 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023
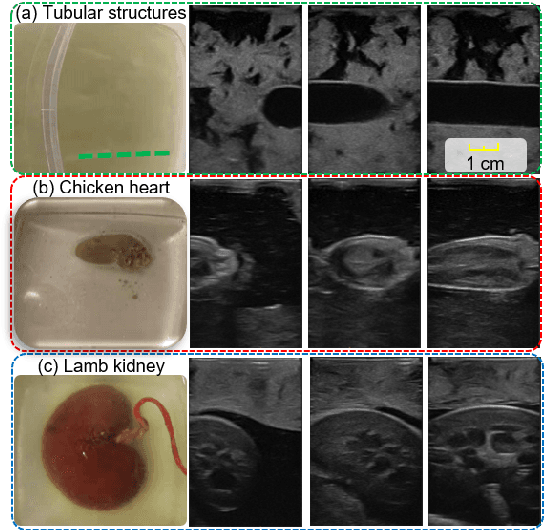
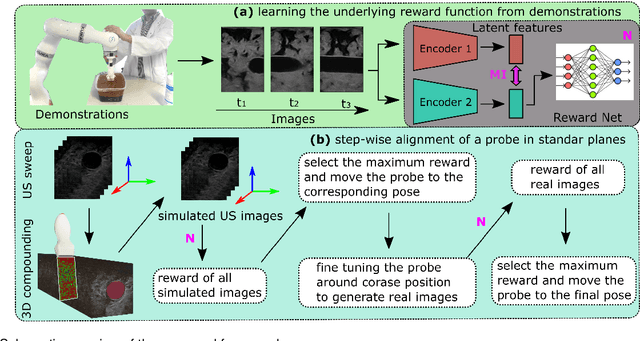
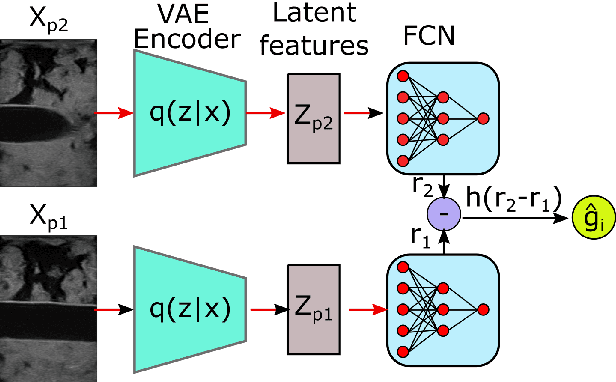
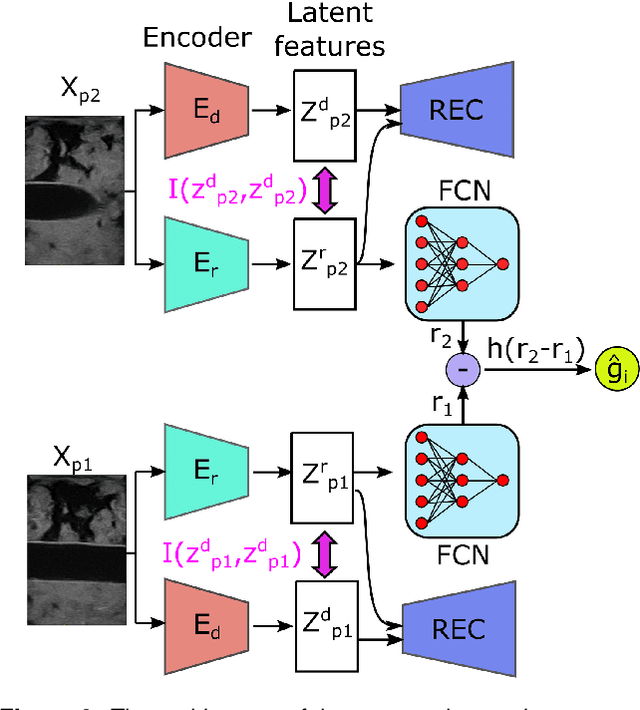
Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
Language-free Compositional Action Generation via Decoupling Refinement
Jul 07, 2023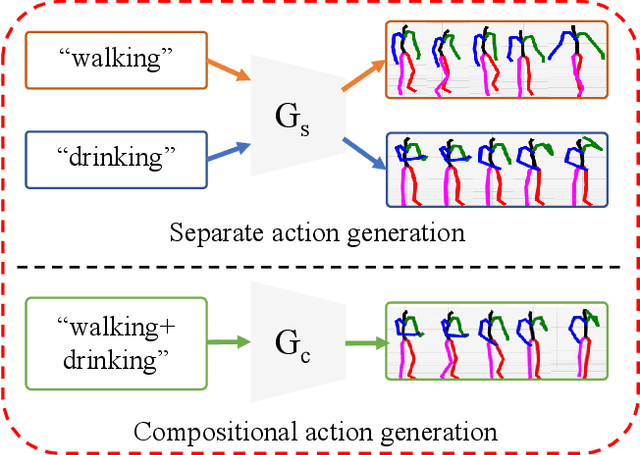

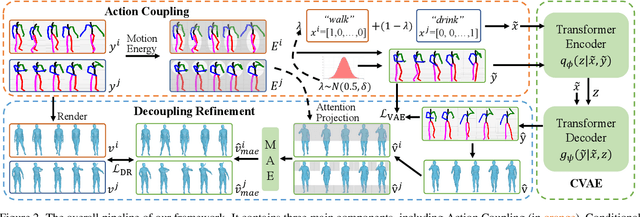
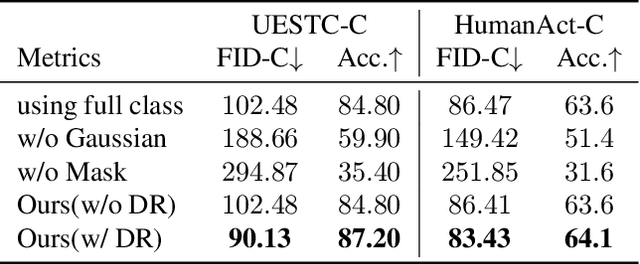
Composing simple elements into complex concepts is crucial yet challenging, especially for 3D action generation. Existing methods largely rely on extensive neural language annotations to discern composable latent semantics, a process that is often costly and labor-intensive. In this study, we introduce a novel framework to generate compositional actions without reliance on language auxiliaries. Our approach consists of three main components: Action Coupling, Conditional Action Generation, and Decoupling Refinement. Action Coupling utilizes an energy model to extract the attention masks of each sub-action, subsequently integrating two actions using these attentions to generate pseudo-training examples. Then, we employ a conditional generative model, CVAE, to learn a latent space, facilitating the diverse generation. Finally, we propose Decoupling Refinement, which leverages a self-supervised pre-trained model MAE to ensure semantic consistency between the sub-actions and compositional actions. This refinement process involves rendering generated 3D actions into 2D space, decoupling these images into two sub-segments, using the MAE model to restore the complete image from sub-segments, and constraining the recovered images to match images rendered from raw sub-actions. Due to the lack of existing datasets containing both sub-actions and compositional actions, we created two new datasets, named HumanAct-C and UESTC-C, and present a corresponding evaluation metric. Both qualitative and quantitative assessments are conducted to show our efficacy.
