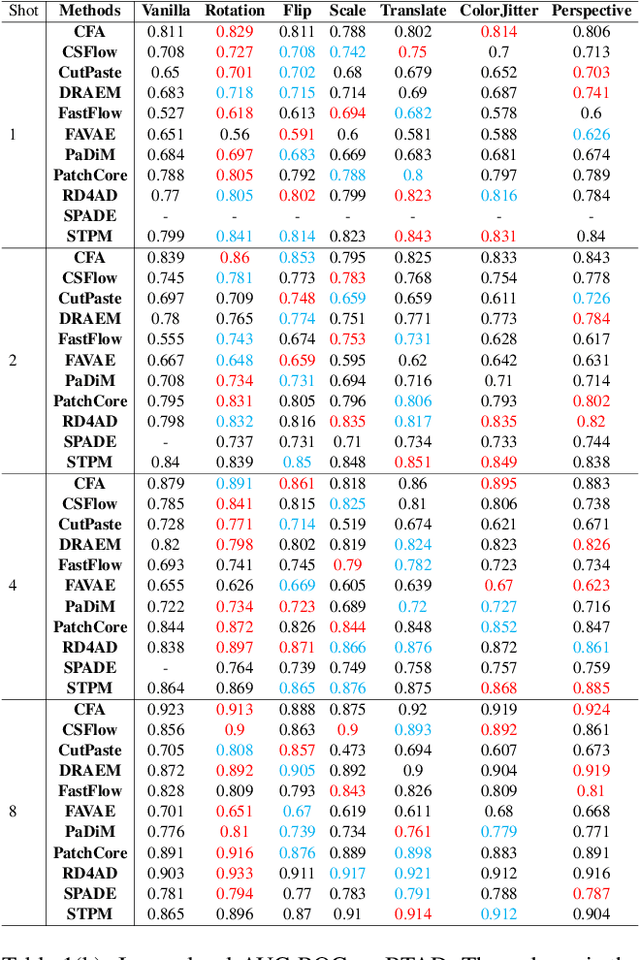
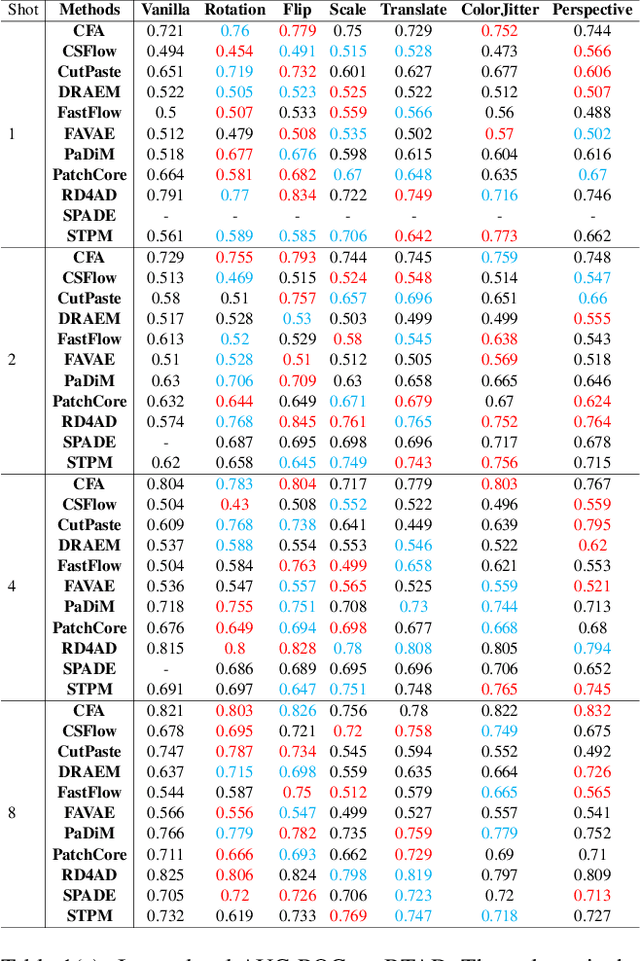
Data augmentation is a promising technique for unsupervised anomaly detection in industrial applications, where the availability of positive samples is often limited due to factors such as commercial competition and sample collection difficulties. In this paper, how to effectively select and apply data augmentation methods for unsupervised anomaly detection is studied. The impact of various data augmentation methods on different anomaly detection algorithms is systematically investigated through experiments. The experimental results show that the performance of different industrial image anomaly detection (termed as IAD) algorithms is not significantly affected by the specific data augmentation method employed and that combining multiple data augmentation methods does not necessarily yield further improvements in the accuracy of anomaly detection, although it can achieve excellent results on specific methods. These findings provide useful guidance on selecting appropriate data augmentation methods for different requirements in IAD.