Equivariant Single View Pose Prediction Via Induced and Restricted Representations
Jul 07, 2023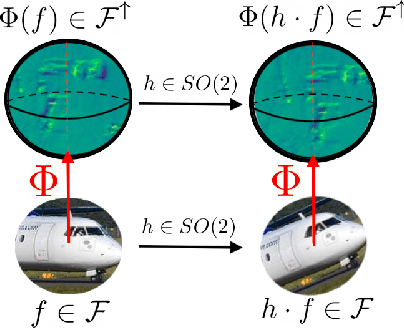
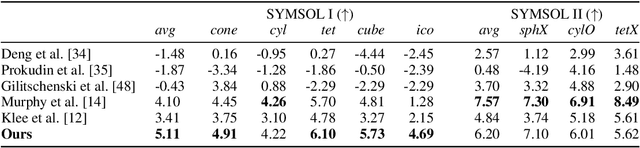
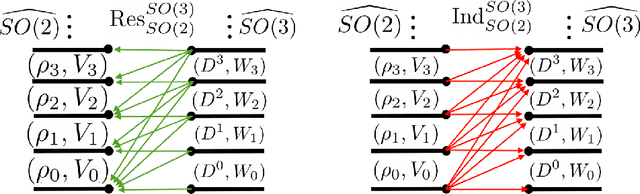

Learning about the three-dimensional world from two-dimensional images is a fundamental problem in computer vision. An ideal neural network architecture for such tasks would leverage the fact that objects can be rotated and translated in three dimensions to make predictions about novel images. However, imposing SO(3)-equivariance on two-dimensional inputs is difficult because the group of three-dimensional rotations does not have a natural action on the two-dimensional plane. Specifically, it is possible that an element of SO(3) will rotate an image out of plane. We show that an algorithm that learns a three-dimensional representation of the world from two dimensional images must satisfy certain geometric consistency properties which we formulate as SO(2)-equivariance constraints. We use the induced and restricted representations of SO(2) on SO(3) to construct and classify architectures which satisfy these geometric consistency constraints. We prove that any architecture which respects said consistency constraints can be realized as an instance of our construction. We show that three previously proposed neural architectures for 3D pose prediction are special cases of our construction. We propose a new algorithm that is a learnable generalization of previously considered methods. We test our architecture on three pose predictions task and achieve SOTA results on both the PASCAL3D+ and SYMSOL pose estimation tasks.
Robotic Ultrasound Imaging: State-of-the-Art and Future Perspectives
Jul 08, 2023
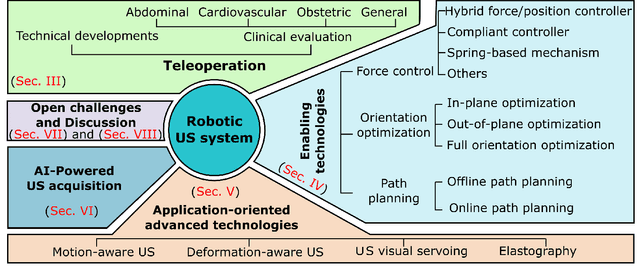
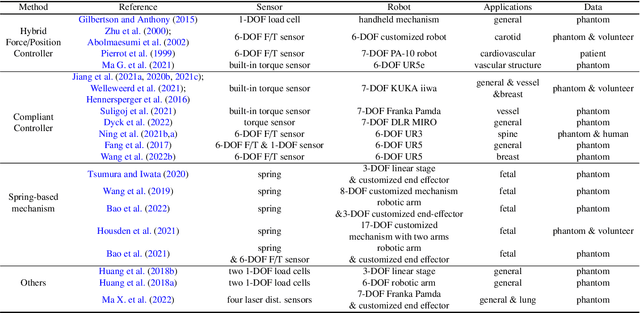
Ultrasound (US) is one of the most widely used modalities for clinical intervention and diagnosis due to the merits of providing non-invasive, radiation-free, and real-time images. However, free-hand US examinations are highly operator-dependent. Robotic US System (RUSS) aims at overcoming this shortcoming by offering reproducibility, while also aiming at improving dexterity, and intelligent anatomy and disease-aware imaging. In addition to enhancing diagnostic outcomes, RUSS also holds the potential to provide medical interventions for populations suffering from the shortage of experienced sonographers. In this paper, we categorize RUSS as teleoperated or autonomous. Regarding teleoperated RUSS, we summarize their technical developments, and clinical evaluations, respectively. This survey then focuses on the review of recent work on autonomous robotic US imaging. We demonstrate that machine learning and artificial intelligence present the key techniques, which enable intelligent patient and process-specific, motion and deformation-aware robotic image acquisition. We also show that the research on artificial intelligence for autonomous RUSS has directed the research community toward understanding and modeling expert sonographers' semantic reasoning and action. Here, we call this process, the recovery of the "language of sonography". This side result of research on autonomous robotic US acquisitions could be considered as valuable and essential as the progress made in the robotic US examination itself. This article will provide both engineers and clinicians with a comprehensive understanding of RUSS by surveying underlying techniques.
End-to-End Supervised Multilabel Contrastive Learning
Jul 08, 2023
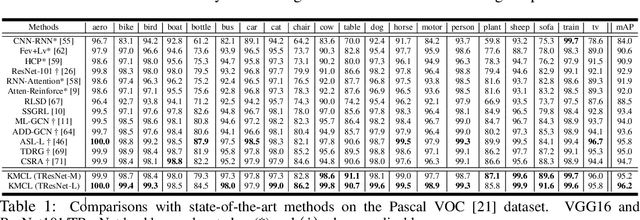
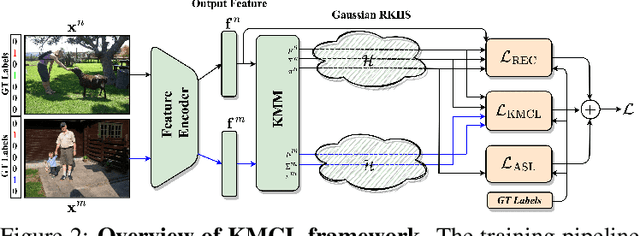

Multilabel representation learning is recognized as a challenging problem that can be associated with either label dependencies between object categories or data-related issues such as the inherent imbalance of positive/negative samples. Recent advances address these challenges from model- and data-centric viewpoints. In model-centric, the label correlation is obtained by an external model designs (e.g., graph CNN) to incorporate an inductive bias for training. However, they fail to design an end-to-end training framework, leading to high computational complexity. On the contrary, in data-centric, the realistic nature of the dataset is considered for improving the classification while ignoring the label dependencies. In this paper, we propose a new end-to-end training framework -- dubbed KMCL (Kernel-based Mutlilabel Contrastive Learning) -- to address the shortcomings of both model- and data-centric designs. The KMCL first transforms the embedded features into a mixture of exponential kernels in Gaussian RKHS. It is then followed by encoding an objective loss that is comprised of (a) reconstruction loss to reconstruct kernel representation, (b) asymmetric classification loss to address the inherent imbalance problem, and (c) contrastive loss to capture label correlation. The KMCL models the uncertainty of the feature encoder while maintaining a low computational footprint. Extensive experiments are conducted on image classification tasks to showcase the consistent improvements of KMCL over the SOTA methods. PyTorch implementation is provided in \url{https://github.com/mahdihosseini/KMCL}.
Fraunhofer SIT at CheckThat! 2023: Mixing Single-Modal Classifiers to Estimate the Check-Worthiness of Multi-Modal Tweets
Jul 02, 2023The option of sharing images, videos and audio files on social media opens up new possibilities for distinguishing between false information and fake news on the Internet. Due to the vast amount of data shared every second on social media, not all data can be verified by a computer or a human expert. Here, a check-worthiness analysis can be used as a first step in the fact-checking pipeline and as a filtering mechanism to improve efficiency. This paper proposes a novel way of detecting the check-worthiness in multi-modal tweets. It takes advantage of two classifiers, each trained on a single modality. For image data, extracting the embedded text with an OCR analysis has shown to perform best. By combining the two classifiers, the proposed solution was able to place first in the CheckThat! 2023 Task 1A with an F1 score of 0.7297 achieved on the private test set.
* 8 pages
The Forward-Forward Algorithm as a feature extractor for skin lesion classification: A preliminary study
Jul 02, 2023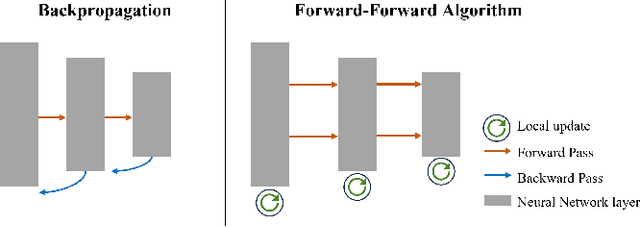
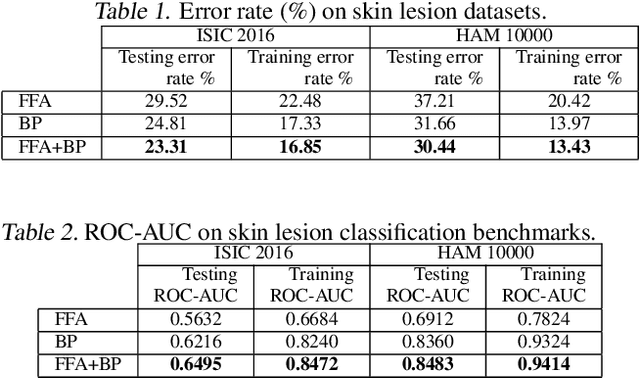
Skin cancer, a deadly form of cancer, exhibits a 23\% survival rate in the USA with late diagnosis. Early detection can significantly increase the survival rate, and facilitate timely treatment. Accurate biomedical image classification is vital in medical analysis, aiding clinicians in disease diagnosis and treatment. Deep learning (DL) techniques, such as convolutional neural networks and transformers, have revolutionized clinical decision-making automation. However, computational cost and hardware constraints limit the implementation of state-of-the-art DL architectures. In this work, we explore a new type of neural network that does not need backpropagation (BP), namely the Forward-Forward Algorithm (FFA), for skin lesion classification. While FFA is claimed to use very low-power analog hardware, BP still tends to be superior in terms of classification accuracy. In addition, our experimental results suggest that the combination of FFA and BP can be a better alternative to achieve a more accurate prediction.
ARHNet: Adaptive Region Harmonization for Lesion-aware Augmentation to Improve Segmentation Performance
Jul 02, 2023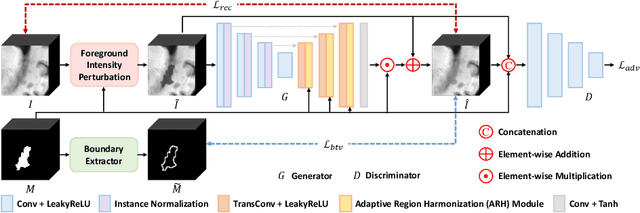
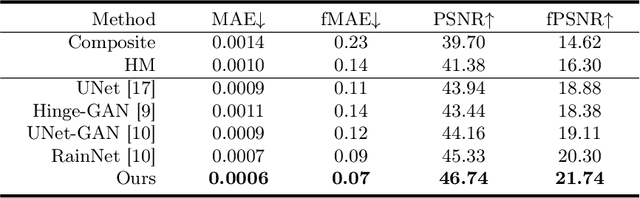
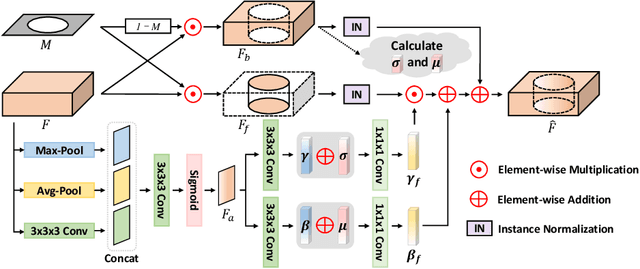
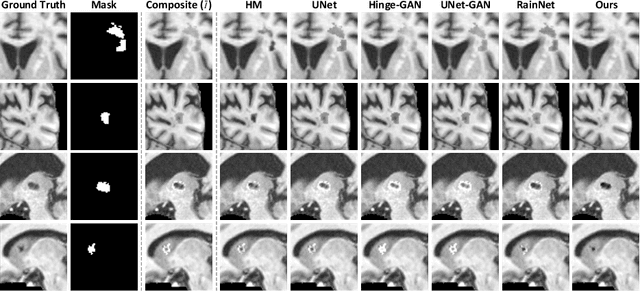
Accurately segmenting brain lesions in MRI scans is critical for providing patients with prognoses and neurological monitoring. However, the performance of CNN-based segmentation methods is constrained by the limited training set size. Advanced data augmentation is an effective strategy to improve the model's robustness. However, they often introduce intensity disparities between foreground and background areas and boundary artifacts, which weakens the effectiveness of such strategies. In this paper, we propose a foreground harmonization framework (ARHNet) to tackle intensity disparities and make synthetic images look more realistic. In particular, we propose an Adaptive Region Harmonization (ARH) module to dynamically align foreground feature maps to the background with an attention mechanism. We demonstrate the efficacy of our method in improving the segmentation performance using real and synthetic images. Experimental results on the ATLAS 2.0 dataset show that ARHNet outperforms other methods for image harmonization tasks, and boosts the down-stream segmentation performance. Our code is publicly available at https://github.com/King-HAW/ARHNet.
Noisy Image Segmentation With Soft-Dice
Apr 04, 2023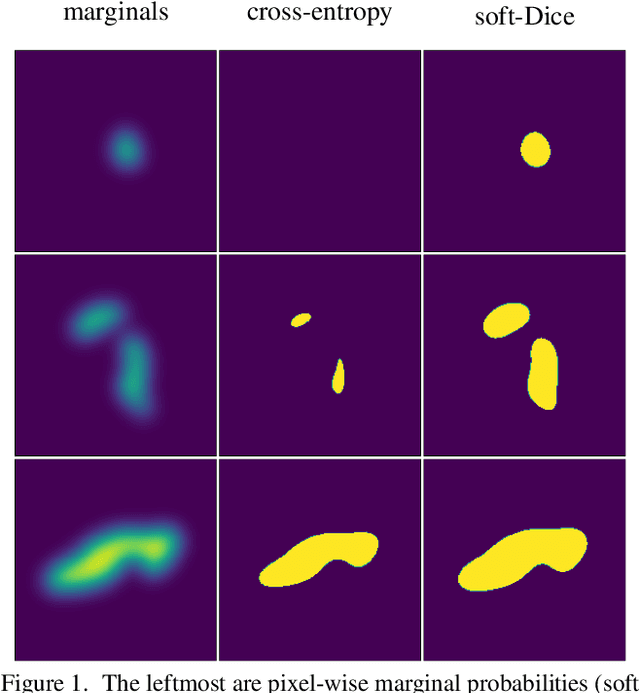
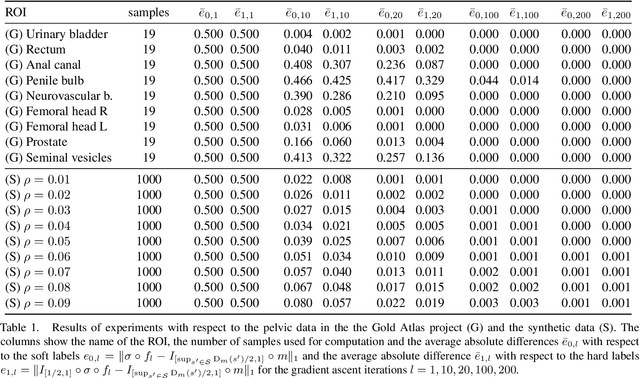
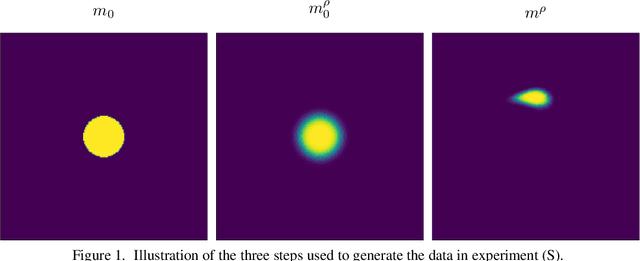
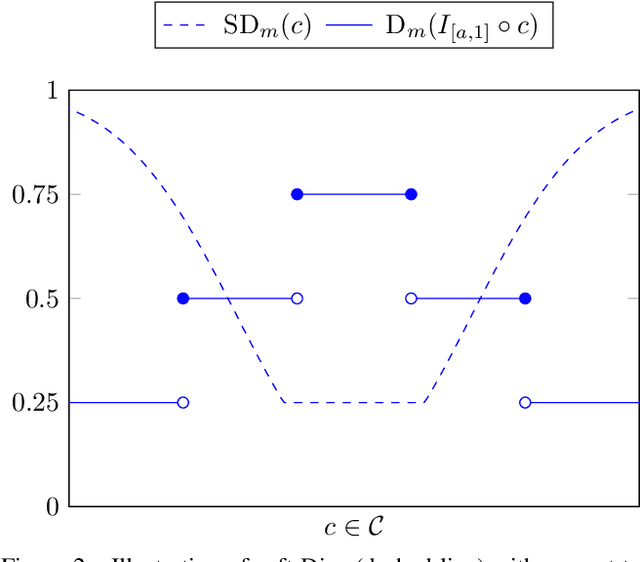
This paper presents a study on the soft-Dice loss, one of the most popular loss functions in medical image segmentation, for situations where noise is present in target labels. In particular, the set of optimal solutions are characterized and sharp bounds on the volume bias of these solutions are provided. It is further shown that a sequence of soft segmentations converging to optimal soft-Dice also converges to optimal Dice when converted to hard segmentations using thresholding. This is an important result because soft-Dice is often used as a proxy for maximizing the Dice metric. Finally, experiments confirming the theoretical results are provided.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023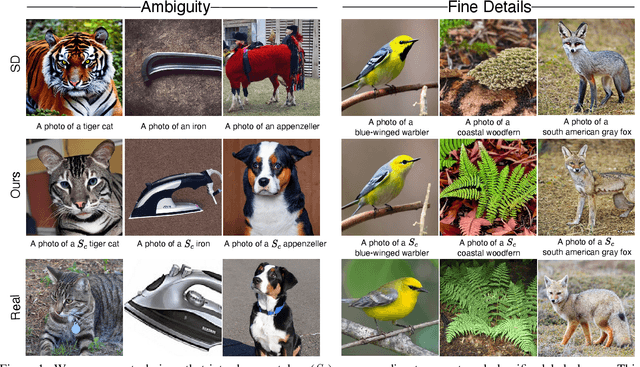
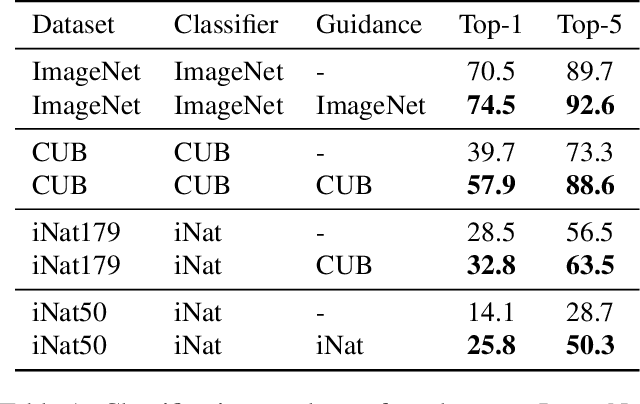
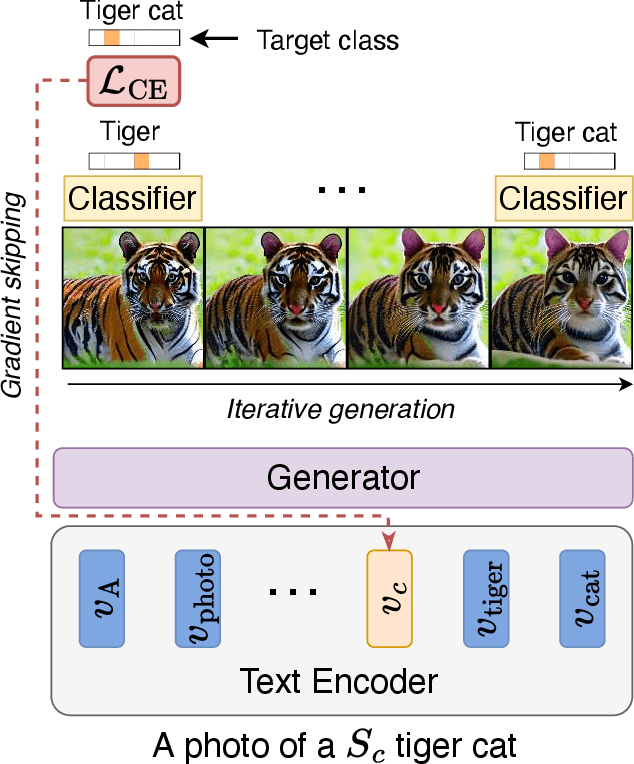
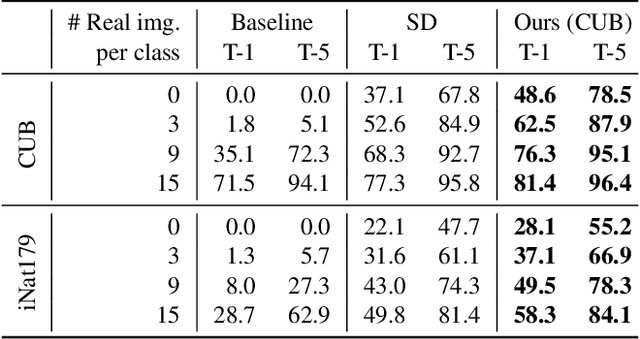
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}